1. 生成器函数
一个包含yield关键字的函数就是一个生成器函数。yield可以为我们从函数中返回值,但是yield又不同于return,return的执行意味着程序的结束,调用生成器函数不会得到返回的具体的值,而是得到一个可迭代的对象。每一次获取这个可迭代对象的值,就能推动函数的执行,获取新的返回值。直到函数执行结束。
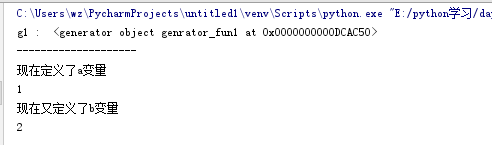
import time def genrator_fun1(): a = 1 print('现在定义了a变量') yield a b = 2 print('现在又定义了b变量') yield b g1 = genrator_fun1() print('g1 : ',g1) #打印g1可以发现g1就是一个生成器 print('-'*20) #我是华丽的分割线 print(next(g1)) time.sleep(1) #sleep一秒看清执行过程 print(next(g1))
结果:
2. 生成器有什么好处呢?就是不会一下子在内存中生成太多数据
假如我想让工厂给学生做校服,生产2000000件衣服,我和工厂一说,工厂应该是先答应下来,然后再去生产,我可以一件一件的要,也可以根据学生一批一批的找工厂拿。
而不能是一说要生产2000000件衣服,工厂就先去做生产2000000件衣服,等回来做好了,学生都毕业了。。。
def produce(): """生产衣服""" for i in range(2000000): yield "生产了第%s件衣服"%i product_g = produce() print(product_g.__next__()) #要一件衣服 print(product_g.__next__()) #再要一件衣服 print(product_g.__next__()) #再要一件衣服 num = 0 for i in product_g: #要一批衣服,比如5件 print(i) num +=1 if num == 5: break
结果:

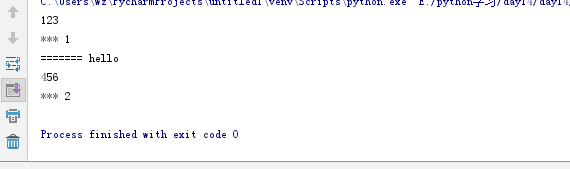
3 send
def generator(): print(123) content = yield 1 print('=======',content) print(456) yield 2 g = generator() ret = g.__next__() print('***',ret) ret = g.send('hello') #send的效果和next一样 print('***',ret) #send 获取下一个值的效果和next基本一致 #只是在获取下一个值的时候,给上一yield的位置传递一个数据 #使用send的注意事项 # 第一次使用生成器的时候 是用next获取下一个值 # 最后一个yield不能接受外部的值
结果:
列表推导式和生成器表达式
l = [i for i in range(10)] print(l) l1 = ['选项%s'%i for i in range(10)] print(l1)
结果:

1.把列表解析的[]换成()得到的就是生成器表达式
2.列表解析与生成器表达式都是一种便利的编程方式,只不过生成器表达式更节省内存
3.Python不但使用迭代器协议,让for循环变得更加通用。大部分内置函数,也是使用迭代器协议访问对象的。例如, sum函数是Python的内置函数,该函数使用迭代器协议访问对象,而生成器实现了迭代器协议,所以,我们可以直接这样计算一系列值的和:
sum( x**2 for x in range(4)) #生成一个生成器
print(sum,type(sum))
l=sum([ x**2 for x in range(4)]) #列表推导式
print(l)
结果:

各种推导式玩法
推导式套路
之前我们已经学习了最简单的列表推导式和生成器表达式。但是除此之外,其实还有字典推导式、集合推导式等等。
下面是一个以列表推导式为例的推导式详细格式,同样适用于其他推导式
例一:30以内所有能被3整除的数
multiples = [i for i in range(30) if i % 3 is 0] print(multiples) # Output: [0, 3, 6, 9, 12, 15, 18, 21, 24, 27]
例二:30以内所有能被3整除的数的平方
def squared(x): return x*x multiples = [squared(i) for i in range(30) if i % 3 is 0] print(multiples)
结果;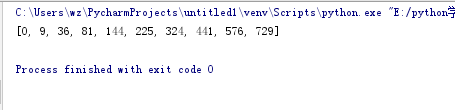
例三:找到嵌套列表中名字含有两个‘e’的所有名字
names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'], ['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']] print([name for lst in names for name in lst if name.count('e') >= 2]) # 注意遍历顺序,这是实现的关键
结果:

例一:将一个字典的key和value对调
mcase = {'a': 10, 'b': 34}
mcase_frequency = {mcase[k]: k for k in mcase}
print(mcase_frequency)
结果:

例二:合并大小写对应的value值,将k统一成小写
mcase = {'a': 10, 'b': 34, 'A': 7, 'Z': 3}
mcase_frequency = {k.lower(): mcase.get(k.lower(), 0) + mcase.get(k.upper(), 0) for k in mcase.keys()}
print(mcase_frequency)
结果:

集合推导式
例:计算列表中每个值的平方,自带去重功能
squared = {x**2 for x in [1, -1, 2]}
print(squared)
# Output: set([1, 4])