HTTP 请求的准备
1、浏览器会将 www.163.com 这个域名发送给 DNS 服务器,让它解析为 IP 地址。
2、建立 TCP 连接,HTTP是基于TCP协议的,目前使用的 HTTP 协议大部分都是 1.1。在 1.1 的协议里面,默认是开启了 Keep-Alive 的,这样建立的 TCP 连接,就可以在多次请求中复用。
HTTP 请求的构建
建立连接后就要发送HTTP请求,请求格式如下:

HTTP 的报文大概分为三大部分。第一部分是请求行,第二部分是请求的首部,第三部分才是请求的正文实体。
第一部分:请求行
GET :去服务器获取一些资源。返回的可能是一个 JSON 字符串。
POST:需要主动告诉服务端一些信息,而非获取。常见的格式也是 JSON。
PUT:就是向指定资源位置上传最新内容。一般做更新用。
DELETE:用来删除资源的。
第二部分:首部字段
首部是 key value,通过冒号分隔。
如:Accept-Charset,表示客户端可以接受的字符集。
Content-Type 是指正文的格式。
缓存强调一下对于这种高并发场景下的系统,在真正的业务逻辑之前,都需要有个接入层,将这些静态资源的请求拦在最外面,以达到快速加载页面的效果。架构如下:
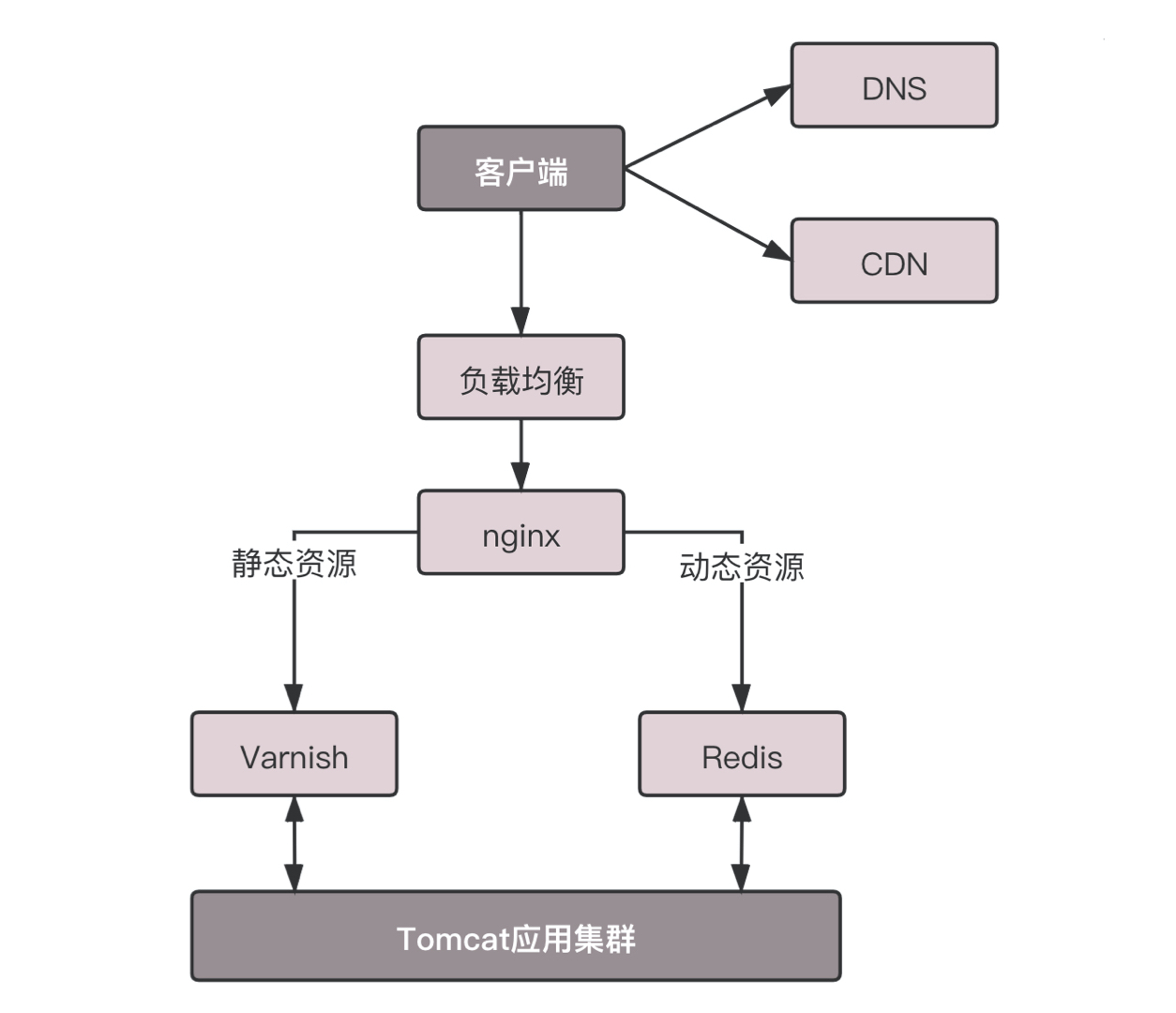
Cache-control 是用来控制缓存的。当客户端发送的请求中包含 max-age 指令时,如果判定缓存层中,资源的缓存时间数值比指定时间的数值小,那么客户端可以接受缓存的资源;当指定 max-age 值为 0,那么缓存层通常需要将请求转发给应用集群。
If-Modified-Since 也是一个关于缓存的。也就是说,如果服务器的资源在某个时间之后更新了,那么客户端就应该下载最新的资源;如果没有更新,服务端会返回“304 Not Modified”的响应,那客户端就不用下载了,也会节省带宽。
