前言
本文已经收录到我的
Github个人博客,欢迎大佬们光临寒舍:
学习导图:
一、应用层协议原理
Q1:网络应用程序体系结构
-
客户 - 服务器体系结构(
C/S):Web -
点对点结构(
P2P):迅雷 -
混合结构:
Napster
Q2:进程通信
-
客户和服务器进程
-
进程与计算机网络之间的接口:进程通过套接字(
socket)软件接口向网络发送报文和从网络接收报文。 -
进程寻址:主机的地址由
IP地址标识,进程的位置由端口号标识。
Q3:可供应用使用的运输服务
运输服务的衡量标准:
- 可靠数据传输
- 吞吐量
- 定时
- 安全性
Q4:因特网提供的运输服务
-
TCP服务:特点是面向连接和可靠的数据传送 -
UDP服务:特点是无连接的最小服务(非可靠)
Q5:应用层协议
应用层协议 (application layer protocol) 定义了运行在不同端系统上的应用程序进程如何相互传递报文
(1) 交换的报文类型,如请求报文和响应报文;
(2) 各种报文类型的语法,如报文中的各个字段公共详细描述;
(3) 字段的语义,即包含在字段中信息的含义;
(4) 进程何时、如何发送报文及对报文进行响应。
二、Web 和 HTTP
Q1:HTTP
HTTP名为超文本传输协议, 规定了客户端和服务器之间进行报文交换的方法HTTP用TCP作为他的传输层协议。HTTP客户首先发起一个与服务器的TCP连接- 服务器响应的时候,不存储客户端的状态信息,因此
HTTP也被称为 无状态协议
Q2:非持续连接和持续连接
-
持续链接:只采用一个
TCP连接完成 -
非持续连接:采用独立的
TCP连接完成 -
由服务器端决定,
TCP协议的请求,是采用一个TCP连接完成,还是独立TCP连接完成 -
默认情况下使用持续连接
-
非持续连接
HTTP:每个TCP连接 只传送一个请求报文和相应报文
这里书上提到了一个概念,
