一、order by产生using filesort详解
1.首先建表和索引(以下使用的sql版本是5.5.54)
/*课程表*/ create table course( id int primary key auto_increment,/* 主键自增*/ title varchar(50) not null,/* 标题*/ category_id int not null,/* 属于哪个类目*/ school_id int not null,/* 属于哪个学校*/ buy_times int not null,/* 购买次数*/ browse_times int not null/* 浏览次数*/ ); insert into course(title,category_id,school_id,buy_times,browse_times) values('java课程',1,1,800,8680); insert into course(title,category_id,school_id,buy_times,browse_times) values('android课程',2,1,400,8030); insert into course(title,category_id,school_id,buy_times,browse_times) values('mysql课程',3,2,200,2902); insert into course(title,category_id,school_id,buy_times,browse_times) values('oracle课程',2,2,100,6710); insert into course(title,category_id,school_id,buy_times,browse_times) values('C#课程',1,3,620,2890); insert into course(title,category_id,school_id,buy_times,browse_times) values('PS课程',4,4,210,4300); insert into course(title,category_id,school_id,buy_times,browse_times) values('CAD课程',5,1,403,6080); /*在category_id和buy_times上建立组合索引*/ create index idx_cate_buy on course(category_id,buy_times);
2.order by 和 group by 会产生 using filesort的有哪些?
(1)explain select id from course where category_id>1 order by category_id;
根据最左前缀原则,order by后面的的category_id会用到组合索引
(2)explain select id from course where category_id>1 order by category_id,buy_times;
根据最左前缀原则,order by后面的的category_id buy_times会用到组合索引,因为索引就是这两个字段
(3)explain select id from course where category_id>1 order by buy_times;
根据最左前缀原则,order by后面的字段是缺少了最左边的category_id,所以会产生 using filesort
(4)explain select id from course where category_id>1 order by buy_times,category_id;
order by后面的字段顺序不符合组合索引中的顺序,所以order by后面的不会走索引,即会产生using filesort
(5)explain select id from course order by category_id;
根据最左前缀原则,order by后面存在索引中的最左列,所以会用到索引
(6)explain select id from course order by buy_times;
根据最左前缀原则,order by后面的字段 没有索引中的最左列的字段,所以不会走索引,会产生using filesort
(7)explain select id from course where buy_times > 1 order by buy_times;
根据最左前缀原则,order by后面的字段 没有索引中的最左列的字段,所以不会走索引,会产生using fillesort
(8)explain select id from course where buy_times > 1 order by category_id;
根据最左前缀原则,order by后面的字段存在于索引中最左列,所以会走索引
(9)explain select id from course order by buy_times desc,category_id asc;
根据最最左前缀原则,order by后面的字段顺序和索引中的不符合,则会产生using filesort
(10)explain select id from course order by category_id desc,buy_times asc;
这一条虽然order by后面的字段和索引中字段顺序相同,但是一个是降序,一个是升序,所以也会产生using filesort,同时升序和同时降序就不会产生using filesort了
总结:终上所述,(3)(4)(6)(7)(9)(10)都会产生using filesort.
二、in和exists哪个性能更优
sql脚本:
/*建库*/ create database testdb6; use testdb6; /* 用户表 */ drop table if exists users; create table users( id int primary key auto_increment, name varchar(20) ); insert into users(name) values ('A'); insert into users(name) values ('B'); insert into users(name) values ('C'); insert into users(name) values ('D'); insert into users(name) values ('E'); insert into users(name) values ('F'); insert into users(name) values ('G'); insert into users(name) values ('H'); insert into users(name) values ('I'); insert into users(name) values ('J'); /* 订单表 */ drop table if exists orders; create table orders( id int primary key auto_increment,/*订单id*/ order_no varchar(20) not null,/*订单编号*/ title varchar(20) not null,/*订单标题*/ goods_num int not null,/*订单数量*/ money decimal(7,4) not null,/*订单金额*/ user_id int not null /*订单所属用户id*/ )engine=myisam default charset=utf8 ; delimiter $$ drop procedure batch_orders $$ /* 存储过程 */ create procedure batch_orders(in max int) begin declare start int default 0; declare i int default 0; set autocommit = 0; while i < max do set i = i + 1; insert into orders(order_no,title,goods_num,money,user_id) values (concat('NCS-',floor(1 + rand()*1000000000000 )),concat('订单title-',i),i%50,(100.0000+(i%50)),i%10); end while; commit; end $$ delimiter ; /*插入1000万条订单数据*/ call batch_orders(10000000); /*插入数据的过程根据机器的性能 花费的时间不同,有的可能3分钟,有的可能10分钟*/
上面的sql中 订单表中(orders) 存在user_id,而又有用户表(users),所以我们用orders表中user_id和user表中的id 来in 和 exists。
结果
1.where后面是小表
(1)select count(1) from orders o where o.user_id in(select u.id from users u);

(2)select count(1) from orders o where exists (select 1 from users u where u.id = o.user_id);

2.where后面是大表
(1)select count(1) from users u where u.id in (select o.user_id from orders o);

(2)select count(1) from users u where exists (select 1 from orders o where o.user_id = u.id);

