Summary of OAuth 2.0
1 Problems:
This pattern of applications obtaining user passwords obviously has a number of problems. Since the application would need to log in to the service as the user, these applications would often store users’ passwords in plain text, making them a target for harvesting passwords. Once the application has the user’s password, it has complete access to the user’s account, including having access to capabilities such as changing the user’s password! Another problem was that after giving an app your password, the only way you’d be able to revoke that access was by changing your password, something that users are typically reluctant to do.
OAuth 2.0 is the industry-standard protocol for authorization, focusing on client developer simplicity while providing specific authorization flows for web applications, desktop applications, mobile phones, and living room devices.
2 Basic KnowLedge
Roles
OAuth2 defines 4 roles :
Resource Owner: generally yourself.
Resource Server: server hosting protected data (for example Google hosting your profile and personal information).
Client: application requesting access to a resource server (it can be your PHP website, a Javascript application or a mobile application).
Authorization Server: server issuing access token to the client. This token will be used for the client to request the resource server. This server can be the same as the resource server (same physical server and same application), and it is often the case.
Tokens
Tokens are random strings generated by the authorization server and are issued when the client requests them.
There are 2 types of token:
Access Token: this is the most important because it allows the user data from being accessed by a third-party application. This token is sent by the client as a parameter or as a header in the request to the resource server. It has a limited lifetime, which is defined by the authorization server.
Refresh Token: this token is issued with the access token but unlike the latter, it is not sent in each request from the client to the resource server. It merely serves to be sent to the authorization server for renewing the access token when it has expired. For security reasons, it is not always possible to obtain this token.
Access token scope
The scope is a parameter used to limit the rights of the access token. This is the authorization server that defines the list of the available scopes. The client must then send the scopes he wants to use for his application during the request to the authorization server.
HTTPS
OAuth2 requires the use of HTTPS for communication between the client and the authorization server because of sensitive data passing between the two (tokens and possibly resource owner credentials). In fact you are not forced to do so if you implement your own authorization server but you must know that you are opening a big security hole by doing this.
