| 这个作业属于哪个课程 | 软件工程实践 |
|---|---|
| 这个作业要求在哪里 | 疫情统计可视化(实现) |
| 结对学号 | 221701309,221701403 |
| 这个作业的目标 | 实现疫情地图可视化,详细省份折线图 |
| 作业正文 | 正文如下 |
| 其他参考文献 | ... |
一、Github仓库地址和代码规范链接
1.github仓库地址
https://github.com/qiuyanHuang/InfectStatisticWeb
2.代码规范链接
https://github.com/qiuyanHuang/InfectStatisticWeb/blob/master/README.md
二、成品展示
1.全国疫情地图实现
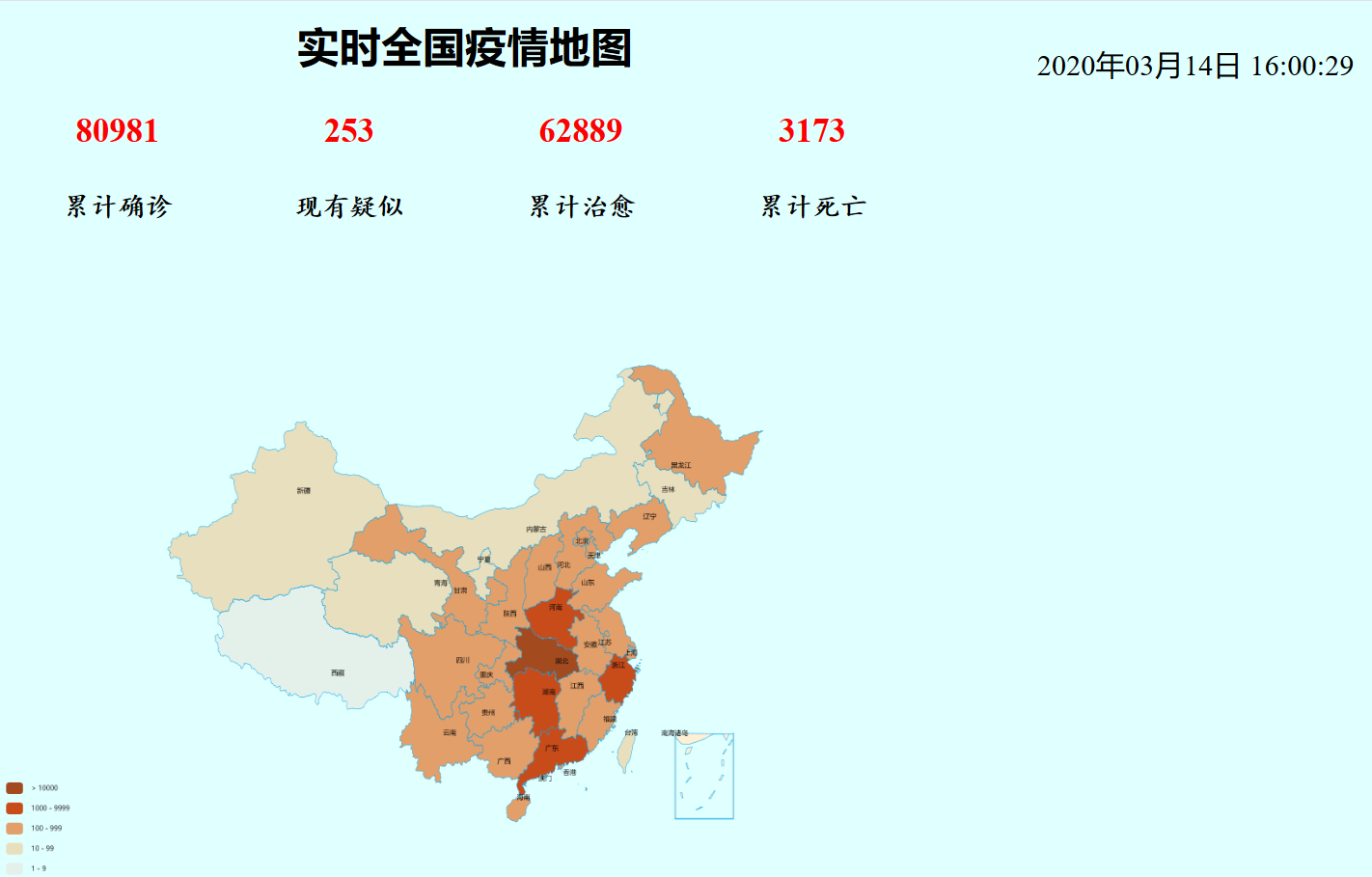