HTTP 请求的发送
HTTP 协议是基于 TCP 协议的,所以它使用面向连接的方式发送请求,通过 stream 二进制流的方式传给对方。当然,到了 TCP 层,它会把二进制流变成一个个报文段发送给服务器。
在发送给每个报文段的时候,都需要对方有一个回应 ACK,来保证报文可靠地到达了对方。如果没有回应,那么 TCP 这一层会进行重新传输,直到可以到达。同一个包有可能被传了好多次,但是 HTTP 这一层不需要知道这一点,因为是 TCP 这一层在埋头苦干。
TCP 层发送每一个报文的时候,都需要加上自己的地址(即源地址)和它想要去的地方(即目标地址),将这两个信息放到 IP 头里面,交给 IP 层进行传输。
IP 层需要查看目标地址和自己是否是在同一个局域网。如果是,就发送 ARP 协议来请求这个目标地址对应的 MAC 地址,然后将源 MAC 和目标 MAC 放入 MAC 头,发送出去即可;如果不在同一个局域网,就需要发送到网关,还要需要发送 ARP 协议,来获取网关的 MAC 地址,然后将源 MAC 和网关 MAC 放入 MAC 头,发送出去。
网关收到包发现 MAC 符合,取出目标 IP 地址,根据路由协议找到下一跳的路由器,获取下一跳路由器的 MAC 地址,将包发给下一跳路由器。这样路由器一跳一跳终于到达目标的局域网。这个时候,最后一跳的路由器能够发现,目标地址就在自己的某一个出口的局域网上。于是,在这个局域网上发送 ARP,获得这个目标地址的 MAC 地址,将包发出去。
目标的机器发现 MAC 地址符合,就将包收起来;发现 IP 地址符合,根据 IP 头中协议项,知道自己上一层是 TCP 协议,于是解析 TCP 的头,里面有序列号,需要看一看这个序列包是不是我要的,如果是就放入缓存中然后返回一个 ACK,如果不是就丢弃。