3 Authorization grant types
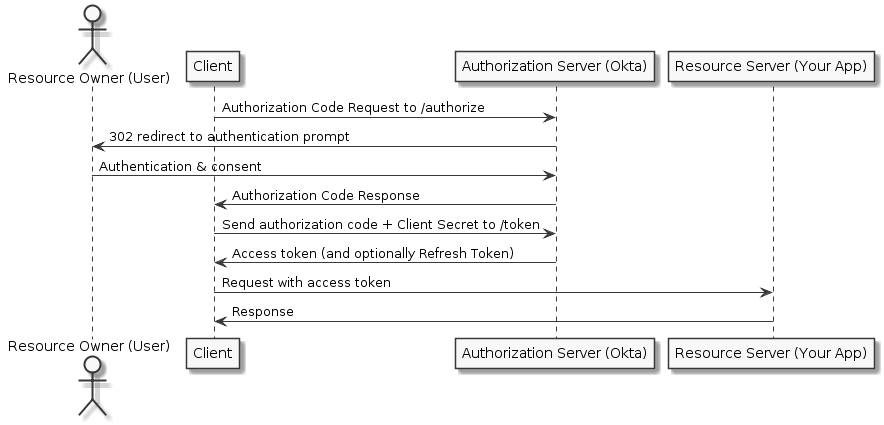
Authorization Code Flow
The Authorization Code flow is best used by server-side apps where the source code is not publicly exposed. The apps should be server-side because the request that exchanges the authorization code for a token requires a client secret, which will have to be stored in your client. The server-side app requires an end-user, however, because it relies on interaction with the end-user's web browser which will redirect the user and then receive the authorization code. Access token can be renewed with a refresh token (if the authorization server enables it)
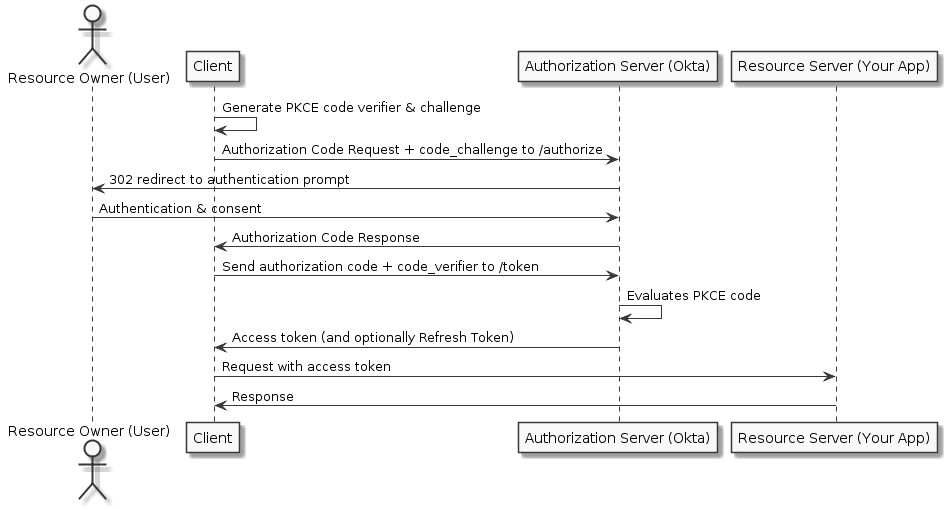
Authorization Code with PKCE Flow
For web/native/mobile applications, the client secret cannot be stored in the application because it could easily be exposed. Additionally, mobile redirects use app:// protocols, which are prone to interception. Basically, a rogue application could intercept the authorization code as it is being passed through the mobile/native operating system. Therefore native apps should make use of Proof Key for Code Exchange (PKCE), which acts like a secret but isn't hard-coded, to keep the Authorization Code flow secure.
The PKCE-enhanced Authorization Code flow requires your application to generate a cryptographically random key called a "code verifier". A "code challenge" is then created from the verifier, and this challenge is passed along with the request for the authorization code.
When the authorization code is sent in the access token request, the code verifier is sent as part of the request. The authorization server recomputes the challenge from the verifier using an agreed-upon hash algorithm and then compares that. If the two code challenges and verifier match, then it knows that both requests(for Authorization code and for Access token) were sent by the same client.
A rogue app could only intercept the authorization code, but it would not have access to the code challenge or verifier, since they are both sent over HTTPS.
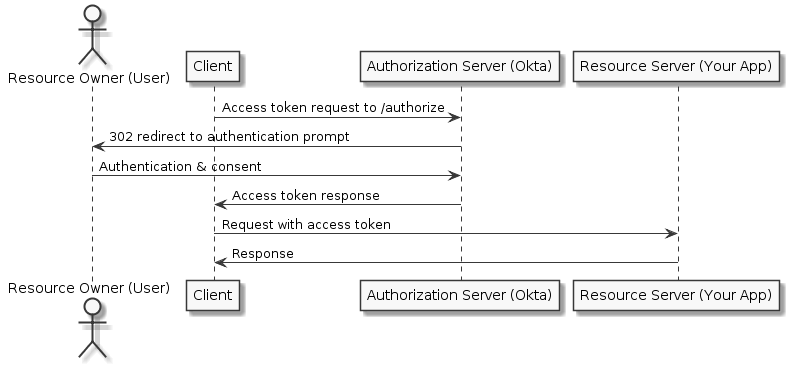
Implicit Flow
The Implicit Flow is intended for applications where the confidentiality of the client secret cannot be guaranteed. In this flow, the client does not make a request to the /token endpoint, but instead receives the access token directly from the /authorize endpoint. For Single Page Applications (SPA) running in modern browsers we recommend using the Authorization Code Flow with PKCE instead for maximum security.
NOTE: Because it is intended for less-trusted clients, the Implicit Flow does not support refresh tokens.
