---恢复内容开始---
数据库恢复技术
- 事务:是用户定义的一个数据库操作序列,这些操作要么全做,要么全不做,是一个不可分割的工作单位。
- 事物的 ACID 特性:原子性、一致性、隔离性、持续性。
- 恢复的实现技术:建立冗余数据 -> 利用冗余数据实施数据库恢复。
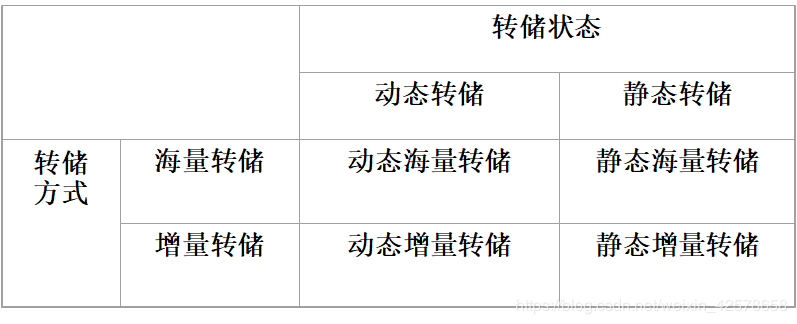
- 建立冗余数据常用技术:数据转储(动态海量转储、动态增量转储、静态海量转储、静态增量转储)、登记日志文件。
ACID特性
1. 原子性(Atomicity)
一个原子事务要么完整执行,要么干脆不执行。这意味着,工作单元中的每项任务都必须正确执行。如果有任一任务执行失败,则整个工作单元或事务就会被终止。即此前对数据所作的任何修改都将被撤销。如果所有任务都被成功执行,事务就会被提交,即对数据所作的修改将会是永久性的。
2. 一致性(Consistency)
一致性代表了底层数据存储的完整性。它必须由事务系统和应用开发人员共同来保证。事务系统通过保证事务的原子性,隔离性和持久性来满足这一要求; 应用开发人员则需要保证数据库有适当的约束(主键,引用完整性等),并且工作单元中所实现的业务逻辑不会导致数据的不一致(即,数据预期所表达的现实业务情况不相一致)。例如,在一次转账过程中,从某一账户中扣除的金额必须与另一账户中存入的金额相等。
3. 隔离性(Isolation)
隔离性意味着事务必须在不干扰其他进程或事务的前提下独立执行。换言之,在事务或工作单元执行完毕之前,其所访问的数据不能受系统其他部分的影响。
当我们编写了一条 update 语句,提交到数据库的一刹那间,有可能别人也提交了一条 delete 语句到数据库中。也许我们都是对同一条记录进行操作,可以想象,如果不稍加控制,就会出大麻烦来。我们必须保证数据库操作之间是“隔离”的(线程之间有时也要做到隔离),彼此之间没有任何干扰。
4. 持久性(Durability)
持久性表示在某个事务的执行过程中,对数据所作的所有改动都必须在事务成功结束前保存至某种物理存储设备。这样可以保证,所作的修改在任何系统瘫痪时不至于丢失。当我们执行一条 insert 语句后,数据库必须要保证有一条数据永久地存放在磁盘中。
隔离性
三类数据读问题
1.Dirty Read(脏读):
一个事务读到另外一个事务还没有提交的数据,我们称之为脏读。(进行存款事务时候,还没有存完,允许查询事务)
2.Unrepeatable Read(不可重复读):
在数据库访问中,一个事务范围内两个相同的查询却返回了不同数据。这是由于查询时系统中其他事务修改的提交而引起的。
例如:事务B中对某个查询执行两次,当第一次执行完时,事务A对其数据进行了修改。事务B中再次查询时,数据发生了改变
3.Phantom Read(幻读)
幻读,是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样.