RTT(Round-Trip Time)往返时延,报文从C->S->C的时间。由于有三次握手的存在,前两次握手已经用了 2个RTT,所以真正的响应时间应该是 2RTT+ 传输HTML对象
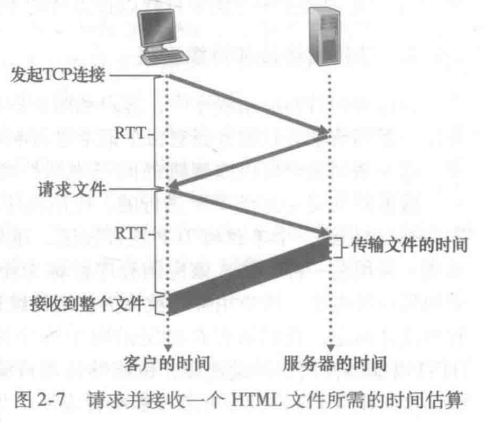
- 持续连接
HTTP:持续连接可以提高传输效率
上面说过,每个对象都要握手,经过2个
RTT才可以传输。而持续连接,则是用系统资源来换取效率。
Q3:HTTP 报文格式
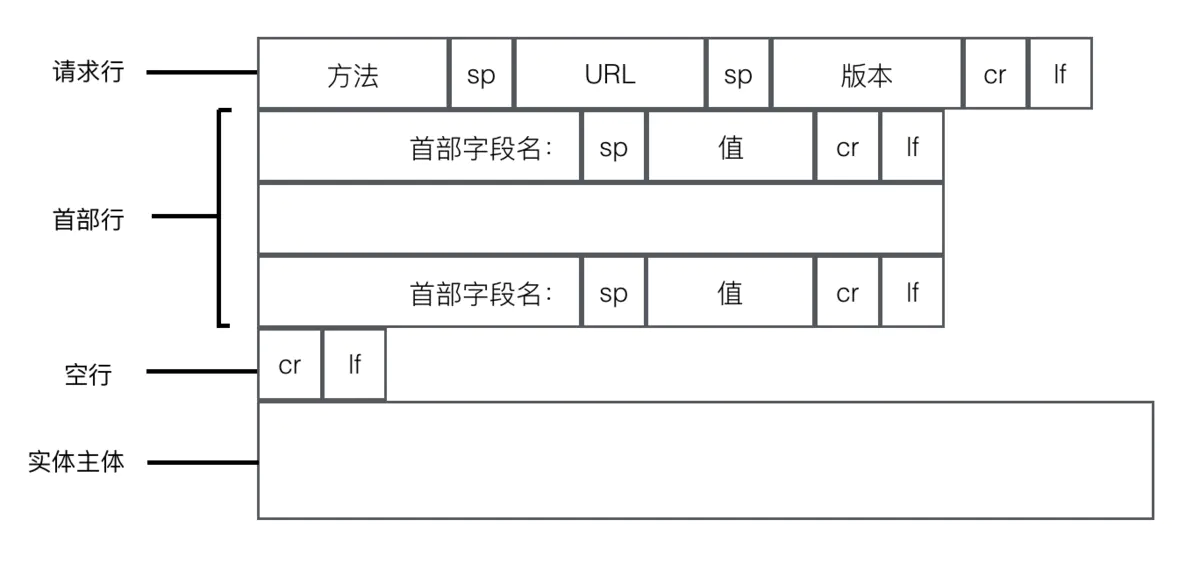
- 请求报文的格式:
- 请求行:方法字段、
URL字段、HTTP版本 - 请求头(首部行):服务器要使用的附加信息
- 空行:请求头后面必有空行
- 请求数据:请求数据的主题。
Get方法是没有的,放在了URL的参数中,POST方法放在表单中
GET /somedir/page.html HTTP/1.1
Host: www.someschool.edu
Connection: close //浏览器告诉服务器不要用持续链接,要求服务器在发送完请求对象后就关闭连接
User-agent: Mozilla/5.0 //指明用户代理
Accept-language: fr //指明用户得到对象的语言版本
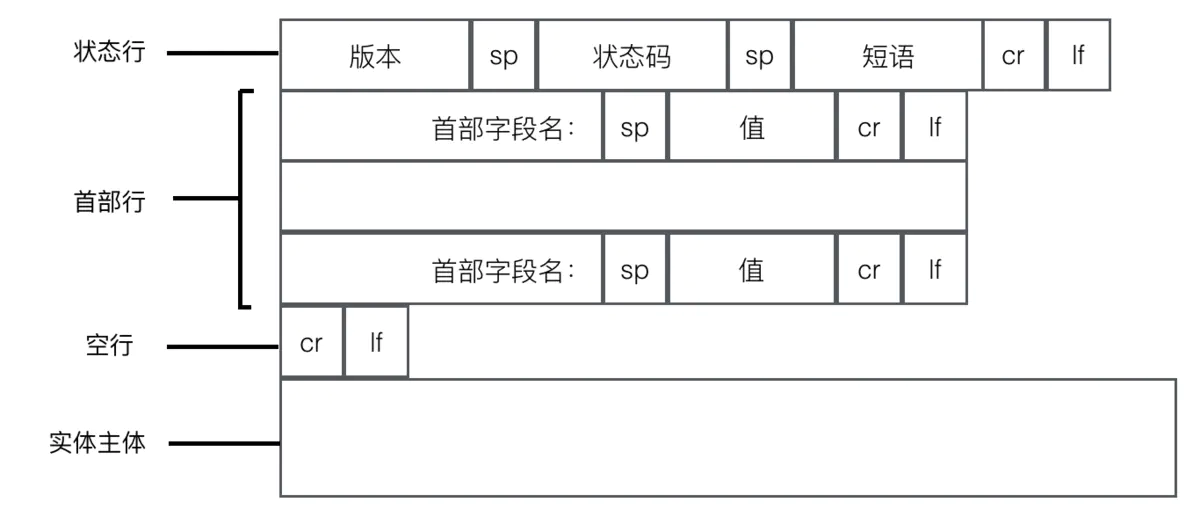
2.响应报文的格式:
- 状态行:
HTTP版本、状态 - 响应头(首部行):发送日期,服务器相关信息等
- 空行:
- 响应正文:响应的数据正文
HTTP/1.1 200 OK
Connection: close
Date: Tue, 09 Aug 2011 15:44:04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 09 Aug 2011 15:11:03 GMT
Content-Length: 6821
Content-Type: text/html
(data data data data data ...)