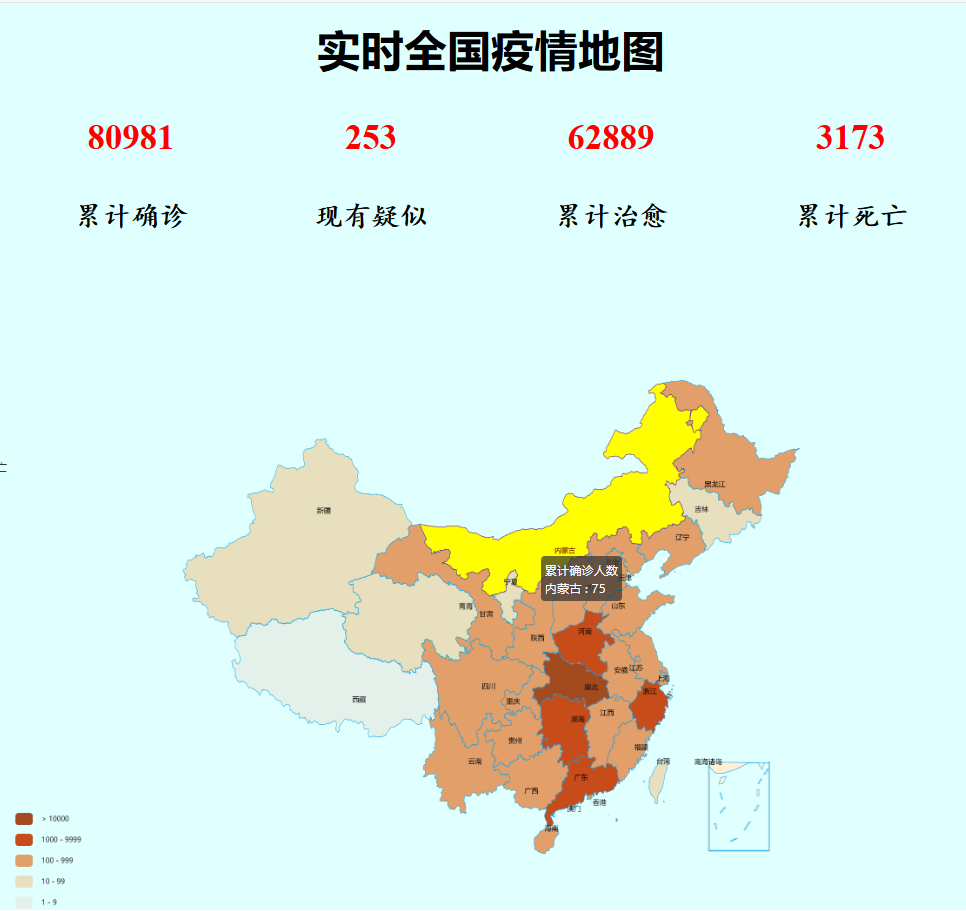
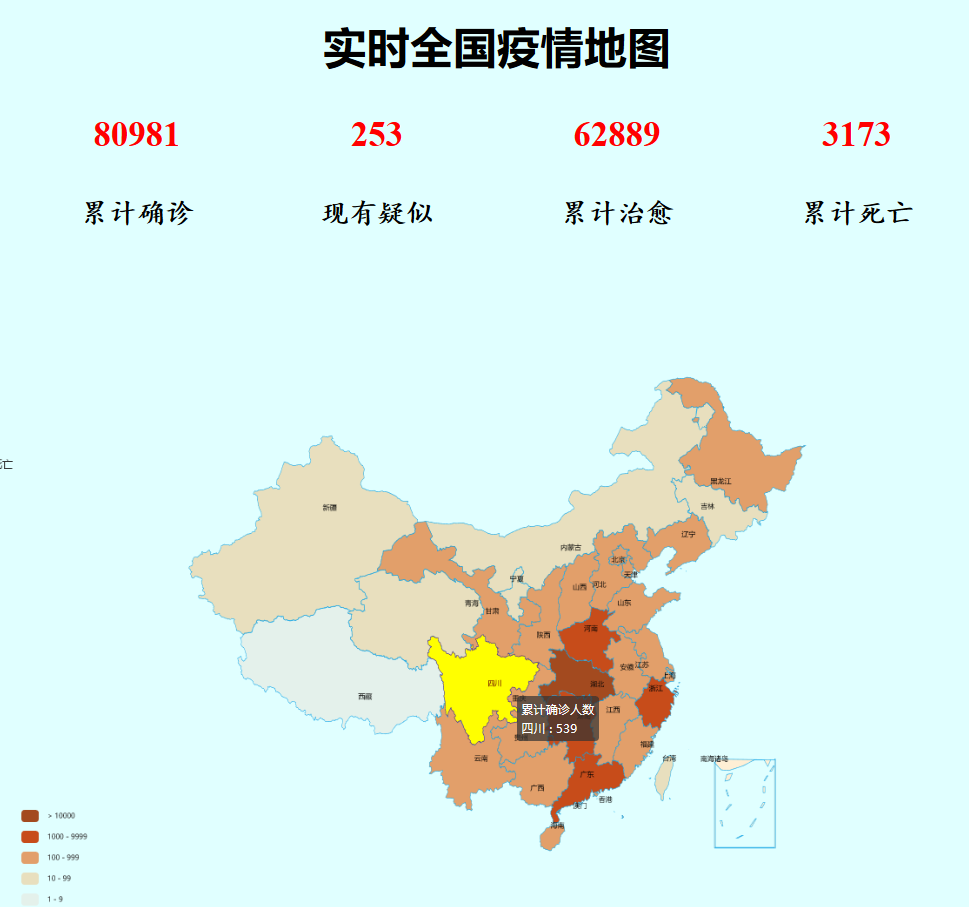
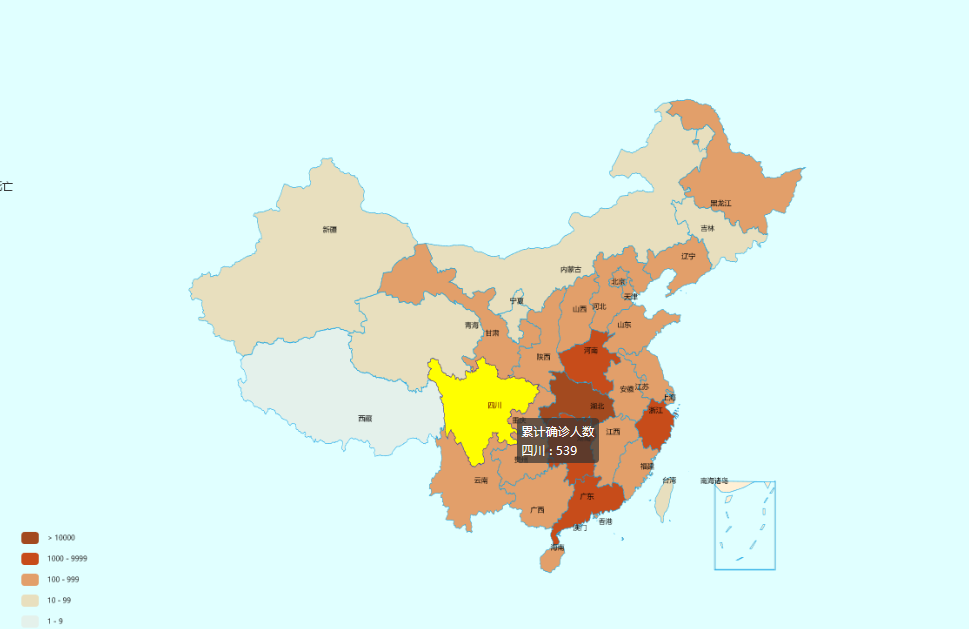
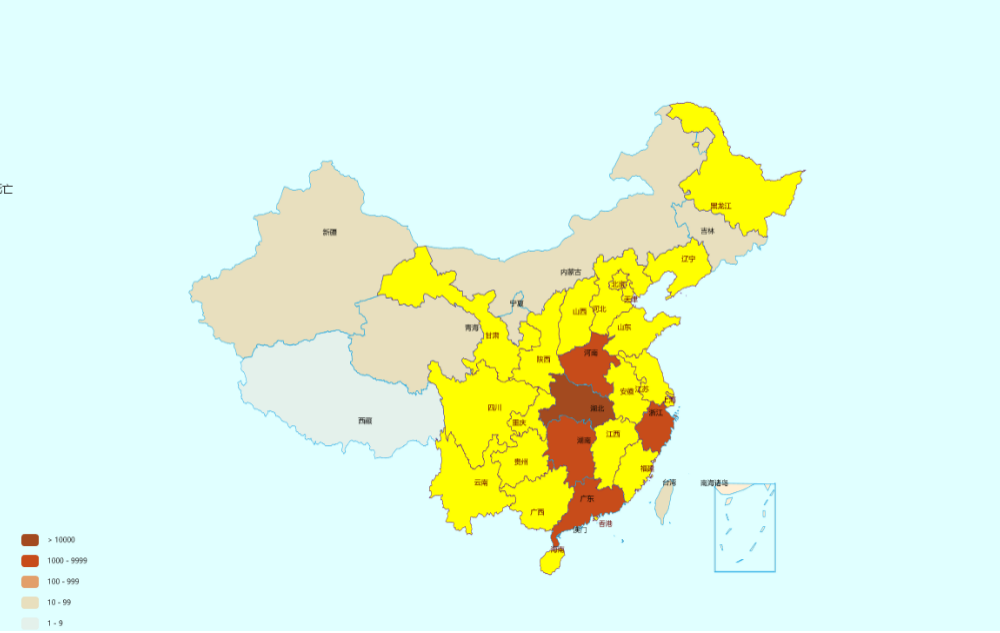
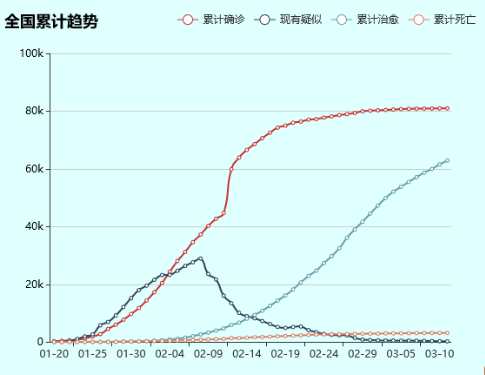
2.(扩展功能)全国累计确诊趋势折线图
三、结对讨论过程
- 初期
我们一起查阅各种学习资料,然后一起学习,我们在对资料进行解读时,产生了许多疑惑,然后我们会进行语音通话来共同探讨,直至找到较为优秀的解决方法。(由于现在还是未开学,因此我与队友之间依然只能通过各种社交软件来沟通交流。)其实我与队友开发技术与代码掌握都比较薄弱,web开发技术中比较熟悉的,也就html了。