声明:
1)仅作为个人学习,如有冒犯,告知速删!
2)不想误导,如有错误,不吝指教!
-
简介
------------------文件存储------------------
-
TXT文本存储
-
JSON文件存储
-
CSV文件存储
------------------关系型数据库---------------
-
MySQL存储
------------------非关系数据库---------------
-
Mongodb
-
redis
一 简单介绍:
我们前面很少将提取的数据或者获取的源码保存下来;其实日常的工作中在解析出数据后接下来就是存储数据。
保存数据的形式有多种多样txtjsoncsvmysqlmobgodb
edis,接下来我们一一介绍。
1). txt文本存储:
python txt文件操作中离不开open()函数,它可以创建或者打开指定的文件,并创建一个文件对象 ,基本的语法:
1 open() 函数用于创建或打开指定文件,该函数的语法格式如下:
2 file = open(file_name,"文件打开方式")
文件打开的方式有以下几种:
| 模式 | 意义 | 注意事项 |
|---|---|---|
| r | 只读模式打开文件,读文件内容的指针会放在文件的开头。 | 操作的文件必须存在。 |
| rb | 以二进制格式、采用只读模式打开文件,读文件内容的指针位于文件的开头,一般用于非文本文件,如图片文件、音频文件等。 | |
| r+ | 打开文件后,既可以从头读取文件内容,也可以从开头向文件中写入新的内容,写入的新内容会覆盖文件中等长度的原有内容。 | |
| rb+ | 以二进制格式、采用读写模式打开文件,读写文件的指针会放在文件的开头,通常针对非文本文件(如音频文件)。 | |
| w | 以只写模式打开文件,若该文件存在,打开时会清空文件中原有的内容。 | 若文件存在,会清空其原有内容(覆盖文件);反之,则创建新文件。 |
| wb | 以二进制格式、只写模式打开文件,一般用于非文本文件(如音频文件) | |
| w+ | 打开文件后,会对原有内容进行清空,并对该文件有读写权限。 | |
| wb+ | 以二进制格式、读写模式打开文件,一般用于非文本文件 | |
| a | 以追加模式打开一个文件,对文件只有写入权限,如果文件已经存在,文件指针将放在文件的末尾(即新写入内容会位于已有内容之后);反之,则会创建新文件。 | |
| ab | 以二进制格式打开文件,并采用追加模式,对文件只有写权限。如果该文件已存在,文件指针位于文件末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 | |
| a+ | 以读写模式打开文件;如果文件存在,文件指针放在文件的末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 | |
| ab+ | 以二进制模式打开文件,并采用追加模式,对文件具有读写权限,如果文件存在,则文件指针位于文件的末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 |
熟悉/了解上面的知识点后(详细信息:菜鸟教程/w3school),我们实例一下;
小说网站:https://xs.sogou.com/mianfei/ 获取书名、简洁并保存为txt文件:
1 import requests
2 import json
3 #设置ua
4 headers = {
5 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3941.4 Safari/537.36",
6 }
7 #获取网页源代码
8 r = requests.get("https://xs.sogou.com/api/pc/v1/activity/freeread/current?pageNo=1&pageSize=12",headers=headers).text
9 #json格式一下
10 html = json.loads(r)
11 #接下来就是获取数据
12 name = html["data"]["pageList"]
13 for i in name:
14 bookName = i["bookName"]
15 content = i["description"]
16 #写入数据
17 with open("小说.txt","a",encoding="utf-8") as f:
18 f.write(bookName)
19 f.write(content)
20 f.write("
"+ "==" * 20 + "
")
21 print("已写入......")
22 with as的方式实现数据存储好处:不需要调用close()方法
23 以上写入还可以使用:
24 file = open("小说.txt","a",encoding="utf-8" )
25 file.write(bookName)
26 file.write(content)
27 file.write("
"+ "==" * 20 + "
")
28 print("已写入......")
29 最后结果都是一样的
注:有细心的同学发现我用的url跟网站的url是不一样的,这个是怎么回事??
