MySQL 教程
用户和权限
创建用户:
%代表匹配任意值
create user 'username'@'192.168.1.1' identified by 'password';
create user 'username'@'192.168.1.%' identified by 'password';
create user 'username'@'%' identified by 'password'; # % 代表任意ip地址的用户都行
删除用户:
drop user 'username'@'ip';
重命名用户:
rename user 'username'@'ip' to 'new_username'@'new_ip';
授权:
grant [权限] on [database].[table] to 'username'@'ip'
all privileges代表所有权限* 代表所有,意思是数据库下所有表
grant select,insert,update on mysql.user to 'username'@'%';
grant all privileges on [database].[table] to 'username'@'ip';
grant all privileges on [database].* to 'username'@'ip';
撤销授权:
revoke 权限 from [database].[table] to 'username'@'ip';
查看授权:
show grants for 'username'@'ip'
数据库
查看数据库:
show databases;
创建数据库:
charset 可以设置默认字符集
engine 可以设置数据库引擎
create database [database_name] default charset=utf8;
使用数据库:
use [database_name];
删除数据库:
drop database [database_name];
表
查询有哪些表:
show tables;
创建表
表的每一列定义:列名 数据类型 [是否为空] [default value] [是否可以自增] [是否是主键]
auto_increment 自增;primary key 主键
create table [table_name] (column1 data_type , column2,...);
create table student(id int not null auto_increment primary key , name char(10) default 'anyone') engine=innodb default charset=utf8;
删除表:
drop table [table_name];
查看表结构:
desc [table_name];
查看表创建语句:
show create table [table_name] \G
修改表下次自增的起始数:
alter table [table_name] AUTO_INCREMENT=10;
表中数据
增
插入数据:
insert into [table_name](column1,...) values(column1,...),(column1,...),...; # values后面的括号,每个括号相当于一行数据
mysql> insert into student(id,name) values(1,'zhangsan');
插入另一个表中已有的数据:
insert into [table_name](column1,...) select column1,... from [another_table_name]; # 从另一个表中复制某些列数据,插入当前表的对应列中
查询数据:
mysql> select * from student;
+----+----------+
| id | name |
+----+----------+
| 1 | zhangsan |
+----+----------+
删
清除表的数据:
两种方法都行,可以清空表格所有数据
delete from [table_name]; # 删除表中所有数据
truncate table [table_name]; # 删除表中所有数据
delete from [table_name] where [condition] # 删除满足条件的语句
# ====================
delete from student where age>22 and name='wztshine' # 删除满足条件的语句
改
update [table_name] set [column]='value' where [condition] # condition条件:id=2
# ====================
update student set age=18,name='wang' where id=2
查
select * from [table];
select col1,col2,... from [table];
select col1,col2,... from [table] where [condition];
select * from [table] where id between 1 and 3;
select * from [table] where name like "%a" # % 匹配任意多个字符
select * from [table] where name like "zhang_" # _ 匹配任意一个字符
select column1 as col1 from [table]; # 重命名列名
select [table].[column] from [table1]