这次任务中所需要的大部分工具、语言都是我们从未接触过的,如果说这次的作业是座大山,那么我们就是连工具都没有就想要挪开这座山的人。
在语言和工具的选择上,一方面我们享用原本熟悉的C++或JAVA,另一方面,经过网上资料的查证表明python处理起来会方便一些,但是我们并没有深入了解过这门语言。经过抉择,我们最终选择了python进行开发,尽管面对一门新的语言会有困难,但是只要愿意付出总会有收获。接着我们又在前辈的博客园和各种资料中摸索到flask这一用python编写的web应用框架和echarts这样一个非常好用的可视化前端框架。(其实,在确定使用flask框架之前我们还走了不少弯路,最开始用的是Django重量级框架,但是在学习过程中遇到了一些困难,最后只好另辟蹊径选择flask轻量级框架)

- 中期
经过前期的学习,我们终于有了挪山的工具了!正式开工!但是,我们对这些工具运用的不太熟练(在开发过程中我们还一直不断地查找各种资料),在遇到无数个BUG,在无数次陷入绝望后,在一次次相互帮助和鼓励后,我们终于写出了一个大概模型。
我们的开发计划是先用爬虫爬取数据存入数据库,然后再在flask框架下进行web前端开发,最后写博客。
终于,在deadline截止的前一天,我们的功能一(疫情地图)终于出炉了。我们有尝试更进一步的功能实现,但由于时间问题,很遗憾我们暂且只能做这么多了。(后续期待我们会在进一步学习之后利用课余空闲时间一起去实现完整的功能)
- 后期
最后就是撰写博客。我们对自己这次任务的完成情况都不是很满意,因此在撰写博客的时候我们特意语音通话一起反思,交流自己的想法以及对彼此的建议。虽然这次我们做的不够好,但这会是我们的一次经验,相信我们会更好的!

