Pandas基础教程-翻译
简单翻译,pivot 部分内容没翻译,小部分内容略有缺失。
安装
pip install pandas
1. 数据类型
想要使用,先导入包:
import pandas as pd
表格数据展示

- 想要展示一群人的数据,如年龄,姓名,性别,如何展示?
df = pd.DataFrame(
{
"Name": [
"Braund, Mr. Owen Harris",
"Allen, Mr. William Henry",
"Bonnell, Miss. Elizabeth",
],
"Age": [22, 35, 58],
"Sex": ["male", "male", "female"],
}
)
df
Out[3]:
Name Age Sex
0 Braund, Mr. Owen Harris 22 male
1 Allen, Mr. William Henry 35 male
2 Bonnell, Miss. Elizabeth 58 female
想要存放表格类型数据,使用 DataFrame 数据类型。当使用包含列表的字典时,字典的键会作为每一列的表头,每个键所对应的值(列表),会作为每列的数据。
注意最左边一列的0,1,2. 这是每一行的行索引标签。
一个 DataFrame 是一个二维数据结构,可以保存不同的数据类型:文本,整数,浮点数...,它有有点像一个电子表格,一个 SQL 表等。
在电子表格中,上面的数据,有点像这样:
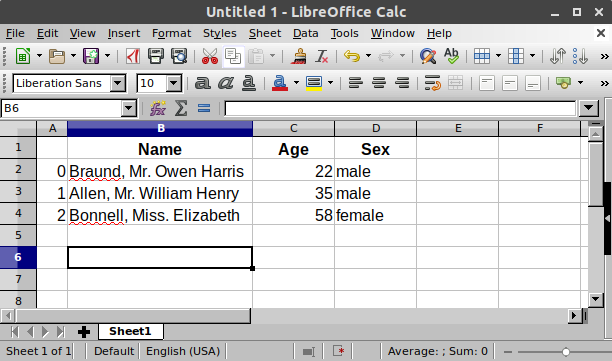
DataFrame 中的每一列数据,都是 Series 类型。

只想要 Age 列数据:
df["Age"]
Out[4]:
0 22
1 35
2 58
Name: Age, dtype: int64
可以看出,取某一列的方式,有点像python基于键来获取值的方式。
你也可以自己创建一个 Series
ages = pd.Series([22, 35, 58], name="Age")
ages
Out[6]:
0 22
1 35
2 58
Name: Age, dtype: int64
pandas Series 没有列标签,它就是一个单独的列。当然,Series有行标签。
使用 Series
- 想知道人群的最大年龄:
选中 Age 列,然后使用 max()
df["Age"].max()
Out[7]: 58
或者,直接使用Series:
ages.max()
Out[8]: 58
- 想知道年龄的一些基础统计分析
df.describe()
Out[9]:
Age
count 3.000000
mean 38.333333
std 18.230012
min 22.000000
25% 28.500000
50% 35.000000
75% 46.500000
max 58.000000
describe() 对数字类型的数据,提供了一个基础的统计总览。Name,Sex 列是文本类型的,因此不能使用此方法。
REMEMBER
导入包:
import pandas as pd表格类型数据: DataFrame
表格的每一列数据都是:Series
对 DataFrame 或 Series,可以应用一些方法
更深入数据结构:data strutures
2. 读写表格数据
titanic = pd.read_csv("data/titanic.csv")
pandas 提供了 read_csv() 来读取 csv 文件到 DataFrame 中。还可以读取其他文件:(csv, excel, sql, json, parquet, …), 每个方法的前缀都是:read_*
确保每次读取完,都检查一下读取的数据。当展示 DataFrame 时,默认显示前5行和后5行:
titanic
Out[3]:
PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male ... 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female ... 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female ... 0 STON/O2. 3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female ... 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male ... 0 373450 8.0500 NaN S
.. ... ... ... ... ... ... ... ... ... ... ...
886 887 0 2 Montvila, Rev. Juozas male ... 0 211536 13.0000 NaN S
887 888 1 1 Graham, Miss. Margaret Edith female ... 0 112053 30.0000 B42 S
888 889 0 3 Johnston, Miss. Catherine Helen "Carrie" female ... 2 W./C. 6607 23.4500 NaN S
889 890 1 1 Behr, Mr. Karl Howell male ... 0 111369 30.0000 C148 C
890 891 0 3 Dooley, Mr. Patrick male ... 0 370376 7.7500 NaN Q
[891 rows x 12 columns]
Ques: 我想展示前8行,怎么办?
titanic.head(8)
Out[4]:
PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male ... 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female ... 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female ... 0 STON/O2. 3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female ... 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male ... 0 373450 8.0500 NaN S
5 6 0 3 Moran, Mr. James male ... 0 330877 8.4583 NaN Q
6 7 0 1 McCarthy, Mr. Timothy J male ... 0 17463 51.8625 E46 S
7 8 0 3 Palsson, Master. Gosta Leonard male ... 1 349909 21.0750 NaN S
[8 rows x 12 columns]
想看前 N 行数据,使用 head(N) 方法。同样,想看后多少行,用:titanic.tail(N)
想知道各列的数据类型,用 dtypes 属性
titanic.dtypes
Out[5]:
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object
integers (int64), floats (float64), strings (object).
Ques: 如何导出成为电子表格?
titanic.to_excel("titanic.xlsx", sheet_name="passengers", index=False)
之前我们使用 read_* 方法来读取文件,现在可以使用 to_* 来导出文件。sheet_name 可以设置自定义表单名称,而不是用默认的'Sheet1', index=False 可以禁止行索引标签出现在表格中。
如果我们想读取到刚才保存的那个文件,对应的代码是:
titanic = pd.read_excel("titanic.xlsx", sheet_name="passengers")
titanic.head()
Out[8]:
PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male ... 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female ... 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female ... 0 STON/O2. 3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female ... 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male ... 0 373450 8.0500 NaN S
[5 rows x 12 columns]
Ques: 我想知道整个 DataFrame 的概括信息?
titanic.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
info() 可以显示一个 DataFrame 的基础信息. 信息大致如下:
它确实是一个 DataFrame 类型。
它有 891 行,索引从 0 - 890
总共有 12 列数据
索引为 0 的 PassengerId 列,它有 891 行 非空数据,此列格式是 int64(整数型)
索引为 5 的 Age 列,它有 714 行非空数据,此列格式是 float64(浮点型)
...
REMEMBER
-
从文件读取:read_* 方法.
-
导出到文件:to_* 方法.
-
head/tail/info 方法和 dtypes 属性,可以快速检查一些状态内容。
更多读写功能:more
3. DataFrame 的子集

- 选择某列,可以用:[列名] 的方式,选中
ages = titanic["Age"]
ages.head()
Out[5]:
0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
Name: Age, dtype: float64
DataFrame 的每列,都是 Series 类型, 我们可以用 type 检查一下:
type(titanic["Age"])
Out[6]: pandas.core.series.Series
我们也可以看一下它的 shape
titanic["Age"].shape
Out[7]: (891,)
DataFrame.shape 可以获取一个 DataFrame 或 Series 包含了多少行,多少列:(nrows, ncolumns),因为 Series 是一维数据类型,所以只返回多少行。
- 选择多列数据
age_sex = titanic[["Age", "Sex"]]
age_sex.head()
Out[9]:
Age Sex
0 22.0 male
1 38.0 female
2 26.0 female
3 35.0 female
4 35.0 male
选择多列,将多个列名放到一个列表中,再用[]来选择。返回的数据,同样是一个DataFrame
更多索引信息:indexing and selecting data
过滤 DataFrame

Ques: 我想筛选年龄大于35的人
above_35 = titanic[titanic["Age"] > 35]
above_35.head()
Out[13]:
PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female ... 0 PC 17599 71.2833 C85 C
6 7 0 1 McCarthy, Mr. Timothy J male ... 0 17463 51.8625 E46 S
11 12 1 1 Bonnell, Miss. Elizabeth female ... 0 113783 26.5500 C103 S
13 14 0 3 Andersson, Mr. Anders Johan male ... 5 347082 31.2750 NaN S
15 16 1 2 Hewlett, Mrs. (Mary D Kingcome) female ... 0 248706 16.0000 NaN S
[5 rows x 12 columns]
将筛选条件放到[]中,就可以筛选满足条件的数据
筛选条件:titanic["Age"] > 35, 它用来检查哪些 Age 列哪些数据大于35。
titanic["Age"] > 35
Out[14]:
0 False
1 True
2 False
3 False
4 False
...
