什么是序列化和反序列化?
序列化是将 Java 对象转换成与平台无关的二进制流,而反序列化则是将二进制流恢复成原来的 Java 对象,二进制流便于保存到磁盘上或者在网络上传输。
如何实现序列化和反序列化
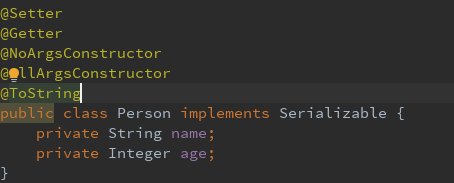
如果想要序列化某个类的对象,就需要让该类实现 Serializable 接口或者 Externalizable 接口。
如果实现 Serializable 接口,由于该接口只是个 “标记接口”,接口中不含任何方法,序列化是使用 ObjectOutputStream(处理流)中的 writeObject(obj) 方法将 Java 对象输出到输出流中,反序列化是使用 ObjectInputStream 中的 readObject(in) 方法将输入流中的 Java 对象还原出来。
下面程序演示实现 Serializable 接口,将对象序列化到文件中,再从文件中反序列化对象。
实现Serializable的序列化和反序列化
Bean类
序列化和反序列化
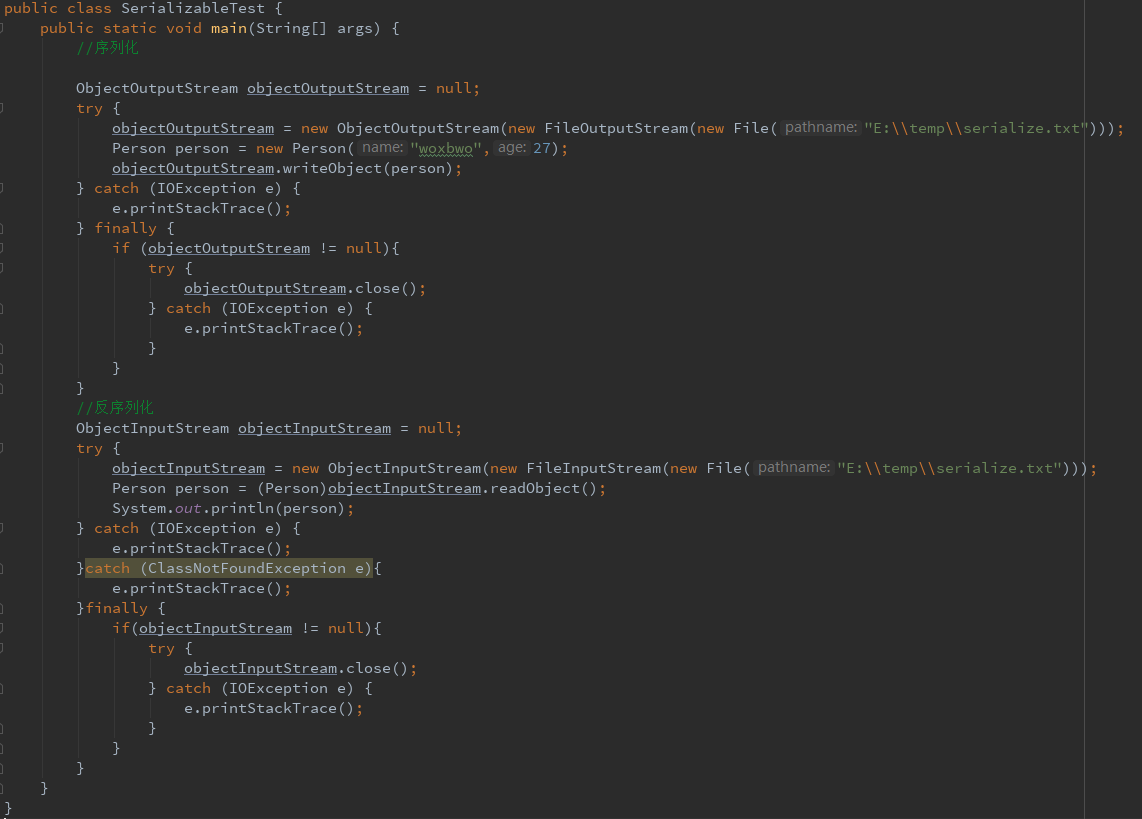
输出结果:Person(name=woxbwo, age=27)
需要注意的是反序列化读取的仅仅是 Java 对象中的数据,而不是包含 Java 类的信息,所以在反序列化时还需要对象所属类的字节码(class)文件,否则会出现 ClassNotFoundException 异常。
实现Externalizable的序列化和反序列化
如果实现 Externalizable接口,该接口继承自 Serializable 接口,在 Java Bean 类中实现接口中的 writeExternal(out) 和 readExternal(in) 方法,需要注意的是必须提供默认的无参构造函数,否则反序列化失败。
Bean类
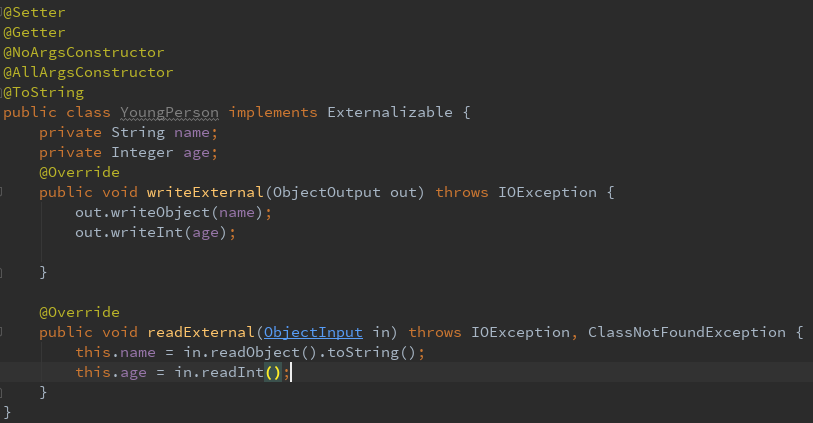
这两种序列化反序列化方式,前一种是使用默认的 Java 实现,而后一种是自定义实现,可以在序列化中选择如何序列化,比如对某个属性加密处理。
其实让类实现 Serializable 接口也是可以实现自定义序列化,只是需要在类中提供下面这三个方法。

writeObject() 方法的作用和上面 writeExternal() 方法类似,readObject() 方法的作用和上面 readExternal() 方法类似,而 readObjectNoData() 方法是在序列化流不完整、序列化和反序列化版本不一致导致不能正确反序列时调用的容错方法。