四、实现过程
1.使用的语言:我们选择了python作为开发语言。python作为一种面向对象的解释型语言,对于web开发和网络爬虫非常适用。而且经过多数资料的查询,我们发现在疫情可视化这方面前辈们都喜欢用python进行开发,这大大增加了我们的信心。任务中网络爬虫和数据的整理汇总主要是由python代码来实现的。
2.使用的框架:由于本次需要将代码与网络接口对接,因此网络框架是必不可少
的。我们在各种框架中,最后选定了flask。Flask是一个用python编写的web应用框架,较其他同类型框架更是灵活轻便,安全且易上手。flask将用户与URL用视图函数连接起来,大大减少了工作量。
3.使用的工具:除了python语言和前端的IDE,还用了一个特殊的工具——echarts。echarts作为一个纯JavaScript的图表库,用它来进行数据的可视化,以及各种丰富的交互功能。
(附思维导图式的功能结构图)
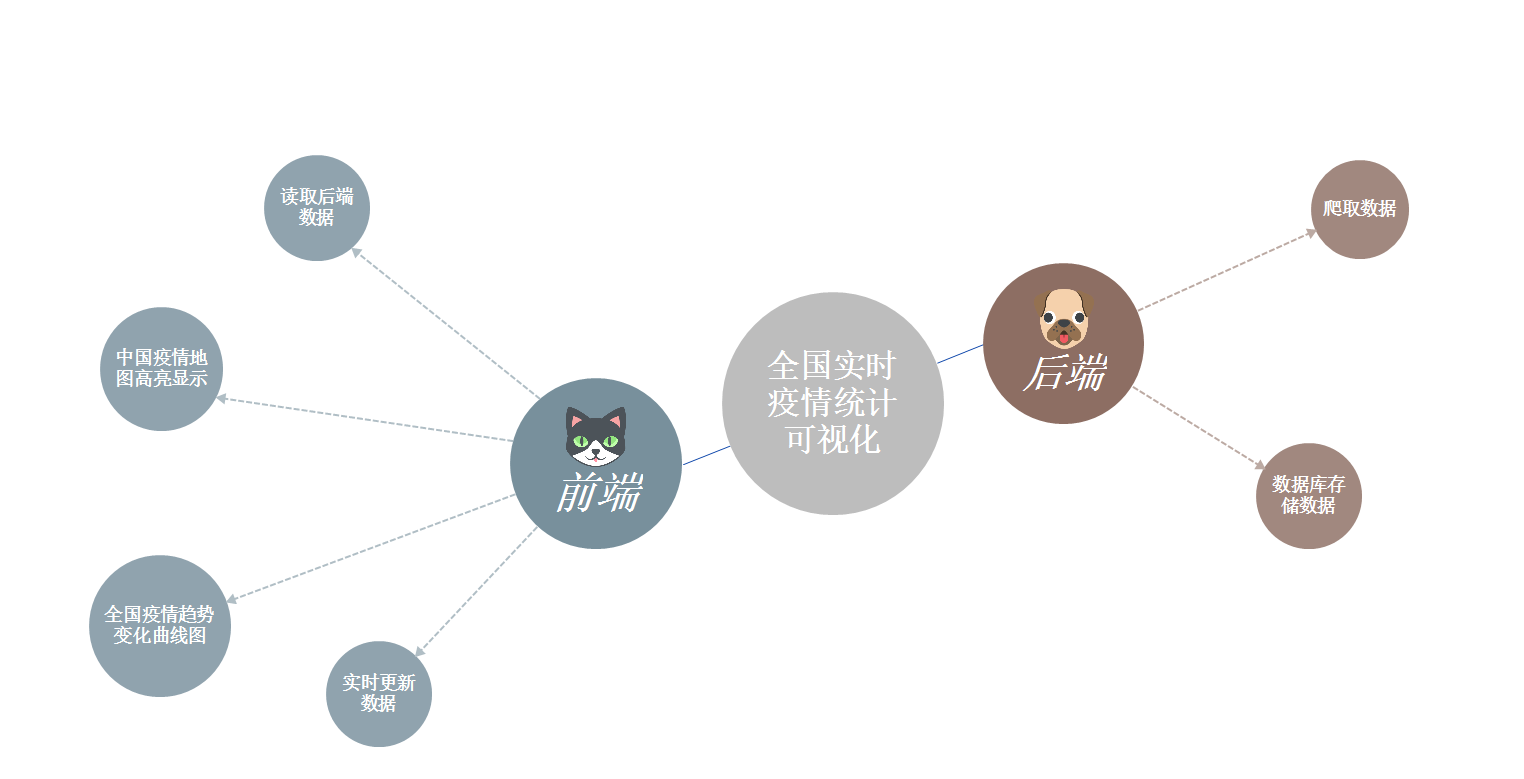
五、代码说明
1.爬虫获取网上实时数据
def get_tencent_data():
# 爬虫获取并处理数据
# 返回历史数据和当日详细数据
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5'
url1 = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_other'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
}
r = requests.get(url, headers)
r1= requests.get(url1, headers)
res = json.loads(r.text) # json字符串转字典
res1 = json.loads(r1.text)
data_all = json.loads(res['data'])
data_all1 = json.loads(res1['data'])
# 获取历史记录
history = {} # 历史记录
for i in data_all1["chinaDayList"]:
ds = "2020." + i["date"]
tup = time.strptime(ds,"%Y.%m.%d")
ds = time.strftime("%Y-%m-%d",tup) # 改变时间格式,不然插入数据库会报错,数据库是datetime类型
confirm = i["confirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
history[ds] = {"confirm": confirm, "suspect": suspect, "heal": heal, "dead": dead}
for i in data_all1["chinaDayAddList"]:
ds = "2020." + i["date"]
tup = time.strptime(ds, "%Y.%m.%d")
ds = time.strftime("%Y-%m-%d", tup) # 改变时间格式,不然插入数据库会报错,数据库是datetime类型
confirm = i["confirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
history[ds].update({"confirm_add": confirm, "suspect_add": suspect, "heal_add": heal, "dead_add": dead})