886 False
887 False
888 False
889 False
890 False
Name: Age, Length: 891, dtype: bool
上面用到了 '>' 符号,同样的:==, !=, <, <= 这些判断符号也能使用。返回 True 或 False。返回的结果,可以传递给[],用来筛选 True 的那些数据。
Ques: 筛选 2级和3级仓的乘客。
class_23 = titanic[titanic["Pclass"].isin([2, 3])]
class_23.head()
Out[17]:
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S
4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S
5 6 0 3 Moran, Mr. James male NaN 0 0 330877 8.4583 NaN Q
7 8 0 3 Palsson, Master. Gosta Leonard male 2.0 3 1 349909 21.0750 NaN S
注:Pclass 是乘客的舱室类别。有1,2,3三个级别。这里筛选2,3两个级别的乘客。
isin(),和上面所说的 条件判断类似。如果当前 Pcalss 的值是2或3,则返回True。然后通过这种方法筛选。
上面的筛选语句,可以使用 | 连接符,等同于:
class_23 = titanic[(titanic["Pclass"] == 2) | (titanic["Pclass"] == 3)]
当多个条件连接时,必须要将每个条件用小括号'()' 括起来。| 代表 or,& 代表 and
Ques: 筛选非空的年龄的乘客
age_no_na = titanic[titanic["Age"].notna()]
age_no_na.head()
Out[21]:
PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male ... 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female ... 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female ... 0 STON/O2. 3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female ... 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male ... 0 373450 8.0500 NaN S
[5 rows x 12 columns]
notna() 可以返回 True 如果当前行的数据不是空值(Null)的话。因此,也可以放到[]中来筛选数据。
怎么选中特定的行和列

Ques: 我想知道年龄大于35岁的人的名字
adult_names = titanic.loc[titanic["Age"] > 35, "Name"]
adult_names.head()
Out[24]:
1 Cumings, Mrs. John Bradley (Florence Briggs Th...
6 McCarthy, Mr. Timothy J
11 Bonnell, Miss. Elizabeth
13 Andersson, Mr. Anders Johan
15 Hewlett, Mrs. (Mary D Kingcome)
Name: Name, dtype: object
这里我们需要一次性找到年龄大于35的人,然后找到他们的名字。所以之前的方法适用了。我们需要使用 loc/iloc 操作符。当用这两个操作符时如:loc[condition, column]. 逗号之前是我们想要的那些数据行,逗号之后是我们想要的列。
如果你想要多个列名,可以将多个列名写在一个列表中: titanic.loc[titanic["Age"] > 35, ["Name", "Pclass"]]
当使用列名,行标签或条件表达式时,使用 loc 操作符。在逗号的前后,你可以使用单独的标签,一个标签列表,标签切片,条件表达式,甚至直接一个':', 使用冒号意味着你想要选择所有行或者列(类似列表切片).
Ques: 我想选中 10-25行,3-5列的数据
titanic.iloc[9:25, 2:5]
Out[25]:
Pclass Name Sex
9 2 Nasser, Mrs. Nicholas (Adele Achem) female
10 3 Sandstrom, Miss. Marguerite Rut female
11 1 Bonnell, Miss. Elizabeth female
12 3 Saundercock, Mr. William Henry male
13 3 Andersson, Mr. Anders Johan male
.. ... ... ...
20 2 Fynney, Mr. Joseph J male
21 2 Beesley, Mr. Lawrence male
22 3 McGowan, Miss. Anna "Annie" female
23 1 Sloper, Mr. William Thompson male
24 3 Palsson, Miss. Torborg Danira female
[16 rows x 3 columns]
如果你想要基于数据所在表格中的位置选择数据,使用 iloc 操作符。
选中数据后,你还可以直接给选择的数据赋值:
titanic.iloc[0:3, 3] = "anonymous"
titanic.head()
Out[27]:
PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked
0 1 0 3 anonymous male ... 0 A/5 21171 7.2500 NaN S
1 2 1 1 anonymous female ... 0 PC 17599 71.2833 C85 C
2 3 1 3 anonymous female ... 0 STON/O2. 3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female ... 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male ... 0 373450 8.0500 NaN S
[5 rows x 12 columns]
REMEMBER
-
选择子集时,用 []
-
在选择子集的[]中,你可以使用一个单独的行/列标签,一个行/列标签的列表,标签切片,条件表达式,或者冒号
-
用行和列名作为选择工具时,用 loc
-
用基于表格的位置来选择某个子集区域时,用 iloc
-
在使用 loc/iloc 时,可以给选定的区域赋值
4. pandas 作图
会用到 matplotlib 的一些功能,所以可以先去看一下 matplotlib
air_quality = pd.read_csv("data/air_quality_no2.csv", index_col=0, parse_dates=True)
air_quality.head()
Out[4]:
station_antwerp station_paris station_london
datetime
2019-05-07 02:00:00 NaN NaN 23.0
2019-05-07 03:00:00 50.5 25.0 19.0
2019-05-07 04:00:00 45.0 27.7 19.0
2019-05-07 05:00:00 NaN 50.4 16.0
2019-05-07 06:00:00 NaN 61.9 NaN
使用 index_col, parse_dates 参数,来定义将第一列作为索引(默认的行标签索引是0,1,...),然后将格式设置为时间格式。
怎么创建图表

Ques: 我想快速做个可视化图表
air_quality.plot()
Out[5]: <AxesSubplot:xlabel='datetime'>
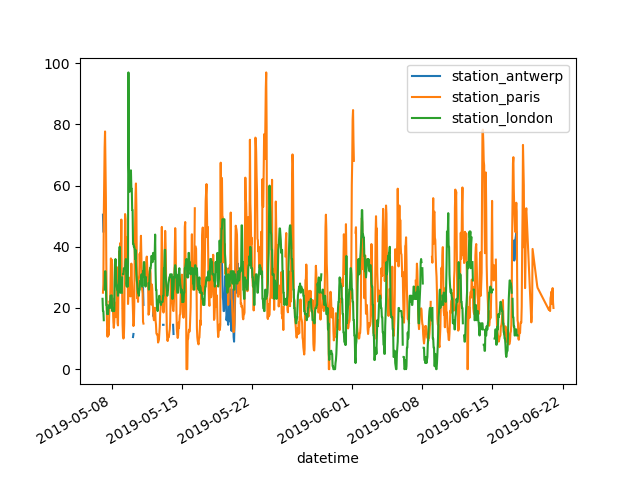
使用 DataFrame时,pandas会默认为每一列创建一条线。
Ques: 只想画出某列的图表
air_quality["station_paris"].plot()
Out[6]: <AxesSubplot:xlabel='datetime'>
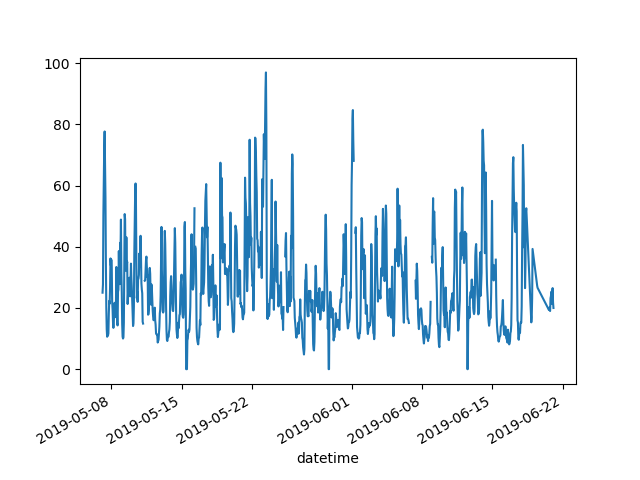
要画某一列数据,先选出子集,然后使用 plot(),就可以画出了。所以,plot() 可以应用于 DataFrame 和 Series
Question:想比较两个城市的二氧化氮值。
air_quality.plot.scatter(x="station_london", y="station_paris", alpha=0.5)
Out[7]: <AxesSubplot:xlabel='station_london', ylabel='station_paris'>
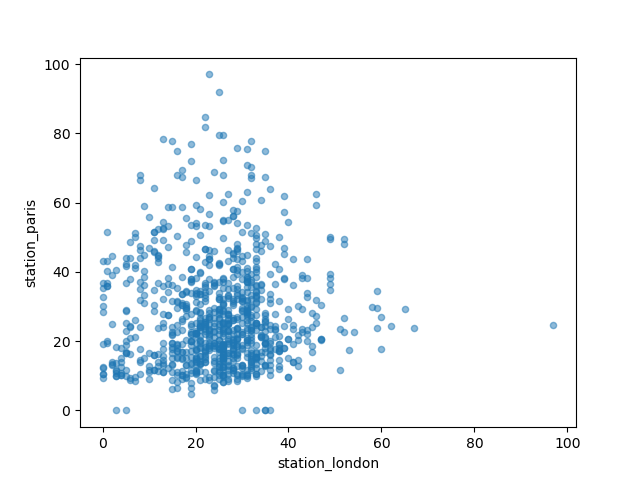
除了默认的折线图,还有一些其他图表类型:
[
method_name
for method_name in dir(air_quality.plot)
if not method_name.startswith("_")
]
Out[8]:
['area',
'bar',
'barh',
'box',
'density',
'hexbin',
'hist',
'kde',
'line',
'pie',
'scatter']
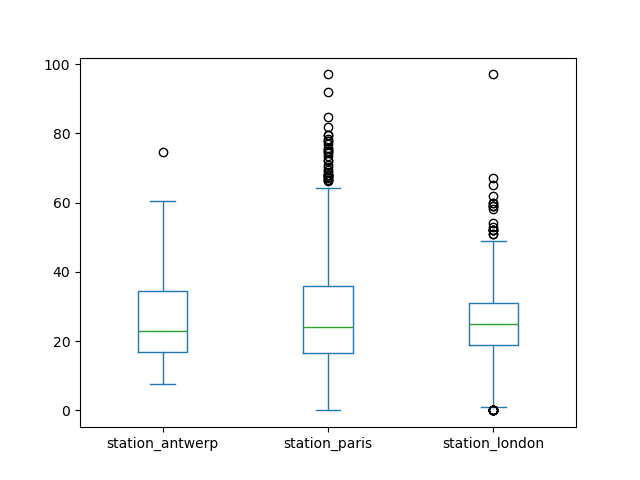
譬如,箱型图:
air_quality.plot.box()
Out[9]: <AxesSubplot:>
Question: 我想每个图表都有一个子图
axs = air_quality.plot.area(figsize=(12, 4), subplots=True)
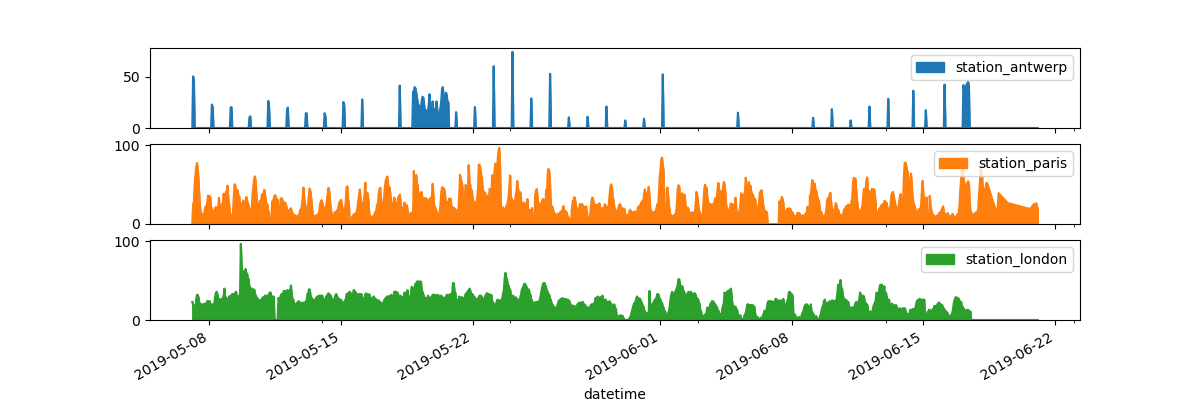
subplots参数,可以让每个图表单独作为一个子图
Question: 我想更深入一些,保存下来图片
fig, axs = plt.subplots(figsize=(12, 4))
air_quality.plot.area(ax=axs)
Out[12]: <AxesSubplot:xlabel='datetime'>
axs.set_ylabel("NO$_2$ concentration")
Out[13]: Text(0, 0.5, 'NO$_2$ concentration')
fig.savefig("no2_concentrations.png")
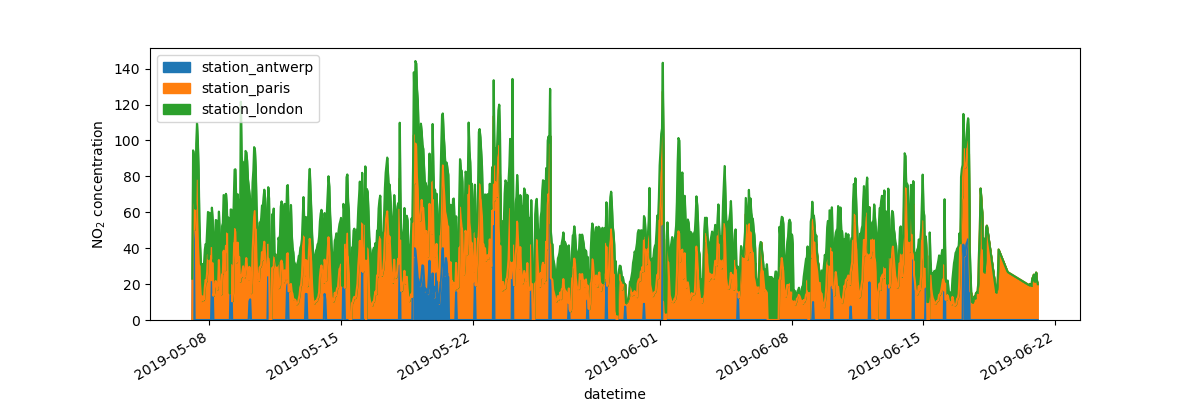
fig, axs = plt.subplots(figsize=(12, 4)) # 创建一个空白的图表和坐标
air_quality.plot.area(ax=axs) # pandas 放置在作图区域
axs.set_ylabel("NO$_2$ concentration") # 做任何 matplotlib 的操作
fig.savefig("no2_concentrations.png") # 用 matplotlib 的操作来保存图片
REMEMBER
- plot.* 方法适用于 Series, DataFrames
- 默认下,每一列会作为一个不同的类型作图(line, boxplot,...)