limit
select * from [table] limit 10; # 取数据库前10条数据
select * from [table] limit 1,10; # 跳过1个数据,从第二条数据开始,往后取10条(不是截止到10,是往后数10个)
select * from [table] limit 10 offset 1; # 从第二条数据开始,往后取10条(不是截止到10,是往后数10个)。和上一个命令一样。
排序:
select * from [table] order by id desc; # 按照 id 降序排序(从大到小)
select * from [table] order by id asc; # 升序排序(从小到大)
select * from [table] order by column1 desc, column2 acs,...;
分组:
假设一个表有 id, name 两列。如果我们想用 id 分组,因为一个id 可能对应多个 name。记住分完组以后,查询出来的表内数据要是 一对一 的。也就是说按照 id 分组,所有相同的 id 会合并变成一条数据,所以原本的 name 列就不能要了:如我们可以计算一下每个id 对应的 name 的数量 。
分组后的数据过滤,必须使用 having , where 只是用于单行的过滤。
select count(id),max(grade) from student group by id;
select id,name from student group by id having id>2; # 分组后过滤 id>2 的数据,这里我们认为id和name是一对一的,不会重复
连表:
select * from [table1],[table2]; # 两个表的笛卡尔积,第一个表的每条数据都会和第二表的每条数据产生一个新数据
select * from [table1],[table2] where [table1].[column] = [table2].[column]; # 内连接,两者的交集部分
select * from [table1] inner join [table2] on [table1].[col] = [table2].[col] # 内链接,和上面一样
select * from [table1] left join [table2] on [table1].[column] = [table2].[column]; # 左连接,只保留左表中的数据
select * from [table1] right join [table2] on [table1].[column] = [table2].[column]; # 右连接,只保留右表中的数据
# 全连接
select * from [table1] left join [table2] on [table1].[column]=[table2].[column]
UNION
select * from [table1] right join [table2] on [table1].[column]=[table2].[column]
约束
主键约束:
primary key 可以设置主键约束,其中可以多个列设置联合主键,也可以单独一列做主键。
create table [table_name](
column1 col_type ...,
column2 col_type ...,
...,
primary key(column1,column2...)
);
# ===================================
create table student(id int auto_increment, name varchar(10), primary key(id,name));
外键约束:
先创建一个班级表。
然后创建 student 表,声明主键是 id
constraint 不重复的约束名字 foreign key(本表的列名) references 关联的表(关联表的列名)
create table class(cid int not null primary key, cname char(10));
mysql> create table student(
-> sid int auto_increment,
-> name varchar(10),
-> cid int,
-> primary key(sid),
-> constraint stu_class foreign key(cid) references class(cid)
-> );
唯一性约束:
unique (列名,...)
unique 可以约束数据,使数据不允许有重复值,可以多列联合起来。
create table [table_name](
column1 col_type,
...,
unique(column1, ...)
);
# =====================
create table t(
id int auto_increment primary key,
name varchar(10),
unique (name));
mysql> insert into t(name) values('wang');
Query OK, 1 row affected (0.17 sec)
mysql> insert into t(name) values('wang');
ERROR 1062 (23000): Duplicate entry 'wang' for key 'name'
数据库:
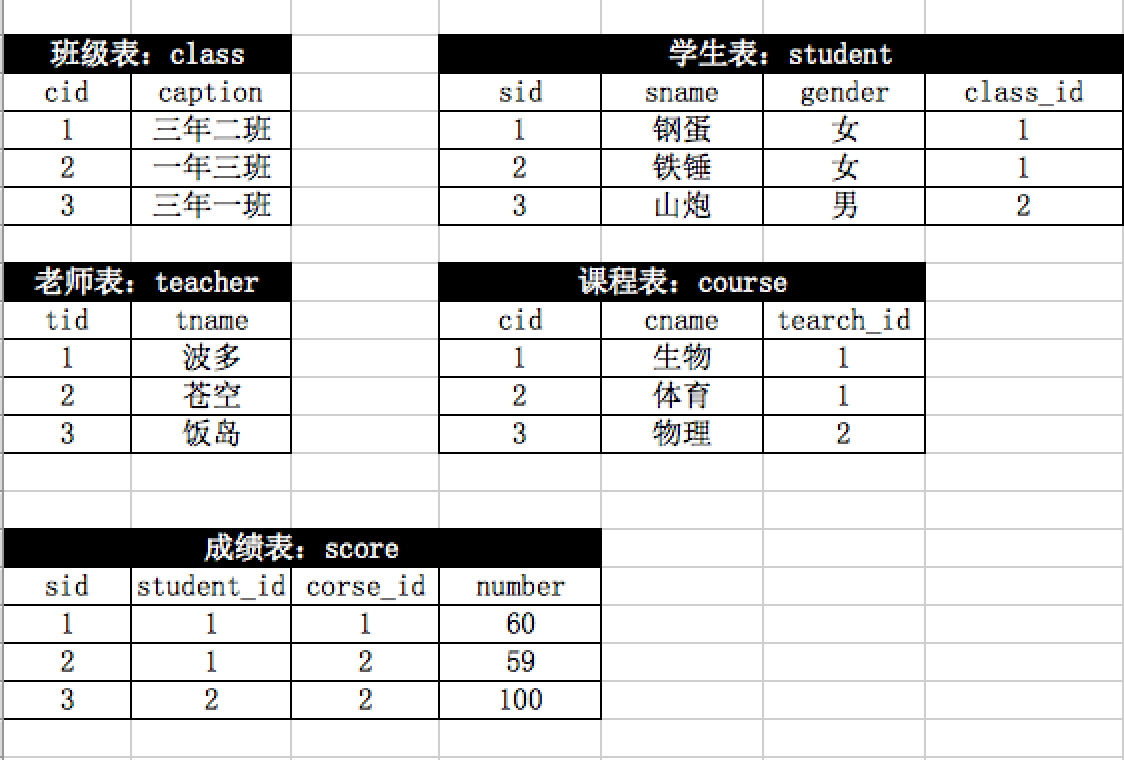
/*
Navicat Premium Data Transfer
Source Server : localhost