两类数据更新问题
1.第一类丢失更新
2.第二类丢失更新
首先看看“脏读”,看到“脏”这个字,我就想到了恶心、肮脏。数据怎么可能脏呢?其实也就是我们经常说的“垃圾数据”了。比如说,有两个事务,它们在并发执行(也就是竞争)。看看以下这个表格,您一定会明白我在说什么:
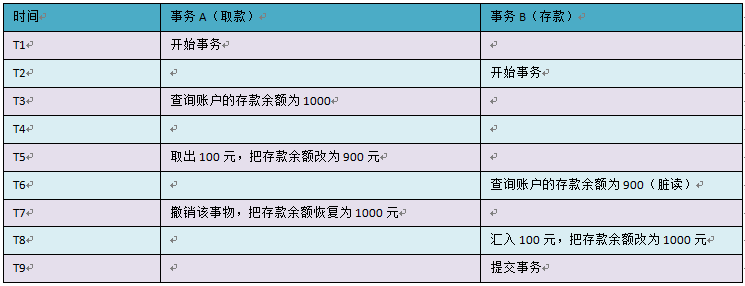
余额应该为 1100 元才对!请看 T6 时间点,事务 A 此时查询余额为 900 元,这个数据就是脏数据,它是事务 A 造成的,明显事务没有进行隔离,渗过来了,乱套了。
所以脏读这件事情是非常要不得的,一定要解决掉!让事务之间隔离起来才是硬道理。
不可重复读又怎么解释呢?还是用类似的例子来说明:
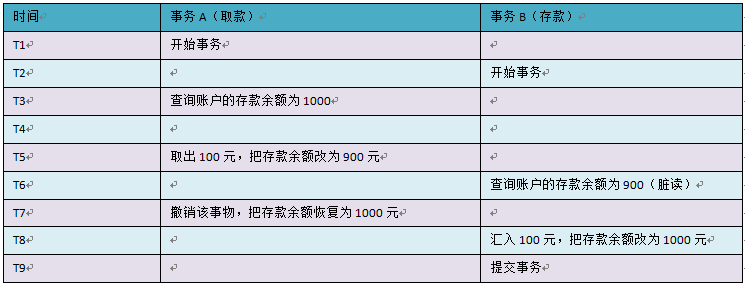
事务 A 其实除了查询了两次以外,其他什么事情都没有做,结果钱就从 1000 变成 0 了,这就是重复读了。可想而知,这是别人干的,不是我干的。其实这样也是合理的,毕竟事务 B 提交了事务,数据库将结果进行了持久化,所以事务 A 再次读取自然就发生了变化。
幻读

银行工作人员,每次统计总存款,都看到不一样的结果。不过这也确实也挺正常的,总存款增多了,肯定是这个时候有人在存钱。但是如果银行系统真的这样设计,那算是玩完了。这同样也是事务没有隔离所造成的,但对于大多数应用系统而言,这似乎也是正常的,可以理解,也是允许的。银行里那些恶心的那些系统,要求非常严密,统计的时候,甚至会将所有的其他操作给隔离开,这种隔离级别就算非常高了(估计要到 SERIALIZABLE 级别了)。
归纳一下,以上提到了事务并发所引起的跟读取数据有关的问题,各用一句话来描述一下:
1.脏读:事务 A 读取了事务 B 未提交的数据,并在这个基础上又做了其他操作。
2.不可重复读:事务 A 读取了事务 B 已提交的更改数据。
3.幻读:事务 A 读取了事务 B 已提交的新增数据。
第一条是坚决抵制的,后两条在大多数情况下可不作考虑。
这就是为什么必须要有事务隔离级别这个东西了,它就像一面墙一样,隔离不同的事务。看下面这个表格,您就清楚了不同的事务隔离级别能处理怎样的事务并发问题:

Read Uncommitted:最低的隔离级别,什么都不需要做,一个事务可以读到另一个事务未提交的结果。所有的并发事务问题都会发生。
Read Committed:只有在事务提交后,其更新结果才会被其他事务看见。可以解决脏读问题。
Repeated Read:在一个事务中,对于同一份数据的读取结果总是相同的,无论是否有其他事务对这份数据进行操作,以及这个事务是否提交。可以解决脏读、不可重复读。