- 任何 pandas 创建的作图,都是 Matplotlib 对象。
5. 根据已有数据,创建新列数据
怎么从已有数据,创建新列数据

Ques: 我想把 NO2 的数据,新加一列 mg/m3 的单位
把二氧化氮的数据,得出每立方米多少毫克(转换参数是 1.882)
air_quality["london_mg_per_cubic"] = air_quality["station_london"] * 1.882
air_quality.head()
Out[5]:
station_antwerp station_paris station_london london_mg_per_cubic
datetime
2019-05-07 02:00:00 NaN NaN 23.0 43.286
2019-05-07 03:00:00 50.5 25.0 19.0 35.758
2019-05-07 04:00:00 45.0 27.7 19.0 35.758
2019-05-07 05:00:00 NaN 50.4 16.0 30.112
2019-05-07 06:00:00 NaN 61.9 NaN NaN
想创建新列,把要创建的列名放到【】中。
我们上面用的是一列数据 * 1.882,它会自动把此列中的每一个元素都 * 1.882。 不用手动遍历此列的数据,然后相乘。
Question:两个城市的比值
air_quality["ratio_paris_antwerp"] = (
air_quality["station_paris"] / air_quality["station_antwerp"]
)
air_quality.head()
Out[7]:
station_antwerp station_paris station_london london_mg_per_cubic ratio_paris_antwerp
datetime
2019-05-07 02:00:00 NaN NaN 23.0 43.286 NaN
2019-05-07 03:00:00 50.5 25.0 19.0 35.758 0.495050
2019-05-07 04:00:00 45.0 27.7 19.0 35.758 0.615556
2019-05-07 05:00:00 NaN 50.4 16.0 30.112 NaN
2019-05-07 06:00:00 NaN 61.9 NaN NaN NaN
同样的,两列相除,会自动把每行的两个数据相除,不用手动遍历相除。
同样的,其他算术符号(+,-,*,/) 或 逻辑运算符:(<, >, =, ...) 都可以进行元素级别的比较计算。譬如我们之前过滤数据时,也是这样。
Ques:我想重命名列名
air_quality_renamed = air_quality.rename(
columns={
"station_antwerp": "BETR801",
"station_paris": "FR04014",
"station_london": "London Westminster",
}
)
air_quality_renamed.head()
Out[9]:
BETR801 FR04014 London Westminster london_mg_per_cubic ratio_paris_antwerp
datetime
2019-05-07 02:00:00 NaN NaN 23.0 43.286 NaN
2019-05-07 03:00:00 50.5 25.0 19.0 35.758 0.495050
2019-05-07 04:00:00 45.0 27.7 19.0 35.758 0.615556
2019-05-07 05:00:00 NaN 50.4 16.0 30.112 NaN
2019-05-07 06:00:00 NaN 61.9 NaN NaN NaN
rename() 可以用在列名和行标签上。只要提供一个字典,它的键是原来的名字,值是新名字,就可以了。
df.rename(columns={...}, index={...},)
rename() 不仅可以作用于重命名,还可以接收一个函数作为参数,例如将所有列名变成小写字母:
air_quality_renamed = air_quality_renamed.rename(columns=str.lower)
air_quality_renamed.head()
Out[11]:
betr801 fr04014 london westminster london_mg_per_cubic ratio_paris_antwerp
datetime
2019-05-07 02:00:00 NaN NaN 23.0 43.286 NaN
2019-05-07 03:00:00 50.5 25.0 19.0 35.758 0.495050
2019-05-07 04:00:00 45.0 27.7 19.0 35.758 0.615556
2019-05-07 05:00:00 NaN 50.4 16.0 30.112 NaN
2019-05-07 06:00:00 NaN 61.9 NaN NaN NaN
REMEMBER
- 创建新列,用: [列名]
- 操作都是基于单个元素的,不需要循环
- 给 rename() 一个字典或函数来重命名列名和行标签。
6. 计算统计信息
Ques: 年龄平均值
titanic["Age"].mean()
Out[4]: 29.69911764705882
Ques: 中位数
同时计算年龄和票价的中位数
titanic[["Age", "Fare"]].median()
Out[5]:
Age 28.0000
Fare 14.4542
dtype: float64
一些基础数据可以为多列数据同时计算出来,还记得之前用的 describe() 吗?
titanic[["Age", "Fare"]].describe()
Out[6]:
Age Fare
count 714.000000 891.000000
mean 29.699118 32.204208
std 14.526497 49.693429
min 0.420000 0.000000
25% 20.125000 7.910400
50% 28.000000 14.454200
75% 38.000000 31.000000
max 80.000000 512.329200
不用预先定义的统计数据,我们可以自定义一些合计数据的组合,得出数据:
titanic.agg(
{
"Age": ["min", "max", "median", "skew"],
"Fare": ["min", "max", "median", "mean"],
}
)
Out[7]:
Age Fare
min 0.420000 0.000000
max 80.000000 512.329200
median 28.000000 14.454200
skew 0.389108 NaN
mean NaN 32.204208
数据分组统计
Question:男女乘客分别平均年龄
titanic[["Sex", "Age"]].groupby("Sex").mean()
Out[8]:
Age
Sex
female 27.915709
male 30.726645
我们先获取 Sex,Age两列数据,然后按照 Sex 分组,最后求平均值。
上面的过程,可以作为一个通用模式:split-apply-combine pattern
分割-应用-组合 模式:
- 分割 数据成为不同的分组
- 对每个组,都应用一个方法
- 组合所有的结果
在pandas中,应用-组合 这两个步骤,通常一起做了。
上面的例子,我们明确的选中了 Sex, Age两列,如果不选中这两列。mean() 会对所有数字类型的列进行求平均值:
titanic.groupby("Sex").mean()
Out[9]:
PassengerId Survived Pclass Age SibSp Parch Fare
Sex
female 431.028662 0.742038 2.159236 27.915709 0.694268 0.649682 44.479818
male 454.147314 0.188908 2.389948 30.726645 0.429809 0.235702 25.523893
针对已经分组后的数据,也可以使用 [] 来获取某列数据,然后求平均值:
titanic.groupby("Sex")["Age"].mean()
Out[10]:
Sex
female 27.915709
male 30.726645
Name: Age, dtype: float64

Pclass这列数据,代表的是座舱的等级,譬如1,2,3三个等级。对它求平均值没有什么意义,所以 pandas 有个数据类型:Categorical,代表一个类别。
Question: 联合分组。怎么针对 Sex,Pclass进行分组,查看每组的票价平均值?
at is the mean ticket fare price for each of the sex and cabin class combinations?
titanic.groupby(["Sex", "Pclass"])["Fare"].mean()
Out[11]:
Sex Pclass
female 1 106.125798
2 21.970121
3 16.118810
male 1 67.226127
2 19.741782
3 12.661633
Name: Fare, dtype: float64
分组可以接收多个参数,只要放进列表里面就行了。
按类别统计次数
Question:每一个座舱类型,有多少个乘客?