Source Server Type : MySQL
Source Server Version : 50624
Source Host : localhost
Source Database : sqlexam
Target Server Type : MySQL
Target Server Version : 50624
File Encoding : utf-8
Date: 10/21/2016 06:46:46 AM
*/
SET NAMES utf8;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for `class`
-- ----------------------------
DROP TABLE IF EXISTS `class`;
CREATE TABLE `class` (
`cid` int(11) NOT NULL AUTO_INCREMENT,
`caption` varchar(32) NOT NULL,
PRIMARY KEY (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `class`
-- ----------------------------
BEGIN;
INSERT INTO `class` VALUES ('1', '三年二班'), ('2', '三年三班'), ('3', '一年二班'), ('4', '二年九班');
COMMIT;
-- ----------------------------
-- Table structure for `course`
-- ----------------------------
DROP TABLE IF EXISTS `course`;
CREATE TABLE `course` (
`cid` int(11) NOT NULL AUTO_INCREMENT,
`cname` varchar(32) NOT NULL,
`teacher_id` int(11) NOT NULL,
PRIMARY KEY (`cid`),
KEY `fk_course_teacher` (`teacher_id`),
CONSTRAINT `fk_course_teacher` FOREIGN KEY (`teacher_id`) REFERENCES `teacher` (`tid`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `course`
-- ----------------------------
BEGIN;
INSERT INTO `course` VALUES ('1', '生物', '1'), ('2', '物理', '2'), ('3', '体育', '3'), ('4', '美术', '2');
COMMIT;
-- ----------------------------
-- Table structure for `score`
-- ----------------------------
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`student_id` int(11) NOT NULL,
`course_id` int(11) NOT NULL,
`num` int(11) NOT NULL,
PRIMARY KEY (`sid`),
KEY `fk_score_student` (`student_id`),
KEY `fk_score_course` (`course_id`),
CONSTRAINT `fk_score_course` FOREIGN KEY (`course_id`) REFERENCES `course` (`cid`),
CONSTRAINT `fk_score_student` FOREIGN KEY (`student_id`) REFERENCES `student` (`sid`)
) ENGINE=InnoDB AUTO_INCREMENT=53 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `score`
-- ----------------------------
BEGIN;
INSERT INTO `score` VALUES ('1', '1', '1', '10'), ('2', '1', '2', '9'), ('5', '1', '4', '66'), ('6', '2', '1', '8'), ('8', '2', '3', '68'), ('9', '2', '4', '99'), ('10', '3', '1', '77'), ('11', '3', '2', '66'), ('12', '3', '3', '87'), ('13', '3', '4', '99'), ('14', '4', '1', '79'), ('15', '4', '2', '11'), ('16', '4', '3', '67'), ('17', '4', '4', '100'), ('18', '5', '1', '79'), ('19', '5', '2', '11'), ('20', '5', '3', '67'), ('21', '5', '4', '100'), ('22', '6', '1', '9'), ('23', '6', '2', '100'), ('24', '6', '3', '67'), ('25', '6', '4', '100'), ('26', '7', '1', '9'), ('27', '7', '2', '100'), ('28', '7', '3', '67