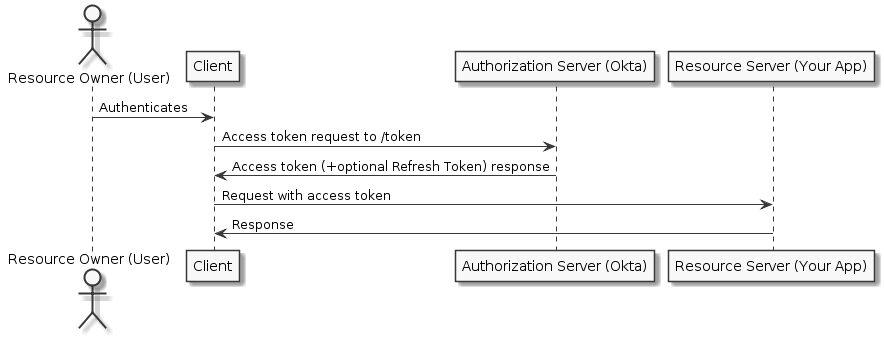
Resource Owner Password Flow
The Resource Owner Password Flow is intended for use cases where you control both the client application(First Party Client) and the resource that it is interacting with. It requires that the client can store a client secret and can be trusted with the resource owner's credentials, and so is most commonly found in clients made for online services, like the Facebook client applications that interact with the Facebook service. It doesn't require redirects like the Authorization Code or Implicit flows, and involves a single authenticated call to the /token endpoint.
Client Credentials Flow
The Client Credentials flow is intended for server-side (AKA "confidential") client applications with no end user, which normally describes machine-to-machine communication. The application must be server-side because it must be trusted with the client secret, and since the credentials are hard-coded, it cannot be used by an actual end-user. It involves a single, authenticated request to the /token endpoint, which returns an access token.
NOTE: The Client Credentials Flow does not support refresh tokens.(You have credentials locally, you don’t need refresh token)
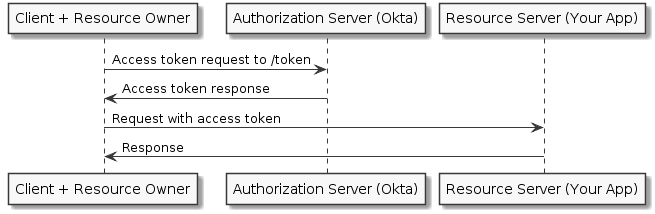
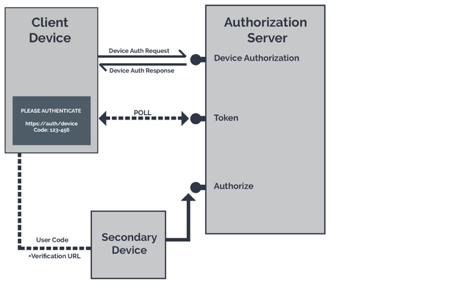
Device Code Flow
The grant type is used by browserless or input-constrained devices in the device flow to exchange a previously obtained device code for an access token,such as a Playstation or an Apple TV.
The Device Code grant type value is urn:ietf:params:oauth:grant-type:device_code.
4 Choose a grant type according to your client.
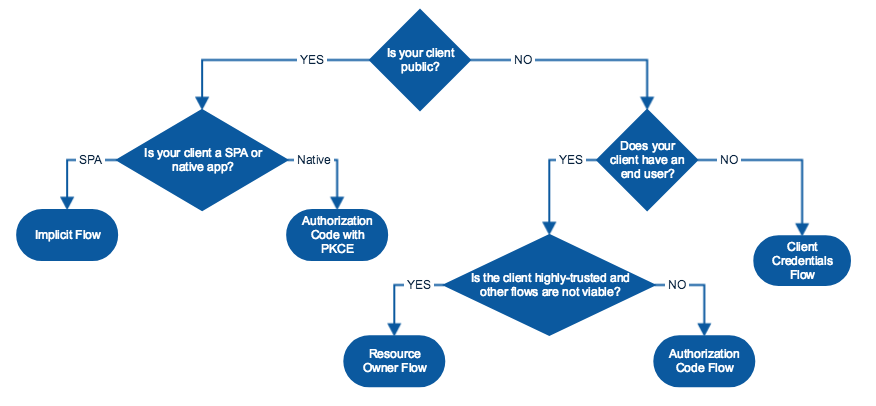
Is your client public?