Serialization:事务串行化执行,隔离级别最高,牺牲了系统的并发性。可以解决并发事务的所有问题。
通常,在工程实践中,为了性能的考虑会对隔离性进行折中。
更新丢失问题
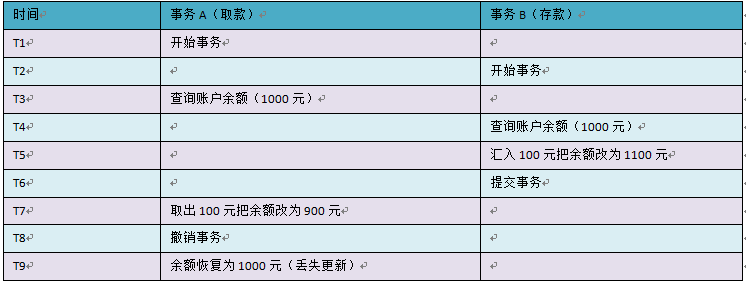
第一类丢失更新,A事务撤销时,把已经提交的B事务的更新数据覆盖了。这种错误可能造成很严重的问题,通过下面的账户取款转账就可以看出来:
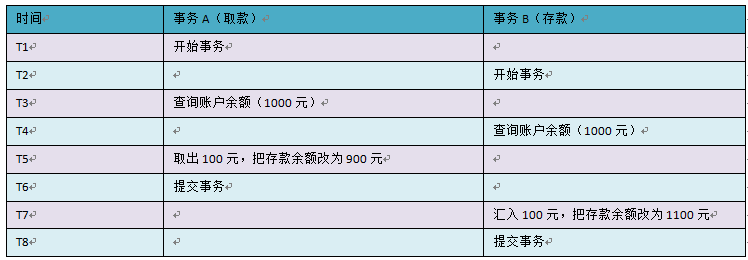
第二类丢失更新,B事务覆盖A事务已经提交的数据,造成A事务所做操作丢失
解决更新丢失的办法:
|
悲观锁 |
试图在更新之前把行锁住,使用SELECT … FOR UPDATE然后更新数据。 |
|||
|
乐观锁 |
认为数据不会被其他用户修改,修改屏幕上的信息而不要锁 |
1.使用版本列的乐观锁定 |
增加NUMBER或TIMESTAMP或DATE列。每次修改行时,检查数据库中这一列的值与最初读出的值是否匹配,匹配的话修改数据且通过触发器要负责递增NUMBER、DATE、TIMESTAMP。 |
增加一个时间戳列,可以知道最后修改时间。 |
|
2.使用校验和的乐观锁定 |
用基数据本身来计算一个“虚拟的”版本列,生成散列值进行比较。 |
数据库独立性好,从CPU使用和网络传输方面来看,资源开销量大。 |
||
|
3.使用 ORA_ROWSCN的乐观锁定 |
建立在Oracle SCN的基础上,建表时,启用ROWDEPENDENCIES,防止整个数据块的ORA_ROWSCN向前推进。可以用SCN_TO_TIMESTAMP(ORA_ROWSCN)将SCN转换为时间格式。 |
将原先的悲观锁机制修改为乐观锁来控制并发,可以使用ORA_ROWSCN,这样可以无需增加新列。也可以通过SCN_TO_TIMESTAMP来获取最后修改时间。 |
||
数据库恢复技术
数据库管理系统要解决的问题:
必须保证多个事务的交叉运行不影响这些事务的原子性
必须保证被强行终止的事务对数据库和其他事务没有任何影响
这两个问题就是数据库管理系统的恢复机制和并发控制机制的责任
把数据库从错误状态恢复到某一已知的正确状态(亦称为一致状态或完整状态),就称为数据库恢复。
故障的分类
事物内部的故障
两个更新操作要么全部完成要么全部不做。否则就会使数据库处于不一致状态,例如只把账户甲的余额减少了而没有把账户乙的余额增加。在这段程序中若产生账户甲余额不足的情况,应用程序可以发现并让事务滚回,撤销已作的修改,恢复数据库到正确状态