常见状态码:
200:请求成功
301:请求的对象被转移了,重定向的URL在响应报文中
400:非法请求,丢弃
404:Not Found,被请求的文档不在服务器上
505:服务器不支持请求报文使用的http版本
3.HTTP1.0 、HTTP1.1、HTTP2.0 之间的比较:
a.HTTP/1.0:
- 支持:
GET、POST、HEAD三种请求方法 - 无状态
- 非持续连接
- 串行发送:前一个请求的响应到达,后一个请求才可以发送
b. HTTP/1.1:
当前正在广泛使用的版本
- 新增了:
OPTIONS、PUT、DELETE、TRACE、CONNECT五种HTTP请求方法 - 持续性连接(持久连接)
- 请求管道化(由于
TCP长连接的存在,所以可以管道化) - 增加缓存处理
- 支持断点传输、增加
Host字段
最重要的是 长连接
c.HTTP/2.0:
- 二进制分帧
- 多路复用(并行传输)
- 头部压缩
- 服务器推送
重点是可以并行传输
Q4:用户和服务器的交互:cookie
之前说过,HTTP 是无状态协议。但是 Web 站点为了 识别用户身份 ,使用了 Cookie 技术。
Cookie 技术包含 4 个组件:
HTTP请求报文里增加一个关于Cookie的首部行HTTP响应报文里增加一个关于Cookie的首部行- 客户端系统 保留一个
Cookie文件,由浏览器保存维护 Web站点建立Cookie和 用户身份的关联
很好理解,自然是请求报文和相应报文都携带
Cookie,客户端和服务器端都存有Cookie文件。即 本地保存,访问携带
Cookie 和 Session 的区别
简单来说,二者都是为了 Web 站点 识别用户身份,Session 译为 会话,就是保存每一次客户端和服务器端会话中的 用户信息和用户操作,是有时间限制的。
Session 会在服务器端有一个 类似 HashTable 的数据来存放用户数据,浏览器第一次请求,生成一个 HashTable 和对应 的SessionID (用于标识这个 HashTable)。这个 Session ID 一般在 30 分钟后会自动销毁。
区别:
Cookie在客户端,会被篡改,不安全。Session在服务器端Cookie只能存String类型对象,且容量小。Session可以存java对象,容量大。
Q5:Web 缓存器(代理服务器)
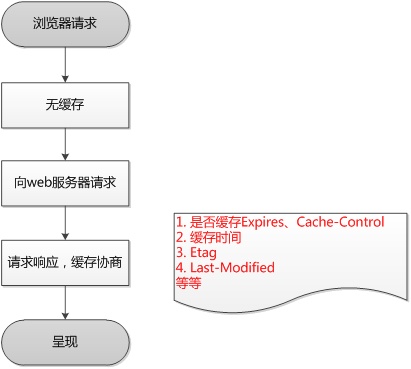
1.使用 Web 缓存器的 2 个主要原因:
- 降低延迟:缓存离客户端更近,因此,从缓存请求内容比从源服务器所用时间更少,呈现速度更快,网站就显得更灵敏
- 降低网络传输:副本被重复使用,大大降低了用户的带宽使用,其实也是一种变相的省钱(如果流量要付费的话),同时保证了带宽请求在一个低水平上,更容易维护了
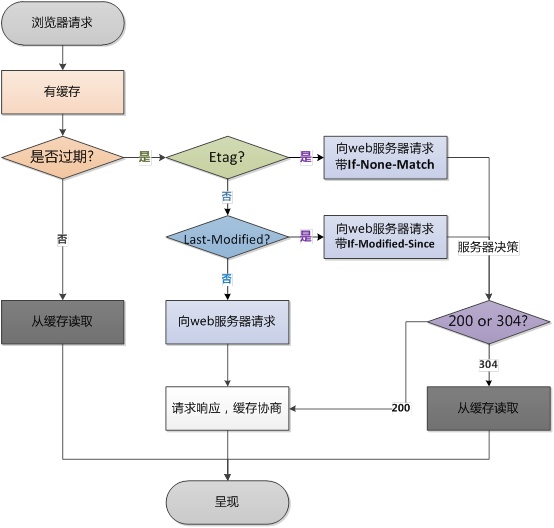
2.工作过程
Q6:条件 get 方法
