今年学习了几个月nodejs。暑假期间,闲的无事,都说学习爬虫一定要爬一爬教务系统,不过更多的人爬教务系统用的都是python,正好最近在学nodejs,于是就想,我可以用nodejs实现一个吗?说干就干。
我有两种思路:一是利用selenium之类的自动化测试来实现爬虫,二是分析教务系统的请求,仿造浏览器请求来实现这个爬虫。于是我一 一按照这两种思路去实现了爬虫。
这里说一说分析教务系统请求的思路,自动化测试就不再说了。
首先我们打开教务系统的首页(这里的例子是山西大学教务网络管理系统--其它青果教务系统大同小异)
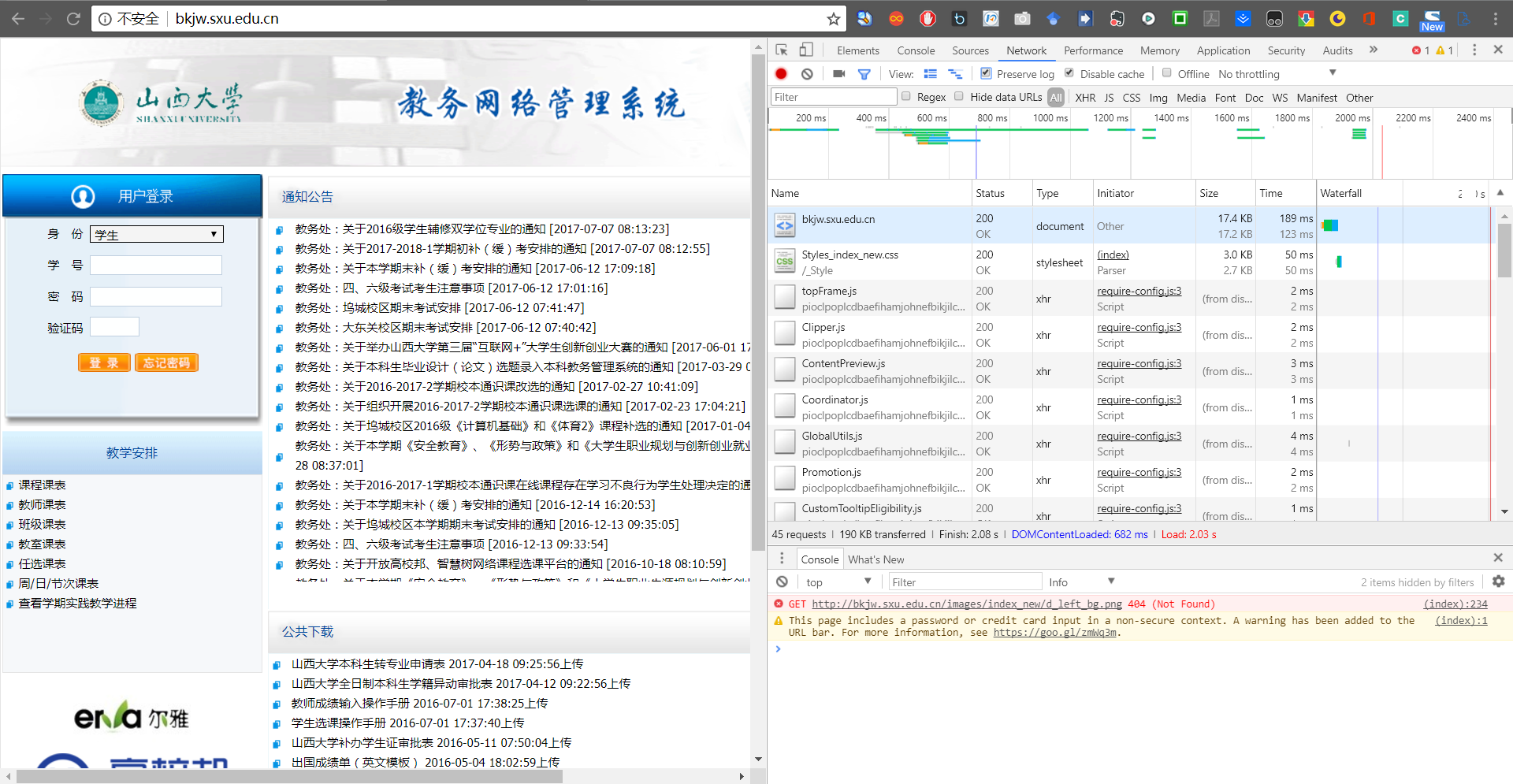
打开F12开发者工具,进入Network选项卡,勾选preserve log,以方便我们记录每一步网络请求。
我们要实现获取成绩获取课表等等操作,首先第一步就是要登录教务系统(也是相对获取成绩之类操作最难的一步)。
下来我们来分析一下登录的过程。

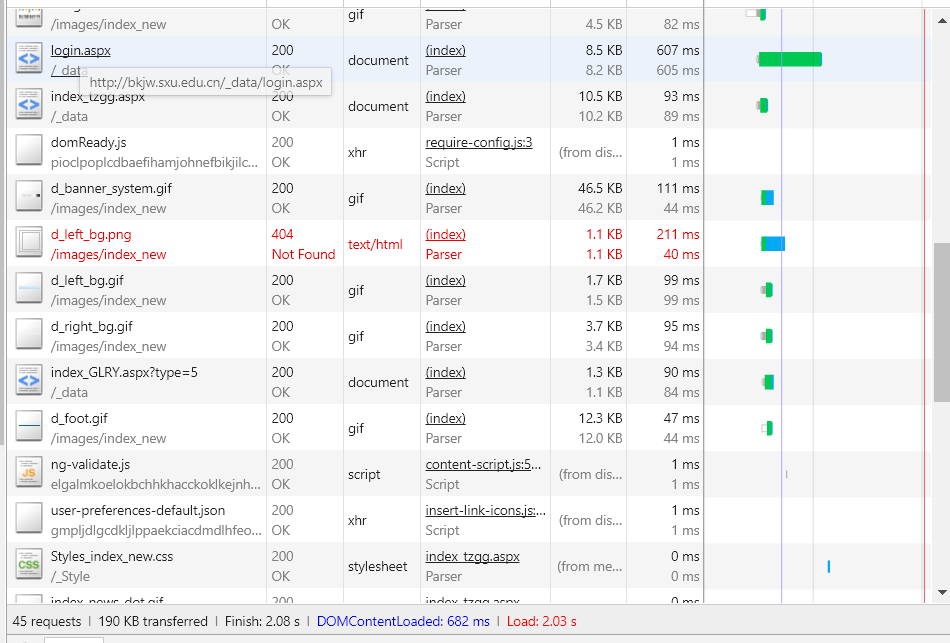
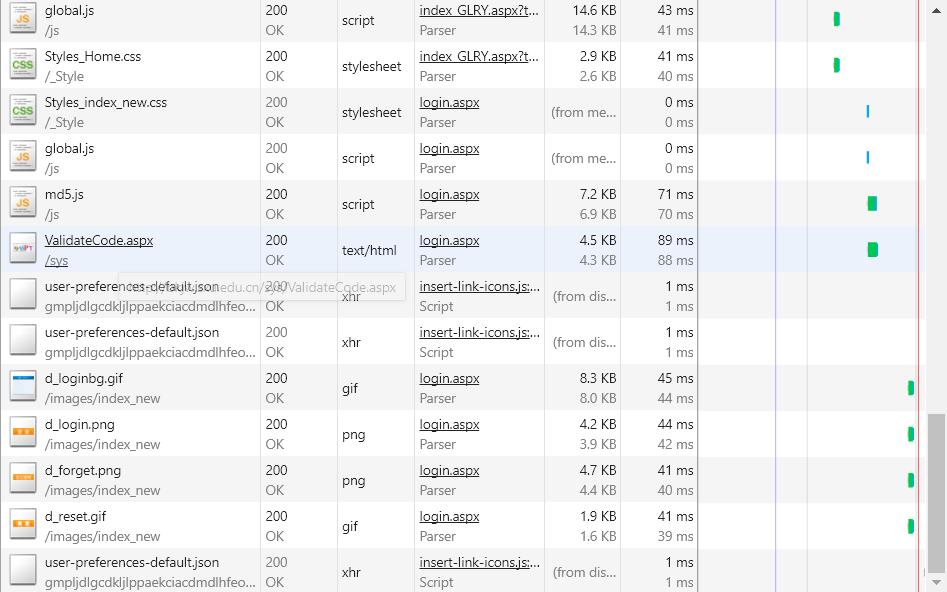
整个主页的请求可以大致简化为:
1.get:http://bkjw.sxu.edu.cn/,同时获取到cookie
2.get:http://bkjw.sxu.edu.cn/_data/login.aspx,带上第一步获取的cookie值
3.get:http://bkjw.sxu.edu.cn/sys/ValidateCode.aspx,带上第一步获取的cookie值,获取到特定的验证码
4.post:http://bkjw.sxu.edu.cn/_data/login.aspx,向这个地址发送post请求,同时带上表单数据
这里的cookie记录的是服务器端的session,关于cookie和session,请阅读http协议相关部分
2-3两者间隔时间不能太长,否则会失败
大致一个登录的过程就是这样。
下来我们来分析一下发送的表单数据。
首先在浏览器里登录教务系统,获得一个post请求的记录。
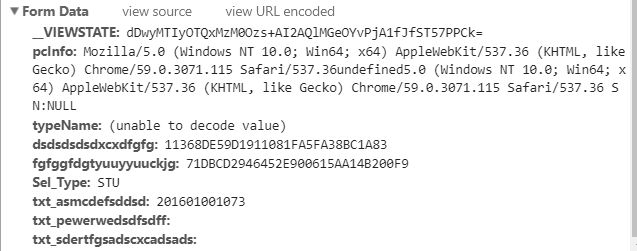
我们发现总共有以下几个数据:
__VIEWSTATE:
这个数据是从哪里获得的呢?
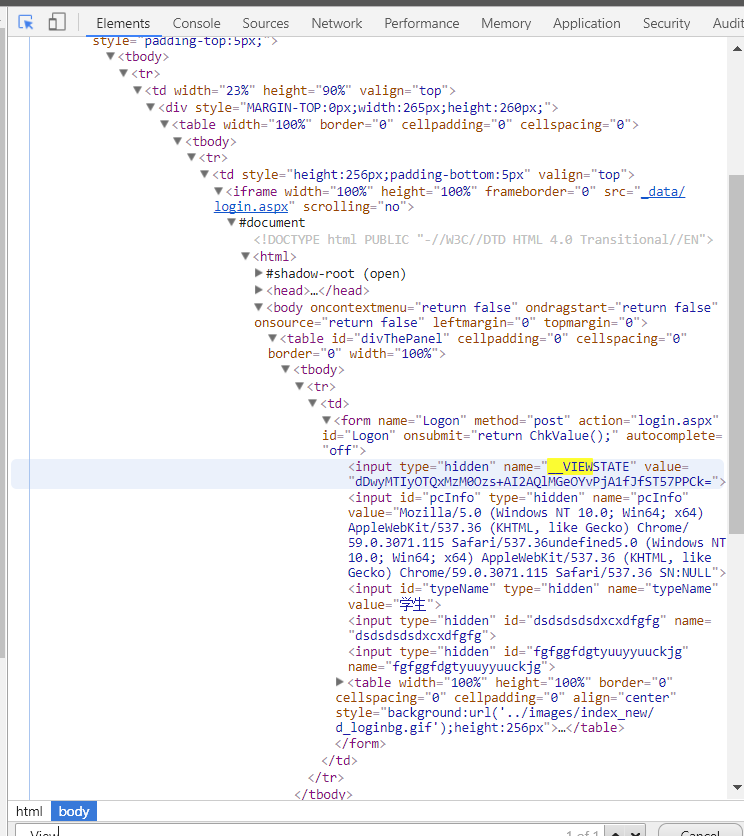
我们再回到表单处,发现有这么一个隐藏的表单,它的value值就是我们所需要的__VIEWSTATE
