一、面向过程和面向对象
面向过程:
核心是"过程"二字
过程的终极奥义就是将程序流程化
过程是"流水线",用来**分步骤解决问题**的
面向对象:
核心是"对象"二字
对象的终极奥义就是将程序"整合"
对象是"容器",用来盛放数据与功能的
类也是"容器",该容器用来存放同类对象共有的数据与功能
二 、什么是面向对象的程序设计及为什么要有它
面向过程的程序设计:
核心是过程二字,过程指的是解决问题的步骤,即先干什么再干什么......面向过程的设计就好比精心设计好一条流水线,是一种机械式的思维方式。
优点:
复杂度的问题流程化,进而简单化(一个复杂的问题,分成一个个小的步骤去实现,实现小的步骤将会非常简单)
缺点:
一套流水线或者流程就是用来解决一个问题,生产汽水的流水线无法生产汽车,即便是能,也得是大改,改一个组件,牵一发而动全身。
应用场景:
一旦完成基本很少改变的场景,著名的例子有Linux內核,git,以及Apache HTTP Server等。
面向对象的程序设计:
核心是对象二字,,对象是特征与技能的结合体,基于面向对象设计程序就好比在创造一个世界,你就是这个世界的上帝,存在的皆为对象,不存在的也可以创造出来,与面向过程机械式的思维方式形成鲜明对比,面向对象更加注重对现实世界的模拟,是一种“上帝式”的思维方式。
优点:
解决了程序的扩展性。对某一个对象单独修改,会立刻反映到整个体系中,如对游戏中一个人物参数的特征和技能修改都很容易。
缺点:
-
编程的复杂度远高于面向过程,不了解面向对象而立即上手基于它设计程序,极容易出现过度设计的问题。一些扩展性要求低的场景使用面向对象会徒增编程难度,比如管理linux系统的shell脚本就不适合用面向对象去设计,面向过程反而更加适合。
-
无法向面向过程的程序设计流水线式的可以很精准的预测问题的处理流程与结果,面向对象的程序一旦开始就由对象之间的交互解决问题,即便是上帝也无法准确地预测最终结果。于是我们经常看到对战类游戏,新增一个游戏人物,在对战的过程中极容易出现阴霸的技能,一刀砍死3个人,这种情况是无法准确预知的,只有对象之间交互才能准确地知道最终的结果。
应用场景:
需求经常变化的软件,一般需求的变化都集中在用户层,互联网应用,企业内部软件,游戏等都是面向对象的程序设计大显身手的好地方

代码实例
# 学生的功能
def tell_stu_info(stu_obj):
print('学生信息:名字:%s 年龄:%s 性别:%s' %(
stu_obj['stu_name'],
stu_obj['stu_age'],
stu_obj['stu_gender']
))
def set_info(stu_obj,x,y,z):
stu_obj['stu_name']=x
stu_obj['stu_age']=y
stu_obj['stu_gender']=z
stu_obj={
'stu_school':'oldboy',
'stu_name':'egon',
'stu_age':18,
'stu_gender':'male',
'tell_stu_info': tell_stu_info,
'set_info':set_info
}
stu1_obj={
'stu_school':'oldboy',
'stu_name':'lili',
'stu_age':19,
'stu_gender':'female',
'tell_stu_info': tell_stu_info,
'set_info':set_info
}
三 类与对象
类即类别/种类,是面向对象分析和设计的基石,如果多个对象有相似的数据与功能,那么该多个对象就属于同一种类。有了类的好处是:我们可以把同一类对象相同的数据与功能存放到类里,而无需每个对象都重复存一份,这样每个对象里只需存自己独有的数据即可,极大地节省了空间。所以,如果说对象是用来存放数据与功能的容器,那么类则是用来存放多个对象相同的数据与功能的容器。
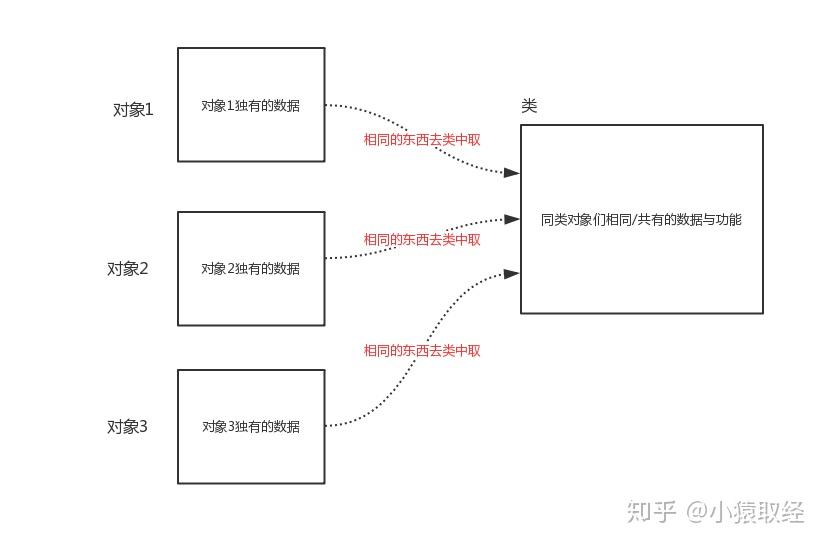
综上所述,虽然我们是先介绍对象后介绍类,但是需要强调的是:在程序中,必须要事先定义类,然后再调用类产生对象(调用类拿到的返回值就是对象)。产生对象的类与对象之间存在关联,这种关联指的是:对象可以访问到类中共有的数据与功能,所以类中的内容仍然是属于对象的,类只不过是一种节省空间、减少代码冗余的机制,面向对象编程最终的核心仍然是去使用对象。
四 面向对象编程
类的定义与实例化
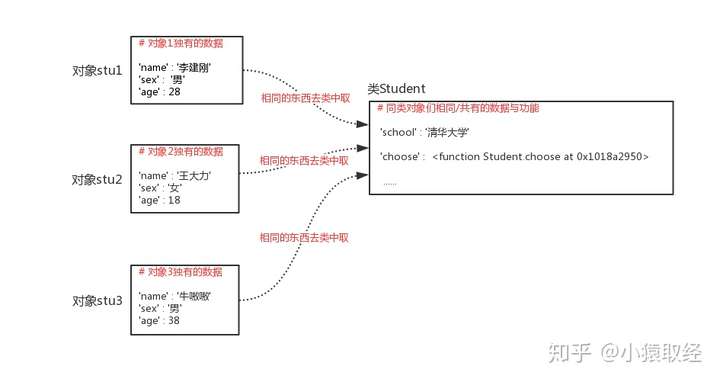
面向对象的基本思路就是把程序中要用到的、相关联的数据与功能整合到对象里,然后再去使用,但程序中要用到的数据以及功能那么多,如何找到相关连的呢?我需要先提取选课系统里的角色:学生、老师、课程等,然后显而易见的是:学生有学生相关的数据于功能,老师有老师相关的数据与功能,我们单以学生为例,
# 学生1:
数据:
学校=清华大学
姓名=李建刚
性别=男
年龄=28
功能:
选课
# 学生2:
数据:
学校=清华大学
姓名=王大力
性别=女
年龄=18
功能:
选课
# 学生3:
数据:
学校=清华大学
姓名=牛嗷嗷
性别=男
年龄=38
