1、分布式协调技术
分布式协调技术主要用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种临界资源,防止造成"脏数据"的后果。这时,有人可能会说这个简单,写一个调度算法就轻松解决了。说这句话的人,可能对分布式系统不是很了解,所以才会出现这种误解。如果这些进程全部是跑在一台机上的话,相对来说确实就好办了,问题就在于他是在一个分布式的环境下。
2、分布式锁
好我们知道,为了防止分布式系统中的多个进程之间相互干扰,我们需要一种分布式协调技术来对这些进程进行调度。而这个分布式协调技术的核心就是来实现这个分布式锁。由于分布式系统的线上通常有多台机器是干同一件事的(集群),而我们只需要一台机器来执行,所以要通过zookeeper选出一个leader然后给他分布式锁,让它进行操作,如果它down了,则重新投票选举(剩余集群半数以上)
3、分布式协调技术面临的问题
有人可能会感觉这个协调技术并不是很难。无非是将原来在同一台机器上对进程调度的原语,通过网络实现在分布式环境中。是的,表面上是可以这么说。但是问题就在网络这,在分布式系统中,所有在同一台机器上的假设都不存在:因为网络是不可靠的。
4、分布式锁的实现者
目前,在分布式协调技术方面做得比较好的就是Google的Chubby还有Apache的ZooKeeper他们都是分布式锁的实现者。有人会问既然有了Chubby为什么还要弄一个ZooKeeper,难道Chubby做得不够好吗?不是这样的,主要是Chbby是非开源的,Google自家用。后来雅虎模仿Chubby开发出了ZooKeeper,也实现了类似的分布式锁的功能,并且将ZooKeeper作为一种开源的程序捐献给了Apache,那么这样就可以使用ZooKeeper所提供锁服务。而且在分布式领域久经考验,它的可靠性,可用性都是经过理论和实践的验证的。所以我们在构建一些分布式系统的时候,就可以以这类系统为起点来构建我们的系统,这将节省不少成本,而且bug也 将更少。


一、Zookeeper简介
ZooKeeper是一种为分布式应用所设计的高可用、高性能且一致的开源协调服务,它提供了一项基本服务:分布式锁服务。由于ZooKeeper的开源特性,后来我们的开发者在分布式锁的基础上,摸索了出了其他的使用方法:配置维护、组服务、分布式消息队列、分布式通知/协调等。
注意:ZooKeeper性能上的特点决定了它能够用在大型的、分布式的系统当中。从可靠性方面来说,它并不会因为一个节点的错误而崩溃(只要半数以上节点存活就可以提供服务)。除此之外,它严格的序列访问控制意味着复杂的控制原语可以应用在客户端上。ZooKeeper在一致性、可用性、容错性的保证,也是ZooKeeper的成功之处,它获得的一切成功都与它采用的协议——Zab协议是密不可分的,这些内容将会在后面介绍。
前面提到了那么多的服务,比如分布式锁、配置维护、组服务等,那它们是如何实现的呢,我相信这才是大家关心的东西。ZooKeeper在实现这些服务时,首先它设计一种新的数据结构——Znode,然后在该数据结构的基础上定义了一些原语,也就是一些关于该数据结构的一些操作。有了这些数据结构和原语还不够,因为我们的ZooKeeper是工作在一个分布式的环境下,我们的服务是通过消息以网络的形式发送给我们的分布式应用程序,所以还需要一个通知机制——Watcher机制。那么总结一下,ZooKeeper所提供的服务主要是通过:数据结构+原语+watcher机制,三个部分来实现的。那么我就从这三个方面,给大家介绍一下ZooKeeper。
- 原语:是由若干条指令组成的,用于完成一定功能的一个过程。
1、ZooKeeper数据模型——Znode
ZooKeeper拥有一个层次的命名空间,这个和标准的文件系统非常相似,如下图所示。
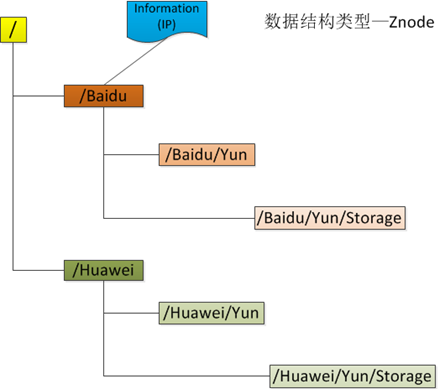
从图中我们可以看出ZooKeeper的数据模型,在结构上和标准文件系统的非常相似,都是采用这种树形层次结构,ZooKeeper树中的每个节点被称为—Znode。和文件系统的目录树一样,ZooKeeper树中的每个节点可以拥有子节点。但也有不同之处:
(1) 引用方式
Zonde通过路径引用,如同Unix中的文件路径。路径必须是绝对的,因此他们必须由斜杠字符来开头。除此以外,他们必须是唯一的,也就是说每一个路径只有一个表示,因此这些路径不能改变。在ZooKeeper中,路径由Unicode字符串组成,并且有一些限制。字符串"/zookeeper"用以保存管理信息,比如关键配额信息。