常见的原因:事务内部更多的故障是非预期的,是不能由应用程序处理的。
- 运算溢出
- 并发事务发生死锁而被选中撤销该事务
- 违反了某些完整性限制等
系统故障(软故障)
指造成系统停止运转的任何事件,使得系统要重新启动
常见的原因:
- 特定类型的硬件错误(如CPU故障)
- 操作系统故障
- DBMS代码错误
- 系统断电
介质故障(硬故障,指外存故障)
常见原因:
- 磁盘损坏
- 磁头碰撞
- 操作系统的某种潜在错误
- 瞬时强磁场干扰
恢复的实现技术
1.恢复操作的基本原理:冗余
利用存储在系统其他地方的冗余数据来重建数据库中已被破坏或者不正确的那部分数据
2.恢复机制涉及到的关键:
建立数据冗余数据的方法:数据转储,登陆日志文件
数据转储
转储是指DBA将整个数据库复制到磁带或另一个磁盘上保存起来的过程,备用的数据成为后备副本或后援副本
数据转储的使用
数据库遭到破坏后可以将后备副本重新装入
重装后备副本只能将数据库恢复到转储时的状态
转储方法
静态转储
- 系统中无运行事务时进行的转储操作
- 转储期间不允许对数据库进行操作
- 转储开始时数据库处于一致性状态
- 得到的一定是一个数据一致性的副本
优点:实现简单
缺点:1.降低了数据库的可用性 2.转储必须等待正运行的用户事务结束 3.新的事务必须等转储结束
动态转储
- 转储操作与用户并发进行
- 转储期间允许对数据库进行存取或修改
优点:1.不用等待正在进行的事务结束 2.转储期间允许对数据库进行存取或修改
缺点:不能保证副本中的数据正确有效
动态转储进行故障恢复,需要把动态转储期间各事务对数据库的修改活动登记下来,建立日志文件;后备副本加上日志文件才能把数据库恢复到某一时刻的正确状态
海量转储
- 每次转储全部数据库
增量转储
- 只转储上次转储更新过的数据
海量转储与增量转储的比较
1.从恢复角度看,使用海量转储得到的后备副本进行恢复往往更方便
2.如果数据库很大,事务处理又十分频繁,则增量转储更有效
登记日志文件
日志文件:记录事务对数据库的更新操作文件
格式:1. 以记录为单位的日志文件(事务标识,操作类型,操作对象,更新前数据的旧值,更新后数据的新值);2. 以数据表为单位的日志文件(事务标识,被更新的数据块)
内容:1 各个事务的开始标记;2 各个事务的结束标记;3 各个事务所有的更新操作
作用:1 进行事务故障恢复;2 进行系统故障恢复;3 协助后备副本进行介质故障恢复
利用静态转储副本和日志文件进行恢复
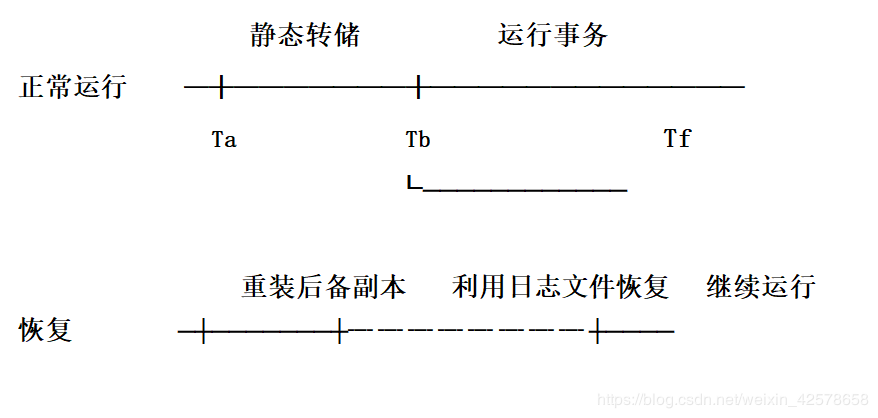
对上图进行说明:
- 系统在Ta时刻停止运行事务,进行数据库转储