使用默认的序列化方式,会将对象中的每个实例属性依次进行序列化,如果某个属性是一个类类型,那么需要保证这个类也要是可序列化的类,否则将不能序列化该对象。在 Java 的序列化机制中,被序列化后的对象都有一个编号,多次序列化同一个对象,除了第一次真正序列化对象外,其他都是保存一个序列化编号。这样的机制带来的问题就是如果在序列化一个对象后,修改了对象中的属性,也不会生效。并不是对象中每个属性都需要序列化的,如被 static 修饰的属性是属于类的,而不是只属于某个对象。使用默认序列化方式,是不会将这些属性序列化的,在自定义的序列化方式中,我们也可以将这些属性忽略掉。除此之外,可以使用 transient 关键字来修饰某个属性,这样默认的序列化方式就不会序列化该属性了,自定义还是可以的。如果在反序列化时强行得到这些没有被序列化的值,得到的会是默认值(0 或 null)。
序列化和反序列化的版本问题
在 Java 的序列化机制中,允许给类提供一个 private static final 修饰的 SerialVersionUID 类常量,来作为类版本的代号。这样即使类被修改了(如修改了方法),也会把修改前的类和修改后的类当成同一版本的类,序列化和反序列化照样可以正常使用。如果我们不显式的定义这个 SerialVersionUID,Java 虚拟机会根据类的信息帮我们自动生成,修改前和修改后的计算结果往往不同,造成版本不兼容而发生反序列化失败,另外由于平台的差异性,在程序移植中也可能出现无法反序列化。强大的 IDE 工具,也都有自动生成 SeriaVersionUID 的方法,这里就不多说了。JDK 中自带的也有生成 SeriaVersionUID 值的工具 serialver.exe,使用 serialver 类名(编译后) 命令就能生成该类的 SeriaVersionUID 值啦!
总结
序列化和反序列化的方式可以分为三种,一种是实现 Serializable 接口使用默认的序列化和反序列化方式,一种是实现 Serializable 接口但是自定义序列化和反序列化方法,另外一种是实现 Externalizable 接口,实现接口中的方法。
序列化和反序列化要注意版本问题,自定义序列化和反序列化时还要注意属性的顺序要保持一致,这些都可能会导致反序列化失败。