'), ('29', '7', '4', '88'), ('30', '8', '1', '9'), ('31', '8', '2', '100'), ('32', '8', '3', '67'), ('33', '8', '4', '88'), ('34', '9', '1', '91'), ('35', '9', '2', '88'), ('36', '9', '3', '67'), ('37', '9', '4', '22'), ('38', '10', '1', '90'), ('39', '10', '2', '77'), ('40', '10', '3', '43'), ('41', '10', '4', '87'), ('42', '11', '1', '90'), ('43', '11', '2', '77'), ('44', '11', '3', '43'), ('45', '11', '4', '87'), ('46', '12', '1', '90'), ('47', '12', '2', '77'), ('48', '12', '3', '43'), ('49', '12', '4', '87'), ('52', '13', '3', '87');
COMMIT;
-- ----------------------------
-- Table structure for `student`
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`gender` char(1) NOT NULL,
`class_id` int(11) NOT NULL,
`sname` varchar(32) NOT NULL,
PRIMARY KEY (`sid`),
KEY `fk_class` (`class_id`),
CONSTRAINT `fk_class` FOREIGN KEY (`class_id`) REFERENCES `class` (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `student`
-- ----------------------------
BEGIN;
INSERT INTO `student` VALUES ('1', '男', '1', '理解'), ('2', '女', '1', '钢蛋'), ('3', '男', '1', '张三'), ('4', '男', '1', '张一'), ('5', '女', '1', '张二'), ('6', '男', '1', '张四'), ('7', '女', '2', '铁锤'), ('8', '男', '2', '李三'), ('9', '男', '2', '李一'), ('10', '女', '2', '李二'), ('11', '男', '2', '李四'), ('12', '女', '3', '如花'), ('13', '男', '3', '刘三'), ('14', '男', '3', '刘一'), ('15', '女', '3', '刘二'), ('16', '男', '3', '刘四');
COMMIT;
-- ----------------------------
-- Table structure for `teacher`
-- ----------------------------
DROP TABLE IF EXISTS `teacher`;
CREATE TABLE `teacher` (
`tid` int(11) NOT NULL AUTO_INCREMENT,
`tname` varchar(32) NOT NULL,
PRIMARY KEY (`tid`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `teacher`
-- ----------------------------
BEGIN;
INSERT INTO `teacher` VALUES ('1', '张磊老师'), ('2', '李平老师'), ('3', '刘海燕老师'), ('4', '朱云海老师'), ('5', '李杰老师');
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;
以下查询结果仅供参考,本人未实际验证,仅适用于上文图片中的表设计。
参考自:https://www.cnblogs.com/wupeiqi/articles/5748496.html
1. 查询所有数学成绩比语文成绩高的学生学号和姓名
分析:
-
想要找到数学成绩比语文成绩高的同学,也就是说一个学生自身的两门课程进行对比
-
我们分别获取学生的数学成绩和语文成绩作为两张表,然后两张表再对比
-
获取数学成绩,将 课程表和成绩表关联起来,获取数学成绩
select student_id, corse_id, number from score left join course on score.course_id = course.cid where course.cname='数学' -
获取语文成绩,同上
select student_id, corse_id, number from score left join course on score.course_id = course.cid where course.cname='语文' -
将上面两个表再次根据 学号 关联起来,对比数学和语文成绩
select student_id,number from [上面数学表] as A left join [上面的语文表] as B on A.student_id = B.student_id where A.number > B.number
-
