
文字解码完后,你可以想象有一条纸带,上面写着代码。从左侧向左拉动纸带,用剪刀将程序
纸带剪成纸片,在内存中依次摆放这些纸片,然后才可以执行内存中的这些纸片。

执行内存中代码的时侯,会用到一种名为堆栈(stack)的数据结构(也就是数据的组织处理
方式)。堆栈像个容器,放东西与取东西都在同一端,越晚放进去的东西,越早被取出来(后
进先出)。用通俗一点的比喻:堆栈就像是停车场,越早停进去的车,会停在越里面的位置,
要等到比它晚进的车都开走之后,才能开走。
为什么需要堆栈?因为程序在执行的过程中,有时候需要把某些事暂时保留不做(因为条件不
成熟),等到后面的事做完才能回头去做之前保留的事,这时候用堆栈是最适合的。
从下一页开始连续有好几个范例,你会看到这些范例在执行的过程中堆栈如何变化,而且屏幕
上的输出如何变化。通过这些范例,你应该可以理解解释器的运行原理。
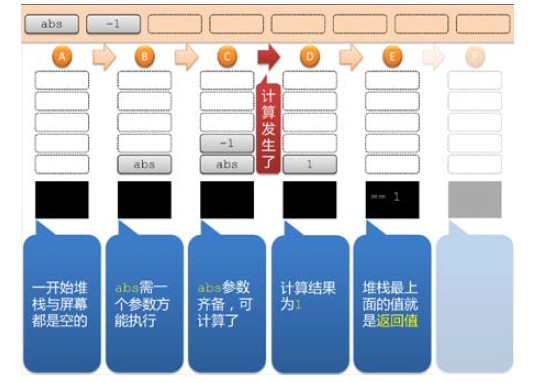
对于abs -1 这段代码来说,会被剪成两个值:abs 与-1,然后开始执行。
在状态A,堆栈与屏幕都是空的。然后把abs 放进堆栈中,abs 是求绝对值的函数,它后面
需要跟着一个数字,但堆栈中目前只有abs 自己,所以执行不了,这是状态B。
到了状态C,-1 也被放进堆栈。有了这一个参数,abs 终于可以计算了,计算方式是把这两
个值都从堆栈中取出,计算之后得到的值是1,再把1 放回堆栈,现在是状态D。
内存中的代码已经执行完毕,堆栈中也没有任何进一步的计算要进行,这表示程序要结束了。
结束时,堆栈中剩下的1 就是返回值。所以在状态E 中,我们看到堆栈被清空,但屏幕上出
现== 1。
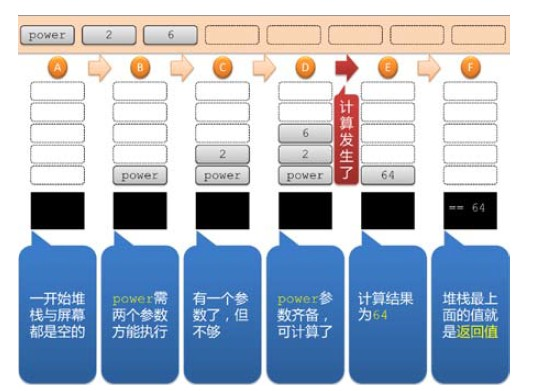
对于power 2 6 这段代码来说,会被剪成power、2、6 这三个值,然后开始执行。
在状态A,堆栈与屏幕都是空的。然后把power 放进堆栈中,成为状态B。power 是求幂的
函数,它后面需要跟着两个数字,分别是底数与指数,所以目前计算不了。状态C,把2 放进
堆栈,依然无法执行。
状态D,把6 放进堆栈,现在power 的两个参数都到齐了,可以计算了。方式是把三个值都
取出来计算,结果得到64,再把结果放回堆栈,进入状态E。
内存中的代码已经执行完毕,堆栈中也没有任何进一步的计算要进行。这表示程序要结束了。
结束时,堆栈中剩下的64 就是返回值。所以在状态F 中,我们看到堆栈被清空,但屏幕上出
现== 64。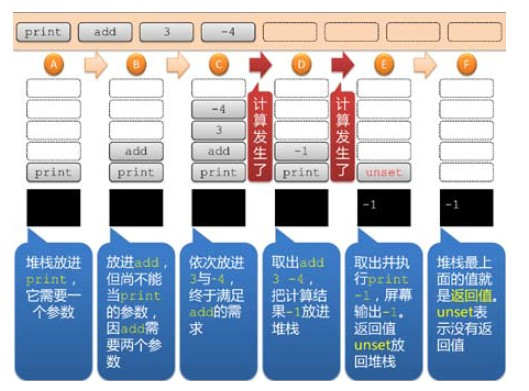
对于print add 3 -4 这段代码来说,会被剪成print、add、3、-4 这四个值,然后
解释其原理