- 在Tb时刻转储完毕,得到Tb时刻的数据库一致性副本
- 系统运行到Tf时刻发生故障
- 为恢复数据库,首先由DBA重装数据库后备副本,将数据库恢复到Tb时刻的状态
- 重新运行自Tb~Tf时刻的所有更新事务,把数据库恢复到故障发生前的一致状态
登记日志文件
基本原则:登记的次序严格按并行事务执行的时间次序;必须先写日志文件,后写数据库
恢复策略
事务故障的恢复
事务故障:事务运行至正常终止点前被终止
恢复方法:由恢复子系统利用日志文件撤销(UNDO)此事务已对数据库进行的修改
注:事务故障的恢复由系统自动完成,对用户是透明的,不需要用户干预
恢复步骤
- 反向扫描文件日志(从后往前扫描),查找该事务的更新操作
- 对该事务的更新操作执行逆操作,即将日志记录中“更新前的值”写入数据库
- 继续反向扫描日志文件,查找该事务的其他更新操作,并做同样处理。
- 如此处理下去,直至读到此事务的开始标记,事务故障恢复就完成了。
系统故障的恢复
系统故障:
- 未完成事务对数据库的更新已写入数据库
- 已提交事务对数据库的更新还留在缓存区没来得及写入数据库
恢复方法:
- UNDO故障发生时未完成的事务
- Redo已完成的事务
注:系统故障的恢复由系统在重新启动时自动完成,不需要用户干预
恢复步骤:
- 正向扫描日志文件(1.将在故障发生前已经提交的事务加入重做(REDO)队列,这些事务既有begin transaction记录,也有commit记录;2.将在故障发生时未完成的事务加入撤销(Undo)队列,这些事务中只有begin transaction记录,无相应的commit记录)
- 对撤销(Undo)队列事务进行撤销(Undo)处理(1.反向扫描日志文件,对每个undo事务的更新操作进行逆操作;2.将日志记录中“更新前的值”写入数据库)
- 对重做(Redo)队列事务进行重做(Redo)处理(1.正向扫描日志文件,对每个REDO事务重新执行登记的操作;2.将日志记录中“更新后的值”写入数据库)
介质故障的恢复(需要DBA介入)
- 重装数据库
- 重做已完成的事务
具有检查点的恢复技术
解决问题:
- 搜索整个日志将耗费大量的时间
- REDO处理:重新执行,浪费了大量时间
解决方法:
- 在日志文件中增加检查点记录
- 增加重新开始文件
- 恢复子系统在登录日志文件期间动态地维护日志
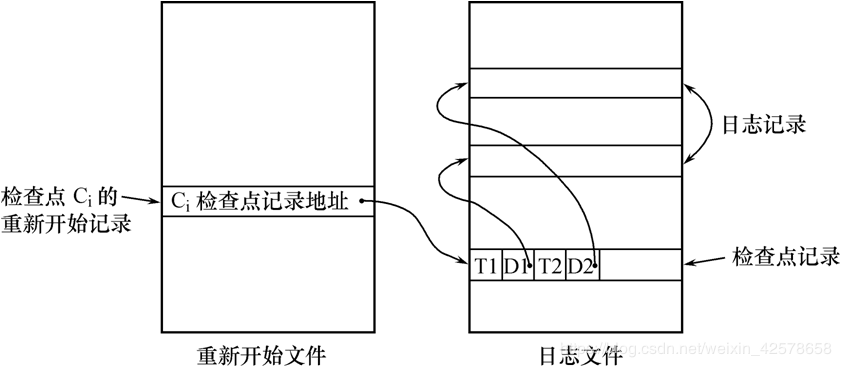
建立检查点:
恢复子系统可以定期或不定期地建立检查点,保存数据库状态
- 定期:按照预定的一个时间间隔,如每隔一小时建立一个检查点