2. 查询平均成绩大于60分的同学的学号和平均成绩;
分析:
- 平均成绩,这个词就意味着要对 一组数 求平均值,分组依据是学号
- 成绩大于 60 分,意味着要筛选,使用
having
- 成绩大于 60 分,意味着要筛选,使用
select student_id,avg(number) from score group by student_id having avg(number) > 60
3. 查询所有同学的学号、姓名、选课数、总成绩;
分析:
- 先找关键字:总成绩,选课数。因为学号,姓名都是表中以有的字段,最多通过表关联就能获取。而总成绩之类的数据,是需要特殊处理才会出现的,因此先看这些特殊关键字。
- 总成绩,选课数,肯定需要进行一组数据汇总,所以要按照学号分组
select student_id, count(student_id),sum(number) from score group by student_id # 想查询姓名,再关联一次表就行了,此处没写
4.查询姓“李”的老师的个数;
分析:
- 姓“李” 肯定是个筛选条件
- 求老师的个数,不能用分组,因为没有分组依据,所以使用模糊查询
select count(id) from teacher where tname like "李%"
5. 查询没学过“叶平”老师课的同学的学号、姓名;
分析:
- 先找到所有学过此老师课程的学生
- 从所有学生中排除学过他课程的学生,不就是没学过的嘛
# 1. 查询叶平教过的所有课程id
select course.cid from course left join teacher on teacher.tid = course.teacher_id where tname="叶平"
# 2. 排除课程
select student_id from score where score.course_id not in [上面查询出来的叶平的课程id表]
6. 查询学过“001”并且也学过编号“002”课程的同学的学号、姓名;
分析:
- 筛选出所有 001,002 有关的课程信息
- 针对每一个学生,统计课程个数(等于2说明这两门都选了),用到了分组
# 1. 和 001,002有关的所有学生学号
select student_id from score where course_id in (001, 002)
# 2. 统计个数
select student_id from [上面查询的表] group by student_id having count(student_id) =2
7. 查询有课程成绩小于60分的同学的学号、姓名;
分析:
- 找到有成绩小于60的同学
- 获取学号,姓名,关联表就行
# 找到有分数小于60的学号
select distinct student_id from score where number<60
# 学号和姓名关联
select student_id,sname from [上面查询到的表] as A left join student
on A.student_id = student.sid
8. 查询没有学全所有课的同学的学号、姓名;
- 首先找到所有的课程总数
- 统计每个学生学的课程数:分组计数
- 如果学生学的课程数不等于总数,就没学全
# 获取课程总数
select count(1) from course
# 统计每个学生的课程数,并判断是否等于总数
select student_id from score
group by student_id
having count(course_id)=(select count(1) from course)
9. 查询至少有一门课与学号为“001”的同学所学相同的同学的学号和姓名;
- 先找到 001 同学学的所有课程
- 只要其他同学学过这些课程中的任意一个就行
# 001 同学学过的课程号
select course_id from score where student_id = 001
# 学过上面课程中任一个的同学
select student_id from score where student_id != 001 and course_id in [上面的表]
10. 查询至少学过学号为“001”同学所有课的其他同学学号和姓名;
- 先找到001同学学过的所有课,还有课程总数
- 找到其他同学这些课程的记录
- 统计每个同学的课程数量(分组),如果等于 001 学过的课程总数,就说明满足条件了
# 1. 001 学过的课程号
select course_id from score where student_id = 001
# 2. 001 学过的课程数量
select count(1) from [第一步的表]
# 3. 其他同学关于这些课程的记录
select student_id from score where student_id != 001 and course_id in [第一步的表]
# 4. 分组统计第三步表格的记录,看数量是否满足条件
select student_id from [第三步的表] group by student_id having count(student_id)=[第二步的表]
11. 查询和“002”号的同学学习的课程完全相同的其他同学学号和姓名;
- 先找到001同学学过的所有课,还有课程总数
- 找到其他同学这些课程的记录
- 统计每个同学的课程数量(分组),如果等于 001 学过的课程总数,就说明满足第一个条件(至少包含了001所学的课程)
- 然后不设限制,分组获取每个同学学过的所有课程数,如果这个课程数和第三部的课程数一样,表明此学生没有学习过额外的课程
# 1. 001 学过的课程号
select course_id from score where student_id = 001
