一文看懂Fluentd语法
Fluentd简介
fluentd是一个针对日志的收集、处理、转发系统。通过丰富的插件系统,可以收集来自于各种系统或应用的日志,转化为用户指定的格式后,转发到用户所指定的日志存储系统之中。
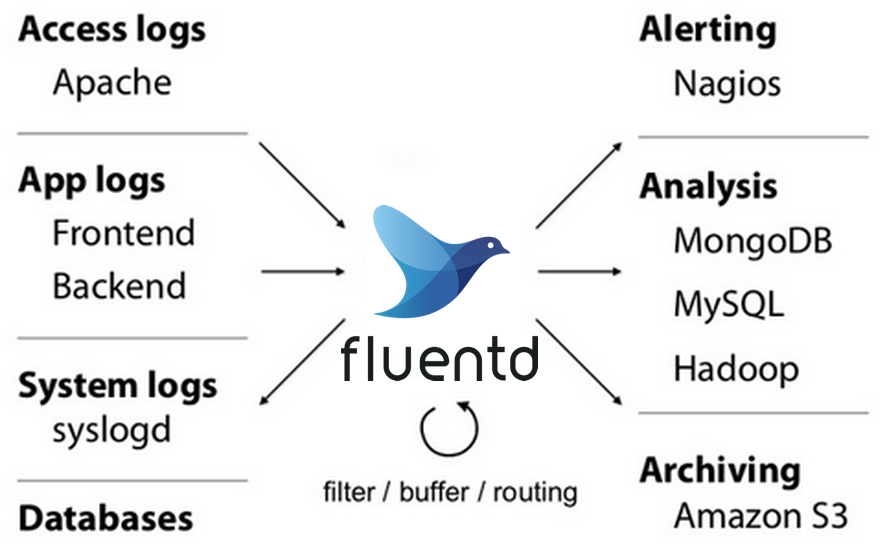
通过 fluentd,你可以非常轻易的实现像追踪日志文件并将其过滤后转存到 MongoDB 这样的操作。fluentd 可以彻底的将你从繁琐的日志处理中解放出来。
与logstash的对比
你也许会觉得和 ELK 中的 Logstash 高度相似。事实上也确实如此,你完全可以用 fluentd 来替换掉 ELK 中的 Logstash。
有两篇文章对这两个工具做了很好的对比:
- Fluentd vs. Logstash: A Comparison of Log Collectors
- Log Aggregation with Fluentd, Elasticsearch and Kibana
概括一下的话,有以下区别:
- fluentd 比 logstash 更省资源;
- 更轻量级的 fluent-bid 对应 filebeat,作为部署在结点上的日志收集器;
- fluentd 有更多强大、开放的插件数量和社区。
配置文件语法
官网文档: 点击直达
Fluentd事件的生命周期
- 每个输入的事件会带有一个tag
- Fluentd通过tag匹配output
- Fluentd发送事件到匹配的output
- Fluentd支持多个数据源和数据输出
- 通过过滤器,事件可以被重新触发
“source”: 定义数据源
数据源可以在source指令中定义,比如我们可以定义http和forward的数据源。http数据源可以通过http协议来接收数据,forward可以通过tcp协议来接收数据。
# Receive events from 24224/tcp
# This is used by log forwarding and the fluent-cat command
<source>
@type forward
port 24224
</source>
# http://this.host:9880/myapp.access?json={"event":"data"}
<source>
@type http
port 9880
</source>
所有source指令中必须包含@type参数,该参数用来指定使用哪个输入插件,比如我们还可以用tail插件来读取文件的内容。
路由
source指令把事件提交到Fluentd的路由引擎。一个事件由三个实体组成:tag、time和record。tag是由’.’分割的字符串组成,被内部路由引擎使用。time由input插件指定,必须是Unix时间戳格式。record是一个Json对象。
强烈推荐使用小写字母、数字和下划线来命名tag,虽然其他的字符也是合法的。
“match”: 定义数据的输出目标
match指令通过匹配tag字段来将事件输出到其他的系统。同样match指令也必须指定@type参数,该参数用来指定使用哪个输出插件。在下面的例子中,只有myapp.access的tag能够匹配到该输出插件。
<match myapp.access>
@type file
path /var/log/fluent/access
</match>
匹配模式
下面的这些匹配模式可以在<match>中使用,用来匹配tag:
- 用来匹配tag的一部分(比如:a.可以匹配a.b,但是不能匹配a或者a.b.c)
- 可以用来匹配tag的0个或多个部分(比如:a.可以匹配a、a.b和a.b.c)
- {X,Y,Z}匹配X,Y或者Z(比如:{a,b}可以匹配a和b,但是不能匹配c。他可以和*或者**结合起来一起使用。)
- 如果有多个匹配模式写在
<match>里面,则可以用空格分开(比如:<match a b>能够匹配a和b。<match a.** b.* >能够匹配a,a.b,a.b.c和b.d。)
匹配顺序
Fluentd是按顺序匹配的,先在配置文件里面出现的match会先匹配。下面的例子中myapp.access永远都不会被匹配到。
# ** matches all tags
<match **>
@type blackhole_plugin
</match>
<match myapp.access>
@type file
path /var/log/fluent/access
</match>
“filter”:事件处理管道
“filter”指令的语法和”match”指令的语法相同,但是”filter”能够在管道中被连起来处理,如下所示:
Input -> filter 1 -> ... -> filter N -> Output
下面的例子展示了record_transformer fliter的用法。source首先会接收到一个{“event”:”data”}的事件,然后该事件会首先被路由到filter,filter会增加一个host_param的字段到record中,然后再把该事件发送到match中。
# http://this.host:9880/myapp.access?json={"event":"data"}
<source>
@type http
port 9880
</source>
<filter myapp.access>
@type record_transformer
<record>
host_param "#{Socket.gethostname}"
</record>
</filter>
<match myapp.access>
@type file
path /var/log/fluent/access
</match>
“system”:设置系统范围配置
以下的配置能够由”system”指令指定。也可以通过Fluentd的配置选项设置相同的配置:
- log_level
- suppress_repeated_stacktrace
- emit_error_log_interval
- suppress_config_dump
- without_source
- process_name (只能用”system”指令指定)
下面是一些例子:
<system>
# 等价于-qq选项
log_level error