- 不定期:按照某种规则,如日志文件已写满一半建立一个检查点
恢复:
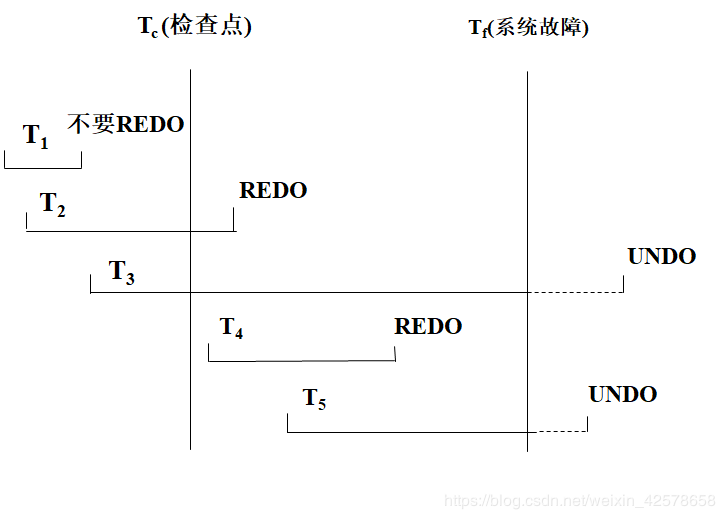
T1:在检查点之前提交
T2:在检查点之前开始执行,在检查点之后故障点之前提交
T3:在检查点之前开始执行,在故障点时还未完成
T4:在检查点之后开始执行,在故障点之前提交
T5:在检查点之后开始执行,在故障点时还未完成
利用检查点的恢复步骤
- 从重新开始文件中找到最后一个检查点记录在日志文件中的地址,由该地址在日志文件中找到最后一个检查点记录
- 由该检查点记录得到检查点建立时刻所有正在执行的事务清单ACTIVE-LIST
- 建立两个事务队列
- UNDO-LIST
- REDO-LIST
- 把ACTIVE-LIST暂时放入UNDO-LIST队列,REDO队列暂为空。
- 建立两个事务队列
- 从检查点开始正向扫描日志文件,直到日志文件结束
- 如有新开始的事务Ti,把Ti暂时放入UNDO-LIST队列
- 如有提交的事务Tj,把Tj从UNDO-LIST队列移到REDO-LIST队列
- 对UNDO-LIST中的每个事务执行UNDO操作
- 对REDO-LIST中的每个事务执行REDO操作
数据库镜像
数据库镜像
- DBMS自动把整个数据库或其中的关键数据复制到另一个磁盘上
- DBMS自动保证镜像数据与主数据库的一致性,每当主数据库更新时,DBMS自动把更新后的数据复制过去,如图
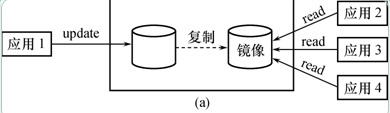
出现介质故障时
- 可由镜像磁盘继续提供使用
- 同时DBMS自动利用镜像磁盘数据进行数据库的恢复
- 不需要关闭系统和重装数据库副本
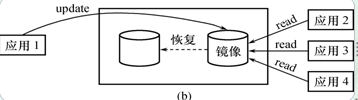
没有出现故障时
- 可用于并发操作
- 一个用户对数据加排他锁修改数据,其他用户可以读镜像数据库上的数据,而不必等待该用户释放锁
结论
事务是数据库的逻辑工作单位
DBMS保证系统中一切事务的原子性、一致性、隔离性和持续性
DBMS必须对事务故障、系统故障和介质故障进行恢复
恢复中最经常使用的技术:数据库转储和登记日志文件
恢复的基本原理:利用存储在后备副本、日志文件和数据库镜像中的冗余数据来重建数据库
常用恢复技术
事务故障的恢复(UNDO)
系统故障的恢复(UNDO + REDO)
介质故障的恢复(重装备份并恢复到一致性状态 + REDO)
提高恢复效率的技术
检查点技术(
Ø可以提高系统故障的恢复效率
Ø可以在一定程度上提高利用动态转储备份进行介质故障恢复的效率
)
镜像技术(镜像技术可以改善介质故障的恢复效率)