# 2. 001 学过的课程数量
select count(1) from [第一步的表]
# 3. 其他同学关于这些课程的记录
select student_id,course_id from score where student_id != 001 and course_id in [第一步的表]
# 4. 分组统计第三步表格的记录,看数量是否满足条件
select student_id,count(course_id) as num1 from [第三步的表] group by student_id having count(student_id)=[第二步的表]
# 5. 统计每个同学学过的所有课程数
select student_id,count(course_id) as num2 from score group by student_id
# 6. 第四步和第五步的表联合起来
select student_id from [表4] as A left join [表5] as B
on A.student_id = B.student_id and A.num1 = B.num2
12. 删除学习“叶平”老师课的score表记录;
分析:
- 先找到叶平老师的课程,也就是 score表和 teahcer表关联
- 从score表中删掉上面查出来的课程
# 找到叶平老师的课程
select cid from course left join teacher on teacher.tid = course.teacher_id where teacher.tname = '叶平'
# 删除这些课程
delete from score where course_id in [上面查询出来的表]
13. 向Score表中插入一些记录:将没上过001课程的学生,给他们设置001课程的成绩(成绩设置为现有所有001课程成绩的平均值)
分析:
- 获取没学过001课程的学生号;获取001现有成绩平均值 (分组)
- 插入数据,insert 支持插入查询结果:
insert into table1(col1,col2,..) select col1,col2,... from table2
# 1. 学过001课程的学生
select student_id from score where course_id = 001
# 2. 没学过001课程的学生
select student_id from score where student_id not in [上表]
# 3. 001 的平均成绩
select avg(number) from score where course_id = 001
# 插入
insert into score(student_id, course_id,number) select student_id,001,[第三步的成绩表] from [第二步的表]
14. 显示所有学生的“语文”、“数学”、“英语”三门的课程成绩,按如下形式显示: 学生ID,语文,数学,英语
分析:
- 需要“语文”,“数学”,“外语” 这三个课程的成绩,正常来说,这三个课程的成绩是在一同列:score.number 列的不同行中间,现在我们想要将这些数据行依据学生id,来放到相应的三列中。
- 我们用子查询来获取三种不同的课程成绩,但是课程成绩是要和学生id对应上,因此需要在子查询中添加限制条件:子查询中某表.id = 父查询出来的某.id ,体现在代码中就是:
- select s1.sid, (select s2.number from score as s2 where s2.sid=s1.sid) from score as s1
select
sid,
(select s2.number from score as s2 left join course on course.cid=s2.course_id where cname='语文' and s2.sid=s1.sid) as chinese,
(select s2.number from score as s2 left join course on course.cid=s2.course_id where cname='数学' and s2.sid=s1.sid) as math,
(select s2.number from score as s2 left join course on course.cid=s2.course_id where cname='外语' and s2.sid=s1.sid) as eng
from score as s1
15. 查询各科成绩最高和最低的分:以如下形式显示:课程ID,最高分,最低分;
- 需要每个科目的最高分和最低分,显然我们需要分别对每个科目(分组),挑出最高和最低分
select course_id,max(number),min(number) from score group by course_id;
16. 按各科平均成绩从低到高和及格率的百分数从高到低顺序;
- 及格率,肯定需要先统计多少人及格和总人数,然后才能算出来,我们可以通过
case when ... then ... end语句来实现:select sum(case when score.number>=60 then 1 else 0 end) as percent from score group by score.course_id - 各科的平均成绩,涉及到针对每一科的操作,需要分组。
select avg(score.number) as avg_num, sum(case when score.number>=60 then 1 else 0 end)/count(1) as percent from score group by course_id order by avg_num asc,percent desc;