上述实现方式还有一个问题就是无法保证本地存储器内的内容是最新的,所以需要采用一种方式(条件性 GET 方法)来保证数据是最新版本。这个方法的基本思想就是本地代理服务器向 URL 目标服务器发送一个 GET 请求消息,这个消息里面包括了本地存储资源的更新时间,在 URL 目标服务器中,会用这个时间与最新版本的时间进行比对,如果时间一致就返回 304 Not Modified , 否则就返回 200 OK 和最新版本的资源。代理服务器接收到返回信息后会判断这个返回码,如果是 304,就直接返回给客户给本地代理服务器存储的资源;如果是 200 就把新接收到的资源返回给用户,同时更新代理服务器存储的内容。
三、文件传输协议 FTP
FTP的特点:同HTTP一样,也是运行在TCP上的协议,但它采用了两个并行的TCP连接来传输文件:
- 一个用于控制连接
- 一个用于数据连接
- 所以我们称其为带外(
out-of-band)传输。另外,控制链接和持续整个过程,而每传输一个新文件,都需要新开一条数据连接
四、因特网中的电子邮件
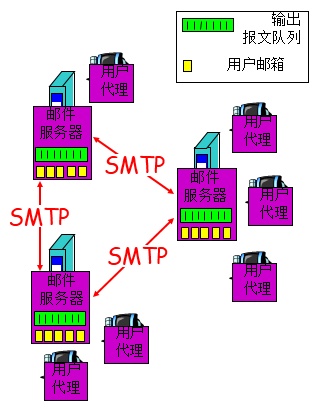
电子邮件的组成部分:
- 用户代理
- 邮件服务器
- 简单邮件传输协议
SMTP
-
用户代理允许用户阅读、回复、转发、保存和撰写报文
-
邮件服务器组成了电子邮件体系结构的核心
每个接收方在其中的某个服务器上有一个邮箱
邮箱包含用户的到达报文、离开 (将发送) 邮件报文的报文队列
在发送电子邮件报文的邮件服务器之间采用
SMTP协议。
SMTP 是因特网电子邮件中主要的应用层协议。它使用 TCP 可靠数据传输服务,从发送方的邮件服务器向接收方的邮件服务器发送邮件。
1、SMTP
-
使用
TCP从客户机到服务器可靠地传输电子邮件报文,用端口25 -
直接传输:发送服务器到接收服务器
-
传输的三个阶段:握手 (欢迎)、报文的传输、关闭
-
报文必须以 7 比特
ASCII格式
为了描述 SMTP 的基本操作,下面来模拟一下 Alice 给 Bob 发送一封简单的 ASCII 报文的过程:
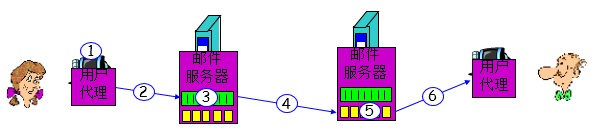
-
Alice使用用户代理写作报文并向 bob@someschool.edu 发送 -
Alice的 用户代理 向其邮件服务器发送报文;报文放置在报文队列中 -
SMTP的客户机侧打开与Bob的邮件服务器的TCP连接 -
SMTP通过TCP连接发送Alice的报文 -
Bob的邮件服务器将该报文放入Bob的邮箱 -
Bob调用其用户代理(通过POP/POP3)来读报文
2、SMTP 与 HTTP 的对比
-
HTTP: 拉协议SMTP: 推协议 -
SMTP要求全部7位ASCII码格式传输HTTP无此要求 -
HTTP: 每个对象封装在其自己的响应报文中SMTP: 所有报文对象放在一个报文中
3、邮件访问协议
- 注意到
