正则表达式做关联:
找到要关联的点在响应数据的位置:
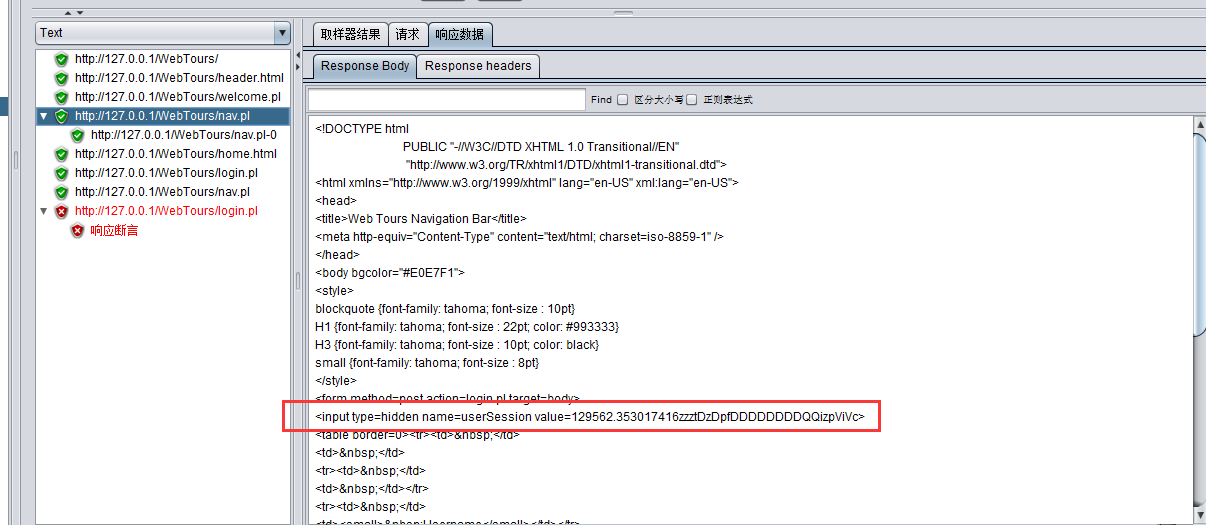
在这个请求添加后置处理,正则表达式提取器:

在下游接口添加参数依赖:

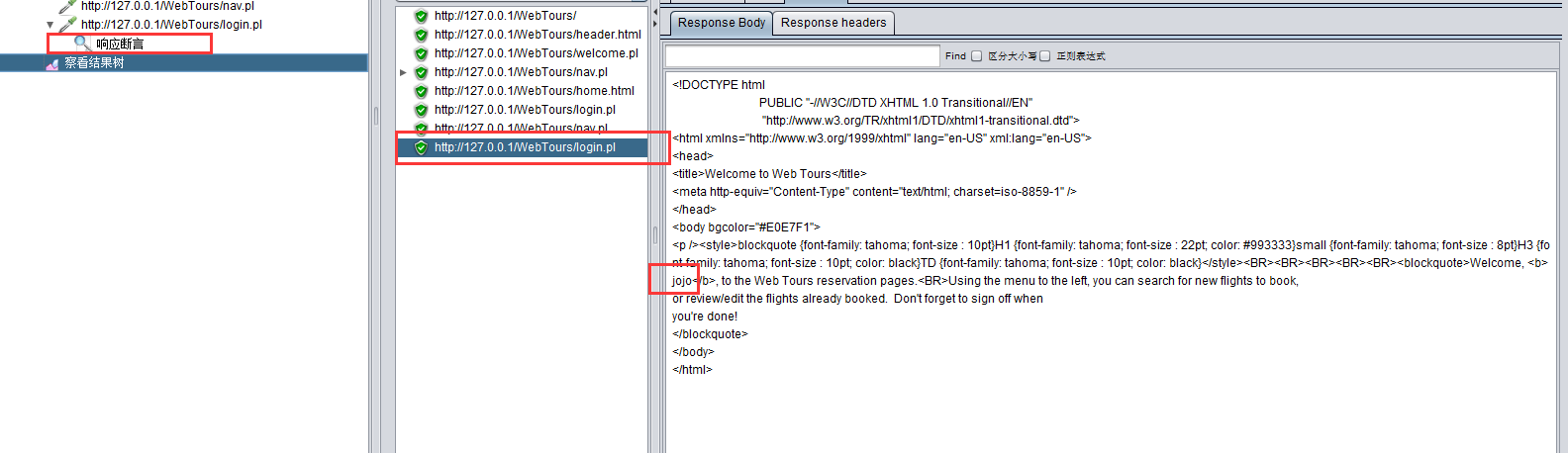
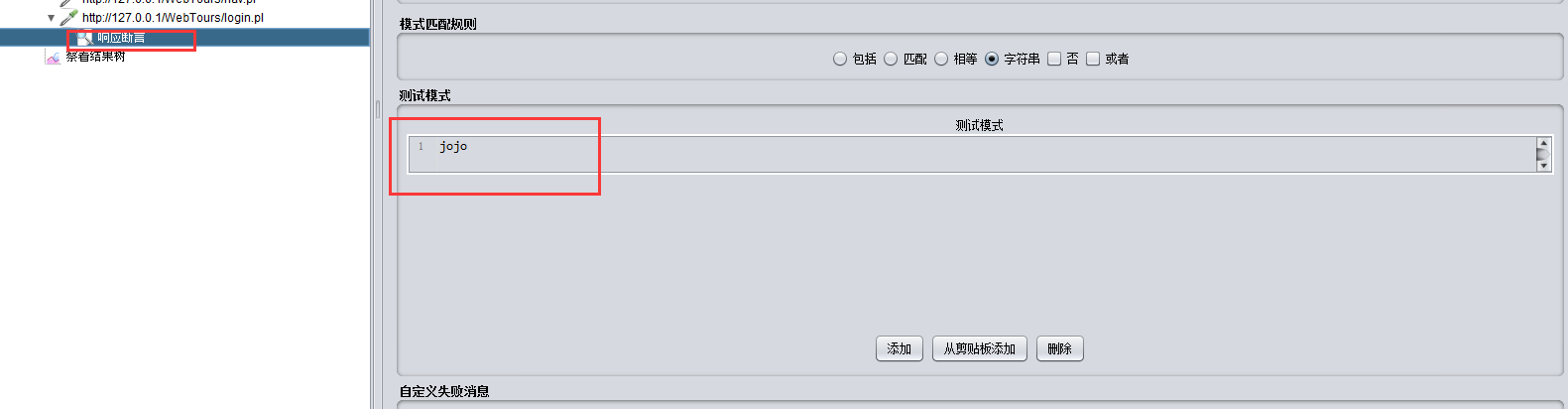