titanic["Pclass"].value_counts()
Out[12]:
3 491
1 216
2 184
Name: Pclass, dtype: int64
value_counts() 可以统计每个类别有多少记录
上面的例子,其实是分组操作的一个快捷方式,完整的方式如下:
titanic.groupby("Pclass")["Pclass"].count()
Out[13]:
Pclass
1 216
2 184
3 491
Name: Pclass, dtype: int64
size 和 count 两个方法,都可以在分组中使用,但是 size 包含空值记录(表格的大小),count 方法不包含空值。
REMEMBER
统计数据可以作用于所有行和列
分组功能提供了 split-apply-combine pattern
value_counts 是一个快捷方式来计算一个类别下不同值的个数。
7. 改变表格布局
对行排序
Ques:我想对年龄进行排序
titanic.sort_values(by="Age").head()
Out[6]:
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
803 804 1 3 Thomas, Master. Assad Alexander male 0.42 0 1 2625 8.5167 NaN C
755 756 1 2 Hamalainen, Master. Viljo male 0.67 1 1 250649 14.5000 NaN S
644 645 1 3 Baclini, Miss. Eugenie female 0.75 2 1 2666 19.2583 NaN C
469 470 1 3 Baclini, Miss. Helene Barbara female 0.75 2 1 2666 19.2583 NaN C
78 79 1 2 Caldwell, Master. Alden Gates male 0.83 0 2 248738 29.0000 NaN S
Ques: 我想对座舱等级,年龄进行降序排序(先对座舱等级排序,然后对年龄排序)
titanic.sort_values(by=['Pclass', 'Age'], ascending=False).head()
Out[7]:
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
851 852 0 3 Svensson, Mr. Johan male 74.0 0 0 347060 7.7750 NaN S
116 117 0 3 Connors, Mr. Patrick male 70.5 0 0 370369 7.7500 NaN Q
280 281 0 3 Duane, Mr. Frank male 65.0 0 0 336439 7.7500 NaN Q
483 484 1 3 Turkula, Mrs. (Hedwig) female 63.0 0 0 4134 9.5875 NaN S
326 327 0 3 Nysveen, Mr. Johan Hansen male 61.0 0 0 345364 6.2375 NaN S
注意:排序完成后,行标签(索引)也会跟着被打乱(排序了嘛),如果想要恢复原来的顺序,可以通过标签重新排序。sorting data
pivot
8. 多表联合数据
air_quality_no2 = pd.read_csv("data/air_quality_no2_long.csv",
parse_dates=True)
air_quality_no2 = air_quality_no2[["date.utc", "location",
"parameter", "value"]]
air_quality_no2.head()
Out[4]:
date.utc location parameter value
0 2019-06-21 00:00:00+00:00 FR04014 no2 20.0
1 2019-06-20 23:00:00+00:00 FR04014 no2 21.8
2 2019-06-20 22:00:00+00:00 FR04014 no2 26.5
3 2019-06-20 21:00:00+00:00 FR04014 no2 24.9
4 2019-06-20 20:00:00+00:00 FR04014 no2 21.4
air_quality_pm25 = pd.read_csv("data/air_quality_pm25_long.csv",
parse_dates=True)
air_quality_pm25 = air_quality_pm25[["date.utc", "location",
"parameter", "value"]]
air_quality_pm25.head()
Out[7]:
date.utc location parameter value
0 2019-06-18 06:00:00+00:00 BETR801 pm25 18.0
1 2019-06-17 08:00:00+00:00 BETR801 pm25 6.5
2 2019-06-17 07:00:00+00:00 BETR801 pm25 18.5
3 2019-06-17 06:00:00+00:00 BETR801 pm25 16.0
4 2019-06-17 05:00:00+00:00 BETR801 pm25 7.5
合并两个表

Ques: 想要将两个表,合并到一张表(把一张表,追加到另一张表底下)
air_quality = pd.concat([air_quality_pm25, air_quality_no2], axis=0)
air_quality.head()
Out[9]:
date.utc location parameter value
0 2019-06-18 06:00:00+00:00 BETR801 pm25 18.0
1 2019-06-17 08:00:00+00:00 BETR801 pm25 6.5
2 2019-06-17 07:00:00+00:00 BETR801 pm25 18.5
3 2019-06-17 06:00:00+00:00 BETR801 pm25 16.0
4 2019-06-17 05:00:00+00:00 BETR801 pm25 7.5
concat() 可以将两张表合并到一张表。axis 可以设置方向(行方向或列方向),0 代表追加到下方(竖直方向)。1代表追加到右边(水平方向),默认 axis 是0
我们对此表排序一下,可以看出 parameter 列中有 no2 和 pm25 两种类型的值,说明确实合并了:
air_quality = air_quality.sort_values("date.utc")
air_quality.head()
Out[14]:
date.utc location parameter value
2067 2019-05-07 01:00:00+00:00 London Westminster no2 23.0
1003 2019-05-07 01:00:00+00:00 FR04014 no2 25.0
100 2019-05-07 01:00:00+00:00 BETR801 pm25 12.5
1098 2019-05-07 01:00:00+00:00 BETR801 no2 50.5
1109 2019-05-07 01:00:00+00:00 London Westminster pm25 8.0
以下内容是译者自己补充的例子,非翻译的文档内容。
Ques: 通过某列合并(有点像 vlookup,或者 SQL 的多表联合查询)
现有三张表:
>>> d1
name age
0 wang 23
1 zhang 35
2 li 23
>>> d2
name age addr
0 wang 100 ssssss
1 zhang 100 kkkkk
2 li 100 llllll
3 any 100 100
>>> d3
names age
0 wang 22
1 huang 23
我们选择 d1, d2 两表 name 列的交集数据:
>>> pd.merge(d1,d2,on='name')
name age_x age_y addr
0 wang 23 100 ssssss
1 zhang 35 100 kkkkk
2 li 23 100 llllll
on="name" 意思是以两张表共有的 name 列为主键,进行两张表的关联, age_x, age_y 代表两张表的 age,因为两张表都有age列,所以合并后都带了一个后缀。默认on=None,则会以两张表共有的所有列为联合键,进行关联,此例子中相当于:on=['name','age']
如果列名不一致:d3 的名字列叫'names', d2 的叫'name',两者不一样,也能合并:
>>> pd.merge(d1,d3,left_on='name',right_on='names')
name age_x names age_y
0 wang 23 wang 22
left_on, right_on,分别指定两个表的联合键,然后合并两张表主键的交集部分。
上面说的都是求两个表的交集部分,如果我们想要两个表的联合部分(并集),或者只想要左侧表的全部,怎么办?
how 参数,可以指定怎么选取两张表的数据,可选值有:'left', 'right', 'outer', 'inner',默认'inner'
取 d1, d2 两张表的姓名列的并集:
>>> pd.merge(d1,d2,how='outer',on='name')
name age_x age_y addr
0 wang 23.0 100 ssssss
1 zhang 35.0 100 kkkkk
2 li 23.0 100 llllll
3 any NaN 100 100
姓名列的并集选出来了,没有的数据,会以 NaN 填充。譬如来自 d3 表的 any,它没有 age_x(来自d2的age),age_x 会是 NaN
同样,只想要左侧 d1 表的所有人名,不要 d2 的人名:
>>> pd.merge(d1,d2,how='left',on='name')
name age_x age_y addr
0 wang 23 100 ssssss
1 zhang 35 100 kkkkk
2 li 23 100 llllll
Ques: 想要按照行索引来关联数据,怎么办
>>> pd.merge(d2,d3,left_index=True,right_index=True)
name age_x addr names age_y
0 wang 100 ssssss wang 22
1 zhang 100 kkkkk huang 23
left_index,right_index。以两张表的行标签为联合键,对齐两张表,参数默认值是 False。此例子中,行标签就是索引 0,1,2,...
Question:我想知道哪些数据是左表独有的,哪些数据是右表独有的,哪些数据是共有的?
>>> pd.merge(d1,d2,indicator=True,how='outer',on='name')
name age_x age_y addr _merge
0 wang 23.0 100 ssssss both
1 zhang 35.0 100 kkkkk both
2 li 23.0 100 llllll both
3 any NaN 100 100 right_only
indicator 参数,默认是 False。它会新增一列 _merge 数据,显示的值有三种:both,left_only, right_only,代表:共有,只在左表,只在右表
怎么检查两个表的数据,是否一一对应?(譬如一个名字对一个名字)
我们对 d1 表,新增一个重复的人名:wang
>>> d1
name age
0 wang 23
1 zhang 35
2 li 23
3 wang 25
>>> pd.merge(d1,d2,on='name',validate='one_to_one')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:py3.9libsite-packagespandascore
eshapemerge.py", line 74, in merge
op = _MergeOperation(
File "C:py3.9libsite-packagespandascore
eshapemerge.py", line 678, in __init__
self._validate(validate)
File "C:py3.9libsite-packagespandascore
eshapemerge.py", line 1362, in _validate
raise MergeError(
pandas.errors.MergeError: Merge keys are not unique in left dataset; not a one-to-one merge
validate 参数,我们指定了数据要 一对一;即左边一个人名,对应右表一个人名。因为我们左表有两个重复的人名,所以报错了。
好了,基本上所有的参数都讲完了。
pd.merge(
left, # 左表,DataFrame 或 Series
right, # 右表,DataFrame 或 Series
how="inner", # 连接方式:inner,outer,left,right
on=None, # 连接用到的联合键;可以是列名或索引名,但是必须要同时在两个表都存在,默认None时,会用两张表所有共有的列作为联合主键。
left_on=None, # 单独指定左表用到的键
right_on=None, # 右表用到的键
left_index=False, # True 时,以行索引来关联(一行对一行)
right_index=False, # 同上
sort=True, # 根据联合键来对结果排序。默认 True
suffixes=("_x", "_y"), # 两个表存在同名列时,结果中会加个后缀区分哪个来自哪列。
copy=True, # 不清楚。
indicator=False, # 指示器,显示哪些数据是独有的,或是共有的。
validate=None, # 四个参数:'one_to_one', 'one_to_many','many_to_one','many_to_many'. 分别代表:检查两个都没有重复值。检查左表没有重复值。检查右表没有重复值。允许有重复值。
)
9. 处理时间
air_quality = pd.read_csv("data/air_quality_no2_long.csv")
air_quality = air_quality.rename(columns={"date.utc": "datetime"})
air_quality.head()
Out[5]:
city country datetime location parameter value unit
0 Paris FR 2019-06-21 00:00:00+00:00 FR04014 no2 20.0 µg/m³
1 Paris FR 2019-06-20 23:00:00+00:00 FR04014 no2 21.8 µg/m³
2 Paris FR 2019-06-20 22:00:00+00:00 FR04014 no2 26.5 µg/m³
3 Paris FR 2019-06-20 21:00:00+00:00 FR04014 no2 24.9 µg/m³
4 Paris FR 2019-06-20 20:00:00+00:00 FR04014 no2 21.4 µg/m³
pandas datatime 属性
air_quality["datetime"] = pd.to_datetime(air_quality["datetime"])
air_quality["datetime"]
Out[8]:
0 2019-06-21 00:00:00+00:00
1 2019-06-20 23:00:00+00:00
2 2019-06-20 22:00:00+00:00
3 2019-06-20 21:00:00+00:00
4 2019-06-20 20:00:00+00:00
...