Bob的用户代理不能使用SMTP来取回邮件,因为取邮件是一个拉操作,而SMTP是一个推协议。因此我们要引入邮件访问协议:
POP
POP协议支持 “离线” 邮件存储转发处理:客户端程序连接服务器,下载所有未阅读的电子邮件- 一旦将邮件从邮件服务器端送到客户端上,邮件服务器上的邮件将会被删除
POP3
POP3协议允许电子邮件客户端下载服务器上的邮件- 但是在客户端的操作(如移动邮件、标记已读等),不会反馈到服务器上,比如通过客户端收取了邮箱中的 3 封邮件并移动到其他文件夹,邮箱服务器上的这些邮件是没有同时被移动的
IMAP的介绍,以及和 POP3 的区别
-
IMAP像POP3那样提供了方便的邮件下载服务,让用户能进行离线阅读 -
IMAP和POP3是邮件访问最为普遍的Internet标准协议。不同的是:
IMAP提供Webmail与电子邮件客户端之间的双向通信,客户端收取的邮件仍然保留在服务器上,同时在客户端上的操作都会反馈到服务器上(如:删除邮件,标记已读等,服务器上的邮件也会做相应的动作。所以无论从浏览器登录邮箱或者客户端软件登录邮箱,看到的邮件以及状态都是一致的)。而POP3在客户端的操作不会反馈到服务器上。IMAP更好地支持了从多个不同设备中随时访问新邮件IMAP提供的摘要浏览功能:可以让你在阅读完所有的邮件到达时间、主题、发件人、大小等信息后才作出是否下载的决定。POP3需要下载未阅读的邮件,IMAP可以不用把所有的邮件全部下载,而是通过客户端直接对服务器上的邮件进行操作。所有通过IMAP传输的数据都会被加密,从而保证通信的安全性。IMAP整体上为用户带来更为便捷和可靠的体验。POP3更易丢失邮件或多次下载相同的邮件。
五、DNS:因特网的目录服务
-
DNS提供的服务主要为主机名到IP地址的转换 -
DNS采用的是UDP
Q1:DNS 提供的其他服务:
- 主机别名
有着复杂主机名的主机可以拥有一个或多个别名。原复杂主机名也叫规范主机名。主机别名(如果有的话)比主机规范名更容易记忆。应用程序可以调用
DNS来获得主机别名对应的规范主机名以及主机的IP地址
- 邮件服务器别名
同主机别名类似,电子邮件应用程序调用
DNS,对提供的邮件服务器别名进行解析,以获得该主机的规范主机名以及其IP地址。MX(Mail Exchanger,邮件交换)记录允许一个公司的邮件服务器和Web服务器用相同的(别名化的)主机名
- 负载分配
DNS也用于在冗余的服务器(如冗余的Web服务器等)之间进行负载分配。对于这些冗余的Web服务器,一个IP地址集合对应于同一个规范主机名。DNS数据库中存储着这些IP地址集合。当客户机为映射到这个IP地址集合的名字发出一个DNS请求时,该服务器用包含全部这些地址的报文回答,但在每个回答中旋转这些地址排放顺序。因为客户机通常总是向IP地址排在最前面的服务器发送HTTP请求报文,所以DNS就在所有这些冗余的Web服务器之间旋转分配负载。DNS旋转同样适用于邮件服务器,因此,多个邮件服务器可以具有相同的别名。