在有返回登录成功标准的请求里添加响应断言:
传入数据参数化:
添加csv数据文件:
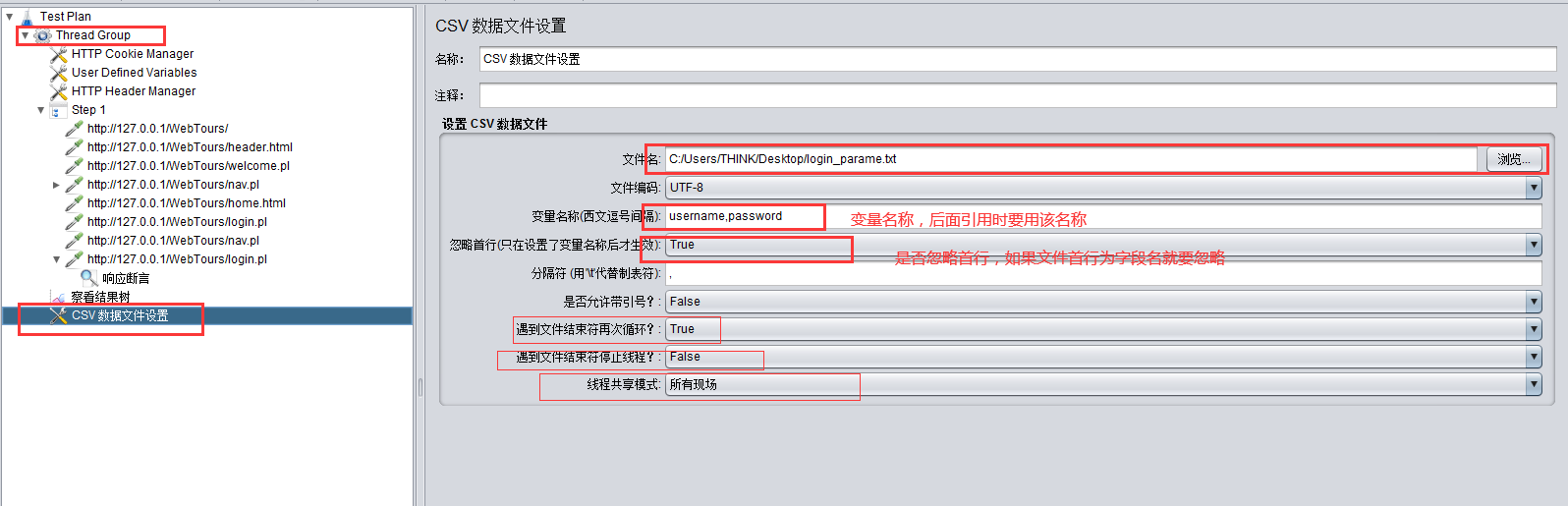
线程数和文件结束是否循环是有关联的,比如线程数大于文件内的记录数,此时设置为文件结束就不再循环,并停止线程,那它只会运行记录数的线程数;如果设置为不停止线程,那它就会执行指定线