我们先来看一个经典的Tornado代码
# coding:utf-8
import tornado.web
import tornado.ioloop
import tornado.httpserver
import tornado.options
class IndexHandler(tornado.web.RequestHandler):
def get(self):
self.write("hello,world!")
if __name__ == "__main__":
app = tornado.web.Application([
(r"/",IndexHandler),
])
app.listen(8000) # 创建服务器实例,绑定服务器端口
tornado.ioloop.IOLoop.current().start() # 启动当前线程的IOLoop实例的循环,并监听服务器
1. tornado.web模块
RequestHandler
封装了对应一个请求的所有信息和方法,write(响应信息)就是写响应信息的一个方法;对应每一种http请求方式(get、post等),把对应的处理逻辑写进同名的成员方法中(如对应get请求方式,就将对应的处理逻辑写在get()方法中),当没有对应请求方式的成员方法时,会返回“405: Method Not Allowed”错误。
Application
Tornado Web框架的核心应用类,是与服务器对接的接口,里面保存了路由信息表,其初始化接收的第一个参数就是一个路由信息映射元组的列表;其listen(端口)方法用来创建一个http服务器实例,并绑定到给定端口(注意:此时服务器并未开启监听)。
2. tornado.ioloop模块
tornado的核心io循环模块,封装了Linux的epoll和BSD的kqueue,tornado高性能的基石。
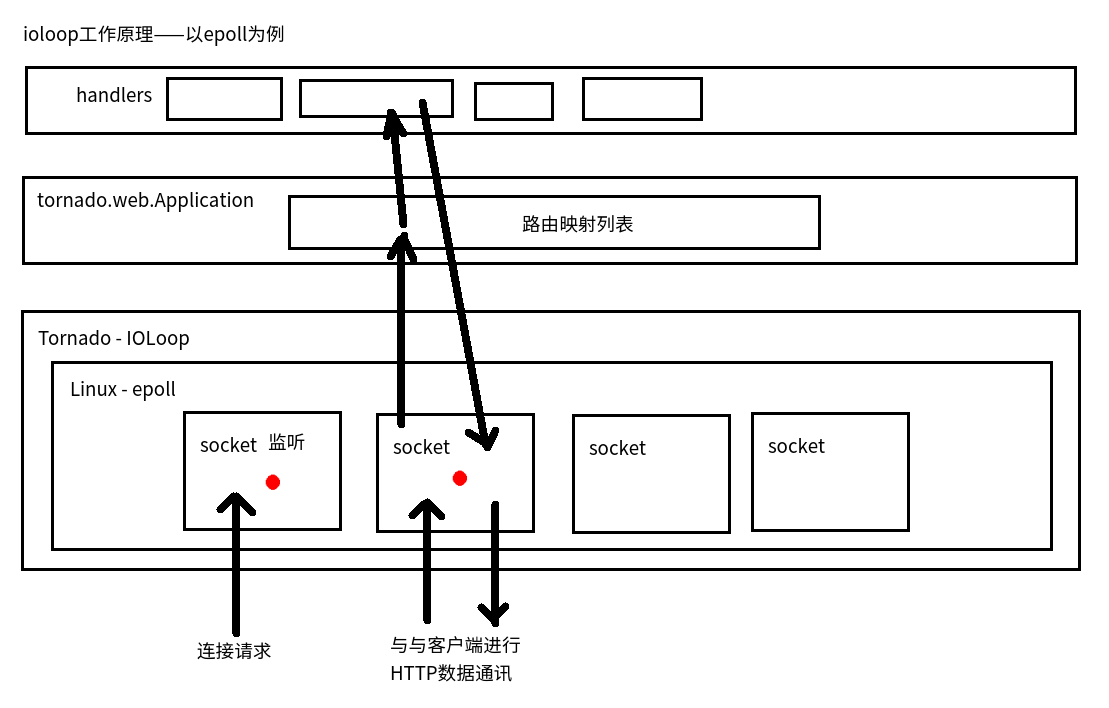
IOLoop.current():返回当前线程的IOLoop实例。
IOLoop.start():启动IOLoop实例的I/O循环,同时服务器监听被打开。
3、tornado.httpserver模块
tornado的HTTP服务器实现。
我们创建了一个HTTP服务器实例http_server,因为服务器要服务于我们刚刚建立的web应用,将接收到的客户端请求通过web应用中的路由映射表引导到对应的handler中,所以在构建http_server对象的时候需要传出web应用对象app。http_server.listen(8000)将服务器绑定到8000端口。
实际上一版代码中app.listen(8000)正是对这一过程的简写(所以我们还是用app.listen吧,知道它是怎么实现的就行了)。
# coding:utf-8
import tornado.web
import tornado.ioloop
import tornado.httpserver # 引入tornado.httpserver模块
class IndexHandler(tornado.web.RequestHandler):
def get(self):
self.write("hello,world!")