17. 课程平均分从高到低显示(显示任课老师名字);
- 课程平均分(分组),从高到低(排序),老师名字(连表)
- 所以连表,分组查询
select course_id, avg(score.number) as num from score
left join course on course.cid = score.course_id
left join teacher on teacher.tid = course.teacher_id
group by score.course_id
order by num desc;
18. 查询各科成绩前三名的记录:(不考虑成绩并列情况)
分析:(写的很乱,直接看实现代码吧)
- 先找到每科第一名和第四名的成绩表,格式为:科目id | 第一名成绩 | 第四名成绩
- 用上面这个表和score进行连表,条件是成绩小于等于第一名,大于第四名
- 现在难点是如何将每科成绩并列放置成两列,形成第一步的那种格式
- 我们知道,我们可以从数据库中选择一个常数,就会形成一个新列:
select 1 from score;, 所以我们只要用子查询获取到某个成绩就行了。 - 在编程语言中,通常有个
for循环语法,可以遍历数据,然后在循环内部进行某些操作,在数据库中,也有类似的思想,下面我对这种思想用python和mysql进行比较:
# 假设数据库表 people:
id name age
1 wang 22
2 zhang 23
3 huang 29
4 liang 30
# 以下两者等同:
# ================== mysql:
select people.id from people;
# ================== python(假设python把数据库当成列表,每行都是列表的一个元素,并且每行都是一个对象,id,name等字段是这个对象的属性)
ls = [] # 模拟一个表,用来存放查询结果(因为mysql是一次性显示出结果的,而不是边查询边显示)
for line in people:
ls.append(line.id)
print(ls) # 最后显示查询结果
# ================== mysql
select p1.id, (select age from people as p2 where p2.id=p1.id order by p2.age desc limit 1) from people as p1;
# ================== python
ls = []
for line in people:
ls_2 = [] # 这个列表用来存放子查询的临时结果
for line2 in people: # 内部又一次遍历,用来模拟子查询
if line.id == line2.id: # 模拟 where p2.id=p1.id 这个条件
ls_2.append(line2.age) # 模拟满足条件的查询结果(这个结果只是临时的,还没有排序呢)
ls_2.sort(reverse=True) # 模拟对查询结果 order by 排序
ls.append([line.id, ls_2[0]]) # ls[0] 模拟 limit 1
print(ls)
select * from score left join (
select s1.sid,
(select number from score as s2 where s2.course_id = s1.course_id order by number desc limit 1) as num1,
(select number from score as s2 where s2.course_id = s1.course_id order by number desc limit 3,1) as num4,
from score as s1
) as table1
on table1.sid = score.sid
where score.number <= table1.num1 and score.number>=table1.num4;
22. 查询每门课程被选修的学生数
- 针对每门课程统计学生数量(分组)
select count(student_id),course_id from score group by course_id;
23. 查询出只选修了一门课程的全部学生的学号和姓名;
- 统计每个学生学的课程数量(分组)
- 筛选条件是只学了一门课程(having )
- 要获取姓名,和 student 表关联
# 查询只修了一门课程的学生
select student_id from score group by student_id having count(course_id) = 1
select student_id,sname from 【上表】as T1 left join student on student.sid=T1.student_id
24. 查询男生、女生的人数;
- 每个性别的人数,分组
select gender,count(sid) from student group by gender;
25. 查询姓“张”的学生名单
模糊查询: %
select * from student where student.sname like '张%'
26. 查询同名同姓姓名和同名人数;
同名人数,即按照人名分组,统计人数
select sname,count(1) from student group by sname;
27. 查询每门课程的平均成绩,结果按平均成绩升序排列,平均成绩相同时,按课程号降序排列;
- 每门课程,平均成绩(group by)