2063 2019-05-07 06:00:00+00:00
2064 2019-05-07 04:00:00+00:00
2065 2019-05-07 03:00:00+00:00
2066 2019-05-07 02:00:00+00:00
2067 2019-05-07 01:00:00+00:00
Name: datetime, Length: 2068, dtype: datetime64[ns, UTC]
to_datetime() 可以很轻松的将字符串类型的时间列,转换成时间格式,类似于 datetime.datetime
在读取文件如:read_csv(),read_json()时,可以将 列名 传递给参数 parse_dates,在读取时,就会将此列转换成时间:
pd.read_csv("../data/air_quality_no2_long.csv", parse_dates=["datetime"])
pandas.Timestamp 还可以进行日期计算:
air_quality["datetime"].min(), air_quality["datetime"].max()
Out[9]:
(Timestamp('2019-05-07 01:00:00+0000', tz='UTC'),
Timestamp('2019-06-21 00:00:00+0000', tz='UTC'))
air_quality["datetime"].max() - air_quality["datetime"].min()
Out[10]: Timedelta('44 days 23:00:00')
Ques: 新增一列只包含月份
air_quality["month"] = air_quality["datetime"].dt.month
air_quality.head()
Out[12]:
city country datetime location parameter value unit month
0 Paris FR 2019-06-21 00:00:00+00:00 FR04014 no2 20.0 µg/m³ 6
1 Paris FR 2019-06-20 23:00:00+00:00 FR04014 no2 21.8 µg/m³ 6
2 Paris FR 2019-06-20 22:00:00+00:00 FR04014 no2 26.5 µg/m³ 6
3 Paris FR 2019-06-20 21:00:00+00:00 FR04014 no2 24.9 µg/m³ 6
4 Paris FR 2019-06-20 20:00:00+00:00 FR04014 no2 21.4 µg/m³ 6
除了 month, 还有 year, weekofyear, quarter,weekday,hour 可以使用,只需要通过 dt 来访问。
Ques: 按照每天和地点分组,求每个组的平均值
air_quality.groupby(
[air_quality["datetime"].dt.weekday, "location"])["value"].mean()
Out[13]:
datetime location
0 BETR801 27.875000
FR04014 24.856250
London Westminster 23.969697
1 BETR801 22.214286
FR04014 30.999359
...
5 FR04014 25.266154
London Westminster 24.977612
6 BETR801 21.896552
FR04014 23.274306
London Westminster 24.859155
Name: value, Length: 21, dtype: float64
weekday 可以获取日期是周几。0代表周一,6代表周日。
datetime 作为 索引
no_2 = air_quality.pivot(index="datetime", columns="location", values="value")
no_2.head()
Out[19]:
location BETR801 FR04014 London Westminster
datetime
2019-05-07 01:00:00+00:00 50.5 25.0 23.0
2019-05-07 02:00:00+00:00 45.0 27.7 19.0
2019-05-07 03:00:00+00:00 NaN 50.4 19.0
2019-05-07 04:00:00+00:00 NaN 61.9 16.0
2019-05-07 05:00:00+00:00 NaN 72.4 NaN
pivot 可以重塑表格的形状(行转换成列,列转换成行等),此处把 datetime 列转换成了索引。通常来说,可以使用 set_index 方法来将列转换成索引。
时间索引,可以不再通过 dt 来访问一些属性,而是通过 index 直接访问:
no_2.index.year, no_2.index.weekday
Out[20]:
(Int64Index([2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019,
...
2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019],
dtype='int64', name='datetime', length=1033),
Int64Index([1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
...
3, 3, 3, 3, 3, 3, 3, 3, 3, 4],
dtype='int64', name='datetime', length=1033))
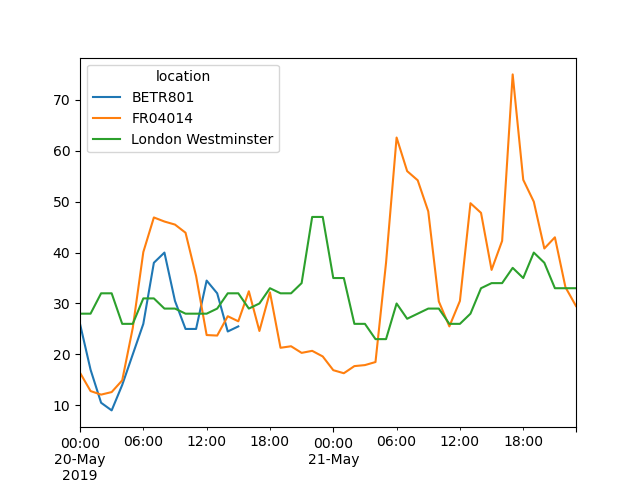
Ques:选取特定时间段的数据:
no_2["2019-05-20":"2019-05-21"].plot();
时间频率转换采样
将时间转换成其他频率:如小时转换成天。下面的例子将时间按照月重新采样,然后求最大值
monthly_max = no_2.resample("M").max()
monthly_max
Out[23]:
location BETR801 FR04014 London Westminster
datetime
2019-05-31 00:00:00+00:00 74.5 97.0 97.0
2019-06-30 00:00:00+00:00 52.5 84.7 52.0
resample() 有点像分组操作:
- 它提供了一个时间分组,用字符串('M','5H','D', ...) 来定义目标频率
- 需要一个聚合函数:max, mean, ...
我们可以使用 freq 属性来查询它的频率
monthly_max.index.freq
Out[24]: <MonthEnd>
REMEMBER
- 有效的时间字符串可以用:to_datetime 方法来转换成时间格式。也可以在读取文件时转换成。
- Datetime 对象支持计算,逻辑操作,使用 dt 访问器还有一些其他方便的时间相关的属性
- 一个时间索引(DatetimeIndex) 包含了时间相关的属性,并支持方便的切片
- 对时间重新采样可以方便的转换时间频率
10. 操作文本数据
Question:将人名转换成小写字符
titanic["Name"].str.lower()
Out[4]:
0 braund, mr. owen harris
1 cumings, mrs. john bradley (florence briggs th...
2 heikkinen, miss. laina
3 futrelle, mrs. jacques heath (lily may peel)
4 allen, mr. william henry
...
886 montvila, rev. juozas
887 graham, miss. margaret edith
888 johnston, miss. catherine helen "carrie"
889 behr, mr. karl howell
890 dooley, mr. patrick
Name: Name, Length: 891, dtype: object
获取 Name 列的切片,然后通过 str 访问并应用 lower() 方法,将此列转换成小写。
Ques: 字符串分割后,放到新列?
titanic["Name"].str.split(",")
Out[5]:
0 [Braund, Mr. Owen Harris]
1 [Cumings, Mrs. John Bradley (Florence Briggs ...
2 [Heikkinen, Miss. Laina]
3 [Futrelle, Mrs. Jacques Heath (Lily May Peel)]
4 [Allen, Mr. William Henry]
...