if __name__ == "__main__":
app = tornado.web.Application([
(r"/",IndexHandler),
])
# app.listen(8000) # 建立与8000端口的连接
# =================== 单进程模式 ===================
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(8000) # <==> http_server.start(num_processes=1)
# =================== 多进程模式 ===================
http_server = tornado.httpserver.HTTPServer(app) # 创建httpserver实例
http_server.bind(8000) # 将服务器绑定到指定端口
http_server.start(0) # 可以使用http_server.start(num_processes=1)方法指定开启几个进程,如果num_processes为None或者<=0,则自动根据机器硬件的cpu核芯数创建同等数目的。
tornado.ioloop.IOLoop.current().start()
注意的两点:
1.关于app.listen()
app.listen()这个方法只能在单进程模式中使用。
对于app.listen()与手动创建HTTPServer实例
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(8000)
这两种方式,建议大家先使用后者即创建HTTPServer实例的方式,因为其对于理解tornado web应用工作流程的完整性有帮助,便于大家记忆tornado开发的模块组成和程序结构;在熟练使用后,可以改为简写。
2.关于多进程
虽然tornado给我们提供了一次开启多个进程的方法,但是由于:
- 每个子进程都会从父进程中复制一份IOLoop实例,如过在创建子进程前我们的代码动了IOLoop实例,那么会影响到每一个子进程,势必会干扰到子进程IOLoop的工作;
- 所有进程是由一个命令一次开启的,也就无法做到在不停服务的情况下更新代码;
- 所有进程共享同一个端口,想要分别单独监控每一个进程就很困难。
不建议使用这种多进程的方式,而是手动开启多个进程,并且绑定不同的端口。
在前面的示例中我们都是将服务端口的参数写死在程序中,很不灵活。
tornado为我们提供了一个便捷的工具,tornado.options模块——全局参数定义、存储、转换。
4、tornado.options模块
1)tornado.options.define()
用来定义options选项变量的方法,定义的变量可以在全局的tornado.options.options中获取使用,传入参数:
- name 选项变量名,须保证全局唯一性,否则会报“Option 'xxx' already defined in ...”的错误;
- default 选项变量的默认值,如不传默认为None;
- type 选项变量的类型,从命令行或配置文件导入参数的时候tornado会根据这个类型转换输入的值,转换不成功时会报错,可以是str、float、int、datetime、timedelta中的某个,若未设置则根据default的值自动推断,若default也未设置,那么不再进行转换。可以通过利用设置type类型字段来过滤不正确的输入。
- multiple 选项变量的值是否可以为多个,布尔类型,默认值为False,如果multiple为True,那么设置选项变量时值与值之间用英文逗号分隔,而选项变量则是一个list列表(若默认值和输入均未设置,则为空列表[])。
- help 选项变量的帮助提示信息,在命令行启动tornado时,通过加入命令行参数 --help 可以查看所有选项变量的信息(注意,代码中需要加入tornado.options.parse_command_line())。
2)tornado.options.options.xxx
全局的options对象,所有定义的选项变量都会作为该对象的属性。
3)tornado.options.parse_command_line()
转换命令行参数,并将转换后的值对应的设置到全局options对象相关属性上。追加命令行参数的方式是--myoption=myvalue
示例:
# coding:utf-8
import tornado.web
import tornado.ioloop
import tornado.httpserver
import tornado.options
tornado.options.define("port",default=8000,type=int,help="给个端口号呗")
class IndexHandler(tornado.web.RequestHandler):
def get(self):
self.write("hello,world!")