TCP 头里面还有端口号,HTTP 的服务器正在监听这个端口号。于是,目标机器自然知道是 HTTP 服务器这个进程想要这个包,于是将包发给 HTTP 服务器。HTTP 服务器的进程看到,原来这个请求是要访问一个网页,于是就把这个网页发给客户端。
HTTP 返回的构建
HTTP 的返回报文也是有一定格式的。这也是基于 HTTP 1.1 的:
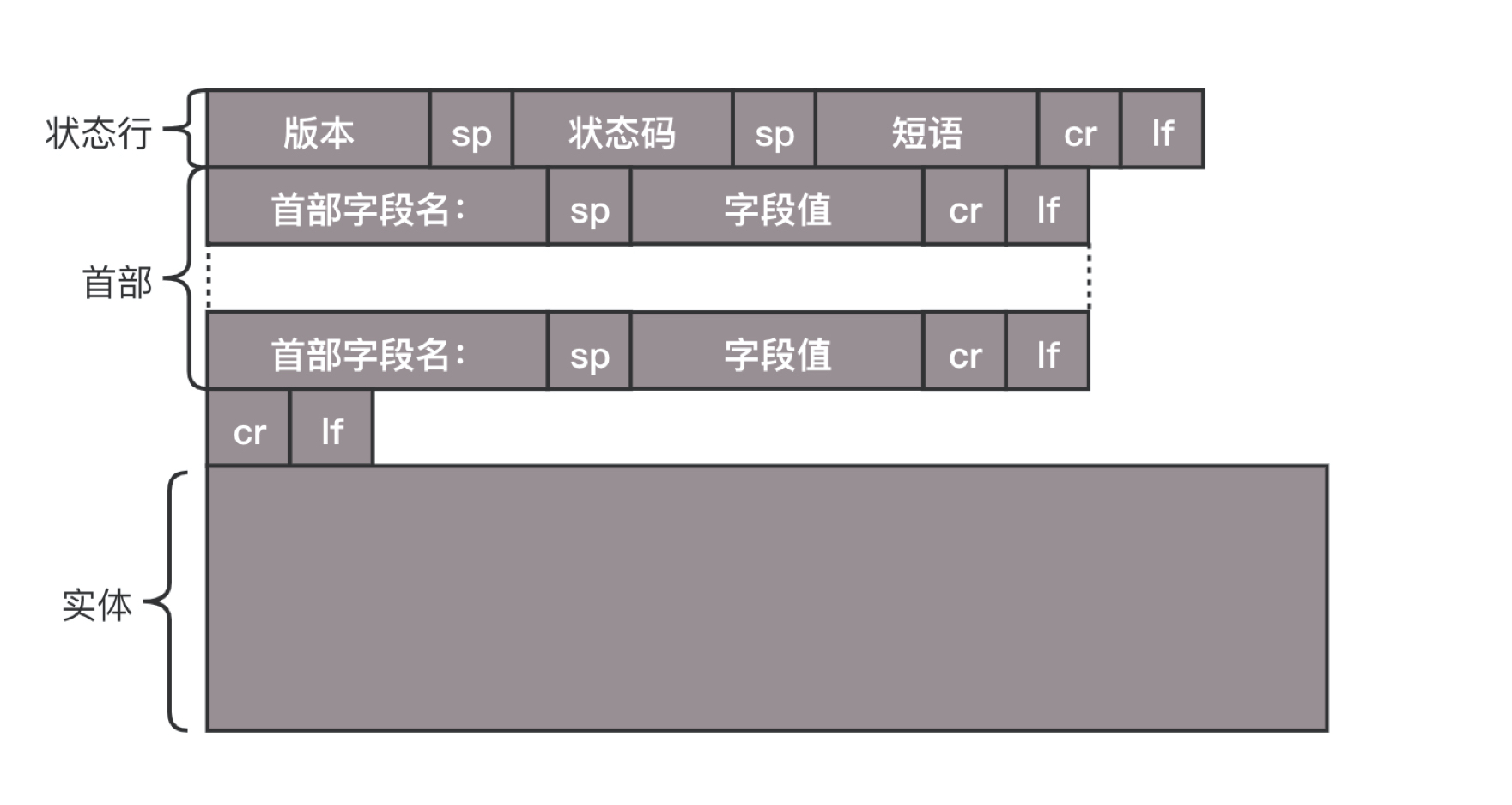
1、状态码:200、404、500啥的
2、首部:key value
如:Retry-After 表示,告诉客户端应该在多长时间以后再次尝试一下。一般与状态码“503 ”是说“服务暂时不再和这个值配合使用”。
Content-Type 表示,返回的是 HTML,还是 JSON。
3、返回实体
构造好了返回的 HTTP 报文,接下来就是把这个报文发送出去。还是交给 Socket 去发送,还是交给 TCP 层,让 TCP 层将返回的 HTML,也分成一个个小的段,并且保证每个段都可靠到达。这些段加上 TCP 头后会交给 IP 层,然后把刚才的发送过程反向走一遍。
虽然两次不一定走相同的路径,但是逻辑过程是一样的,一直到达客户端。客户端发现 MAC 地址符合、IP 地址符合,于是就会交给 TCP 层。根据序列号看是不是自己要的报文段,如果是,则会根据 TCP 头中的端口号,发给相应的进程。这个进程就是浏览器,浏览器作为客户端也在监听某个端口。
当浏览器拿到了 HTTP 的报文。发现返回“200”,一切正常,于是就从正文中将 HTML 拿出来。HTML 是一个标准的网页格式。浏览器只要根据这个格式,展示出一个绚丽多彩的网页。这就是一个正常的 HTTP 请求和返回的完整过程。