分析
我们用下面的这两条语句分析:
select count(1) from orders o where o.user_id in(select u.id from users u);
select count(1) from orders o where exists (select 1 from users u where u.id = o.user_id);
1.in:先查询in后面的users表,然后再去orders中过滤,也就是先执行子查询,结果出来后,再遍历主查询,遍历主查询是根据user_id和id相等查询的。
即查询users表相当于外层循环,主查询就是外层循环
小结:in先执行子查询,也就是in()所包含的语句。子查询查询出数据以后,将前面的查询分为n次普通查询(n表示在子查询中返回的数据行数)
2.exists:主查询是内层循环,先查询出orders,查询orders就是外层循环,然后会判断是不是存在order_id和 users表中的id相等,相等才保留数据,查询users表就是内层循环
这里所说的外层循环和内层循环就是我们所说的嵌套循环,而嵌套循环应该遵循“外小内大”的原则,这就好比你复制很多个小文件和复制几个大文件的区别
小结:如果子查询查到数据,就返回布尔值true;如果没有,就返回布尔值false。返回布尔值true则将该条数据保存下来,否则就舍弃掉。也就是说exists查询,是查询出一条数据就执行一次子查询
结论
小表驱动大表。
in适合于外表大而内表小的情况,exists适合于外表小而内表大的情况。
三、慢查询
1.慢查询的用途
它能记录下所有执行超过long_query_time时间的SQL语句,帮我们找到执行慢的SQL,方便我们对这些SQL进行优化。
2.查看是否开启慢查询
show variables like 'slow_query%';
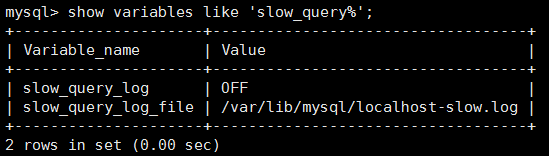
slow_query_log = off,表示没有开启慢查询
slow_query_log_file 表示慢查询日志存放的目录
3.开启慢查询(需要的时候才开启,因为很耗性能,建议使用即时性的)
方式一:(即时性的,重启mysql之后失效,常用的)
set global slow_query_log=1; 或者 set global slow_query_log=ON;
开启之后 我们会发现 /var/lib/mysql下已经存在 localhost-slow.log了,未开启的时候默认是不存在的。
方式二:(永久性的)
在/etc/my.cfg文件中的[mysqld]中加入:
slow_query_log=ON
slow_query_log_file=/var/lib/mysql/localhost-slow.log
4.设置慢查询记录的时间
查询慢查询记录的时间:show variables like 'long_query%',默认是10秒钟,意思是大于10秒才算慢查询。
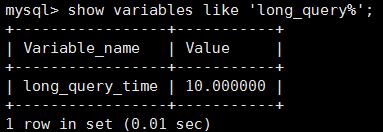
我们现在设置慢查询记录时间为1秒:set long_query_time=1;