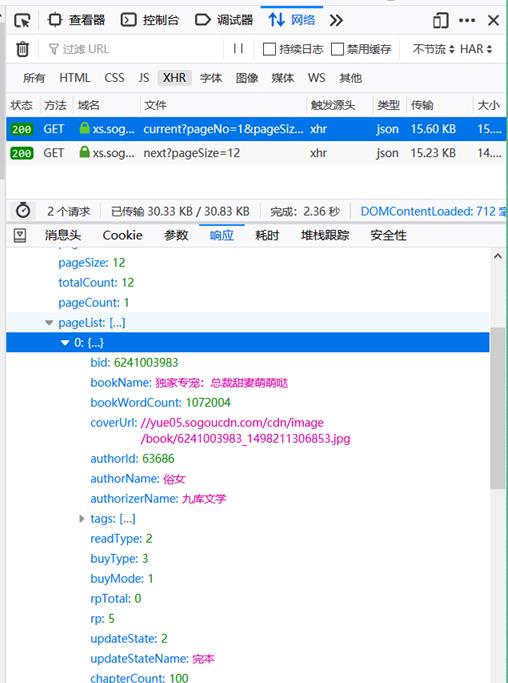
这样我们直接请求这个网址后得到的就是一个json的数据文件,之后我们解析一下就可以了。
2). JSON文件存储:
先官方话了解一下: JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于ECMAScript的一个子集。
JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C、C++、Java、JavaScript、Perl、Python等)。
这些特性使JSON成为理想的数据交换语言。易于人阅读和编写,同时也易于机器解析和生成(一般用于提升网络传输速率)。
你读一遍的话会懵逼的,不要慌,你暂时不要管,学习它常用的:
json: 用于字符串和python数据类型间进行转换 ,它提供四个功能 dumps、dump、loads、load ,用的比较多的是(loads,dumps)下面我们学习下。
loads():将JSON文本字符串转换成JSON对象;
dumps():将JSON对象转换成JSON文本字符串;
1 #在我们上面的小说例子中,我们使用的就是loads()
2 import json
3
4 test_dict = {'bigberg': [7600, {1: [['iPhone', 6300], ['Bike', 800], ['shirt', 300]]}]}
5 print(test_dict)
6 print(type(test_dict))
7 #dumps 将数据转换成字符串
8 json_str = json.dumps(test_dict)
9 print(json_str)
10 print(type(json_str))
11 #loads: 将字符串转换为字典
12 new_dict = json.loads(json_str)
13 print(new_dict)
14 print(type(new_dict))
dump: 将数据写入json文件中 ; load:把文件打开,并把字符串变换为数据类型 ;有兴趣的同学可以学习一下用法。
3). CSV文件存储:
使用csv文件存储,我理解的就是表格存储,Excel都用过吧,就是那个;接下来我们分文件的写入跟读取两部分分开讲解,请系好安全带(如果非要介绍定义的话,请百度......我就是懒);
简单写入,首先打开一个csv文件,指定打开的模式然后使用write()方法初始化写入对象,最后调用writerow()方法传入每行的数据即可,代码如下:
1 import csv
2 #如果不加newline参数的话,会自动这只每行换行,如下图所示
3 #加上以后就不会出现下图的问题,小技巧,你值得拥有
4 with open("name.csv","w",newline="") as f:
5 writer = csv.writer(f)
6 #传入的是一个列表
7 writer.writerow(["num","name","age","sex"])
8 writer.writerow(["100","你",12,"男"])
9 writer.writerow(["101","好",13,"女"])
效果图如下:
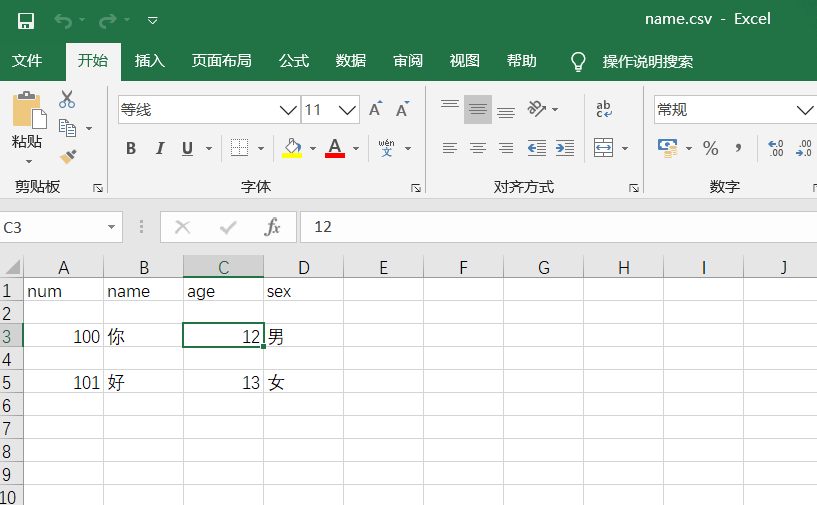
可以看到还有排版的问题,更多的功能等你发掘;
简单读取:我们需要构造reader对象,通过遍历的方式输出每行的信息;代码及效果图如下:
1 import csv
2
3 with open("name.csv",'r') as f:
4 reader = csv.reader(f)
5 for i in reader:
6 print(i)
7
8 #接触到pandas的话你会了解到read_csv()方法:
9 import pandas as pd
10 df = read_csv("name.csv")
11 print(df)
这个要比第一个方式舒服很多。。。。。

------------------------------------分隔符---------------------------------
-
-
DML(数据操作语言)------>对表中的记录操作增删改查 -
DQL(数据查询语言)------>对表中的查询操作 -
DCL(数据控制语言)------>对用户权限的设置
一:DDl:
创建:
-
create database 数据库名;
-
create database 数据库名 if not exits;
-
create database 数据库名 character set 字符集;
-
show databases;
-
select create database 数据库名;
修改:
alter database 数据库名 default character set 字符集;
删除:
drop database 数据库名;
使用数据库:
select database(); ----->查看正在使用的数据库
use 数据库名;------->使用/切换数据库
DDL表操作:
create table 表名(字段1,字段类型,字段2,字段类型);创建表
intdoublevarchardate
查:
show tables;---->查看当前数据库中所有表
desc 表名; ----->查看表的结构
show create table 表名;---->查看创建表的sql语句
创建:
create table 新表名 like 就表名; ---->快速创建一个与就旧表结构相同的的新表
删除:
drop table 表名;----->直接删除
drop table if exists 表名;----->判断是否存在
改:
alter table 表名 add 列名 类型;----->添加表列 add
alter table 表名 modify 列名 新类型;------>添加列类型modify
alter table 表名 change 旧列 新列 类型;----->修改列名change
alter table 表名 drop 列名;----->删除列
rename table 旧表 to 新表;----->修改表名
alter table 表名 character set 字符集;
二:DML
插入:
insert into 表名 (字段1,字段2.....) values(值1,值2......);----->插入全部字段
insert into 表名 values(值1,值2.....); ----->不写字段名
insert into 表名 ( 字段1,2,3) values (值1,2,3); ----插入部分
select * from 表名;---->查表中信息
蠕虫复制:
insert into 表1 select * from 表2 ;---->将表2中的所有列复制到表1中
insert into 表1 (列1,列2) select (列1,列2)from 表2;--->只复制部分列
更新:
update 表名(需更新) set 列名=值 [where 条件表达式];
update 表名 set 列名=值;
update 表名 set 列名=值 where 列名=值;
删:
delete from 表名 [where 条件表达式];
delete from 表名;删除全部数据
delete from 表名 where 字段(列) = 值;
truncate table 表名;----删除整个表的所有记录重建新表
查:
select 列名 from 表名;
select * from 表名:
select 列1,列2 from 表名;
清楚重复值: