【第一部分】视频学习心得及问题总结
1.视频学习心得
俞子君:在视频的学习中,我重新认识了深度学习这一概念。首先,认清了人工智能、机器学习和深度学习的概念,也明白了这三个概念之间的从属关系。通过对于传统机器学习和深度学习的比较,发现传统的机器学习是由人为规定的特征进行划分,更加片面,而深度学习则是通过从简单特征到复杂特征的演变从而最后得出最贴切的结论。并且深度学习花费的时间要远远短于传统机器学习所需要的时间。从不同的实例讲解中,我也知道了人工智能和深度学习所能完成的些许事情,并且也了解到人工智能这一概念早在八十年前就已经有了,这是我没有预料到的。另外,我也发现学习深度学习需要扎实的数学功底和思维能力,想要学好这一门技术,我还需要继续努力钻研!希望在接下来的学习中,能够收获到更多!
李剑飞:本次观看完两个视频后,打开了我对人工智能的新世界大门,也为我普及了许多概念,打破了我以往片面和肤浅的认识。比如了解到了人工智能和机器学习以及深度学习之间的逐层分解下的联系,从规模和复杂程度上,更深层次的了解到了从专家系统到机器学习的区别和进步。更是为我普及了从传统机器学习到深度学习的历史发展脉络,当然也让我第一次了解到了深度学习的能与不能。不得不再一次感叹人类模仿学的伟大,通过模仿生物神经元从而发展出单层感知器,多层感知器。而反向传播和梯度消失的分析让我再一次想起了被数字逻辑和线性代数支配的恐惧。为什么要了解浅层神经网络?因为深度学习就是深层次的神经网络模型,从而诞生出了逐层预训练,自编码器和受限玻尔兹曼机技术。虽然现在后两者技术已经过时,不再使用。但是了解这两项技术可以为以后的进一步学习埋下伏笔,同时再一次见证前人的智慧结晶。
林思源:对神经网络的发展较之前有更进一步的认识,了解到神经网络所擅长和不擅长的,以及使用神经网络解决问题的优点和缺点。
卢浩:哪怕算法没有主观上的歧视,但因为数据的不公正也很可能给出带有歧视的结果。深度学习虽然强大,但也很容易被攻击。传统算法不容易被攻击不是因为安全,而是准确度不值得被攻击
李瑞涛:绪论以及概述的前半部分:大体上有两个重点,那就是深度学习的优缺点,亦即深度学习能干什么,不能干什么。深度学习的用处简单来说正如计算机最初的用途一样,就是替人完成繁杂工作的。而深度学习的缺点与不足中,个人比较重要而且难以解决的主要有两个:
-
易被攻击。如果有人故意用大量“不正常”的数据对一套基于深度学习的系统进行训练,就会导致这套系统出问题。比如让翻译器把某些语句翻译成不和原意,通过训练人为设置的文字。
-
模型难以迁移。简单的说,机器学习几乎不可能做到举一反三,这是计算机与人不可跨越的一道鸿沟。比如教一个三岁小孩认狗,首先指着哈士奇教他这是狗,教会之后,第二天看到一只柴犬,不需要额外说明,他也能认出这是狗;而对计算机来说,认哈士奇需要专门训练,认柴犬也需要另外专门训练,认哈士奇的“经验”难以迁移到认柴犬上。
概述的后半段:这一个多小时全是新知识,这部分大部分思想理解了,但各种公式函数之类的令人头疼。
蔺一迪:在这里我对深度学习有了更深入的理解。深度学习是机器学习之下神经网络的一个分支,相比于旧时的传统机器学习,神经网络没有人工的参与,可以自动学习特征,花费时间短,人工投入量少,因此如今被广范围应用。
我个人对深度学习的理解是:人们取得一部分训练数据,进行输入输出,最终选择训练效果最好的参数传递到模型中,从而进行对数据的预测、分类等,而如何选择最好的参数呢?就需要loss函数(训练值与实际值得到的差)与梯度下降方法。
随着深度学习的不断发展,其被应用到了各个领域,应用范围之广,但是深度学习并不是万能的,它仍有很多缺点例如算法输出不稳定,容易被攻击(对像素加一些噪声就会有截然不同的结果)因此,虽然深度学习中的神经网络模拟人体内的神经细胞,但深度学习只是单纯依靠数据从而训练模型,得到结果,与我们人类思考模式仍有很大的区别。
2.问题总结
李剑飞:每一次人工智能技术的取得突破进步(以至于让人们感受到会被AI所取代)之后,都会伴随一次人工智能的大低谷。所以很好奇会有哪些的技术的突破和发现会导致的下一次人工智能的突破进步和大低谷?
林思源:神经网络的激活函数,深层网络的梯度消失
俞子君:视频中说人工智能不可能与人类相媲美的重要原因是人类会进化,想知道具体会表现在哪一方面。
蔺一迪:1 神经网络具体结构解析:包括输入输出、loss、梯度下降等一系列成分之间的联系;2 不同的激活函数,例如sigmoid,ReLU等适用情况有哪些
【第二部分】代码练习
俞子君:




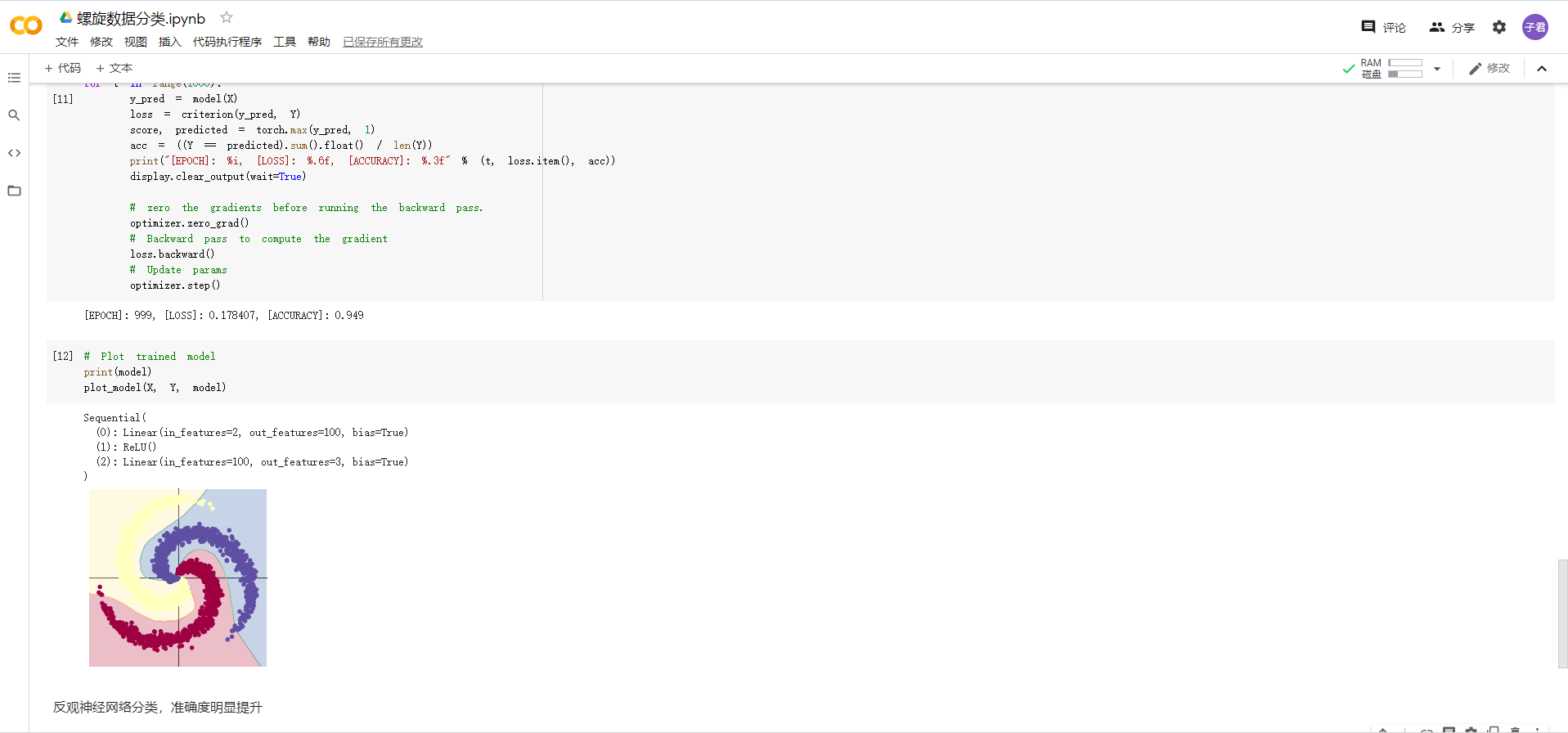
通过对于线性结构和神经网络分类的对比,进一步反映了深度学习我们应该掌握的内容——提高匹配的准确率。
李剑飞:
*牛刀小试:*第一次在谷歌 Colab 上进行pytorch的小测试,对于可以直接运行代码感到很有意思,后了解到其本质是linux虚拟机。
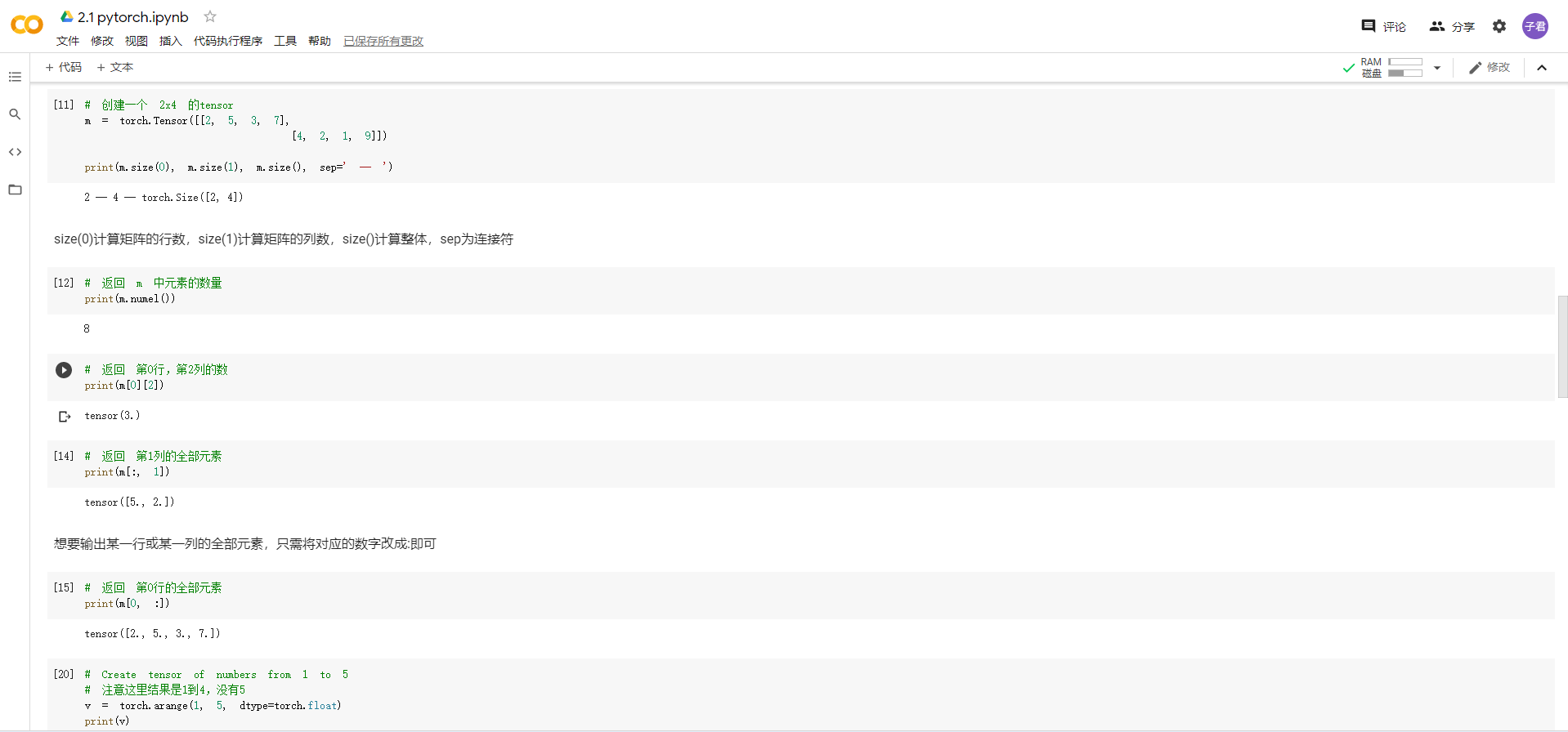
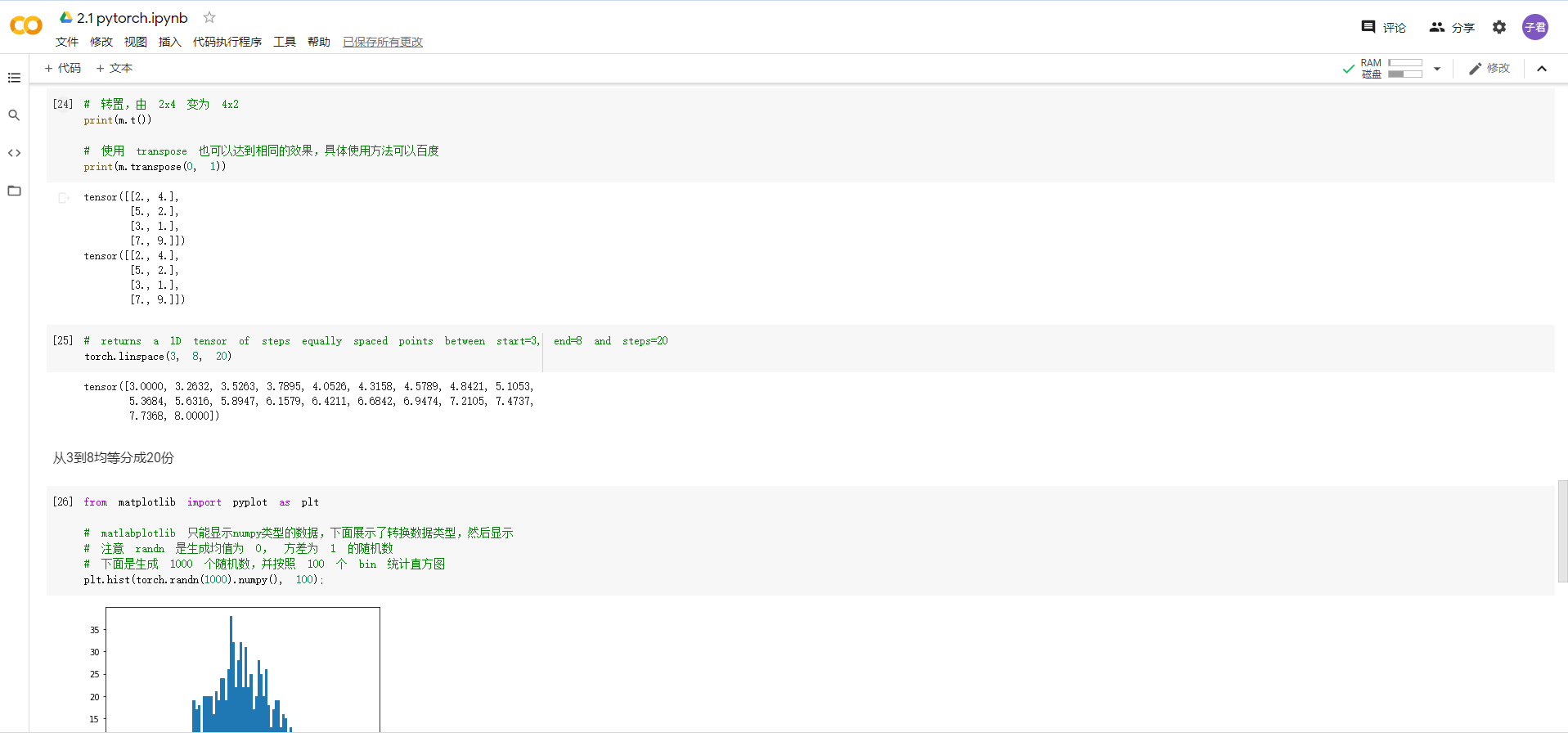
*pytorch基础练习:*通过将代码和注释通读,并且全部运行测试后,对于数据的定义以及运算操作的定义有了初步的了解。不过torch.的方法有很多,这一个小测试并不能全部了解,希望在以后的编写代码过程中能够逐步的揭开其他数据和操作定义的神秘面纱。
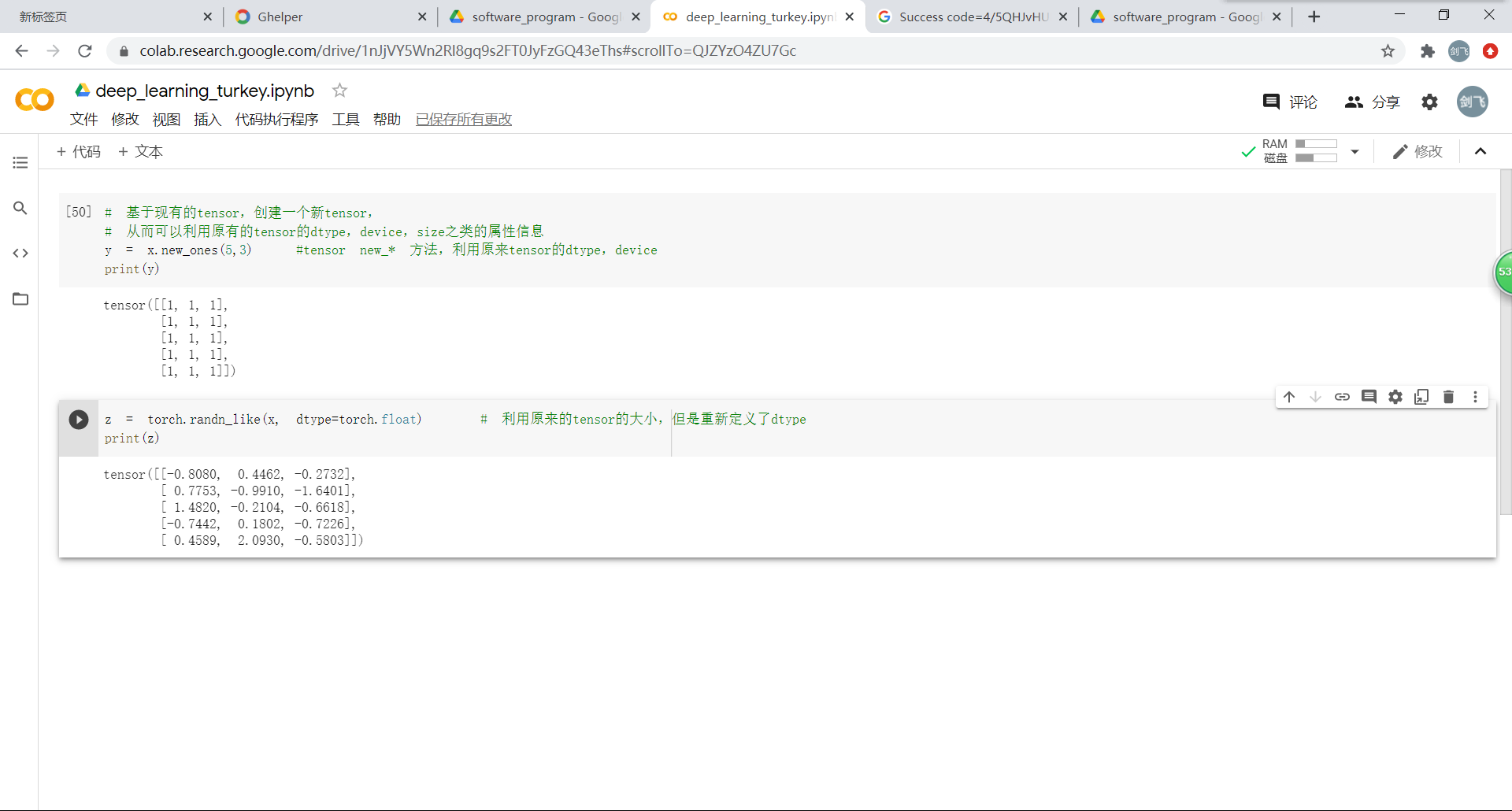


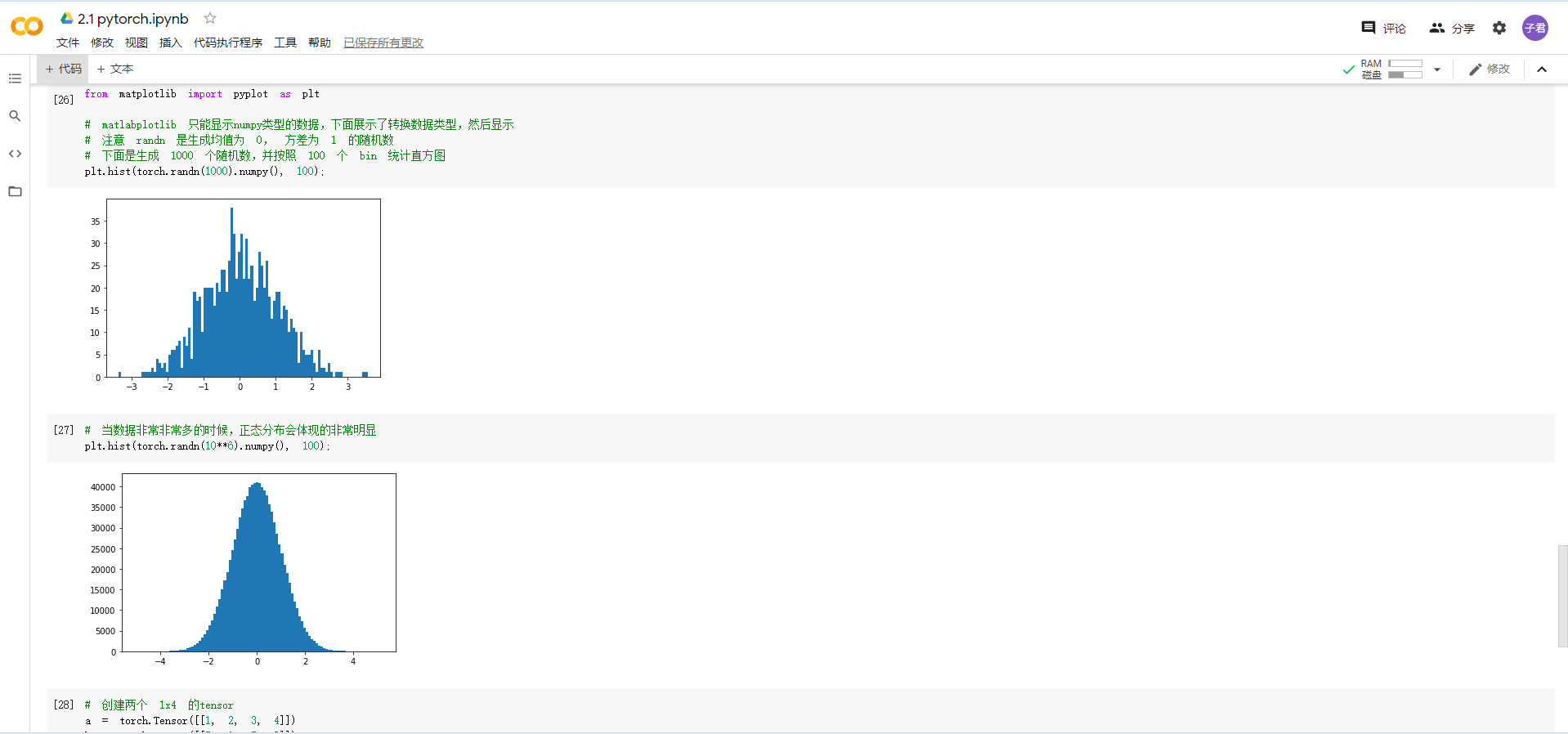
螺旋数据分类:听视频的时候,就觉得逐层与训练、反向传播和梯度消失很厉害,所幸也能够理解其概念和方法。但是当看到用pytorch写出来的代码时,果然发现了不懂pytorch语言带来的弊端——很大一部分核心代码只能靠自己的推测去判断含义。希望以后能够加深pytorch的理解和编写,最后顺利通过自己和团队的努力写出项目。
1.下载绘图函数到本地
2.初始化重要参数
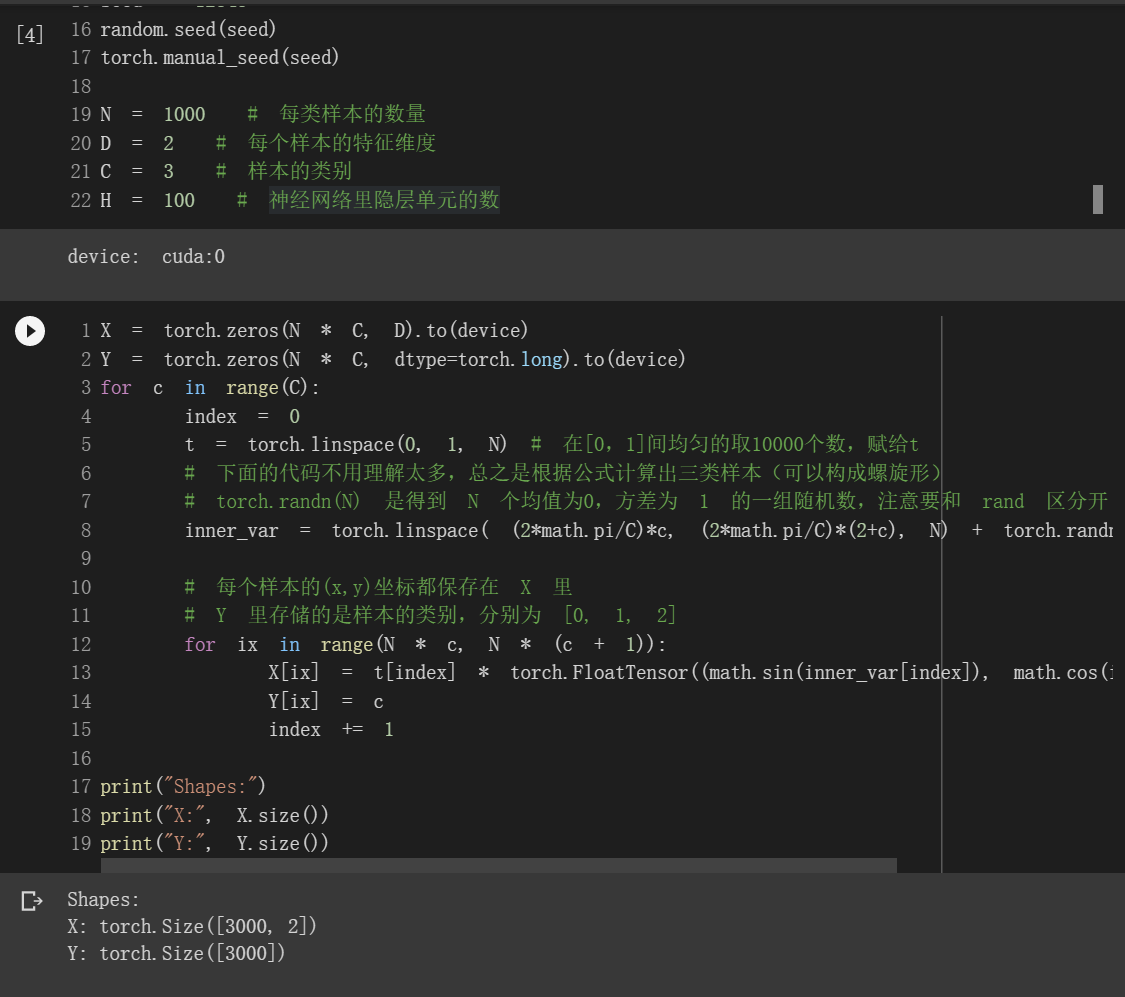
3.3000个样本的特征的初始化
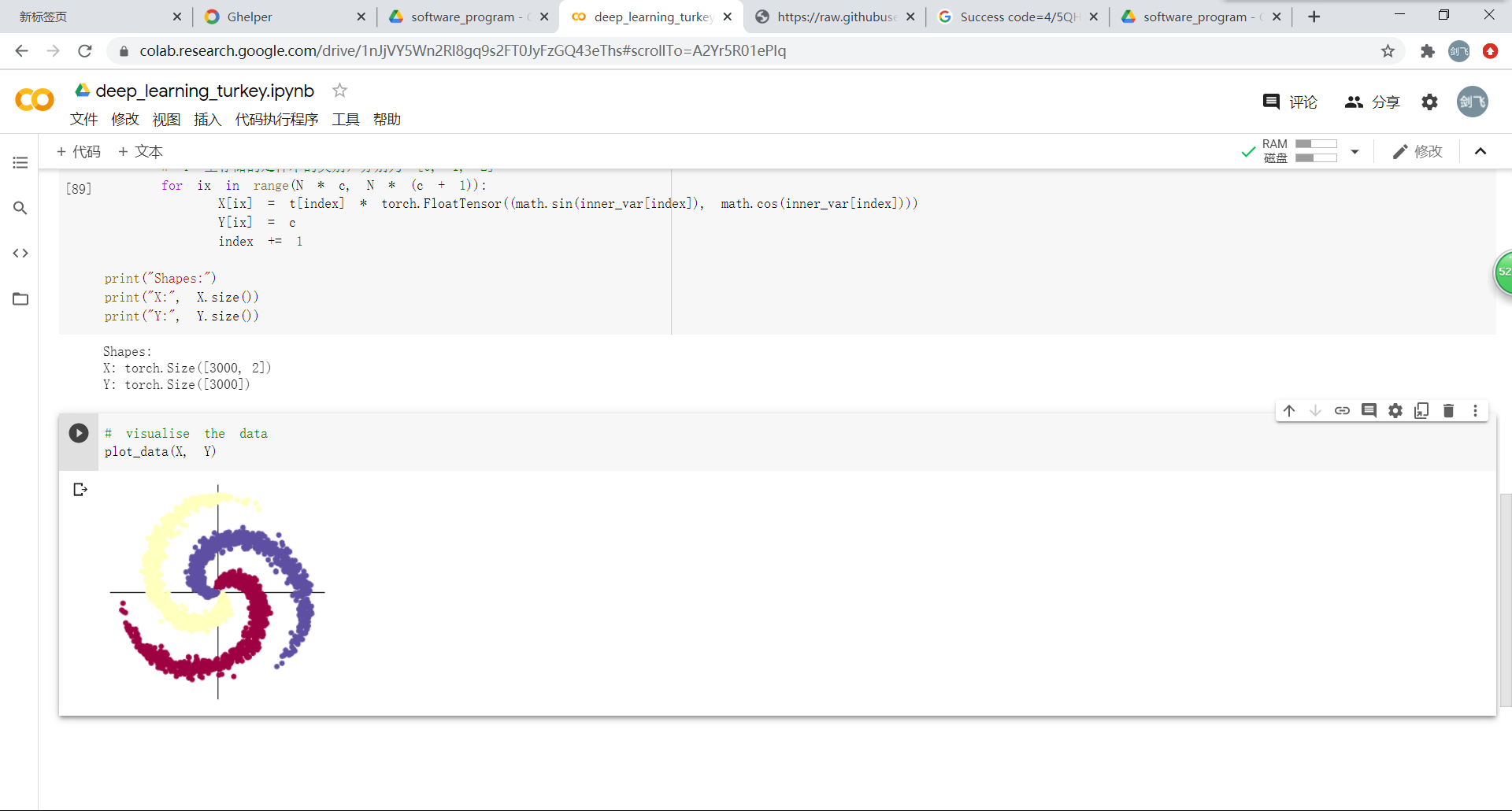
构建线性模型:使用到了损失函数、梯度下降优化、预训练和反向传播优化,但是分类效果并不理想。
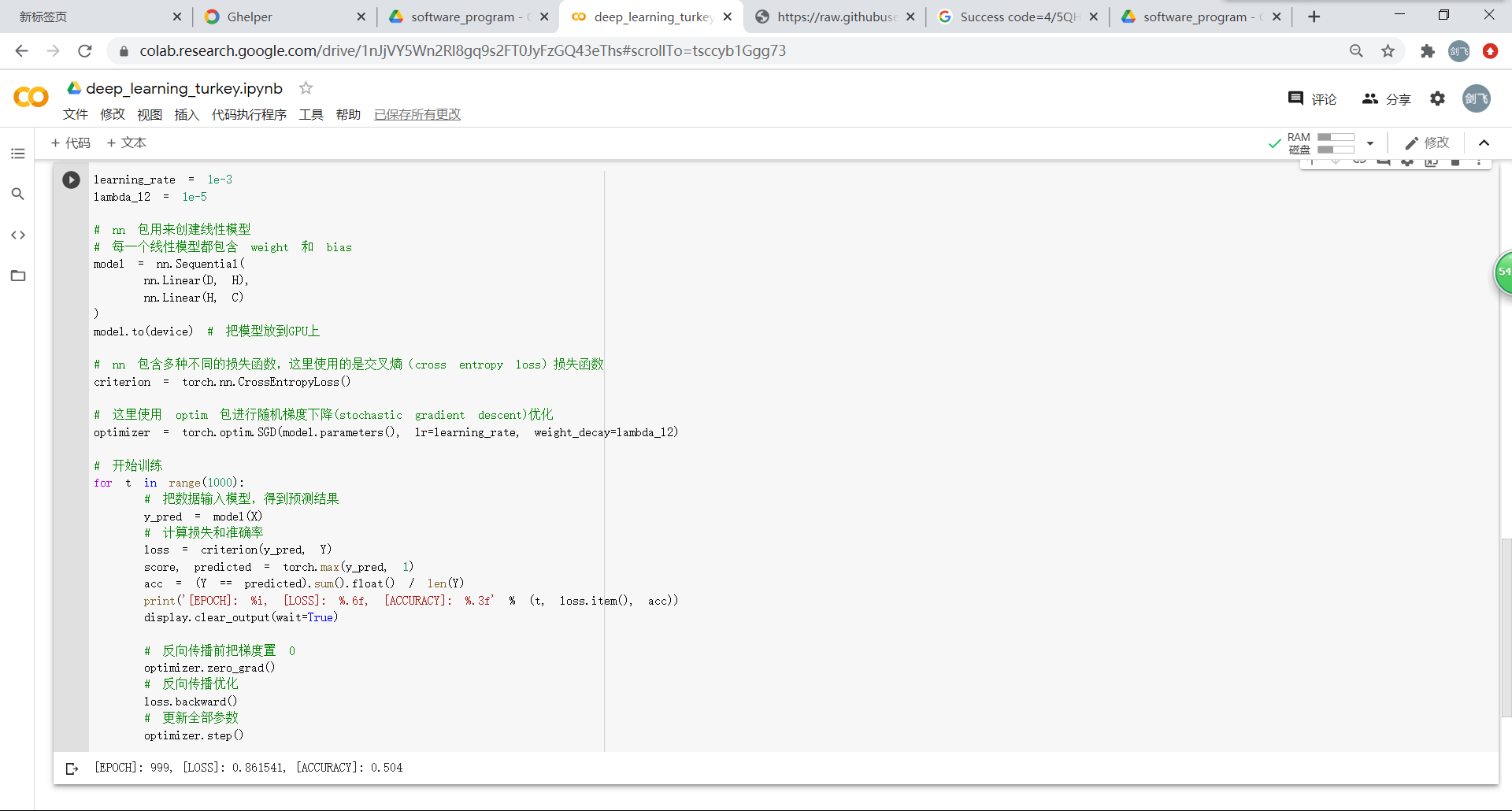
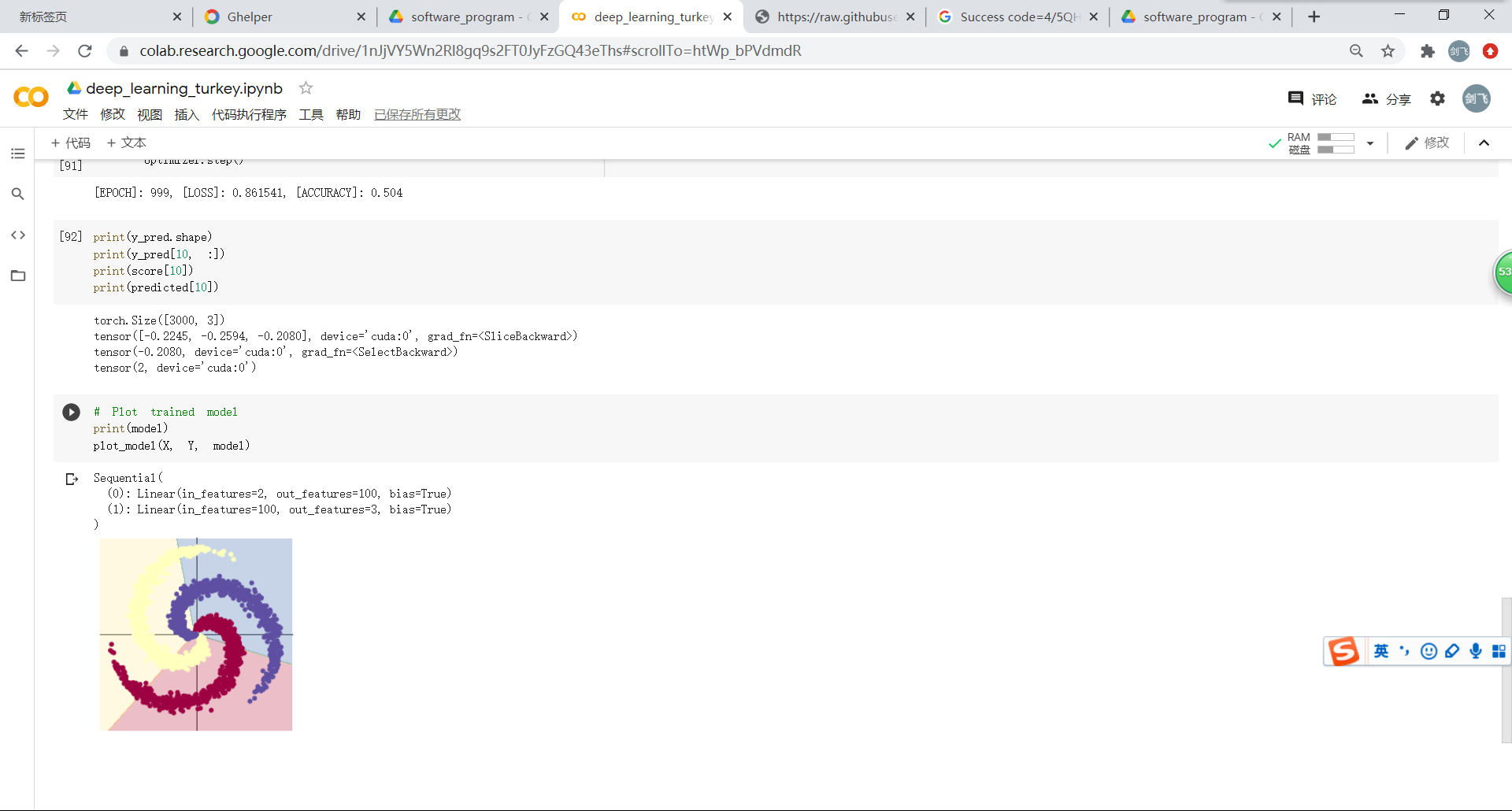
构建两层神经网络:在线性的基础上增加了ReLU函数激活。通过两图的对比能够很明显看出分类效果上的显著差别。

林思源:
PyTorch简单的操作:

螺旋数据分类(最终训练结果):

在PyTorch上进行基本操作比较容易实现,但是还不太理解底层运行的过程。
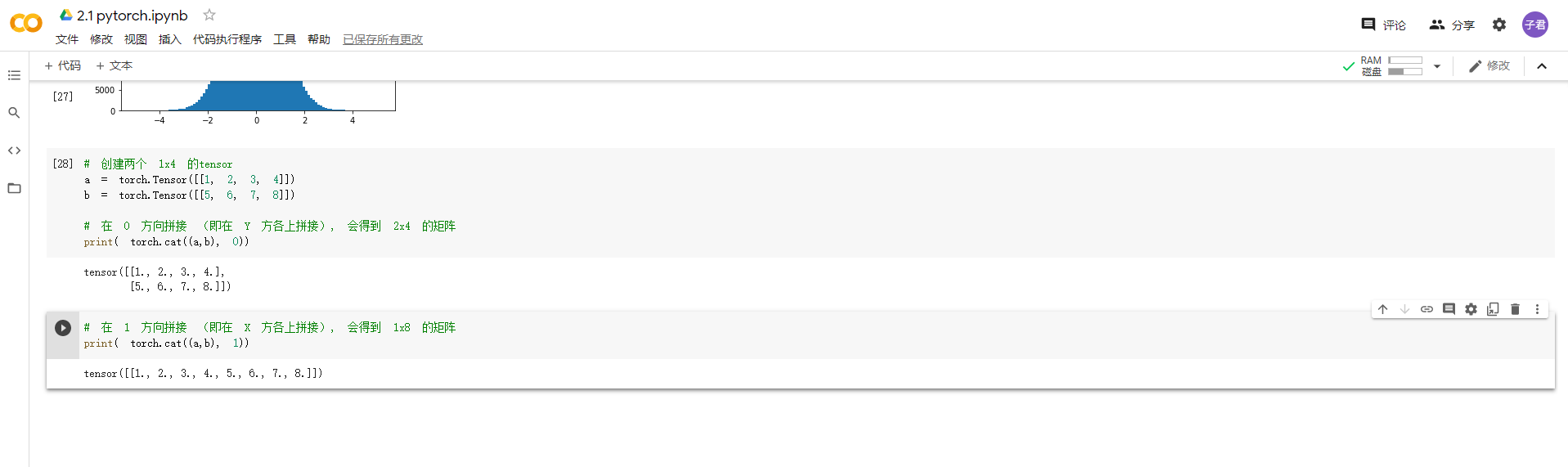
卢浩:1.定义数据

2.定义操作

m@v和下面一行的代码跑不出来,也不理解是什么意思
*Spiral classifciation*
能理解的部分
剩下的跟着把代码写上,能看懂汉语看不懂代码。汉语认识字不知道意思。
看了那个视频,感觉是机翻,字幕莫名其妙的,大概还是我汉语英语水平都不够,不过好在视频中有动图让人略微理解这个实验的实现方式
李瑞涛:1 PyTorch基础
1.1 定义数据
张量可以是其他高级语言中常见的类型
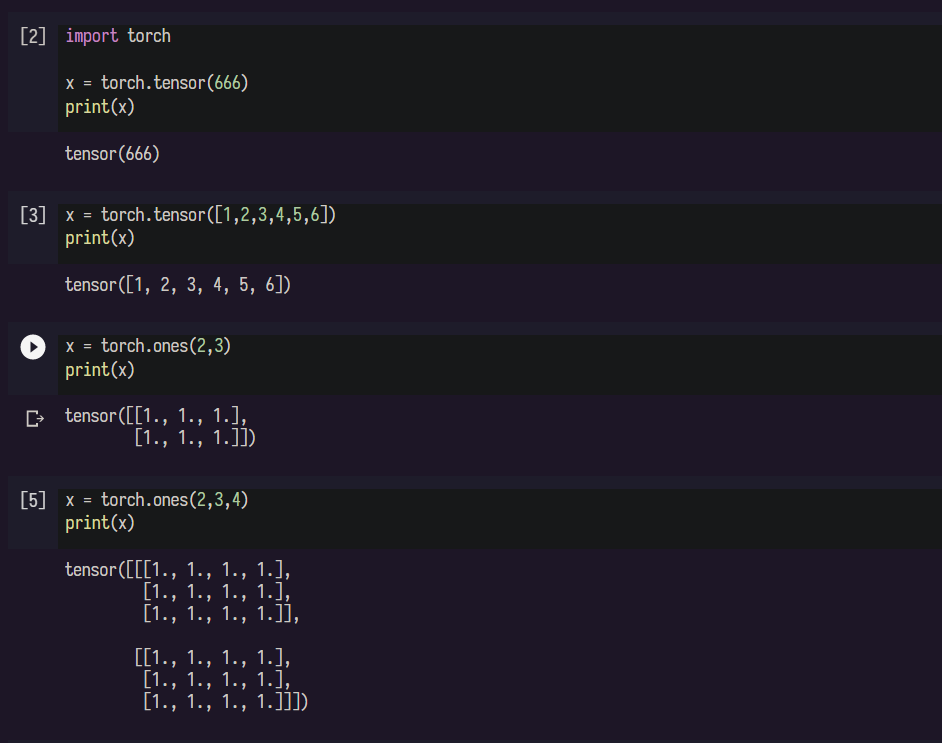
也有自己的特别用途
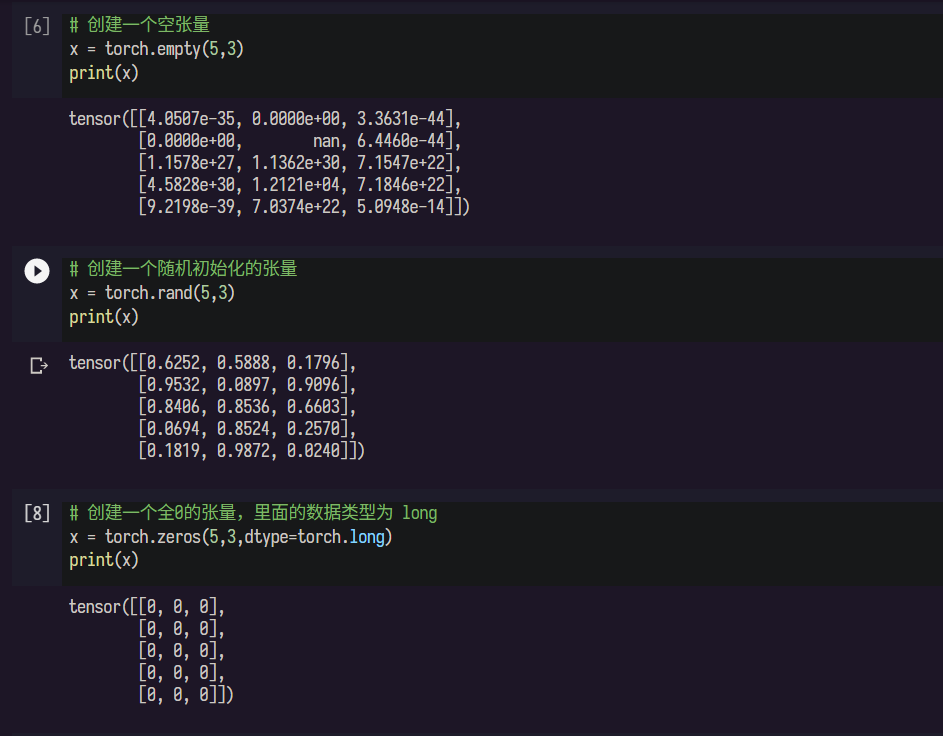
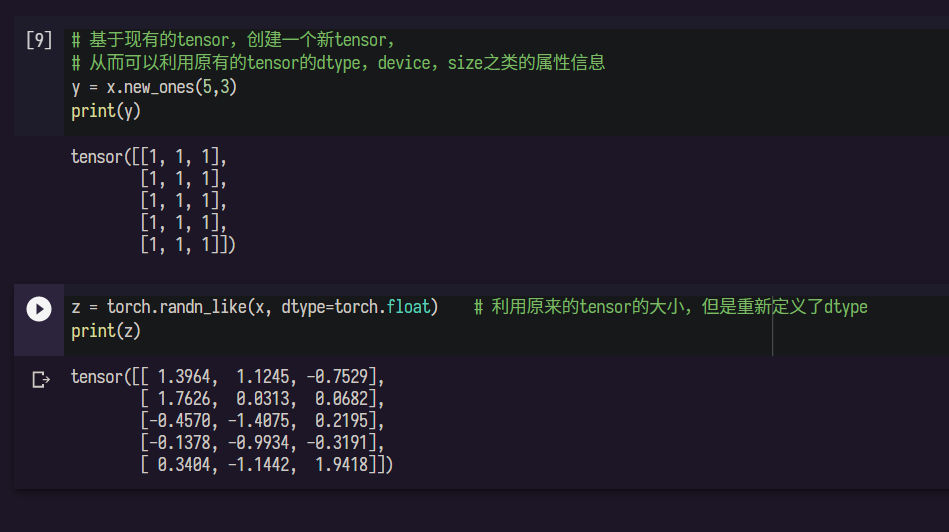
1.2 定义操作
可以对应其他高级语言中的函数、方法之类的东西。

这里按教程操作,在执行
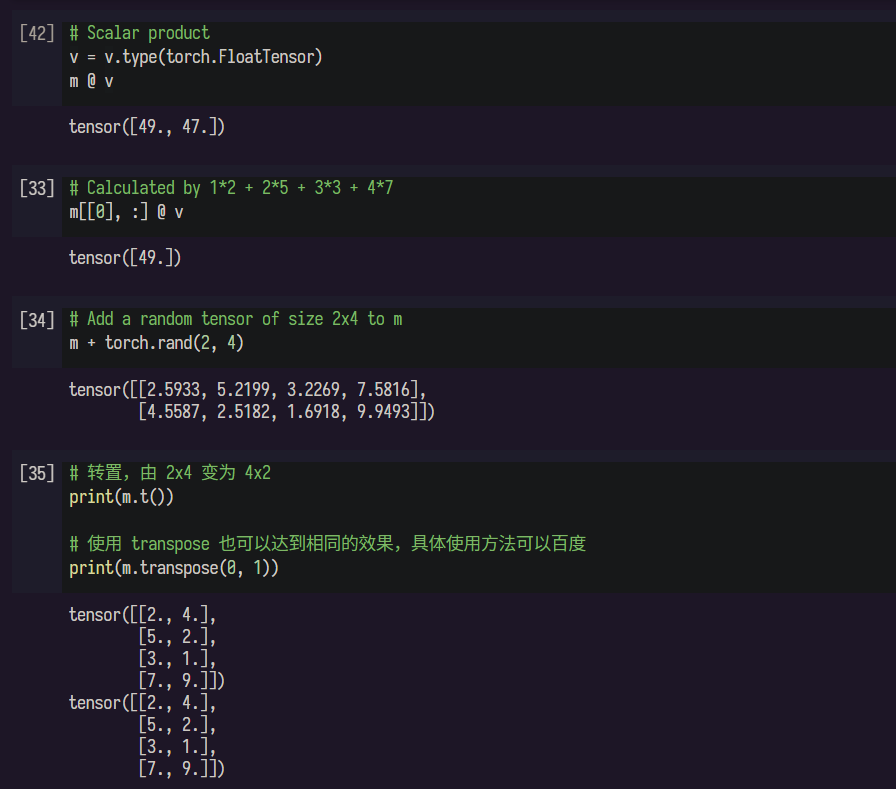
# Scalar product
m @ v
这一步时会出问题,提示RuntimeError: expected scalar type Float but found Long
包括后面用到v的地方基本都会出这一句。
解决方法也很简单,提示需要float类型,将v转换成float类型即可。
# Scalar product
v = v.type(torch.FloatTensor)
m @ v
