转载:https://blog.csdn.net/kwame211/article/details/80364079
假设我们提供了这样的数据样本(样本值取自于y=3*x1+4*x2):
x1 x2 y
1 4 19
2 5 26
5 1 19
4 2 29
x1和x2是特征,y是预测目标,我们需要以一条直线来拟合上面的数据,待拟合的函数如下(也就是建立的模型):
h(θ)=θ1x1+θ2x2
我们的目的就是要求出θ1和θ2的值,让h(θ)尽量逼近目标值y。
梯度下降法原理:
我们首先确定损失函数:
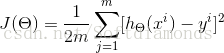
其中,J(θ)是损失函数,m代表每次取多少样本进行训练,如果采用SGD进行训练,那每次随机取一组样本,m=1;如果是批处理,则m等于每次抽取作为训练样本的数量。θ是参数,对应θ1和θ2。求出了θ1和θ2,h(x)的表达式就出来了:
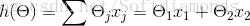
我们的目标是让损失函数J(θ)的值最小,根据梯度下降法,首先要用J(θ)对θ求偏导:
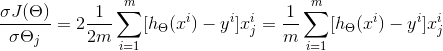
由于是要最小化损失函数,所以参数θ按其负梯度方向来更新:
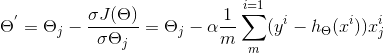
示例:
BGD(Batch gradient descent)批量梯度下降法:每次迭代使用所有的样本。每次迭代都需要把所有样本都送入,这样的好处是每次迭代都顾及了全部的样本,做的是全局最优化。