我们再看发送的表单,发现原来应该是密码和验证码的地方是空,却多了两个dsdsdsdsdxcxdfgfg和fgfggfdgtyuuyyuuckjg
这样看应该是密码和验证码被加密了。
我们就来看看究竟是怎样的加密过程。
function chkpwd(obj) { if(obj.value!='') { var s=md5(document.all.txt_asmcdefsddsd.value+md5(obj.value).substring(0,30).toUpperCase()+'10108').substring(0,30).toUpperCase(); document.all.dsdsdsdsdxcxdfgfg.value=s; } else { document.all.dsdsdsdsdxcxdfgfg.value=obj.value;} } function chkyzm(obj) { if(obj.value!='') { var s=md5(md5(obj.value.toUpperCase()).substring(0,30).toUpperCase()+'10108').substring(0,30).toUpperCase(); }}
由于前端代码我们可以看见,由此可以看到它的加密过程,而且我们的后端用的是nodejs,所以我们只需要小小的修改一下即可(等会讨论)。
到现在我们的整个登录过程就分析完毕了,下面我们开始实现关键过程。
首先先说这个密码的加密和验证码的加密。
我们创建了一个类叫做spider
利用nodejs的crypto模块去实现md5加密
var crypto = require("crypto"); function md5(text){ return crypto.createHash('md5').update(text).digest('hex'); }
对上面的加密方式稍加修改
//md5加密 spider.prototype.secret=function(option){ if(option.type==="password"){ return md5(option.id + md5(option.pwd).substring(0, 30).toUpperCase() + option.schoolNumber).substring(0, 30).toUpperCase(); }else if(option.type==="check"){ return md5(md5(option.checkNumber.toUpperCase()).substring(0, 30).toUpperCase() + option.schoolNumber).substring(0, 30).toUpperCase(); } };