2、DNS 的工作原理
DNS 采用分布式的设计方案
下面是 DNS 服务器的部分层次结构(由上到下,每层分别是根服务器、顶级域TLD 服务器、权威服务器)
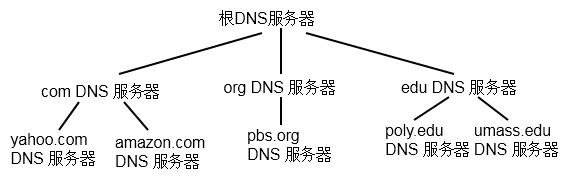
1)分布式、层次数据库
大致来说,有 3 种类型的 DNS 服务器:根 DNS 服务器、顶级域(Top9 Level Domain,TLD)DNS 服务器和权威 DNS 服务器。
下面来详细介绍一下这三种类型的 DNS 服务器:
- 根
DNS服务器
- 顶级域
TLD服务器
负责
com,org,net,edu等,以及所有顶级国家域uk,fr,ca,jp,cn
- 权威
DNS服务器
组织的
DNS服务器为组织的服务器 (如Web和电子邮件) 提供对IP映射的权威主机名。 能够由组织或服务提供商维护。
- 本地
DNS服务器
本地
DNS服务器严格来说并不属于DNS服务器的层次结构,但它对DNS层次结构是很重要的。
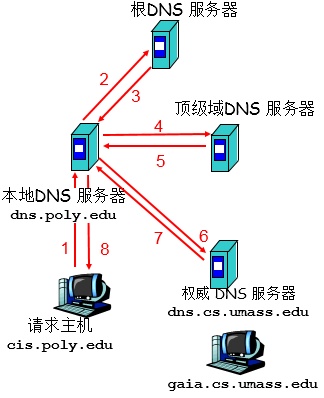
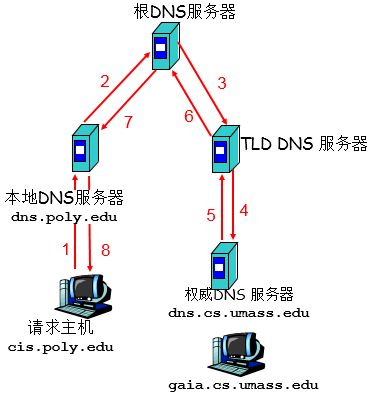
在图 1 的例子中用到了递归查询和迭代查询
从理论上,所有的 DNS 查询既可以是迭代的也可以是递归的。例如,图 2 显示了一条 DNS 查询链,其中所有查询都是递归的
实际中,查询通常遵循图 1 中的模式:从请求主机到本地 DNS 服务器的查询是递归的,其余查询是迭代的
2)DNS 缓存
-
为了改善时延性能并减少在因特网上到处传输的
DNS报文数量,DNS广泛使用缓存技术 -
原理:当一个
DNS服务器接收一个DNS回答(例如,包含主机名到IP地址的映射)时,DNS服务器能将回答中的信息缓存在本地存储器。由于主机与主机名的IP地址映射决不是永久的,所以DNS服务器在一段时间后(通常设置为两天)将丢弃缓存的信息
3)域名解析过程
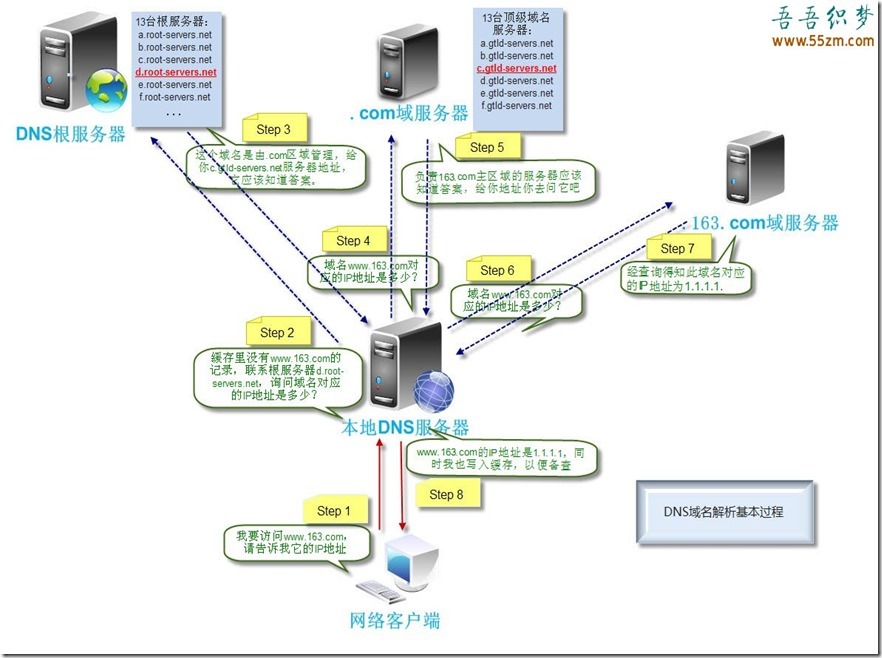
六、P2P 应用
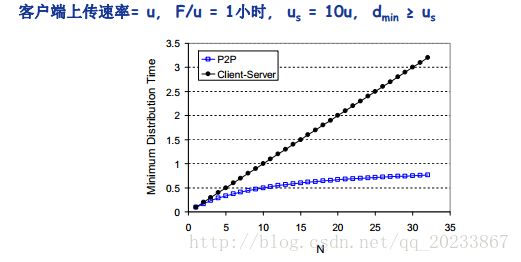
问题 : 从一个服务器向 N 个节点分发一个文件需要多长时间?
(1)客户机 / 服务器:服务器串行地发送 N 个副本
- 时间:
NF/us - 客户机 i 需要 F/di 时间下载
(2)P2P:服务器必须发送一个副本
- 时间:
F/us - 客户机 i 需要
F/di时间下载 - 总共需要下载
NF比特 - 最快的可能上传速率:
us + ∑ui

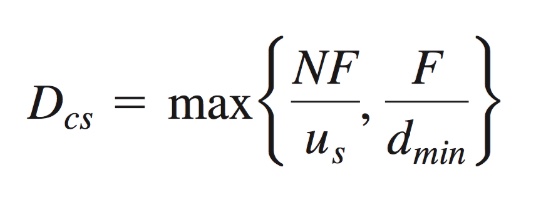
如果文章对您有一点帮助的话,希望您能点一下赞,您的点赞,是我前进的动力
本文参考链接:
- 《计算机网络-自顶向下方法》
- 应用层 |《计算机网络:自顶向下方法》
- 《计算机网络-自顶向下方法》第二章-应用层 要点
- 《计算机网络-自顶向下方法》重点笔记