HTTP 2.0
假设我们的一个页面要发送三个独立的请求,一个获取 css,一个获取 js,一个获取图片 jpg。如果使用 HTTP 1.1 就是串行的,但是如果使用 HTTP 2.0,就可以在一个连接里,客户端和服务端都可以同时发送多个请求或回应,而且不用按照顺序一对一对应。
下图中左侧为HTTP1.1 右侧为HTTP2.0

HTTP 2.0 其实是将三个请求变成三个流,将数据分成帧,乱序发送到一个 TCP 连接中。
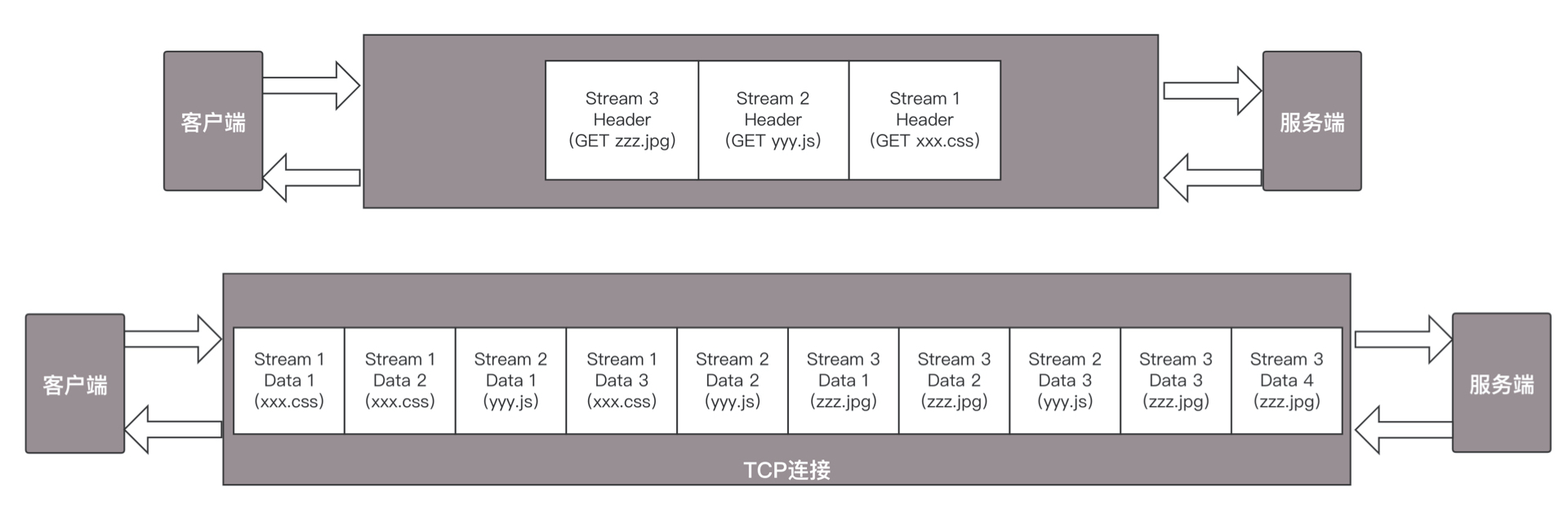
HTTP 2.0 成功解决了 HTTP 1.1 的队首阻塞问题,同时,也不需要通过 HTTP 1.x 的 pipeline 机制用多条 TCP 连接来实现并行请求与响应;减少了 TCP 连接数对服务器性能的影响,同时将页面的多个数据 css、js、 jpg 等通过一个数据链接进行传输,能够加快页面组件的传输速度。
QUIC 协议
HTTP 2.0 虽然大大增加了并发性,但还是有问题的。因为 HTTP 2.0 也是基于 TCP 协议的,TCP 协议在处理包时是有严格顺序的。当其中一个数据包遇到问题,TCP 连接需要等待这个包完成重传之后才能继续进行。虽然 HTTP 2.0 通过多个 stream,使得逻辑上一个 TCP 连接上的并行内容,进行多路数据的传输,然而这中间并没有关联的数据。一前一后,前面 stream 2 的帧没有收到,后面没有关系的 stream 1 的帧也会因此阻塞。于是,就又到了从 TCP 切换到 UDP。这就是 Google 的 QUIC 协议。
QUIC拥有一下机制更适用于HTTP2.0:
机制一:自定义连接机制