这里我们接受一个对象,形如
{ type:'check',//这里是要得到的md5码类型,check或者password,验证码或是密码 id:'00000000000',//学号 pwd:'000000',//密码 schoolNumber:'10108',//使用青果教务系统的学校代号 checkNumber:checkNumber//验证码 }
其次说一说如何获得viewstate的值
spider.prototype.getViewState=function(cookie,callback){ var that=this; console.log("开始获取viewstate"); console.log(`使用的Cookie是${cookie}`); var data=''; var req=http.request({ hostname:'bkjw.sxu.edu.cn', port:80, path:'/_data/login.aspx', method:'GET', headers:{ 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding':'gzip, deflate', 'Accept-Language':'zh-CN,zh;q=0.8', 'Cache-Control':'no-cache', 'Connection':'keep-alive', 'Cookie':`${cookie}`, 'Host':'bkjw.sxu.edu.cn', 'Pragma':'no-cache', 'Referer':'http://bkjw.sxu.edu.cn', 'Upgrade-Insecure-Requests':'1', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36' } },(res)=>{ res.setEncoding('utf-8'); res.on("data",(chunk)=>{ data+=chunk; }); res.on("end",()=>{ console.log("数据接收完毕"); console.log(data); var $=cheerio.load(data); that.viewstate=$("input[name='__VIEWSTATE']").val(); callback(); }); }); req.on("error",(err)=>{ console.log(err); }); req.end(); //console.log(data); };