#等价于--without-source选项
without_source
</system>
<system>
process_name fluentd1
</system>
process_name用来指定Fluentd监控进程和工作进程的名字,通过ps可以看到
% ps aux | grep fluentd1
foo 45673 0.4 0.2 2523252 38620 s001 S+ 7:04AM 0:00.44 worker:fluentd1
foo 45647 0.0 0.1 2481260 23700 s001 S+ 7:04AM 0:00.40 supervisor:fluentd1
“label”:用来组织filter和match
“label”指令用来降低tag路由的复杂度,通过”label”指令可以用来组织filter和match的内部路由。下面是一个配置的例子,由于”label”是内建的插件,所以他的参数需要以@开头。
<source>
@type forward
</source>
<source>
@type tail
@label @SYSTEM
</source>
<filter access.**>
@type record_transformer
<record>
# ...
</record>
</filter>
<match **>
@type elasticsearch
# ...
</match>
<label @SYSTEM>
<filter var.log.middleware.**>
@type grep
# ...
</filter>
<match **>
@type s3
# ...
</match>
</label>
在上面的例子中,forward的数据源的事件被路由到record_transformer filter和elasticsearch output中。tail数据源被路由到@system里面的grep filter和s3 output中。
@ERROR label
@ERROR label是内建的label,用来记录emit_error_event错误事件的。如果在配置文件里面设置了,当有相关的错误发生(比如:缓冲区已满或无效记录)的话,该错误事件就会被发送到< label @ERROR >。
“@include”:重用配置
可以通过”@include”来导入其他的配置文件,配置文件是按顺序导入的。如果使用模式匹配的话,文件是按字母顺序导入的。
# If you have a.conf,b.conf,...,z.conf and a.conf / z.conf are important...
# This is bad
@include *.conf
# This is good
@include a.conf
@include config.d/*.conf
@include z.conf
如果导入的文件有顺序的要求的话,最好自己主动写导入的语句,模式匹配导入容易出错。
支持的数据类型
每个插件都需要一些参数。例如:in_tail插件有rotate_wait和pos_file这两个参数。每个参数都有对应的类型与其关联。下面是这些类型的定义:
- string 类型:该类型被解析成一个字符串。string类型可以有三种形式:不带引号的字符串、带单引号的字符串和带双引号的字符串。
- integer 类型:该类型被解析成一个整数。
- float 类型:该类型被解析成一个浮点数。
- size 类型:该类型用来解析成有多少个字节。可以在整数后面加上k/K、m/M、g/G、t/T,对应的是计算机学科的度量单位。比如:12k表示为12*1024后的数值。
- time 类型:该类型被解析成时间。可以在浮点数后面加上s、m、h和d分别表示为秒、分、小时、天。可以用0.1表示100ms。
- array 类型:该类型被解析成JSON数组。这种类型还支持缩写,比如:[“key1”, “key2”]可以缩写成key1,key2。
- hash 类型:该类型被解析成JSON对象。这种类型也支持缩写,比如:{“key1”:”value1”, “key2”:”value2”}可以缩写成key1:value1,key2:value2。
常见的插件参数
这些参数是系统保留的并且带有@前缀。
- @type: 指定插件的类型。
- @id: 指定插件的id。
- @label:用来指定标签。
- @log_level:用来指定每个插件的log级别。
检查配置文件
通过–dry-run选项,可以在不启动插件的情况下检查配置文件。
fluentd --dry-run -c fluent.conf
格式建议
双引号包起来的字符串、数组和哈希类型支持多行
str_param "foo # This line is converted to "foo
bar". NL is kept in the parameter
bar"
array_param [
"a", "b"
]
hash_param {
"k":"v",
"k1":10
}
如果想让[或者{开头的字符串不被解析成数组或者对象,则需要用’或者“把该字符串包起来。
<match **>
@type mail
subject "[CRITICAL] foo's alert system"
</match>
<match tag>
@type map
map '[["code." + tag, time, { "code" => record["code"].to_i}], ["time." + tag, time, { "time" => record["time"].to_i}]]'
multi true
</match>
嵌入Ruby代码
可以在”包住的#{}里面执行Ruby代码,这可以用来获取一些机器的信息,比如hostname。
host_param "#{hostname}" # This is same with Socket.gethostname
@id "out_foo#{worker_id}" # This is same with ENV["SERVERENGINE_WORKER_ID"]
在双引号字符串中,是转义字符
被解释为转义字符。你需要用来设置”, , , ,或双引号字符串中的多个字符。
str_param "foo
bar" #
is interpreted as actual LF character