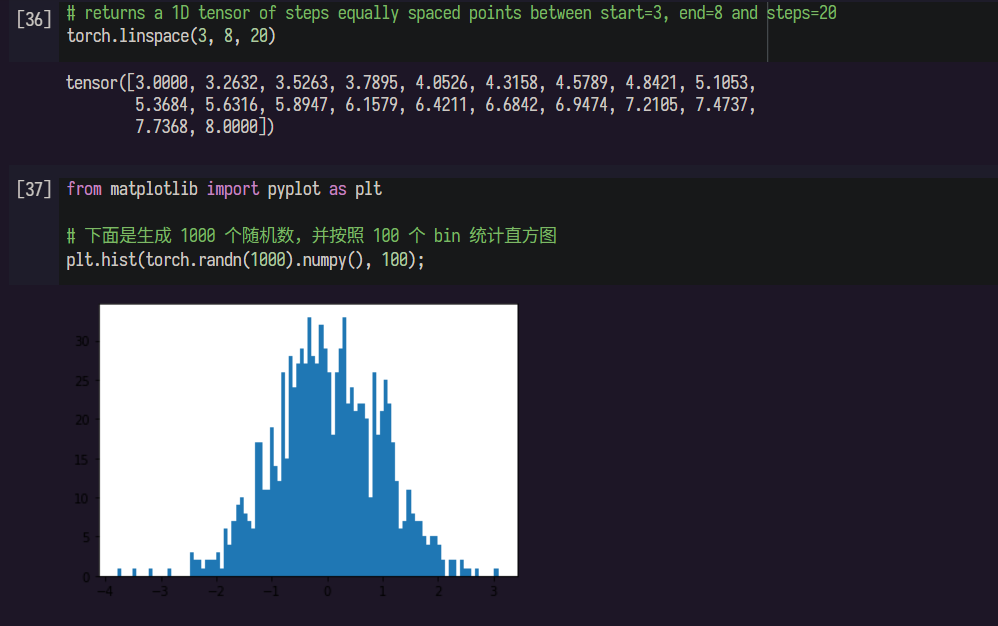
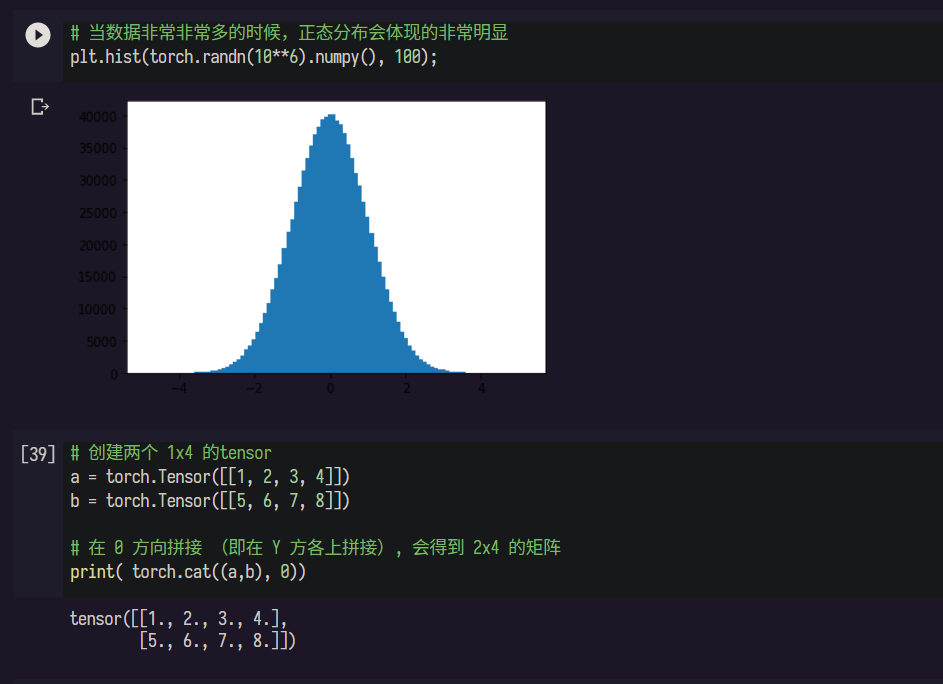

2 螺旋数据分类
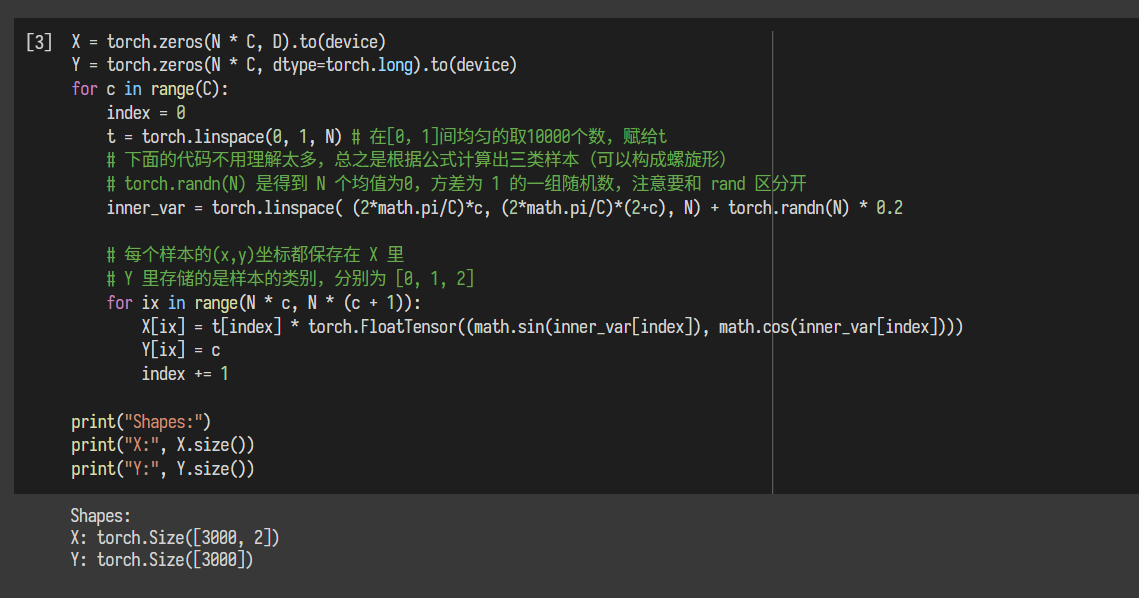

2.1 构建线性模型分类
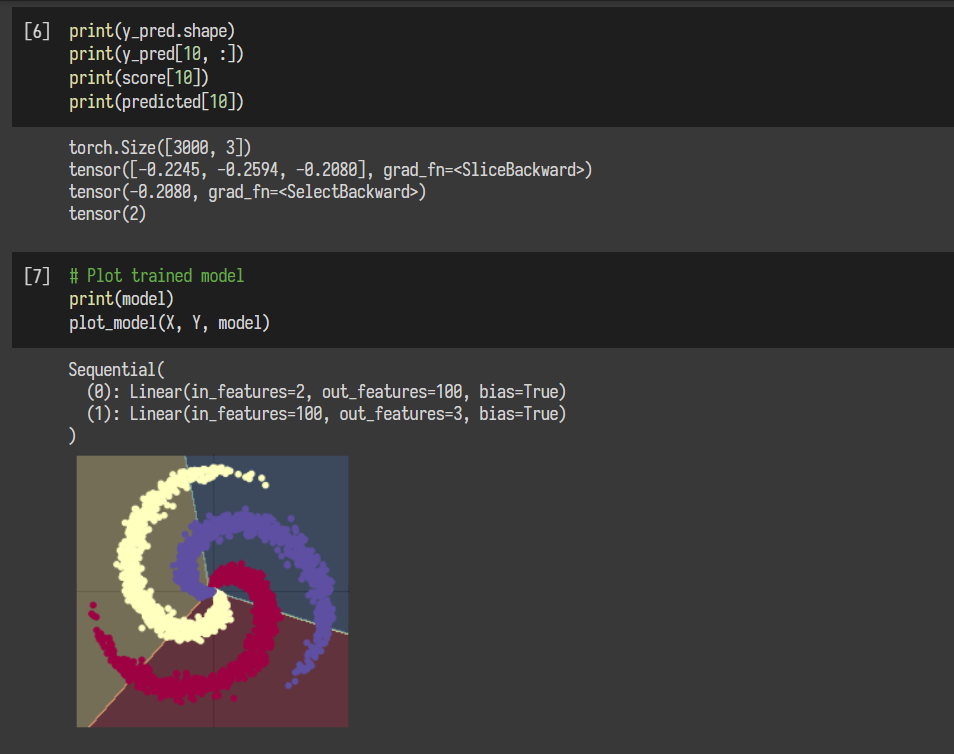
2.2构建两层神经网络分类
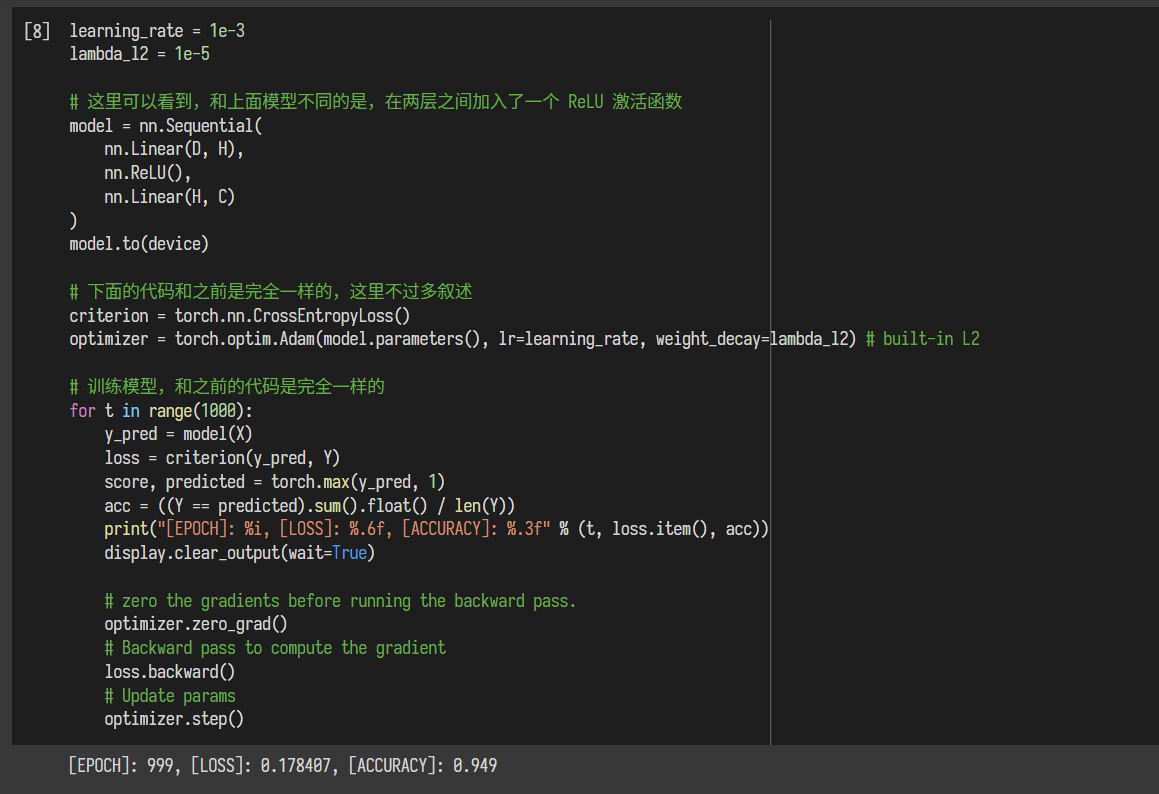
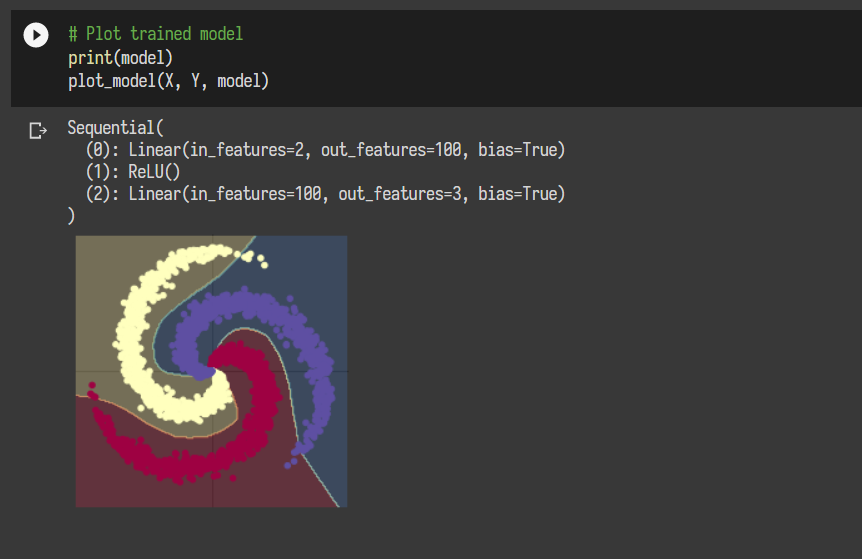
使用两层神经网络后,精度提高了,这也是说明一个神经网络的深度比宽度更重要,特别是在处理一些分布复杂的数据时,使用更深的神经网络可以提高其准确率。
蔺一迪:1 Pytorch基础练习
1)定义数据
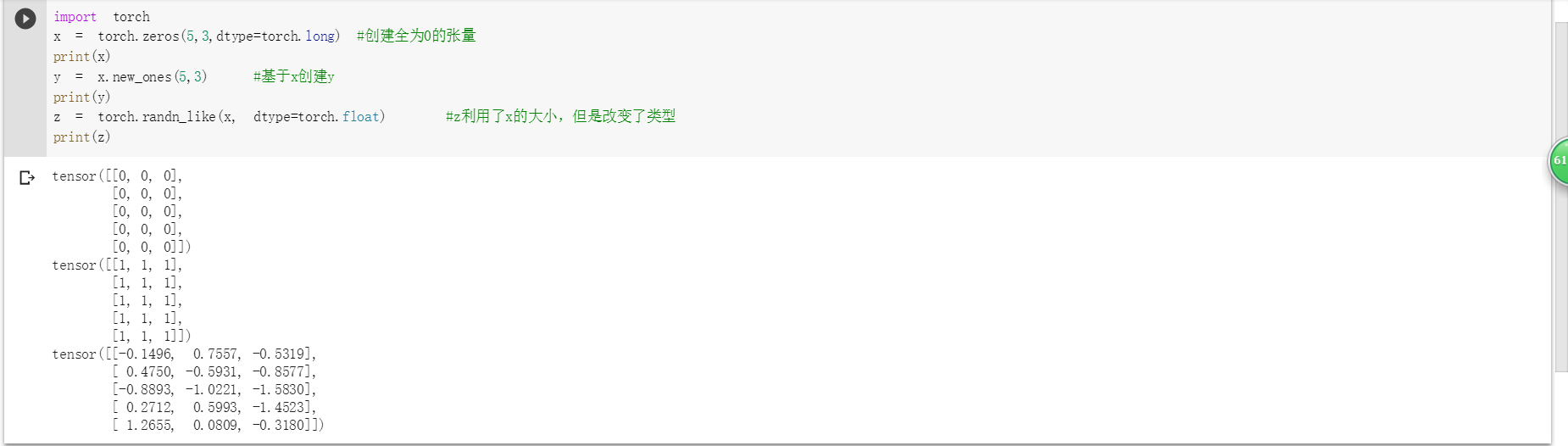
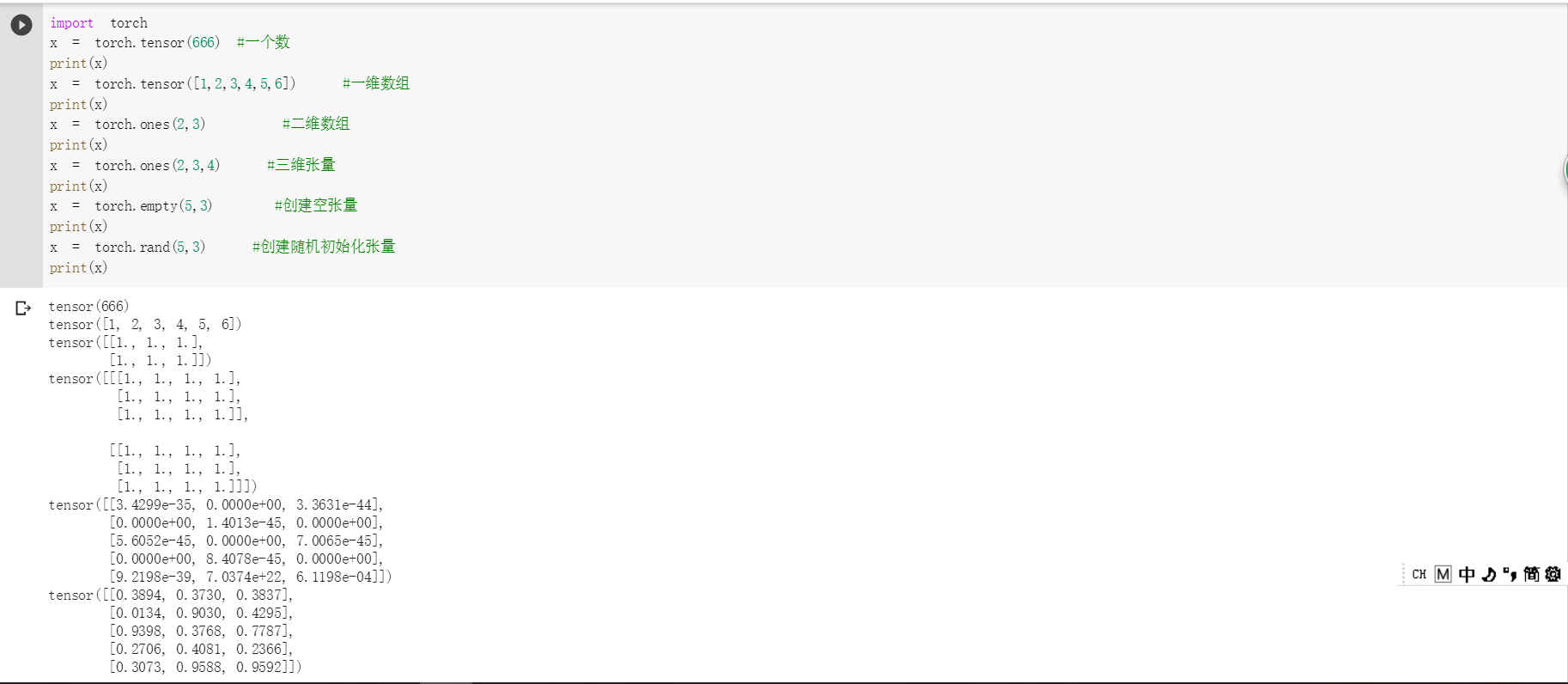
2)定义操作
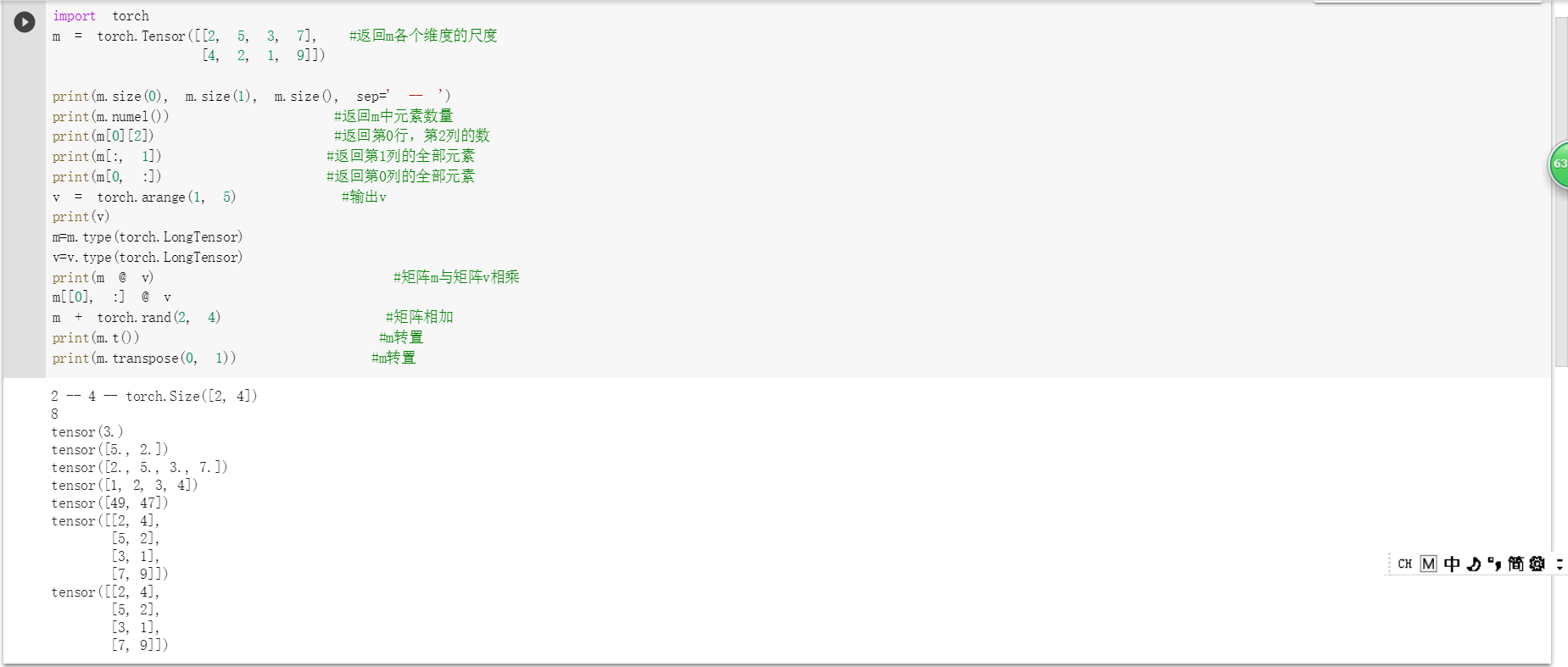

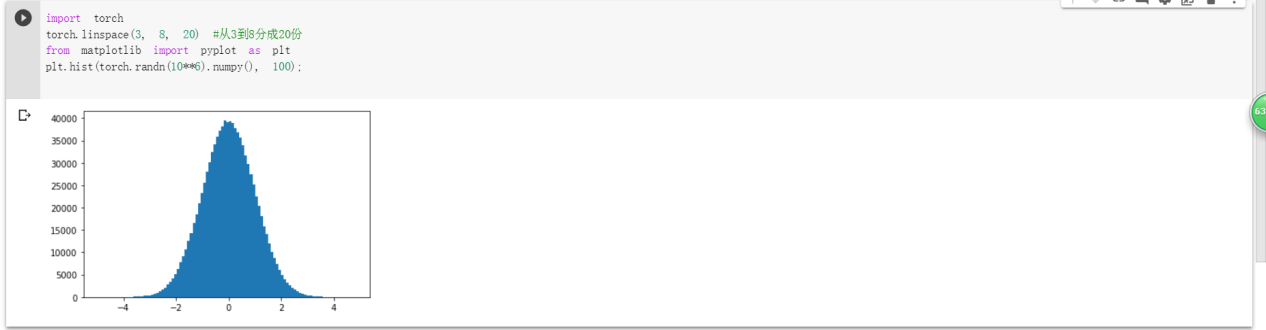
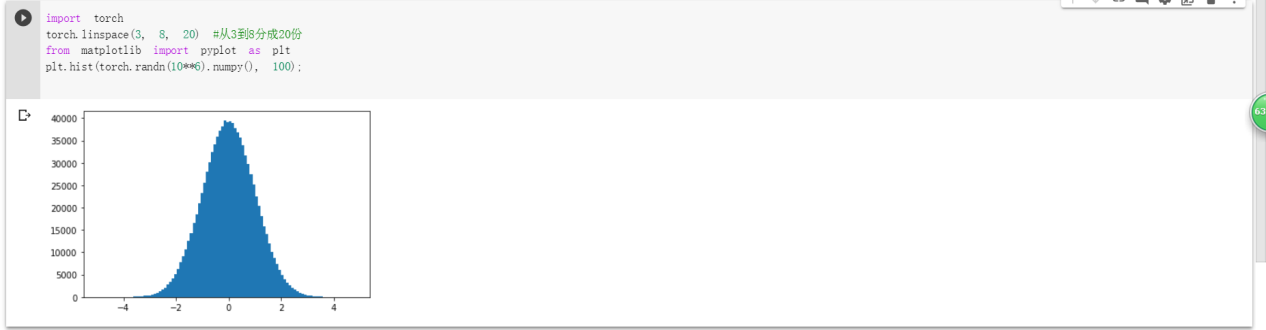
解释均在截图中
2 螺旋数据分类

