MapRduce保证reducer的输入是按照key进行排过序的,原因和归并排序有关,在reducer接收到不同的mapper输出的有序数据后,需要再次进行排序,然后是分组排序,如果mapper输出的是有序数据,将减少reducer阶段排序的时间消耗.一般将排序以及Map的输出传输到Reduce的过程称为混洗(shuffle).Shuffle是MapReduce过程的核心,了解Shuffle非常有助于理解MapReduce的工作原理。如果你不知道MapReduce里的Shuffle是什么,那么请看下面这张图
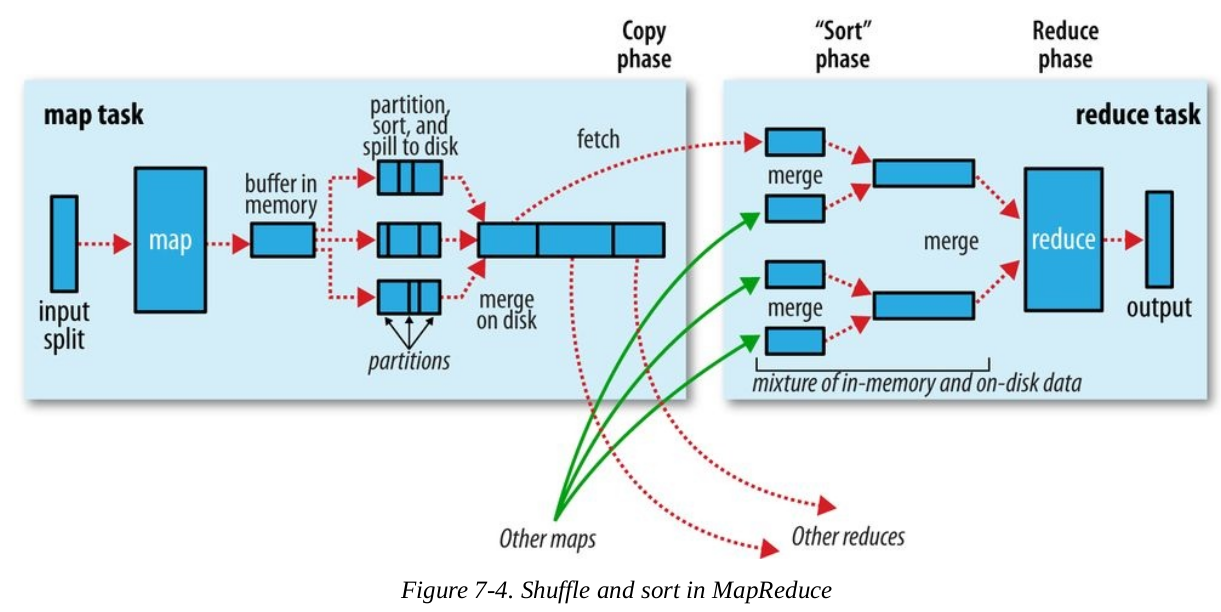
上图中明显分为两个大部分Map任务和Reduce任务,图中的红色虚线代表数据流的一个过程,下面分两部分进行说明:
MAP部分
每一个mapper都有一个circular buffer(环形缓存),环形缓冲区是一个先进先出的循环缓冲区,不用频繁的分配内存,而且在大多数情况下,内存的反复使用也使得我们能用更少的内存块做更多的事,默认情况下大小为100M(可以通过mapreduce.task.io.sort.mb来进行修改).Mapper的输出会首先写进这个缓存里面,当里面的内容达到一个阈值(mapreduce.map.sort.spill.percent,默认情况下为80%),一个后台线程就会开始向磁盘spill这些内容,同时Map将继续向该缓存区写内容.当缓存区写满时,Map被阻塞,直到spill过程完成才会被唤醒.Spills 将会循环写进 mapreduce.cluster.local.dir定义的目录下面,也就是说会产生多个spill磁盘文件.
在spill过程写进磁盘之前还会做一些事情,步骤如下:
(1) 首先线程会先把写的内容分成多个分组,这个和reducer的分组是一致的,partitioner的算法请参考我的另外一篇文章:hadoop之定制自己的Partitioner
(2) 针对每一个分组,线程会实现内存的排序,排序的过程请参考另外一篇文章: hadoop之定制自己的sort过程
(3) 如果存在combiner的话,combiner会在sort之后,在每一个分组进行执行,combiner的执行会导致写到磁盘的数据减少.
每一次环形缓存达到阈值,就会产生一个spill的文件,也就是说可能会产生很多个spill文件.在任务结束之前,这些文件会被合并为统一的带有分组和排好序的文件作为输出.其中mapreduce.task.io.sort.factor定义了一次合并的文件的最大个数,默认的个数为10.另外如果文件个数大于3的话,combiner会再次被调用.如果仅有2个或者更少的文件,没有必要调用combiner了.
如果mapper输出的文件相对较大,不利于在网络中传输,可以考虑下压缩,既能减少写入磁盘的时间开销,也能减小传输的压力.将mapreduce.map.output.compress设置为true即可,使用的压缩算法的库为mapreduce.map.output.compress.codec.是否使用压缩要看减小的网络传输和解压缩时间的对比,如果提升不大,则没有压缩的必要.
Reduce部分
一个reducer的partition输入,可能来自集群的很多个mapper的输出,每个mapper的数据到达时间是不定的,reduce任务一旦接收到数据,立刻开始拷贝,而且这些拷贝的操作是由不同的线程并行运行的,这样就可以接收来自不同的mapper的输出数据.通过设置mapreduce.reduce.shuffle.parallelcopies,可以实现线程数量的改变,默认的情况下该值为5.
如果map的输出文件很小,那么它们就会被拷贝到reduce任务的JVM内存中,否则会写入到磁盘.当在JVM内存中的数据,达到一个阈值时(由mapreduce.reduce.shuffle.merge.percent属性控制)或者map的输出达到一个阈值时(由mapreduce.reduce.merge.inmem.threshold属性控制),这些map输出数据开始merge,并spill到磁盘中,如果mapper输出文件存在压缩,则会在内存中被解压缩.如果merge过程中有combiner,则会被再次运行,以此减少写入磁盘的数据.当磁盘上的文件逐渐增多时,后台程序会将多个spill文件sort和merge成更大的文件.
当所有的map输出文件都已经被拷贝完成,reducer进入到sort阶段,也就是混合map输出文件,使数据保持有序的状态.混合的过程采用round的方式,例如如果有50个map输出文件,而混合因子是10( mapreduce.task.io.sort.facto),将会有5rounds去混合所有的文件,如下图所示:

值得注意的是,最后的一次round可以混合内存和磁盘的数据段.