(2) Znode结构
ZooKeeper命名空间中的Znode,兼具文件和目录两种特点。既像文件一样维护着数据、元信息、ACL、时间戳等数据结构,又像目录一样可以作为路径标识的一部分。图中的每个节点称为一个Znode。 每个Znode由3部分组成:
① stat:此为状态信息, 描述该Znode的版本, 权限等信息
② data:与该Znode关联的数据
③ children:该Znode下的子节点
ZooKeeper虽然可以关联一些数据,但并没有被设计为常规的数据库或者大数据存储,相反的是,它用来管理调度数据,比如分布式应用中的配置文件信息、状态信息、汇集位置等等。这些数据的共同特性就是它们都是很小的数据,通常以KB为大小单位。ZooKeeper的服务器和客户端都被设计为严格检查并限制每个Znode的数据大小至多1M,但常规使用中应该远小于此值。
(3) 数据访问
ZooKeeper中的每个节点存储的数据要被原子性的操作。也就是说读操作将获取与节点相关的所有数据,写操作也将替换掉节点的所有数据。另外,每一个节点都拥有自己的ACL(访问控制列表),这个列表规定了用户的权限,即限定了特定用户对目标节点可以执行的操作。
- 原子操作是指不会被线程调度机制打断的操作
- 事务的原子性(Atomic):一个事务包含多个操作,这些操作要么全部执行,要么全都不执行
(4) 节点类型
ZooKeeper中的节点有两种,分别为临时节点和永久节点。节点的类型在创建时即被确定,并且不能改变。
① 临时节点:该节点的生命周期依赖于创建它们的会话。一旦会话(Session)结束<一台机器down了,就可以将其删除>,临时节点将被自动删除,当然可以也可以手动删除。虽然每个临时的Znode都会绑定到一个客户端会话,但他们对所有的客户端还是可见的。另外,ZooKeeper的临时节点不允许拥有子节点。
② 永久节点:该节点的生命周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,他们才能被删除。
(5) 顺序节点
当创建Znode的时候,用户可以请求在ZooKeeper的路径结尾添加一个递增的计数。这个计数对于此节点的父节点来说是唯一的,它的格式为"%10d"(10位数字,没有数值的数位用0补充,例如"0000000001")。当计数值大于232-1时,计数器将溢出。
(6) 观察
客户端可以在节点上设置watch,我们称之为监视器。当节点状态发生改变时(Znode的增、删、改)将会触发watch所对应的操作。当watch被触发时,ZooKeeper将会向客户端发送且仅发送一条通知,因为watch只能被触发一次,这样可以减少网络流量。
2、Zookeeper——watch触发器
(1) watch概述
ZooKeeper可以为所有的读操作设置watch,这些读操作包括:exists()、getChildren()及getData()。watch事件是一次性的触发器,当watch的对象状态发生改变时,将会触发此对象上watch所对应的事件。watch事件将被异步地发送给客户端,并且ZooKeeper为watch机制提供了有序的一致性保证。理论上,客户端接收watch事件的时间要快于其看到watch对象状态变化的时间。
(2) watch类型
ZooKeeper所管理的watch可以分为两类:
① 数据watch(data watches):getData和exists负责设置数据watch
② 孩子watch(child watches):getChildren负责设置孩子watch
我们可以通过操作返回的数据来设置不同的watch:
① getData和exists:返回关于节点的数据信息
② getChildren:返回孩子列表
因此
① 一个成功的setData操作将触发Znode的数据watch
② 一个成功的create操作将触发Znode的数据watch以及孩子watch
③ 一个成功的delete操作将触发Znode的数据watch以及孩子watch
(3) watch注册与处触发

① exists操作上的watch,在被监视的Znode创建、删除或数据更新时被触发。
② getData操作上的watch,在被监视的Znode删除或数据更新时被触发。在被创建时不能被触发,因为只有Znode一定存在,getData操作才会成功。