程数,但由于设置了文件结束不再循环,没有参数的线程会出错。
在下游接口输入参数名称:

设置运行线程数:(ramp_up启动所有用户花费时间)
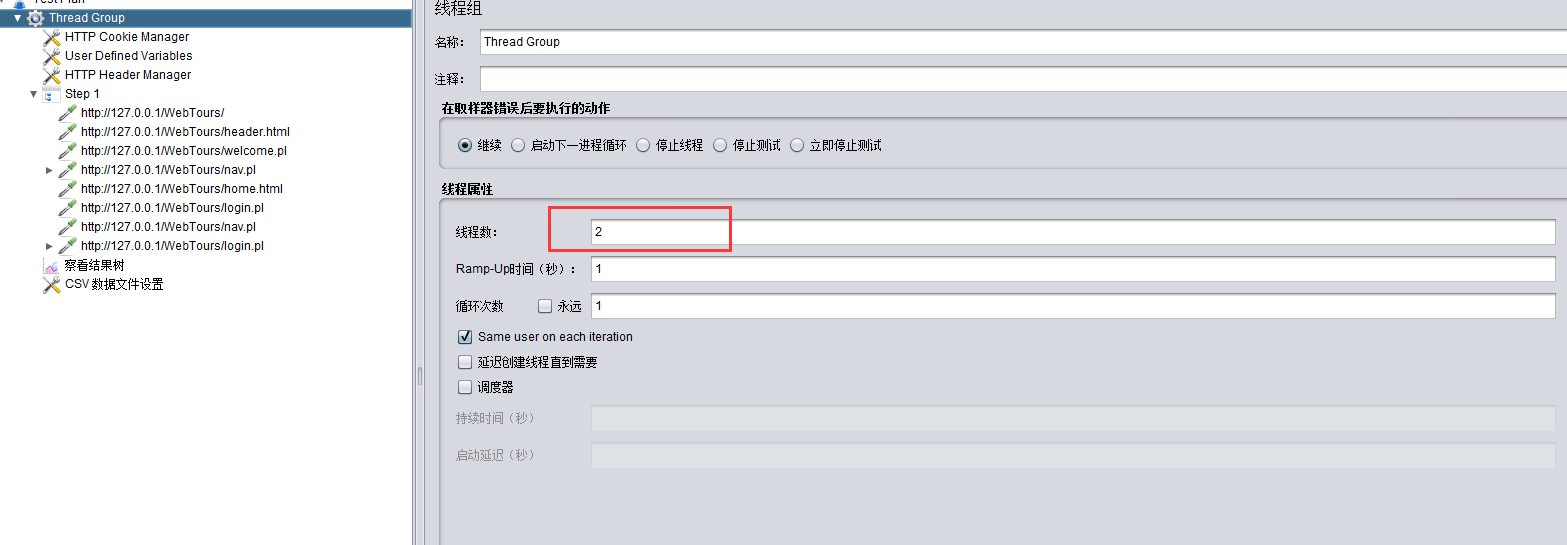
查看运行结果,结果是运行了两个线程,每次从文件提取一条记录,但是两个线程的请求执行时是随机的,不可预测:
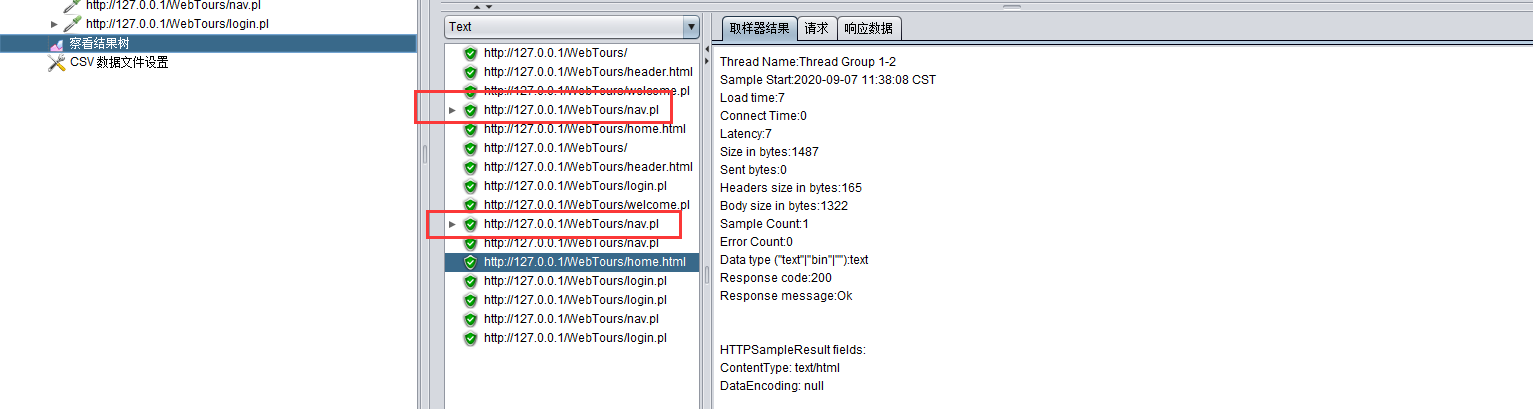
添加集合点,这里叫同步计时器,凑够多少用户才开始事务:
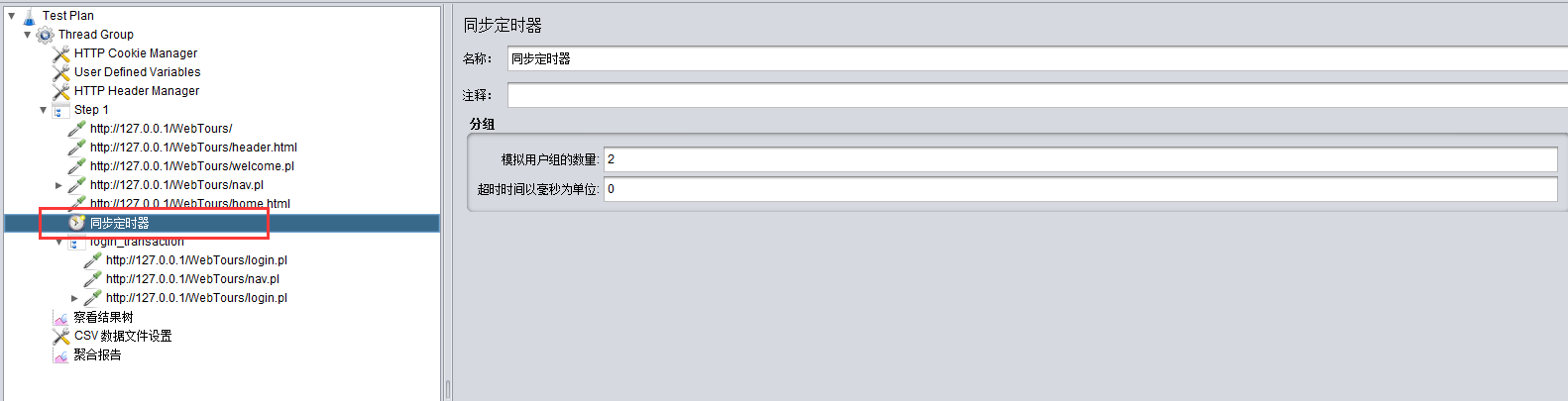
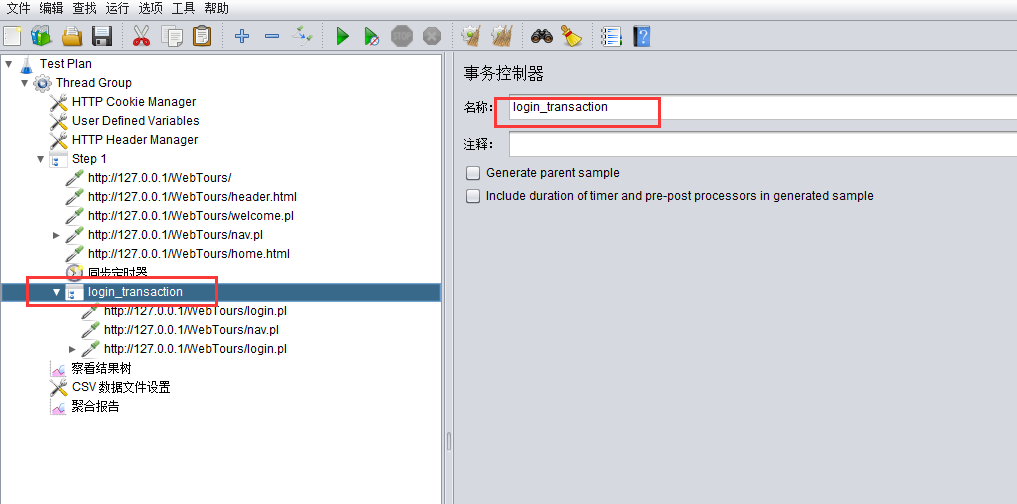
添加事务,在badboy中查看那几个请求属于一个事务,然后添加事务控制器,把这几个请求拖动到事务里:

给线程组添加测试报告,这个报告要比LR的low一点:
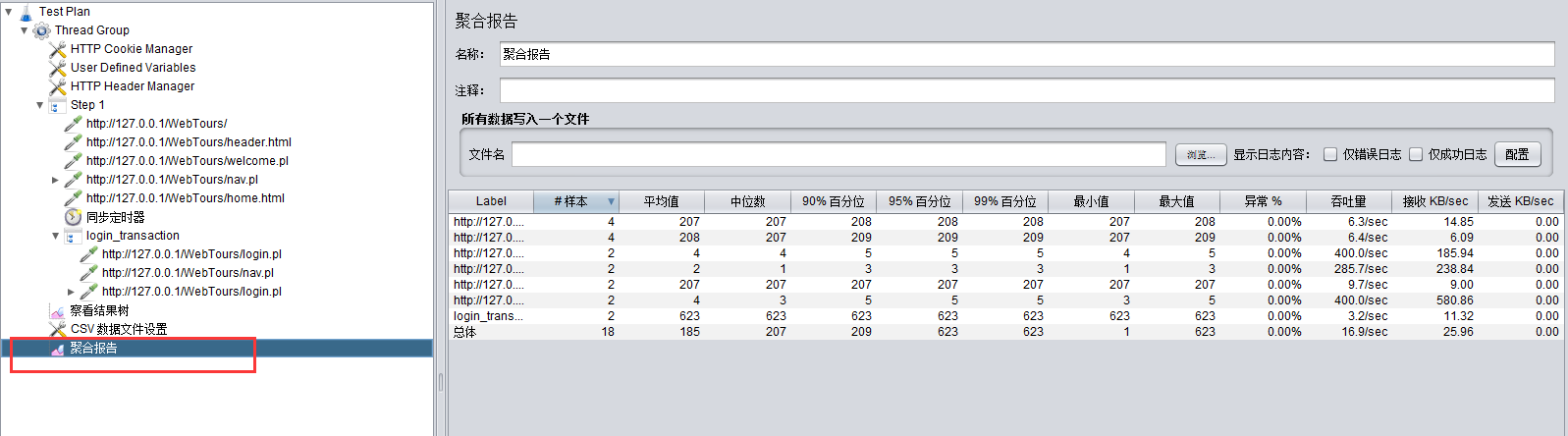
jmeter中线程是并行运行的,但线程里的请求时顺序运行的,如果两个线程的请求相同,那么两个线程之间相同请求会在同一时间并发(谁先谁后就随机了),请求总体会顺序执行,从结果来看就是整体顺序,局部乱序。