我们都知道,一条 TCP 连接是由四元组标识的,{源 IP、源端口、目的 IP、目的端口}。一旦一个元素发生变化时,就需要断开重连,重新连接。在移动互联情况下,当手机信号不稳定或者在 WIFI 和 移动网络切换时,都会导致重连,从而进行再次的三次握手,导致一定的时延。
这在 TCP 是没有办法的,但是基于 UDP,就可以在 QUIC 自己的逻辑里面维护连接的机制,不再以四元组标识,而是以一个 64 位的随机数作为 ID 来标识,而且 UDP 是无连接的,所以当 IP 或者端口变化的时候,只要 ID 不变,就不需要重新建立连接。
机制二:自定义重传机制
TCP 为了保证可靠性,通过使用序号和应答机制,来解决顺序问题和丢包问题。任何一个序号的包发过去,都要在一定的时间内得到应答,否则一旦超时,就会重发这个序号的包。那怎么样才算超时呢?还记得我们提过的自适应重传算法吗?这个超时是通过采样往返时间 RTT 不断调整的。
其实,在 TCP 里面超时的采样存在不准确的问题。例如,发送一个包,序号为 100,发现没有返回,于是再发送一个 100,过一阵返回一个 ACK101。这个时候客户端知道这个包肯定收到了,但是往返时间是多少呢?是 ACK 到达的时间减去后一个 100 发送的时间,还是减去前一个 100 发送的时间呢?事实是,第一种算法把时间算短了,第二种算法把时间算长了。
QUIC 也有个序列号,是递增的。任何一个序列号的包只发送一次,下次就要加一了。例如,发送一个包,序号是 100,发现没有返回;再次发送的时候,序号就是 101 了;如果返回的 ACK 100,就是对第一个包的响应。如果返回 ACK 101 就是对第二个包的响应,RTT 计算相对准确。但是这里有一个问题,就是怎么知道包 100 和包 101 发送的是同样的内容呢?