功能:
选课
我们可以总结出一个学生类,用来存放学生们相同的数据与功能
# 学生类
相同的特征:
学校=清华大学
相同的功能:
选课
基于上述分析的结果,我们接下来需要做的就是在程序中定义出类,然后调用类产生对象
类体最常见的是变量的定义和函数的定义,但其实类体可以包含任意Python代码,类体的代码在类定义阶段就会执行,因而会产生新的名称空间用来存放类中定义的名字,可以打印Student.__dict__来查看类这个容器内盛放的东西
>>> print(Student.__dict__)
{..., 'school': '清华大学', 'choose': <function Student.choose at 0x1018a2950>, ...}
调用类的过程称为将类实例化,拿到的返回值就是程序中的对象,或称为一个实例
>>> stu1=Student() # 每实例化一次Student类就得到一个学生对象
>>> stu2=Student()
>>> stu3=Student()
如此stu1、stu2、stu3全都一样了(只有类中共有的内容,而没有各自独有的数据),想在实例化的过程中就为三位学生定制各自独有的数据:姓名,性别,年龄,需要我们在类内部新增一个__init__方法,如下
class Student:
school='清华大学'
#该方法会在对象产生之后自动执行,专门为对象进行初始化操作,可以有任意代码,但一定不能返回非None的值
def __init__(self,name,sex,age):
self.name=name
self.sex=sex
self.age=age
def choose(self):
print('%s is choosing a course' %self.name)
然后我们重新实例出三位学生
>>> stu1=Student('李建刚','男',28)
>>> stu2=Student('王大力','女',18)
>>> stu3=Student('牛嗷嗷','男',38)
单拿stu1的产生过程来分析,调用类会先产生一个空对象stu1,然后将stu1连同调用类时括号内的参数一起传给Student.init(stu1,’李建刚’,’男’,28)
def __init__(self, name, sex, age):
self.name = name # stu1.name = '李建刚'
self.sex = sex # stu1.sex = '男'
self.age = age # stu1.age = 28
会产生对象的名称空间,同样可以用__dict__查看
>>> stu1.__dict__
{'name': '李建刚', 'sex': '男', 'age': 28}
至此,我们造出了三个对象与一个类,对象存放各自独有的数据,类中存放对象们共有的内容
五 属性查找
类有两种属性:数据属性和函数属性
-
类的数据属性是所有对象共享的
-
类的函数属性是绑定给对象用的
#类的数据属性是所有对象共享的,id都一样
print(id(OldboyStudent.school))
print(id(s1.school))
print(id(s2.school))
print(id(s3.school))
'''
4377347328
4377347328
'''
#类的函数属性是绑定给对象使用的,obj.method称为绑定方法,内存地址都不一样
#ps:id是python的实现机制,并不能真实反映内存地址,如果有内存地址,还是以内存地址为准
print(OldboyStudent.learn)
print(s1.learn)
print(s2.learn)
print(s3.learn)
'''
<function OldboyStudent.learn at 0x1021329d8>
<bound method OldboyStudent.learn of <__main__.OldboyStudent object at 0x1021466d8>>
<bound method OldboyStudent.learn of <__main__.OldboyStudent object at 0x102146710>>
<bound method OldboyStudent.learn of <__main__.OldboyStudent object at 0x102146748>>
'''

六、:封装
封装:面向对象三大特征 最核心 的一个特性
封装 <=> 整合
1:将封装的属性进行隐藏操作
1.如何隐藏:在属性名前加__前缀,就会实现一个对外隐藏属性效果**
该隐藏需要注意的问题:
I:在类外部无法直接访问双下滑线开头的属性,但知道了类名和属性名就可以拼出名字:_类名__属性,然后就可以访问了,如Foo._A__N,所以说这种操作并没有严格意义上地限制外部访问,仅仅只是一种语法意义上的变形。
class Foo:
__x = 1 # _Foo__x
def __f1(self): # _Foo__f1
print('from test')