这里我用了cheerio去解析源文件来取得我们所要的值。
如何获取cookie的值
spider.prototype.getWeb=function(callback){ var that=this; console.log(this.urls); superagent.get(this.urls) .end(function(err,res) { //console.log(that.urls); that.theCookie = res.header['set-cookie'][0].split(";")[0]; console.log(` -------------------------- ------------------------- ${that.theCookie} ------------------------ ------------------------`); // var $=cheerio.load(res.text); //var inputs=$('input'); // console.log(res.text); setTimeout(()=>{ callback(); },500); }) };
关于异步
由于整个过程中有些步骤要等待上一步完成,但是在nodejs中会异步进行完成,所以在写的时候出现了还没有获取cookie就开始进行了请求等等异步问题,我尝试使用promise,但是发现promise并不能完全达到我的需要,最后,不得已用了setTimeout和事件来完成。(急待改进)
这里大体分析了一下整个爬虫的思路和部分实现过程。
我在GitHub上放了我实现整个青果教务系统爬虫的源代码:https://github.com/cuijinyu/qingguospider
使用selenium实现的版本:https://github.com/cuijinyu/spiderForSXU
现在可以实现登录过程,但是爬取课表等等还暂时未完成,获取成绩还有一些bug,我将会尽快改正。
现在有好几个函数依然是仅适用于山西大学教务网络管理系统,我将会尽快将它们改成适合所有青果系统的函数。
新人一只,希望大家可以给我提出意见。