QUIC 定义了一个 offset 概念。QUIC 既然是面向连接的,也就像 TCP 一样,是一个数据流,发送的数据在这个数据流里面有个偏移量 offset,可以通过 offset 查看数据发送到了哪里,这样只要这个 offset 的包没有来,就要重发;如果来了,按照 offset 拼接,还是能够拼成一个流。
机制三:无阻塞的多路复用
有了自定义的连接和重传机制,我们就可以解决上面 HTTP 2.0 的多路复用问题。同 HTTP 2.0 一样,同一条 QUIC 连接上可以创建多个 stream,来发送多个 HTTP 请求。但是,QUIC 是基于 UDP 的,一个连接上的多个 stream 之间没有依赖。这样,假如 stream2 丢了一个 UDP 包,后面跟着 stream3 的一个 UDP 包,虽然 stream2 的那个包需要重传,但是 stream3 的包无需等待,就可以发给用户。
机制四:自定义流量控制
TCP 的流量控制是通过滑动窗口协议。QUIC 的流量控制也是通过 window_update,来告诉对端它可以接受的字节数。但是 QUIC 的窗口是适应自己的多路复用机制的,不但在一个连接上控制窗口,还在一个连接中的每个 stream 控制窗口。还记得吗?
在 TCP 协议中,接收端的窗口的起始点是下一个要接收并且 ACK 的包,即便后来的包都到了,放在缓存里面,窗口也不能右移,因为 TCP 的 ACK 机制是基于序列号的累计应答,一旦 ACK 了一个序列号,就说明前面的都到了,所以只要前面的没到,后面的到了也不能 ACK,就会导致后面的到了,也有可能超时重传,浪费带宽。
QUIC 的 ACK 是基于 offset 的,每个 offset 的包来了,进了缓存,就可以应答,应答后就不会重发,中间的空档会等待到来或者重发即可,而窗口的起始位置为当前收到的最大 offset,从这个 offset 到当前的 stream 所能容纳的最大缓存,是真正的窗口大小。显然,这样更加准确。
数字证书
证书(Certificate),包含公钥,这是最重要的;还有证书的所有者;另外还有证书的发布机构和证书的有效期。
这个证书是怎么生成的呢?
生成证书需要发起一个证书请求,然后将这个请求发给一个权威机构去认证,这个权威机构我们称为 CA( Certificate Authority)。
证书请求可以通过这个命令生成
openssl req -key xxprivate.key -new -out xxcertificate.req
将这个请求发给权威机构,权威机构会给这个证书卡一个章,我们称为签名算法。怎么签名才能保证是真的权威机构签名的呢?当然只有用只掌握在权威机构手里的东西签名了才行,这就是 CA 的私钥。
签名算法大概是这样工作的:
一般是对信息做一个 Hash 计算,得到一个 Hash 值,这个过程是不可逆的,也就是说无法通过 Hash 值得出原来的信息内容。在把信息发送出去时,把这个 Hash 值加密后,作为一个签名和信息一起发出去。
权威机构给证书签名的命令是这样的。
openssl x509 -req -in xxcertificate.req -CA cacertificate.pem -CAkey caprivate.key -out xxcertificate.pem
这个命令会返回 Signature ok,而 xxcertificate.pem 就是签过名的证书。CA 用自己的私钥给xx网站的公钥签名,就相当于给xx网站背书,形成了xx网站的证书。
我们来查看这个证书的内容。
openssl x509 -in xxcertificate.pem -noout -text
这里面有个 Issuer,证书是谁颁发的;Subject,证书颁发给谁;Validity 证书期限;Public-key 公钥内容;Signature Algorithm 签名算法。
HTTPS 的工作模式

加密分对称加密和非对称加密。对称加密效率高,但是解决不了密钥传输问题;