③ getChildren操作上的watch,在被监视的Znode的子节点创建或删除,或是这个Znode自身被删除时被触发。可以通过查看watch事件类型来区分是Znode,还是他的子节点被删除:NodeDelete表示Znode被删除,NodeDeletedChanged表示子节点被删除。
Watch由客户端所连接的ZooKeeper服务器在本地维护,因此watch可以非常容易地设置、管理和分派。当客户端连接到一个新的服务器时,任何的会话事件都将可能触发watch。另外,当从服务器断开连接的时候,watch将不会被接收。但是,当一个客户端重新建立连接的时候,任何先前注册过的watch都会被重新注册。
(4) 需要注意的几点
Zookeeper的watch实际上要处理两类事件:
① 连接状态事件(type=None, path=null)
这类事件不需要注册,也不需要我们连续触发,我们只要处理就行了。
② 节点事件
节点的建立,删除,数据的修改。它是one time trigger,我们需要不停的注册触发,还可能发生事件丢失的情况。
上面2类事件都在Watch中处理,也就是重载的process(Event event)
节点事件的触发,通过函数exists,getData或getChildren来处理这类函数,有双重作用:
① 注册触发事件
② 函数本身的功能
函数的本身的功能又可以用异步的回调函数来实现,重载processResult()过程中处理函数本身的的功能。
3、Zookeeper——投票机制(此部分讲述的是zookeeper的分布式协调功能<选举出一个人干就行了>)
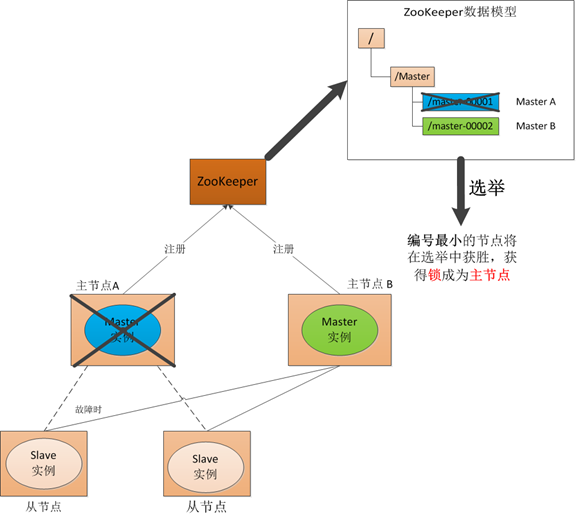
(1) Master启动
在引入了Zookeeper以后我们启动了两个主节点,"主节点-A"和"主节点-B"他们启动以后,都向ZooKeeper去注册一个节点。我们假设"主节点-A"锁注册地节点是"master-00001","主节点-B"注册的节点是"master-00002",注册完以后进行选举,编号最小的节点将在选举中获胜获得锁成为主节点,也就是我们的"主节点-A"将会获得锁成为主节点,然后"主节点-B"将被阻塞成为一个备用节点。那么,通过这种方式就完成了对两个Master进程的调度。

(2) Master故障
如果"主节点-A"挂了,这时候他所注册的节点将被自动删除,ZooKeeper会自动感知节点的变化,然后再次发出选举,这时候"主节点-B"将在选举中获胜,替代"主节点-A"成为主节点。
(3) Master 恢复
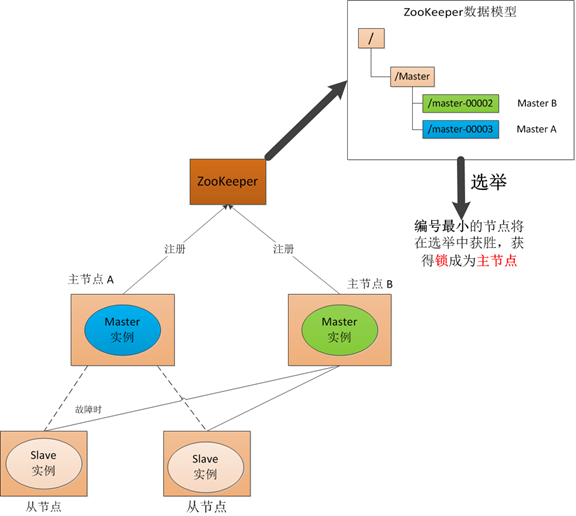
如果主节点恢复了,他会再次向ZooKeeper注册一个节点,这时候他注册的节点将会是"master-00003",ZooKeeper会感知节点的变化再次发动选举,这时候"主节点-B"在选举中会再次获胜继续担任"主节点","主节点-A"会担任备用节点。
以上这种的实现方法
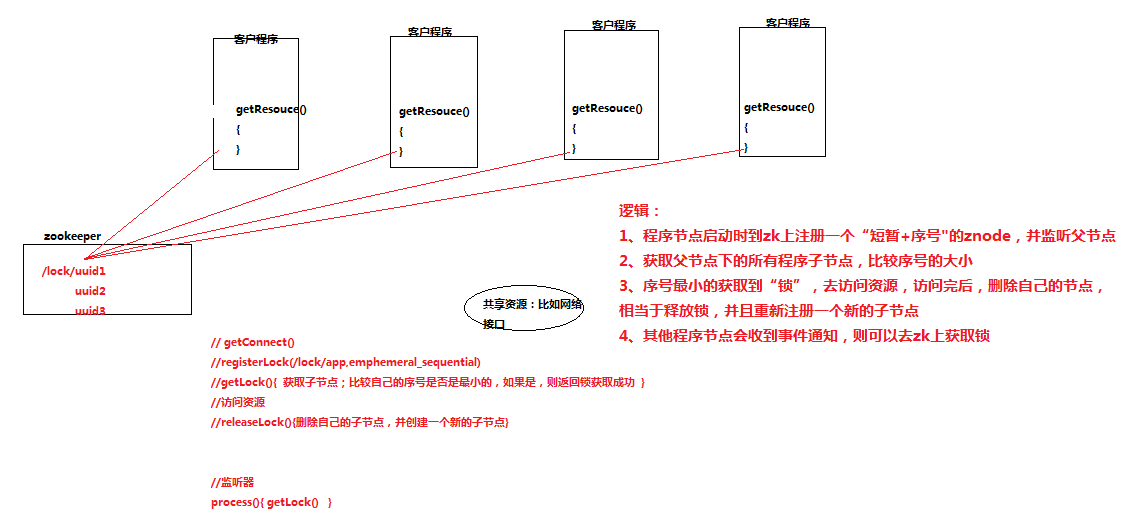
二、干货们
Zookeeper是一个分布式协调服务;就是为用户的分布式应用程序提供协调服务
A、zookeeper是为别的分布式程序服务的
B、Zookeeper本身就是一个分布式程序(只要有半数以上节点存活,zk就能正常服务)
C、Zookeeper所提供的服务涵盖:主从协调、服务器节点动态上下线、统一配置管理、分布式共享锁、统一名称服务……
D、虽然说可以提供各种服务,但是zookeeper在底层其实只提供了两个功能:
- 管理(存储,读取)用户程序提交的数据;
- 并为用户程序提供数据节点监听服务;
为什么选用奇数台服务器:
- 只要集群中有半数以上节点存活,集群就能提供服务(原因:zookeeper为了效率,只会将Znode树的每一个修改都会被复制到集合体中超过半数的机器上)
- 投票机制(半数以上)
1、zookeeper集群的搭建
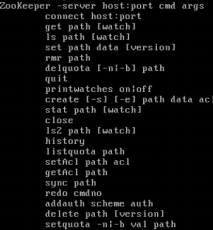
2、命令行操作
运行 zkCli.sh –server <ip>进入命令行工具
1、使用 ls 命令来查看当前 ZooKeeper 中所包含的内容:
[zk: 202.115.36.251:2181(CONNECTED) 1] ls /
2、创建一个新的 znode ,使用 create /zk myData 。这个命令创建了一个新的 znode 节点“ zk ”以及与它关联的字符串:
[zk: 202.115.36.251:2181(CONNECTED) 2] create /zk "myData“
3、我们运行 get 命令来确认 znode 是否包含我们所创建的字符串:
[zk: 202.115.36.251:2181(CONNECTED) 3] get /zk
#监听这个节点的变化,当另外一个客户端改变/zk时,它会打出下面的
#WATCHER::
#WatchedEvent state:SyncConnected type:NodeDataChanged path:/zk
[zk: localhost:2181(CONNECTED) 4] get /zk watch
4、下面我们通过 set 命令来对 zk 所关联的字符串进行设置:
[zk: 202.115.36.251:2181(CONNECTED) 4] set /zk "zsl“
5、下面我们将刚才创建的 znode 删除:
[zk: 202.115.36.251:2181(CONNECTED) 5] delete /zk
6、删除节点:rmr(递归删除)
[zk: 202.115.36.251:2181(CONNECTED) 5] rmr /zk
3、Java API操作(正常人都不会用原生api的,此处只是演示)
import org.apache.zookeeper.*;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
public class ZooKeeperTest {
// 会话超时时间,设置与系统默认时间一致
private final int SESSION_TIMEOUT = 30000;
// 集群的地址
private static final String connectString = "127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183";
//创建ZooKeeper实例
ZooKeeper zk;
// 每次改动都会调用这个方法
Watcher watcher = new Watcher() {
public void process(WatchedEvent event) {
System.out.println(event.toString());
}
};
//初始化ZooKeeper实例
@Before
public void before() throws IOException {
zk = new ZooKeeper(connectString, SESSION_TIMEOUT, watcher);
}
@After
public void after() throws InterruptedException {
zk.close();
}
@Test
public void create() throws KeeperException, InterruptedException {
//在创建节点的时候,需要提供节点的名称、数据、权限以及节点类型
System.out.println("1.创建ZooKeeper节点(znode:zoo2,数据:myData2,权限:OPEN_ACL_UNSAFE,节点类型:Persistent)");
zk.create("/zoo1", "myData".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
@Test
public void getData() throws KeeperException, InterruptedException {
System.out.println("2.查看是否创建成功:");
// 路径 是否监听 获取的版本号
System.out.println(new String(zk.getData("/zoo2", false, null)));
}
@Test
public void setData() throws KeeperException, InterruptedException {
System.out.println("3.修改节点数据:");
zk.setData("/zoo2", "xiugai1234".getBytes(), -1);
}
@Test