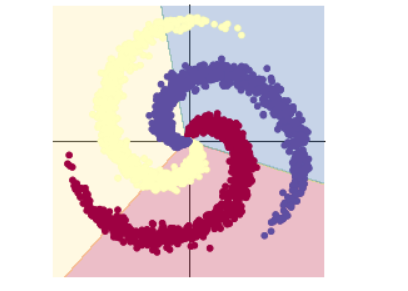
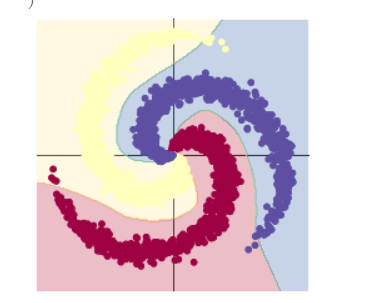
步骤如下:
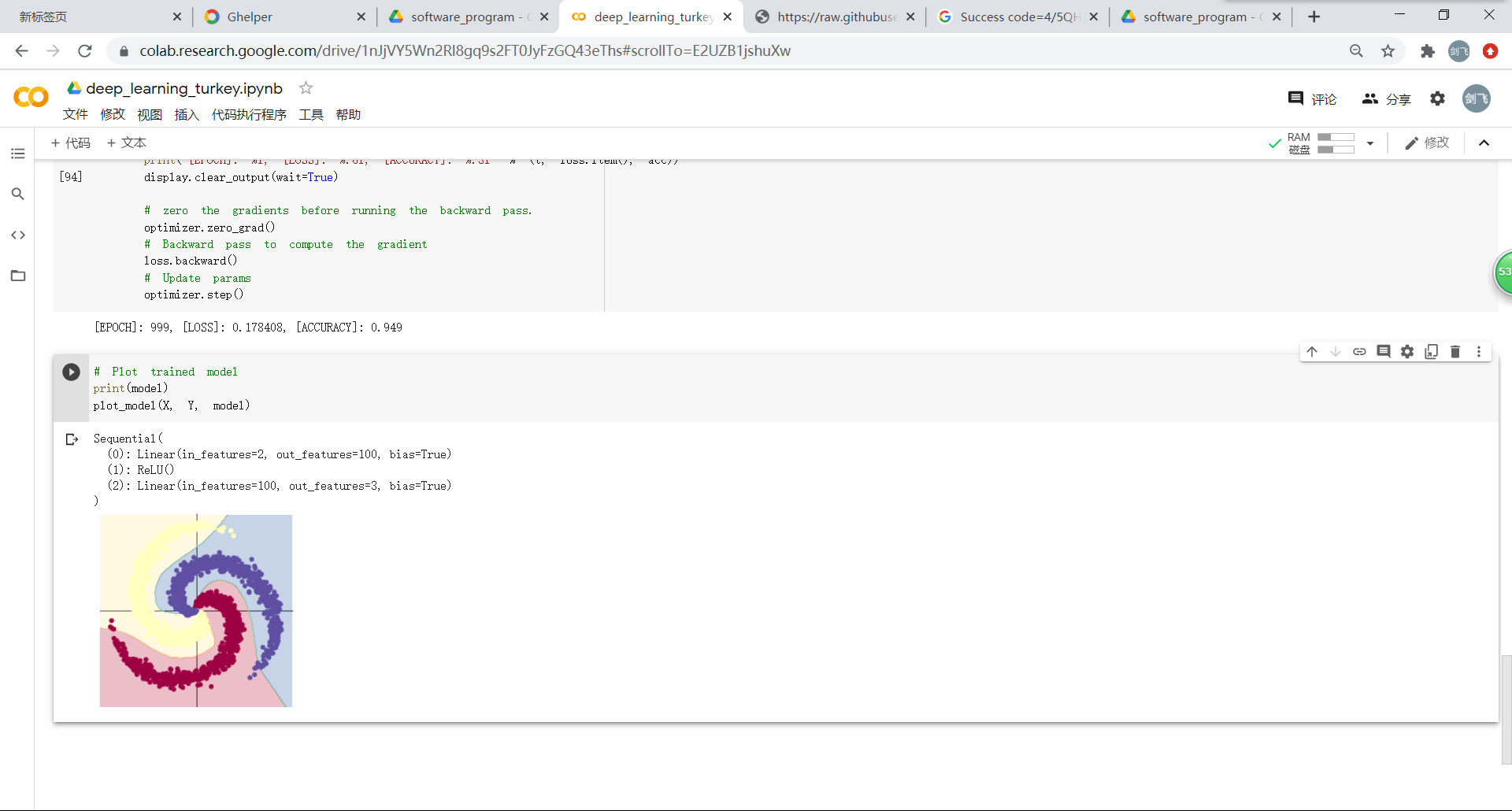
1 将数据输入model模型中
这里采用两层线性模型,并在中间添加ReLU函数,将线性模型转变为非线性模型。从所给的例子也可以看出,加上ReLu后,分类的准确率也得到了准确提高。
model = nn.Sequential(
nn.Linear(D, H),
nn.ReLU(),
nn.Linear(H, C)
)
2 计算损失loss和准确率
这里的loss是cross entropy loss损失函数
criterion = torch.nn.CrossEntropyLoss()
3 反向传播优化
这里通过loss.backward()更新weight从而实现loss的最小化,利用梯度下降w’=w-w*梯度,从而找到损失函数loss最小的参数,达到模型优化
收获
1 初始化参数都是随机的,所以在初始化参数之前,我们需要初始化随机数种子
2 在每一次反向传播前,都要将梯度清零,因为pytorch默认会对梯度进行累加,上一次反向传播结果会对下一次反向传播结果造成影响,因此需要清零。
3 激活函数的作用是很大的,不同情况下也可使用不同激活函数