if __name__ == "__main__":
tornado.options.parse_command_line()
app = tornado.web.Application([
(r"/",IndexHandler),
])
# app.listen(8000) # 建立与8000端口的连接
http_server = tornado.httpserver.HTTPServer(app) # 创建httpserver实例
http_server.bind(tornado.options.options.port) # 将服务器绑定到指定端口
http_server.start(0) # 可以使用http_server.start(num_processes=1)方法指定开启几个进程,如果num_processes为None或者<=0,则自动根据机器硬件的cpu核芯数创建同等数目的。
tornado.ioloop.IOLoop.current().start()
命令行:$ python opt.py --port=9000 # 传递端口号
也可以直接通过配置文件传给tornado.options.parse_command_line(/path)
# coding:utf-8
import tornado.web
import tornado.ioloop
import tornado.httpserver
import tornado.options
tornado.options.define("port",default=8000,type=int,help="给个端口号呗")
class IndexHandler(tornado.web.RequestHandler):
def get(self):
self.write("hello,world!")
if __name__ == "__main__":
tornado.options.parse_command_line("./config")
app = tornado.web.Application([
(r"/",IndexHandler),
])
# app.listen(8000) # 建立与8000端口的连接
http_server = tornado.httpserver.HTTPServer(app) # 创建httpserver实例
http_server.bind(tornado.options.options.port) # 将服务器绑定到指定端口
http_server.start(0) # 可以使用http_server.start(num_processes=1)方法指定开启几个进程,如果num_processes为None或者<=0,则自动根据机器硬件的cpu核芯数创建同等数目的。
tornado.ioloop.IOLoop.current().start()
配置文件格式:
port = 8000
1. 日志
当我们在代码中调用parse_command_line()或者parse_config_file()的方法时,tornado会默认为我们配置标准logging模块,即默认开启了日志功能,并向标准输出(屏幕)打印日志信息。
如果想关闭tornado默认的日志功能,可以在命令行中添加--logging=none 或者在代码中执行如下操作:
from tornado.options import options, parse_command_line options.logging = None parse_command_line()
2. 配置文件
我们看到在使用prase_config_file()的时候,配置文件的书写格式仍需要按照python的语法要求,其优势是可以直接将配置文件的参数转换设置到全局对象tornado.options.options中;然而,其不方便的地方在于需要在代码中调用tornado.options.define()来定义选项,而且不支持字典类型,故而在实际应用中大都不使用这种方法。
在使用配置文件的时候,通常会新建一个python文件(如config.py),然后在里面直接定义python类型的变量(可以是字典类型);在需要配置文件参数的地方,将config.py作为模块导入,并使用其中的变量参数。
如config.py文件:
# conding:utf-8
# Redis配置
redis_options = {
'redis_host':'127.0.0.1',
'redis_port':6379,
'redis_pass':'',
}
# Tornado app配置
settings = {
'template_path': os.path.join(os.path.dirname(__file__), 'templates'),
'static_path': os.path.join(os.path.dirname(__file__), 'statics'),
'cookie_secret':'0Q1AKOKTQHqaa+N80XhYW7KCGskOUE2snCW06UIxXgI=',
'xsrf_cookies':False,
'login_url':'/login',
'debug':True,
}
# 日志
log_path = os.path.join(os.path.dirname(__file__), 'logs/log')
使用config.py的模块中导入config,如下:
# conding:utf-8
import tornado.web
import config
if __name__ = "__main__":
app = tornado.web.Application([], **config.settings)
...