非对称加密可以解决这个问题,但是效率不高。 非对称加密需要通过证书和权威机构来验证公钥的合法性。
HTTPS 是综合了对称加密和非对称加密算法的 HTTP 协议。既保证传输安全,也保证传输效率。
重放与篡改
有了加密和解密,黑客截获了包也打不开了,但是它可以发送 N 次。这个往往通过 Timestamp 和 Nonce 随机数联合起来,然后做一个不可逆的签名来保证。
Nonce 随机数保证唯一,或者 Timestamp 和 Nonce 合起来保证唯一,同样的,请求只接受一次,于是服务器多次收到相同的 Timestamp 和 Nonce,则视为无效即可。
如果有人想篡改 Timestamp 和 Nonce,还有签名保证不可篡改性,如果改了用签名算法解出来,就对不上了,可以丢弃了。
直播
首先要通过编码压缩内容:
视频和图片的压缩过程有什么特点?之所以能够对视频流中的图片进行压缩,因为视频和图片有这样一些特点。
空间冗余:图像的相邻像素之间有较强的相关性,一张图片相邻像素往往是渐变的,不是突变的,没必要每个像素都完整地保存,可以隔几个保存一个,中间的用算法计算出来。
时间冗余:视频序列的相邻图像之间内容相似。一个视频中连续出现的图片也不是突变的,可以根据已有的图片进行预测和推断。
视觉冗余:人的视觉系统对某些细节不敏感,因此不会每一个细节都注意到,可以允许丢失一些数据。
编码冗余:不同像素值出现的概率不同,概率高的用的字节少,概率低的用的字节多,类似霍夫曼编码(Huffman Coding)的思路。
编码发展过程很复杂但是最终规定使用 H.264/MPEG-4 AVC 编码
直播的传输
网络协议将编码好的视频流,从主播端推送到服务器,在服务器上有个运行了同样协议的服务端来接收这些网络包,从而得到里面的视频流,这个过程称为接流。
服务端接到视频流之后,可以对视频流进行一定的处理,例如转码,也即从一个编码格式,转成另一种格式。因为观众使用的客户端千差万别,要保证他们都能看到直播。
流处理完毕之后,就可以等待观众的客户端来请求这些视频流。观众的客户端请求的过程称为拉流。
如果有非常多的观众,同时看一个视频直播,那都从一个服务器上拉流,压力太大了,因而需要一个视频的分发网络,将视频预先加载到就近的边缘节点,这样大部分观众看的视频,是从边缘节点拉取的,就能降低服务器的压力。
当观众的客户端将视频流拉下来之后,就需要进行解码,也即通过上述过程的逆过程,将一串串看不懂的二进制,再转变成一帧帧生动的图片,在客户端播放出来。

编码:如何将丰富多彩的图片变成二进制流?
I 帧,也称关键帧。里面是完整的图片,只需要本帧数据,就可以完成解码。
P 帧,前向预测编码帧。P 帧表示的是这一帧跟之前的一个关键帧(或 P 帧)的差别,解码时需要用之前缓存的画面,叠加上和本帧定义的差别,生成最终画面。B 帧,双向预测内插编码帧。
B 帧,记录的是本帧与前后帧的差别。要解码 B 帧,不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面的数据与本帧数据的叠加,取得最终的画面。
推流:如何把数据流打包传输到对端?
那这个格式是不是就能够直接在网上传输到对端,开始直播了呢?其实还不是,还需要将这个二进制的流打包成网络包进行发送,这里我们使用 RTMP 协议。这就进入了第二个过程,推流。
RTMP 是基于 TCP 的,因而肯定需要双方建立一个 TCP 的连接。在有 TCP 的连接的基础上,还需要建立一个 RTMP 的连接,也即在程序里面,你需要调用 RTMP 类库的 Connect 函数,显示创建一个连接。

大量观看直播的观众就可以通过 RTMP 协议从流媒体服务器上拉取,为缓解压力,需要有分发网络。分发网络分为中心和边缘两层。
边缘层服务器部署在全国各地及横跨各大运营商里,和用户距离很近。
中心层是流媒体服务集群,负责内容的转发。智能负载均衡系统,根据用户的地理位置信息,就近选择边缘服务器,为用户提供推 / 拉流服务。
中心层也负责转码服务,例如,把 RTMP 协议的码流转换为 HLS 码流。
拉流:观众的客户端如何看到视频?