- 排序(order by)
select course_id,avg(number) as avg_num from score group by course_id order by avg_num asc, course_id desc;
28. 查询平均成绩大于85的所有学生的学号、姓名和平均成绩;
- 需要获取每个学生的平均成绩(按照学生分组查询)
- 过滤条件成绩大于85(having)
- 获取姓名(连表)
select student_id,sname,avg(number) from score left join student on student.sid=score.student_id group by student_id having avg(number)>85
29. 查询课程名称为“数学”,且分数低于60的学生姓名和分数;
- 获取的数据应该是:学生姓名,分数
- 过滤条件:分数低于60;课程名称为数学
- 涉及到分数,课程名称,学生姓名,所以需要连表
select sname, number from score
left join course on course.cid = score.course_id where course.cname='数学' and score.number < 60
left join student on student.sid=score.student_id;
30. 查询课程编号为003且课程成绩在80分以上的学生的学号和姓名;
- 获取数据为学生学号,姓名(连表),分数
- 筛选条件:课程编号003,成绩80以上
select student_id, sname, number from score
left join student on student.sid=score.student_id
where course_id=003 and number>80;
31. 求选了课程的学生人数
- 选了课程的人数,只需要从 score 表中找到所有的人数,去重就行了
select count(distinct student_id) from score;
32. 查询选修“杨艳”老师所授课程的学生中,成绩最高的学生姓名及其成绩;
- 先找出“杨艳”教的所有课程
- 找到学了这些课程的所有学生
- 获取最高成绩的人
# 杨艳教过的所有课程id
select cid from course
left join teacher on teacher.tid=course.teacher_id
wehre tname='杨艳'
# 学过上述课程的学生和分数
select student_id,number from score where course_id in [上表] order by number desc limit 1;
33. 查询各个课程及相应的选修人数;
- 按照课程分组,查询每个组的总人数
select course_id, count(1) from score group by course_id;
34. 查询不同课程但成绩相同的学生的学号、课程号、学生成绩;
- score表和自身进行关联,获取笛卡尔积
- 条件是课程号不同,成绩相同
select s1.course_id, s1.student_id,s1.number,s2.course_id,s2.student_id,s2.number from score as s1, score as s2 where s1.course_id != s2.course_id and s1.number = s2.number;
36. 检索至少选修两门课程的学生学号;
- 根据学号分组,查询总课程数至少为2的记录
select student_id from score group by student_id having count(1)>=2;
37. 查询全部学生都选修的课程的课程号和课程名;
- 获取总学生人数
- 根据课程号分组(group by),查询每个课程的选修人数是否等于总学生数(having )
select course_id from score group by course_id having count(1)=(select count(1) from student;)
38. 查询没学过“叶平”老师讲授的任一门课程的学生姓名;
- 找到“叶平” 老师所教过的所有课程
- 找到学过上述课程的所有学生
- 从总学生表中剔除上述学生
# 此老师教的课程id
select cid from course left join teacher on teacher.tid=course.teacher_id where tname = '叶平'
# 学过这个老师课程的学生
select student_id from score where course_id in [上表]
# 剔除学过他课程的学生
select sid in student where sid not in ([上表])
39. 查询两门以上不及格课程的同学的学号;
- 找到所有不及格的课程记录
- 对学生分组,过滤记录数大于2的人
select student_id from score where number < 60 group by student_id having count(1)>2
40. 检索“004”课程分数小于60,按分数降序排列的同学学号;
select student_id,number from score where course_id=004 and number<60 order by number desc;
41. 删除“002”同学的“001”课程的成绩;
delete from score where student_id=002 and course_id = 001