886 [Montvila, Rev. Juozas]
887 [Graham, Miss. Margaret Edith]
888 [Johnston, Miss. Catherine Helen "Carrie"]
889 [Behr, Mr. Karl Howell]
890 [Dooley, Mr. Patrick]
Name: Name, Length: 891, dtype: object
Series.str.split() 可以将每个值都按照分隔符号进行分割,返回列表。
titanic["Surname"] = titanic["Name"].str.split(",").str.get(0)
titanic["Surname"]
Out[7]:
0 Braund
1 Cumings
2 Heikkinen
3 Futrelle
4 Allen
...
886 Montvila
887 Graham
888 Johnston
889 Behr
890 Dooley
Name: Surname, Length: 891, dtype: object
Series.str.get() 可以提取分割后列表中的某个值。没错,str.split() 可以和 str.get() 连接在一起使用。
字符串分割替换
Ques: 是否包含某个字符?
titanic["Name"].str.contains("Countess")
Out[8]:
0 False
1 False
2 False
3 False
4 False
...
886 False
887 False
888 False
889 False
890 False
Name: Name, Length: 891, dtype: bool
contains() 可以对每个元素判断是否存在某个字符。返回的值是 True 或 False,我们可以把它放到 [] 中进行筛选,获取子集。(此函数可以使用正则表达式)
titanic[titanic["Name"].str.contains("Countess")]
Out[9]:
PassengerId Survived Pclass Name Sex Age ... Parch Ticket Fare Cabin Embarked Surname
759 760 1 1 Rothes, the Countess. of (Lucy Noel Martha Dye... female 33.0 ... 0 110152 86.5 B77 S Rothes
[1 rows x 13 columns]
还有一个方法 extract(), 可以直接提取满足条件的内容。
Question:字符串长度
titanic["Name"].str.len()
Out[10]:
0 23
1 51
2 22
3 44
4 24
..
886 21
887 28
888 40
889 21
890 19
Name: Name, Length: 891, dtype: int64
和 python 的方法类似。len() 可以获取数据集内每个字符串的长度。
titanic["Name"].str.len().idxmax()
Out[11]: 307
idxmax() 方法,获取最大值所在的行标签。它不是一个字符串方法。
titanic.loc[titanic["Name"].str.len().idxmax(), "Name"]
Out[12]: 'Penasco y Castellana, Mrs. Victor de Satode (Maria Josefa Perez de Soto y Vallejo)'
根据row(307), column(Name), 使用 loc 操作符,定位到某个值。
Question:字符串替换
titanic["Sex_short"] = titanic["Sex"].replace({"male": "M", "female": "F"})
titanic["Sex_short"]
Out[14]:
0 M
1 F
2 F
3 F
4 M
..
886 M
887 F
888 F
889 M
890 M
Name: Sex_short, Length: 891, dtype: object
使用 replace() 方法,将某个字符串,替换成另一个字符串。将原值作为键,新值作为值,放到字典中,传递给 replace({from : to})
REMEMBER
- 字符串方法,可以使用 str 访问器
- 字符串方法都是元素级别的,可以作为条件判断索引进行筛选子集
- replace 方法可以接收字典来方便的替换值。
compare to Excel
url = (
"https://raw.github.com/pandas-dev"
"/pandas/master/pandas/tests/io/data/csv/tips.csv"
)
tips = pd.read_csv(url)
tips
Out[7]:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
.. ... ... ... ... ... ... ...
239 29.03 5.92 Male No Sat Dinner 3
240 27.18 2.00 Female Yes Sat Dinner 2
241 22.67 2.00 Male Yes Sat Dinner 2
242 17.82 1.75 Male No Sat Dinner 2
243 18.78 3.00 Female No Thur Dinner 2
[244 rows x 7 columns]
筛选:略。上文有
只选择某几列:
tips[["sex", "total_bill", "tip"]]
if语句
=IF(A1<60,"不及格","及格")
tips["bucket"] = np.where(tips["total_bill"] < 10, "low", "high")
tips
Out[19]:
total_bill tip sex smoker day time size bucket
0 14.99 1.01 Female No Sun Dinner 2 high
1 8.34 1.66 Male No Sun Dinner 3 low
2 19.01 3.50 Male No Sun Dinner 3 high
3 21.68 3.31 Male No Sun Dinner 2 high
4 22.59 3.61 Female No Sun Dinner 4 high
.. ... ... ... ... ... ... ... ...
239 27.03 5.92 Male No Sat Dinner 3 high
240 25.18 2.00 Female Yes Sat Dinner 2 high
241 20.67 2.00 Male Yes Sat Dinner 2 high
242 15.82 1.75 Male No Sat Dinner 2 high
243 16.78 3.00 Female No Thur Dinner 2 high
[244 rows x 8 columns]
where(condition, 'true_msg', 'false_msg') 可以做到类似 IF 语句。
日期操作:
tips["date1"] = pd.Timestamp("2013-01-15") # 日期格式时间
tips["date2"] = pd.Timestamp("2015-02-15")
tips["date1_year"] = tips["date1"].dt.year # 获取日期的年份
tips["date2_month"] = tips["date2"].dt.month # 获取日期的月份
tips["date1_next"] = tips["date1"] + pd.offsets.MonthBegin() # 获取下个月这天的日期
tips["months_between"] = tips["date2"].dt.to_period("M") - tips["date1"].dt.to_period("M") # 两个月份之间的时间差; dt.to_period("M") 会返回到月份 2013-01
tips[
["date1", "date2", "date1_year", "date2_month", "date1_next", "months_between"]
]
Out[26]:
date1 date2 date1_year date2_month date1_next months_between
0 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
1 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
2 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
3 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
4 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
.. ... ... ... ... ... ...
239 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
240 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
241 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
242 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
243 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds>
[244 rows x 6 columns]
删除一列:
tips.drop("sex", axis=1)
Out[28]:
total_bill tip smoker day time size
0 14.99 1.01 No Sun Dinner 2
1 8.34 1.66 No Sun Dinner 3
2 19.01 3.50 No Sun Dinner 3
3 21.68 3.31 No Sun Dinner 2
4 22.59 3.61 No Sun Dinner 4
.. ... ... ... ... ... ...
239 27.03 5.92 No Sat Dinner 3
240 25.18 2.00 Yes Sat Dinner 2
241 20.67 2.00 Yes Sat Dinner 2
242 15.82 1.75 No Sat Dinner 2
243 16.78 3.00 No Thur Dinner 2
[244 rows x 6 columns]
drop(列名,axis=1); axis=1 代表列,水平方向
删除一行:
tips.drop(0, axis=0)
drop(行索引, axis=0); axis=0 代表行
新增一行:
df
Out[67]:
class student_count all_pass
0 A 42 Yes
1 A 35 Yes
2 A 42 Yes
3 B 50 No
4 C 47 No
5 D 45 Yes
new_row = {"class": "E", "student_count": 51, "all_pass": True}
df.append(new_row, ignore_index=True)
Out[69]:
class student_count all_pass
0 A 42 Yes
1 A 35 Yes
2 A 42 Yes
3 B 50 No
4 C 47 No
5 D 45 Yes
6 E 51 True
支持 DataFrame/Series/字典,或者这三种数据类型的列表
重命名列名:
tips.rename(columns={"total_bill": "total_bill_2"})
Out[29]:
total_bill_2 tip sex smoker day time size
0 14.99 1.01 Female No Sun Dinner 2
1 8.34 1.66 Male No Sun Dinner 3
2 19.01 3.50 Male No Sun Dinner 3
3 21.68 3.31 Male No Sun Dinner 2
4 22.59 3.61 Female No Sun Dinner 4
.. ... ... ... ... ... ... ...