# 获取当日详细数据
details = [] # 当日详细数据
update_time = data_all["lastUpdateTime"]
data_country = data_all["areaTree"] # list25个国家
data_province = data_country[0]["children"] # 中国各省
for pro_infos in data_province:
province = pro_infos["name"] # 省名
for city_infos in pro_infos["children"]:
city = city_infos["name"]
confirm = city_infos["total"]["confirm"]
confirm_add = city_infos["today"]["confirm"]
heal = city_infos["total"]["heal"]
dead = city_infos["total"]["dead"]
details.append([update_time, province, city, confirm, confirm_add, heal, dead])
return history,details
2.连接数据库,创建表
def get_conn():
# 建立连接
conn = pymysql.connect(host="localhost",
user="root",
password="123456",
db="epidemic",
charset="utf8")
# 创建游标
cursor = conn.cursor()
return conn,cursor
def close_conn(conn, cursor):
# 关闭连接
if cursor:
cursor.close()
if conn:
conn.close()
def query(sql,*args):
# 封装通用查询,返回查询结果
conn,cursor = get_conn()
cursor.execute(sql,args)
res = cursor.fetchall()
close_conn(conn,cursor)
return res
更新detail表
def update_details():
# 更新detail表
cursor = None
conn = None
try:
li = get_tencent_data()[1] # 0是历史数据字典,1是最新详细数据列表
conn,cursor = get_conn()
sql = "insert into details(update_time,province,city,confirm,confirm_add,heal,dead) values(%s,%s,%s,%s,%s,%s,%s)"
sql_query = 'select %s=(select update_time from details order by id desc limit 1)' # 对比当前最大时间戳
cursor.execute(sql_query,li[0][0])
if not cursor.fetchone()[0]:
print(f"{time.asctime()}开始更新最新数据")
for item in li:
cursor.execute(sql, item)
conn.commit()
print(f"{time.asctime()}更新最新数据完毕")
else:
print(f"{time.asctime()}已是最新数据!")
