《Linux内核原理与设计》第五周作业
视频学习及操作分析
一、用户态、内核态和中断
内核态在CPU执行中对应高执行级别,执行级别为0级,具有特权指令,可以访问任意物理地址;用户态执行级别为3级,在低级别执行状态下,代码掌控范围会受到限制。
内核态和用户态的区分:两者有一显著的区分方法,就是cs:eip寄存器。内核态时,cs:eip可以是任意地址,在32位X86机器上具有4G进程地址空间,因此既可以访问0X00000000-0Xbfffffff的地址空间,也可以访问0Xc0000000以上的地址空间;而用户态,只能访问0X00000000-0Xbfffffff的地址空间。
中断处理是从用户态进入内核态主要的方式,从用户态切到内核态时,必须保存用户态寄存的上下文,中断/int指令会在堆栈上保存寄存器的值。进入中断程序,首先要保存现场,保存需要用到的寄存器数据,通过
#define SAVE_ALL
把其他寄存器的值push到内核堆栈中;退出程序时,回复现场,恢复保存寄存器的数据,通过RESTORE_ALL把值popl出来。
interrupt(ex:int 0x80)-save
cs:eip/ss:esp/eflags(current)to kernel stack,
then load cs:eip(entry of a specific ISR)and
ss:esp(point to kernel stack) //中断保存系统调用,
保存了cs:eip的值,堆栈段寄存器,当前栈顶,标志寄存器到内核堆栈,
然后加载了中断服务程序入口到cs:eip, 并把堆栈段和esp指向内核堆栈
二、系统调用概述
API和系统调用:
API是应用程序编程接口,只是一个函数定义,Libc库定义的一些API引用了封装历程,可以发布系统调用,一般每个系统调用对应一个封装历程,库再用这些封装例程定义给用户的API,这样调用系统不需要再进行汇编,只需要调用一个函数即可;而系统调用是通过软中断向内核发出一个明确的请求。API和系统调用并往往不是一一对应关系。
系统调用的三层皮:xyz、system_call和sys_xyz,系统调用将xyz和sys_xyz关联起来了;在使用系统调用时,需要输入输出参数,通过eax寄存器,传递一个名为系统调用号的参数,来指明需要调用的那个系统。寄存器在传递参数时需要注意的是:
(1)每个参数长度不能超过寄存器的长度,即32位;
(2)除eax系统调用外,参数的个数不能超过六个(ebc,ecx,edx,esi,edi,ebp)超过6个参数需将某寄存器作为指针指向内存,通过内存来传递数据。

使用库函数API和C代码中嵌入汇编代码两种方式使用同一个系统调用
这里我们在系统调用列表中选择fork函数进行系统调用
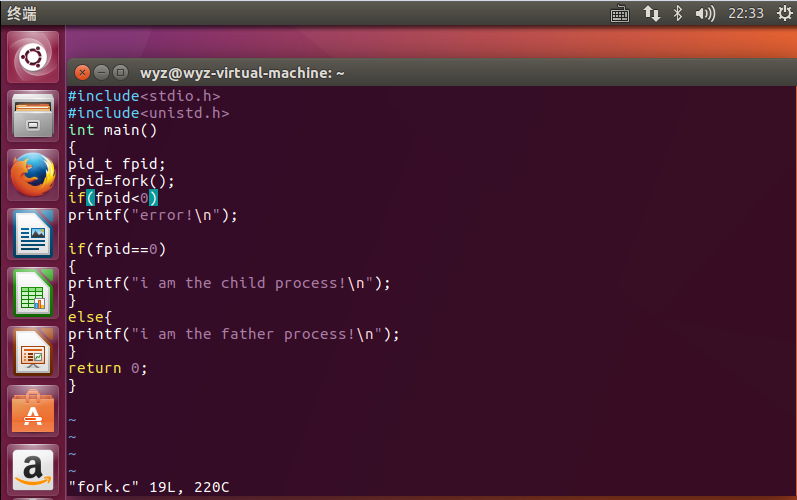
首先我们用C语言编写fork()函数如下:
接下来我们编写C语言嵌入式汇编语言:
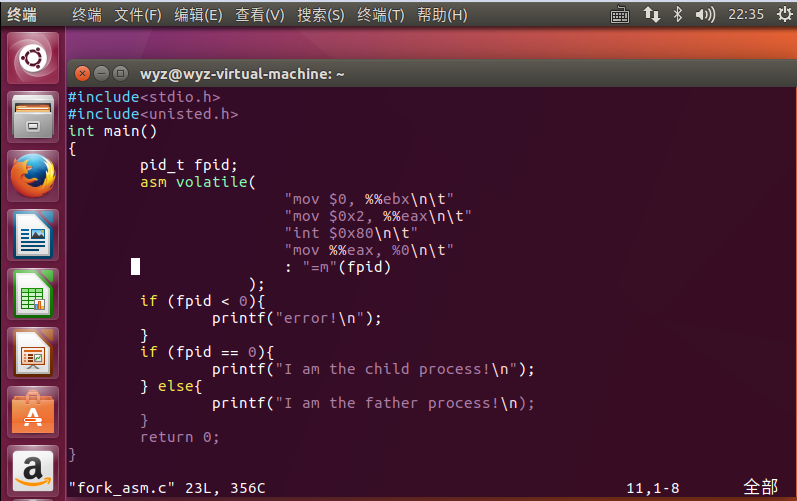
分析嵌入式代码:
#include<stdio.h>
#include<unistd.h>
int main()
{
pid_t fpid; //传递参数
asm volatile( //进入嵌入式汇编,volatile表示禁止服务器优化
"mov $0, %%ebx
" //将ebx寄存器清零
"mov $0x2, %%eax
" //通过系统调用列表查到fork函数参数为2,因此把2号系统调用赋给eax寄存器
"int $0x80
" //执行命令,系统中断
"mov %%eax, %0
" //将eax的值赋给第0个变量
: "=m"(fpid) //0号变量对应,即把eax的值放到内存中
);
if (fpid < 0){
printf("error!
");
}
if (fpid == 0){ //进程标记为0
printf("I am the child process!
"); //输出“这是子进程!”
} else{ //否则
printf("I am the father process!
"); //输出“这是父进程!”
}
return 0;
}
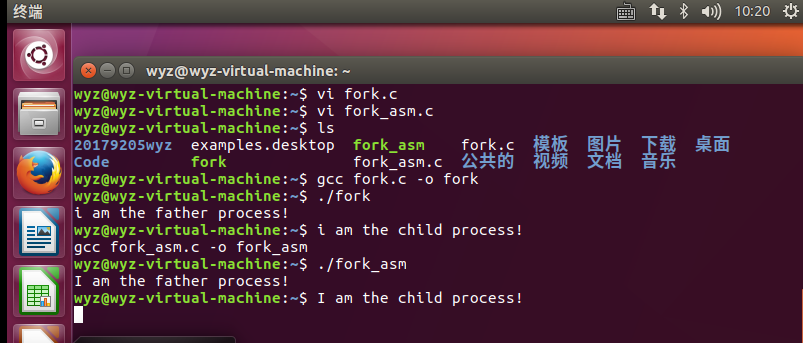
在fork.c以及fork_asm.c文件中编好代码,ls可以查看到这两个可执行文件,那么我们来查看两个程序的执行结果,发现两者运行结果一致。
教材七、八章学习
1、不同的设备对应的中断不同,每个设备都通过一个唯一的数字标志,这些中断值通常被称为中断请求IRQ线,这样操作系统才能给不同的中断提供对应的中断处理程序。它是一种由设备使用的硬件资源异步向处理器发信号,由硬件来打断操作系统。在相应一个特定中断时,内核会执行一个函数,该函数叫做中断处理程序。由于中断处理程序既想运行的快,又想完成的工作量多,因此把中断切分为上半部(立即执行)和下半部(稍后执行)。
2、中断处理程序上、下半步处理逻辑分配原则:
上半部:任务对时间非常敏感;任务和硬件相关;任务保证不被其他中断打断,不并发,不阻塞。其余情况分配到下半步。
3、注册中断处理程序:通过request_irq()函数可注册一个中断处理程序,并且激活给定的中断线,irq表示分配的中断号;handler为指针,指向实际中断处理程序;flags参数可以为0,也可能是下列一个或多个标志的位掩码(IRQF_DISABLED、IRQF_SAMPLE_RANDOM、IRQF_TIMER、IRQF_SHARED)第四个参数name与中断相关的设备的ASCII文本表示。 第五个参数dev用于共享中断线,当中断需要退出时,dev提供唯一的标志信息,以便从共享中断线的中断处理程序中删除指定程序。
注:request_irq()函数可能会睡眠,所以不能在中断上下文或其他不允许阻塞的代码中调用该函数。
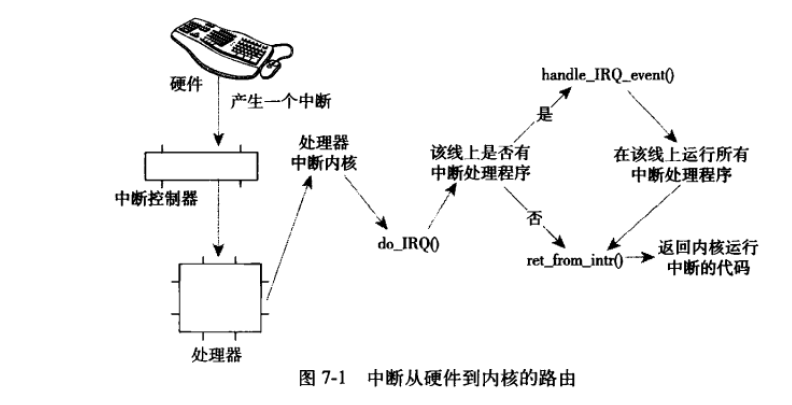
4、在内核中,中断的旅程开始于预定义入口点,这类似于系统调用。对于每条中断线,处理器都会跳到对应的一个唯一的位置。这样,内核就可以知道所接收中断的IRQ号了。初始入口点只是在栈中保存这个号,并存放当前寄存器的值(这些值属于被中断的任务);然后,内核调用函数do_IRQ().从这里开始,大多数中断处理代码是用C写的。书中P100页给出了从中断从硬件到内核的路由过程,总结的很明白:
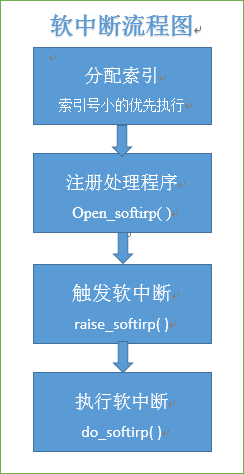
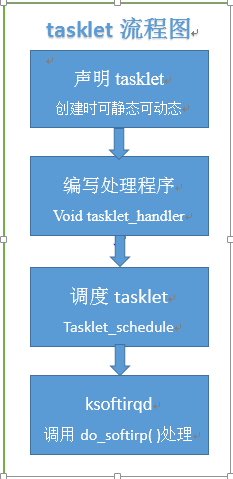
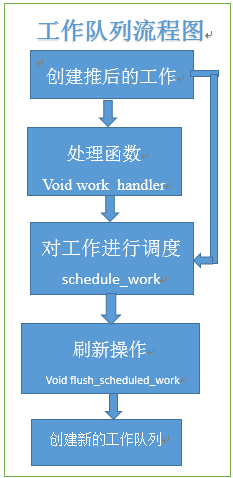
5、下半部的实现机制主要有三种,软中断、tasklet和工作队列,工作队列的机制与它们完全不同,工作队列可把工作推后,交由一个内核线程去执行。在机制的选择上,有休眠需求,选工作队列;追求更高的性能,考虑软中断,它是在编译期间静态分配的,一个软中断不会抢占另外一个软中断,唯一可以抢占软中断的是中断处理程序;;否则最好用tasklet,而tasklet是通过软中断实现的,所以不能睡眠,可以动态地注册或注销(也可以静态)。
三种实现机制的流程如下:
遇到的问题
同步执行和异步执行有什么根本的差别?
同步和异步关注的是消息通信机制,所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由调用者主动等待这个调用的结果。而异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。知乎上有个打电话的例子,感觉通俗易懂。
参考链接:异步执行