239 27.03 5.92 Male No Sat Dinner 3
240 25.18 2.00 Female Yes Sat Dinner 2
241 20.67 2.00 Male Yes Sat Dinner 2
242 15.82 1.75 Male No Sat Dinner 2
243 16.78 3.00 Female No Thur Dinner 2
[244 rows x 7 columns]
rename(columns={'old name': 'new name', ...})
排序
tips = tips.sort_values(["sex", "total_bill"])
tips
Out[31]:
total_bill tip sex smoker day time size
67 1.07 1.00 Female Yes Sat Dinner 1
92 3.75 1.00 Female Yes Fri Dinner 2
111 5.25 1.00 Female No Sat Dinner 1
145 6.35 1.50 Female No Thur Lunch 2
135 6.51 1.25 Female No Thur Lunch 2
.. ... ... ... ... ... ... ...
182 43.35 3.50 Male Yes Sun Dinner 3
156 46.17 5.00 Male No Sun Dinner 6
59 46.27 6.73 Male No Sat Dinner 4
212 46.33 9.00 Male No Sat Dinner 4
170 48.81 10.00 Male Yes Sat Dinner 3
[244 rows x 7 columns]
sort_values 可以对单个或一组标签或列名排序. ascending 参数可以控制升序或降序(默认 True 升序), inplace 参数可以控制是否直接在原数据上更改(默认 False)
去除文本右边空格
tips["time"].str.rstrip()
查找关键字位置:
tips["sex"].str.find("ale")
Out[34]:
67 3
92 3
111 3
145 3
135 3
..
182 1
156 1
59 1
212 1
170 1
Name: sex, Length: 244, dtype: int64
找不到关键字,返回 -1
截取字符串
tips["sex"].str[0:1]
Out[35]:
67 F
92 F
111 F
145 F
135 F
..
182 M
156 M
59 M
212 M
170 M
Name: sex, Length: 244, dtype: object
分割字符串
>>> s = pd.DataFrame({"name":["wang tao", "zhang fei"]})
>>> s
name
0 wang tao
1 zhang fei
>>> s['name'].str.split(' ')
0 [wang, tao]
1 [zhang, fei]
Name: name, dtype: object
>>> s['name'].str.split(' ',expand=True)
0 1
0 wang tao
1 zhang fei
split() 函数可以分割每个元素成一个列表。expand=True 可以让分割后的数据变成 DataFrame 对象。
字符串分割成列:
firstlast = pd.DataFrame({"String": ["John Smith", "Jane Cook"]})
firstlast["First_Name"] = firstlast["String"].str.split(" ", expand=True)[0]
firstlast["Last_Name"] = firstlast["String"].str.rsplit(" ", expand=True)[0]
firstlast
Out[39]:
String First_Name Last_Name
0 John Smith John John
1 Jane Cook Jane Jane
DateFrame[column_index] 可以选取通过列索引选取某列数据
大小写转换:
firstlast = pd.DataFrame({"string": ["John Smith", "Jane Cook"]})
firstlast["upper"] = firstlast["string"].str.upper()
firstlast["lower"] = firstlast["string"].str.lower()
firstlast["title"] = firstlast["string"].str.title()
firstlast
Out[44]:
string upper lower title
0 John Smith JOHN SMITH john smith John Smith
1 Jane Cook JANE COOK jane cook Jane Cook
vlookup 类似合并,见上文:多表联合。
数据填充:
df = pd.DataFrame({"AAA": [1] * 8, "BBB": list(range(0, 8))})
df
Out[58]:
AAA BBB
0 1 0
1 1 1
2 1 2
3 1 3
4 1 4
5 1 5
6 1 6
7 1 7
series = list(range(1, 5))
series
Out[60]: [1, 2, 3, 4]
df.loc[2:5, "AAA"] = series
df
Out[62]:
AAA BBB
0 1 0
1 1 1
2 1 2
3 2 3
4 3 4
5 4 5
6 1 6
7 1 7
数据去重:
df = pd.DataFrame(
{
"class": ["A", "A", "A", "B", "C", "D"],
"student_count": [42, 35, 42, 50, 47, 45],
"all_pass": ["Yes", "Yes", "Yes", "No", "No", "Yes"],
}
)
df.drop_duplicates()
Out[64]:
class student_count all_pass
0 A 42 Yes
1 A 35 Yes
3 B 50 No
4 C 47 No
5 D 45 Yes
df.drop_duplicates(["class", "student_count"])
Out[65]:
class student_count all_pass
0 A 42 Yes
1 A 35 Yes
3 B 50 No
4 C 47 No
5 D 45 Yes
数据透视表:
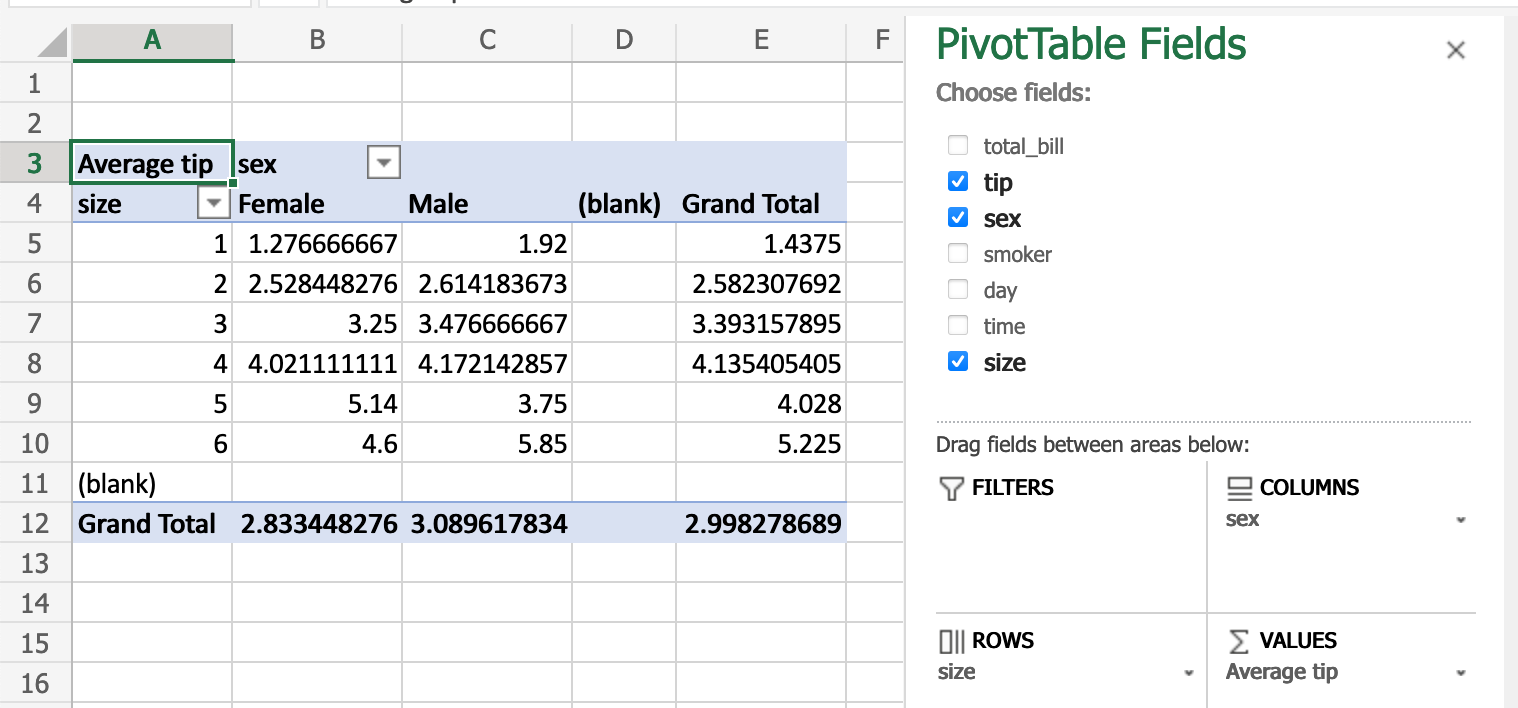
类似操作:
pd.pivot_table(
tips, values="tip", index=["size"], columns=["sex"], aggfunc=np.average
)
Out[66]:
sex Female Male
size
1 1.276667 1.920000
2 2.528448 2.614184
3 3.250000 3.476667
4 4.021111 4.172143
5 5.140000 3.750000
6 4.600000 5.850000
看完觉得还不够?官网用户指导