A client application is considered "public" when an end-user could possibly view and modify the code. This includes Single Page Apps (SPAs) or any mobile or native applications. In both cases, the application cannot keep secrets from malicious users.
Is your client a SPA or native?
If your client application is a Single Page Application (SPA), you should use the Implicit flow.
If your client application is a native application, you should use the Authorization code with PKCE flow.
Does the client have an end-user?
If your client application is running on a server with no direct end user, then it can be trusted to store credentials and use them responsibly. If your client application will only be doing machine-to-machine interaction, then you should use the Client Credentials flow.
Does the resource owner own the client?
If you own both the client application and the resource that it is accessing, then your application can be trusted to store your end-user's login and password. Because of the high degree of trust required here, you should only use this flow if other flows are not viable. In this case, you can use the Resource Owner Password flow.
5 How to build an Authorization Server/Resource Server?
Large scale deployments may have more than one resource server. Each of these resource servers are distinctly separate, but they all share the same authorization server.
Smaller deployments typically have only one resource server, and is often built as part of the same code base or same deployment as the authorization server.
Client Registration
you need to provide a third-party application registration management service. In general, two important parameters that appear in pairs are assigned to the registered third-party application:
Client_id: An identification id of a third-party application. This information is usually public information that is used to distinguish which third-party application.
Client_secret: The private key information of the third-party application. This information is private information that is not allowed to be passed in the OAuth2 process for security detection and encryption.
Authorization
Accepts the authorization request from the client and guides the user to the resource server to complete the login authorization process.
Obtain the access token
Use the license credentials provided by the authorization interface to issue the access token of the Resource owner to the Client, or update the expired access token.
Open Resource
Verifying access tokens
The resource server will be getting requests from applications with an HTTP Authorization header containing an access token. The resource server needs to be able to verify the access token to determine whether to process the request, and find the associated user account, etc.
If you’re using self-encoded access tokens, then verifying the tokens can be done entirely in the resource server without interacting with a database or external servers.
If your tokens are stored in a database, then verifying the token is simply a database lookup on the token table.
Verifying scope
The resource server needs to know the list of scopes that are associated with the access token. The server is responsible for denying the request if the scopes in the access token do not include the required scope to perform the designated action.
6 Self-Encoded Access Tokens
Self-encoded tokens provide a way to avoid storing tokens in a database by encoding all of the necessary information in the token string itself. The main benefit of this is that API servers are able to verify access tokens without doing a database lookup on every API request, making the API much more easily scalable.
JWT(JSON Web Token)
A JSON Web Token (JWT) is a JSON object that is defined in RFC 7519 as a safe way to represent a set of information between two parties. The token is composed of a header, a payload, and a signature.
So a JWT is just a string in this format:
header.payload.signature
Header:
{
"typ":"JWT",
"alg":"HS256”
}
Payload:
{
"sub": 1000,
"iss": "https://authorization-server.com",
"cid": "https://example-app.com",
"iat": 1470002703,
"exp": 1470009903,
"scope": "read write"
}
signature:
// signature algorithm
data = base64urlEncode( header ) + “.” + base64urlEncode( payload )
hashedData = hash( data, secret )
signature = base64urlEncode( hashedData )
As demonstrated in the previous steps, the data inside a JWT is encoded and signed, not encrypted. The purpose of encoding data is to transform the data’s structure. Signing data allows the data receiver to verify the authenticity of the source of the data. Soencoding and signing data does NOT secure the data.
It should also be noted that JWT should be sent over HTTPS connections (not HTTP). Having HTTPS helps prevents unauthorized users from stealing the sent JWT by making it so that the communication between the servers and the user cannot be intercepted .
7 References:
https://oauth.net/2/grant-types/authorization-code/
https://www.oauth.com/oauth2-servers/getting-ready/
http://www.bubblecode.net/en/2016/01/22/understanding-oauth2/#Conclusion
https://www.cnblogs.com/linianhui/p/oauth2-authorization.html#auto_id_3
https://medium.com/vandium-software/5-easy-steps-to-understanding-json-web-tokens-jwt-1164c0adfcec