public void getSetData() throws KeeperException, InterruptedException {
System.out.println("4.查看是否修改成功:");
System.out.println(new String(zk.getData("/zoo2", false, null)));
}
@Test
public void delete() throws InterruptedException, KeeperException {
System.out.println("5.删除节点");
// -1表示删除所有版本
zk.delete("/zoo2", -1);
}
@Test
public void getStat() throws KeeperException, InterruptedException {
//使用 exists函数时,如果节点不存在将返回一个nul值
System.out.println("6.查看节点是否被删除:");
System.out.println("节点状态:["+zk.exists("/zoo2", false)+"]");
}
@Test
public void getChilren() throws KeeperException, InterruptedException {
//使用 exists函数时,如果节点不存在将返回一个nul值
System.out.println("6.查看所有子节点:");
/**
* 第二个参数:是否监听
* 如果设为true,“/”下有任何变化都会在执行一下上面的监听方法,但只生效一次
*/
System.out.println(zk.getChildren("/",true));
// 如果等待的话,程序就会直接结束了
Thread.sleep(Long.MAX_VALUE);
}
}
监听器工作机制(watch内个)
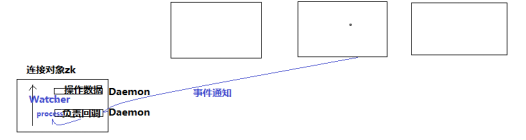
监听器是一个接口,我们的代码中可以实现Wather这个接口,实现其中的process方法,方法中即我们自己的业务逻辑
监听器的注册是在获取数据的操作中实现:
getData(path,watch?)监听的事件是:节点数据变化事件
getChildren(path,watch?)监听的事件是:节点下的子节点增减变化事件
示例们:
服务端
public class DistributedServer {
private static final String connectString = "127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183";
private static final int sessionTimeout = 2000;
private static final String parentNode = "/servers";
private ZooKeeper zk;
/**
* 创建到zk的客户端连接
*
* @throws Exception
*/
public void getConnect() throws Exception {
zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
public void process(WatchedEvent event) {
// 收到事件通知后的回调函数(应该是我们自己的事件处理逻辑)
System.out.println(event.getType() + "---" + event.getPath());
}
});
}
/**
* 向zk集群注册服务器信息
*/
public void registerServer(String hostname) throws Exception {
// 返回path
String create = zk.create(parentNode + "/server", hostname.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println(hostname + "is online.." + create);
}
/**
* 业务功能
*/
public void handleBussiness(String hostname) throws InterruptedException {