5.执行select count(1) from order o where o.user_id in (select u.id where users);
因为我们开启了慢查询,且设置了超过1秒钟的就为慢查询,此sql执行了24秒,所以属于慢查询。
我们在日志中查看:
more /var/lib/mysql/localhost-slow.log,
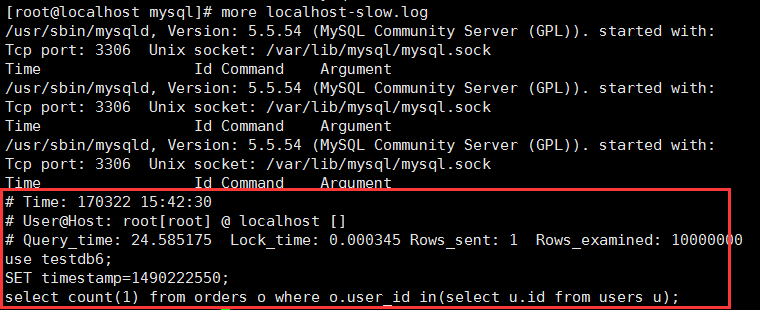
我们可以看到查询的时间,用户,花费的时间,使用的数据库,执行的sql语句等信息。在生产上我们就可以使用这种方式来查看 执行慢的sql。
6.查询慢查询的次数:show status like 'slow_queries';
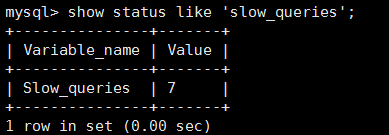
在我们重新执行刚刚的查询sql后,查询慢查询的次数会变为8
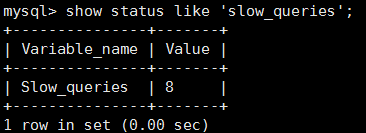
当然,用 more /var/lib/mysql/localhost-slow.log 也是可以看到详细结果的。
在生产中,我们会分析查询频率高的,且是慢查询的sql,并不是每一条查询慢的sql都需要分析。
7.慢查询日志分析工具Mysqldumpslow
由于在生产上会有很多慢查询,所以采用上述的方法查看慢查询sql会很麻烦,还好MySQL提供了慢查询日志分析工具Mysqldumpslow。
其功能是, 统计不同慢sql的出现次数(Count),执行最长时间(Time),累计总耗费时间(Time),等待锁的时间(Lock),发送给客户端的行总数(Rows),扫描的行总数(Rows)
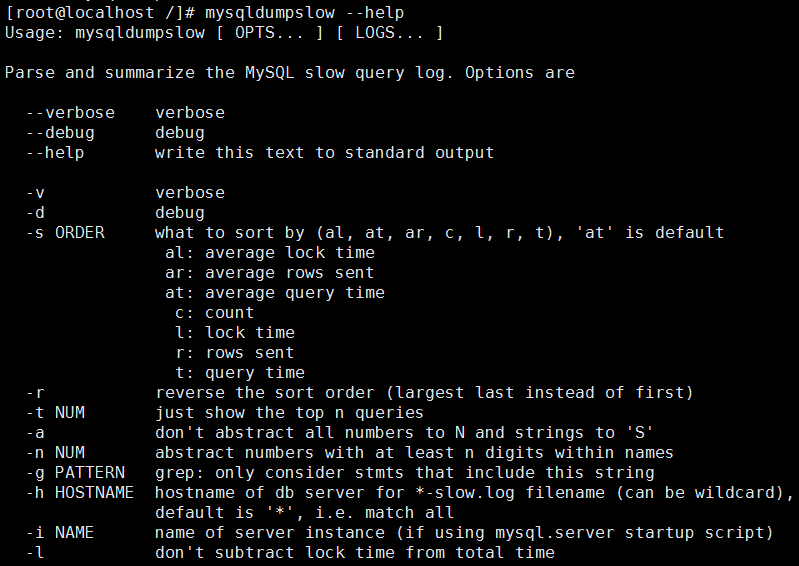
(1)查询Mysqldumpslow的帮助信息,随便进入一个文件夹下,执行:mysqldumpslow --help
查看mysqldumpslow命令安装在哪个目录:whereis mysqldumpslow
说明:
-s,是order的顺序,主要有c(按query次数排序)、t(按查询时间排序)、l(按lock的时间排序)、r (按返回的记录数排序)和 at、al、ar,前面加了a的代表平均数
-t,是top n的意思,即为返回前面多少条的数据
-g,后边可以写一个正则匹配模式,大小写不敏感的
-r:倒序
(2)案例:取出耗时最长的两条sql
格式:mysqldumpslow -s t -t 2 慢日志文件
mysqldumpslow -s t -t 2 /var/lib/mysql/localhost-slow.log

参数分析:
出现次数(Count),
执行最长时间(Time),
累计总耗费时间(Time),
等待锁的时间(Lock),
发送给客户端的行总数(Rows),
扫描的行总数(Rows),
用户以及sql语句本身(抽象了一下格式, 比如 limit 1, 20 用 limit N,N 表示).
(3)案例:取出查询次数最多,且使用了in关键字的1条sql
mysqldumpslow -s c -t 1 -g 'in' /var/lib/mysql/localhost-slow.log

这种方式更加方便,更加快捷!
8.show profile
用途:用于分析当前会话中语句执行的资源消耗情况
(1)查看是否开启profile,mysql默认是不开启的,因为开启很耗性能
show variables like 'profiling%';

(2)开启profile(会话级别的,关闭当前会话就会恢复原来的关闭状态)
set profiling=1; 或者 set profiling=ON;
(3)关闭profile
set profiling=0; 或者 set profiling=OFF;
(4)显示当前执行的语句和时间
show profiles;

(5)显示当前查询语句执行的时间和系统资源消耗
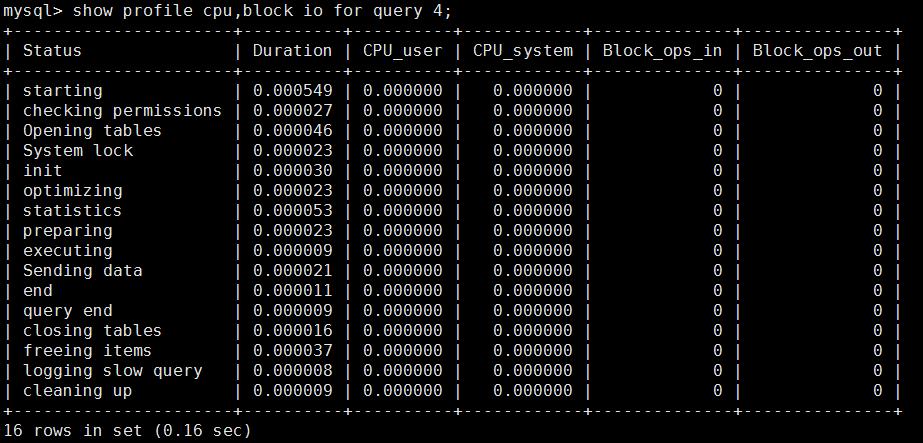
show profile cpu,block io for query 4;(分析show profiles中query_id等于4的sql所占的CPU资源和IO操作)
或者直接 : show profile for query 4;