开始执行。
先把print 放进堆栈,进入状态A。print 需要一个参数,所以此时无法计算。再把add 放
进堆栈,进入状态B。add 现在无法当做print 的参数,因为add 自己就是一个函数,必须
等add 计算完毕的值才能当print 参数。add 需要两个参数。
3 与-4 被依次放进堆栈,进入状态C。这个时候,add 的两个参数已经到齐,可以计算了。
把这三个值取出来,计算之后得到结果-1,把-1 放回堆栈,现在是状态D。
这个时候,print 需要的参数(-1)已经出现了,取出这两个值,计算(执行)的结果是屏
幕上出现-1。print 是没有返回值的。没有返回值也就是说返回值是一个特殊值unset(未
设)。把unset 放进堆栈中。现在状态是E。
内存中的代码已经执行完毕,堆栈中也没有任何进一步的计算要进行。这表示程序要结束了。
结束时,堆栈中剩下的特殊值unset 就是返回值,返回值为特殊值unset 相当于没有返回值。
所以在状态F 中,我们看到堆栈被清空,屏幕中没有出现==。

对于power 2 6 abs add 3 -4 这段代码来说,会被剪成power、2、6、abs、add、3、
-4 这7 个值,然后开始执行。
把power、2、6 依次放进堆栈,进入状态A。终于可以计算了,计算之后进入状态B。堆栈
中已经没有任何进一步的计算要进行,但内存中还有后续的代码,所以尚未结束。
把内存中的abs、add、3、-4 依次放进堆栈,进入状态C。终于可以计算了,取出最上面的
三个值,计算之后把结果-1 放回堆栈,进入状态D。状态D 也可以计算,取出两个值,计算
结果1 放回堆栈,进入状态E。
内存中的代码已经执行完毕,堆栈中也没有任何进一步的计算要进行。这表示程序要结束了。
结束时,堆栈中若有多个值,最上层的值就是返回值。所以在状态F 中,我们看到堆栈被清空,
屏幕中出现== 1,而64 直接被扔了。

这个例子其实有两个段落,所以最后堆栈会有两个值。段落之间彼此独立,因此写代码时,我
们喜欢让段落之间换行,可以帮助阅读理解。
每次发生计算,其实就是找到一个段落。堆栈最后的值分别由power 与abs 产生,所以它们
两个就是段落的起点。
既然每次发生计算就是一个段落,那么add 应该也是段落的起点。但因为add 只是abs 的一
部分(也就是说它是abs 段落的子段落),而且add 没有兄弟段落(power 与abs 在这里就
是兄弟关系,是平级的),再说abs 太简单,让abs 和add 摆一起比较好。把add 段落拆出
去没有太大必要。
最后一个例子。对于power 26 print add 3 -4 这段代码来说,这个例子和前一个例子
差不多,只是abs 换成了print。这导致状态E 的堆栈中有两个值,而最上面的值是特殊值
unset。
尽管最后堆栈中存在一个有效值64,但只有最上面的值才是返回值。unset 表示没有返回值。
---------------------
作者:博文视点
来源:CSDN
原文:https://blog.csdn.net/broadview2006/article/details/7827641
版权声明:本文为博主原创文章,转载请附上博文链接!