System.out.println(hostname + "start working.....");
Thread.sleep(Long.MAX_VALUE);
}
public static void main(String[] args) throws Exception {
// 获取zk连接
DistributedServer server = new DistributedServer();
server.getConnect();
// 利用zk连接注册服务器信息
server.registerServer("host1");
// 启动业务功能
server.handleBussiness("host1");
}
}
客户端
import java.util.ArrayList;
import java.util.List;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
public class DistributedClient {
private static final String connectString = "127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183";
private static final int sessionTimeout = 2000;
private static final String parentNode = "/servers";
// 注意:加volatile的意义何在?
private volatile List<String> serverList;
private ZooKeeper zk = null;
/**
* 创建到zk的客户端连接
*/
public void getConnect() throws Exception {
zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
public void process(WatchedEvent event) {
// 收到事件通知后的回调函数(应该是我们自己的事件处理逻辑)
try {
//重新更新服务器列表,并且注册了监听
getServerList();
} catch (Exception e) {
}
}
});
}
/**
* 获取服务器信息列表
*/
public void getServerList() throws Exception {
// 获取服务器子节点信息,并且对父节点进行监听
List<String> children = zk.getChildren(parentNode, true);
// 先创建一个局部的list来存服务器信息
List<String> servers = new ArrayList<String>();
for (String child : children) {
// child只是子节点的节点名
byte[] data = zk.getData(parentNode + "/" + child, false, null);
servers.add(new String(data));
}
// 把servers赋值给成员变量serverList,已提供给各业务线程使用
serverList = servers;
//打印服务器列表
System.out.println(serverList);
}
/**
* 业务功能
*/
public void handleBussiness() throws InterruptedException {
System.out.println("client start working.....");
Thread.sleep(Long.MAX_VALUE);
}
public static void main(String[] args) throws Exception {
// 获取zk连接
DistributedClient client = new DistributedClient();
client.getConnect();
// 获取servers的子节点信息(并监听),从中获取服务器信息列表
client.getServerList();
// 业务线程启动
client.handleBussiness();
}
}