print(Foo.__dict__) # {'__module__': '__main__', '_Foo__x': 1, '_Foo__f1': <function Foo.__f1 at 0x00C683D0>, '__dict__': <attribute '__dict__' of 'Foo' objects>, '__weakref__': <attribute '__weakref__' of 'Foo' objects>, '__doc__': None}
print(Foo._Foo__x) # 1
print(Foo._Foo__f1) # <function Foo.__f1 at 0x00C683D0>
这种隐藏对外不对内,因为__开头的属性会在检查类体代码语法时统一发生变形
class Foo:
__x = 1 # _Foo__x = 1
def __f1(self): # _Foo__f1
print('from test')
def f2(self):
print(self.__x) # print(self._Foo__x)
print(self.__f1) # print(self._Foo__f1)
# print(Foo.__x) # AttributeError: type object 'Foo' has no attribute '__x'
# print(Foo.__f1) # AttributeError: type object 'Foo' has no attribute '__f1'
obj=Foo() # 1
obj.f2() # <bound method Foo.__f1 of <__main__.Foo object at 0x0143B070>>
class Foo:
__x = 1 # _Foo__x = 1
def __f1(self): # _Foo__f1
print('from test')
def f2(self):
print(self.__x) # print(self._Foo__x)
print(self.__f1) # print(self._Foo__f1)
Foo.__y=3
print(Foo.__dict__) # {'__module__': '__main__', '_Foo__x': 1, '_Foo__f1': <function Foo.__f1 at 0x033A8418>, 'f2': <function Foo.f2 at 0x033A83D0>, '__dict__': <attribute '__dict__' of 'Foo' objects>, '__weakref__': <attribute '__weakref__' of 'Foo' objects>, '__doc__': None, '__y': 3}
print(Foo.__y) # {'__module__': '__main__', '_Foo__x': 1, '_Foo__f1': <function Foo.__f1 at 0x033A8418>, 'f2': <function Foo.f2 at 0x033A83D0>, '__dict__': <attribute '__dict__' of 'Foo' objects>, '__weakref__': <attribute '__weakref__' of 'Foo' objects>, '__doc__': None, '__y': 3}
class Foo:
__x = 1 # _Foo__x = 1
def __init__(self, name, age):
self.__name = name
self.__age = age
obj = Foo('egon', 18)
print(obj.__dict__) # {'_Foo__name': 'egon', '_Foo__age': 18}
# print(obj.name, obj.age) # AttributeError: 'Foo' object has no attribute 'name'
2.为何要隐藏
隐藏数据属性"将数据隐藏起来就限制了类外部对数据的直接操作,然后类内应该提供相应的接口来允许类外部间接地操作数据,接口之上可以附加额外的逻辑来对数据的操作进行严格地控制:
# 设计者:egon
class People:
def __init__(self, name):
self.__name = name
def get_name(self):
# 通过该接口就可以间接地访问到名字属性
# print('小垃圾,不让看')
print(self.__name)
def set_name(self,val):
if type(val) is not str:
print('小垃圾,必须传字符串类型')
return
self.__name=val
# 使用者:王鹏
obj = People('egon')
# print(obj.name) # 无法直接用名字属性
# obj.set_name('EGON')
obj.set_name(123123123)
obj.get_name()
# II、隐藏函数/方法属性:目的的是为了隔离复杂度