FTP:文件传输协议
FTP 采用两个 TCP 连接来传输一个文件。
其中一个是控制连接:服务器以被动的方式,打开众所周知用于 FTP 的端口 21,客户端则主动发起连接。该连接将命令从客户端传给服务器,并传回服务器的应答。常用的命令有:list——获取文件目录;reter——取一个文件;store——存一个文件。
另一个是数据连接:每当一个文件在客户端与服务器之间传输时,就创建一个数据连接,每传输一个文件,都要建立一个全新的数据连接。
FTP 的两种工作模式,分别是主动模式(PORT)和被动模式(PASV),这些都是站在 FTP 服务器的角度来说的。
主动模式下,客户端随机打开一个大于 1024 的端口 N,向服务器的命令端口 21 发起连接,同时开放 N+1 端口监听,并向服务器发出 “port N+1” 命令,由服务器从自己的数据端口 20,主动连接到客户端指定的数据端口 N+1。
被动模式下,当开启一个 FTP 连接时,客户端打开两个任意的本地端口 N(大于 1024)和 N+1。第一个端口连接服务器的 21 端口,提交 PASV 命令。
然后,服务器会开启一个任意的端口 P(大于 1024),返回“227 entering passive mode”消息,里面有 FTP 服务器开放的用来进行数据传输的端口。
客户端收到消息取得端口号之后,会通过 N+1 号端口连接服务器的端口 P,然后在两个端口之间进行数据传输。
P2P
peer-to-peer 端对端,资源开始并不集中地存储在某些设备上,而是分散地存储在多台设备上。这些设备我们称为 peer。想要下载一个文件的时候,你只要得到那些已经存在了文件的 peer,并和这些 peer 之间,建立点对点的连接,而不需要到中心服务器上,就可以就近下载文件。一旦下载了文件,你也就成为 peer 中的一员,你旁边的那些机器,也可能会选择从你这里下载文件,所以当你使用 P2P 软件的时候,例如 BitTorrent,往往能够看到,既有下载流量,也有上传的流量,也即你自己也加入了这个 P2P 的网络,自己从别人那里下载,同时也提供给其他人下载。可以想象,这种方式,参与的人越多,下载速度越快,一切完美。
种子(.torrent)文件 解决了怎么知道哪些 peer 有这个文件的问题
.torrent 文件由两部分组成,分别是:announce(tracker URL)和文件信息。
文件信息里面有这些内容。
info 区:这里指定的是该种子有几个文件、文件有多长、目录结构,以及目录和文件的名字。
Name 字段:指定顶层目录名字。每个段的大小:
BitTorrent(简称 BT)协议把一个文件分成很多个小段,然后分段下载。
段哈希值:将整个种子中,每个段的 SHA-1 哈希值拼在一起。
下载时,BT 客户端首先解析.torrent 文件,得到 tracker 地址,然后连接 tracker 服务器。tracker 服务器回应下载者的请求,将其他下载者(包括发布者)的 IP 提供给下载者。下载者再连接其他下载者,根据.torrent 文件,两者分别对方告知自己已经有的块,然后交换对方没有的数据。此时不需要其他服务器参与,并分散了单个线路上的数据流量,因此减轻了服务器的负担。
这种方式特别依赖 tracker。tracker 需要收集下载者信息的服务器,并将此信息提供给其他下载者,使下载者们相互连接起来,传输数据。虽然下载的过程是非中心化的,但是加入这个 P2P 网络的时候,都需要借助 tracker 中心服务器,这个服务器是用来登记有哪些用户在请求哪些资源。
去中心化网络(DHT)
DHT(Distributed Hash Table)的去中心化网络。每个加入这个 DHT 网络的人,都要负责存储这个网络里的资源信息和其他成员的联系信息,相当于所有人一起构成了一个庞大的分布式存储数据库。有一种著名的 DHT 协议,叫 Kademlia 协议。