except:
traceback.print_exc()
finally:
close_conn(conn,cursor)
向history表中插入爬虫获取的数据
def insert_history():
# 插入历史数据
cursor = None
conn = None
try:
dic = get_tencent_data()[0] # 0是历史数据字典,1是最新详细数据列表
print(f"{time.asctime()}开始插入历史数据")
conn,cursor = get_conn()
sql = "insert into history values(%s,%s,%s,%s,%s,%s,%s,%s,%s)"
for k, v in dic.items():
cursor.execute(sql, [k, v.get("confirm"), v.get("confirm_add"), v.get("suspect"),
v.get("suspect_add"), v.get("heal"), v.get("heal_add"),
v.get("dead"), v.get("dead_add")])
conn.commit() # 提交事务
print(f"{time.asctime()}插入历史数据完毕")
except:
traceback.print_exc()
finally:
close_conn(conn, cursor)
更新history表
def update_history():
# 更新历史数据
cursor = None
conn = None
try:
dic = get_tencent_data()[0] # 0是历史数据字典,1是最新详细数据列表
print(f"{time.asctime()}开始更新历史数据")
conn,cursor = get_conn()
sql = "insert into history values(%s,%s,%s,%s,%s,%s,%s,%s,%s)"
sql_query = "select confirm history where ds=%s"
for k, v in dic.items():
if not cursor.execute(sql_query,k):
cursor.execute(sql, [k, v.get("confirm"), v.get("confirm_add"), v.get("suspect"),
v.get("suspect_add"), v.get("heal"), v.get("heal_add"),
v.get("dead"), v.get("dead_add")])
conn.commit() # 提交事务
print(f"{time.asctime()}历史数据更新完毕")
except:
traceback.print_exc()
finally:
close_conn(conn, cursor)
3.获取数据库中的数据,在前端显示
显示地图上方的关键数据
def get_centerA_data():
# 获取centerA实时数据
# 取时间戳最新的那组数据
sql = "select sum(confirm),"
"(select suspect from history order by ds desc limit 1),"
"sum(heal),"
"sum(dead) "
"from details "
"where update_time=(select update_time from details order by update_time desc limit 1) "
res = query(sql)
return res[0]
获取地图上各省的数据
def get_centerB_data():
# 获取map各省实时数据
# 取时间戳最新的那组数据
sql = "select province,sum(confirm) from details "
"where update_time=(select update_time from details "
"order by update_time desc limit 1) "
"group by province"
res = query(sql)
return res
获取累计确诊趋势折线图数据
def get_left_data():
# 全国累计数据折线图
sql = "select ds,confirm,suspect,heal,dead from history"
res = query(sql)
return res
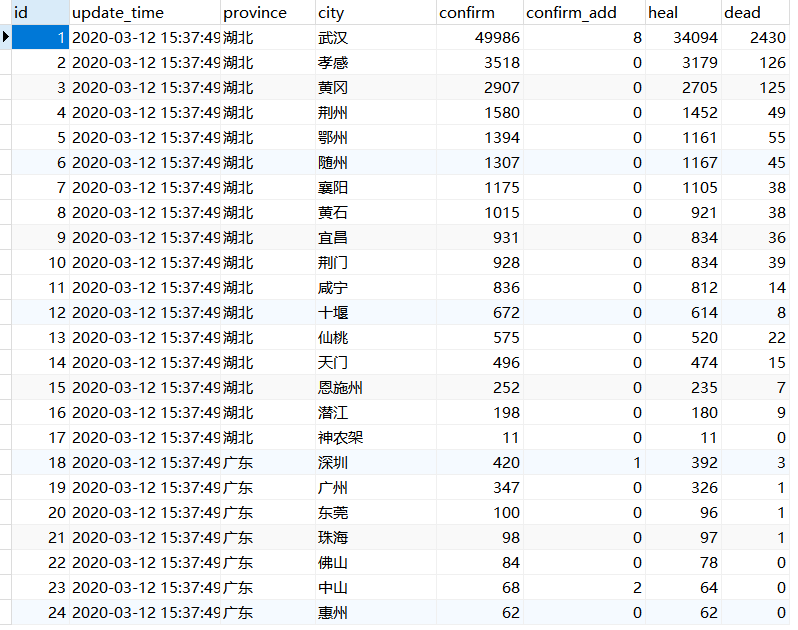
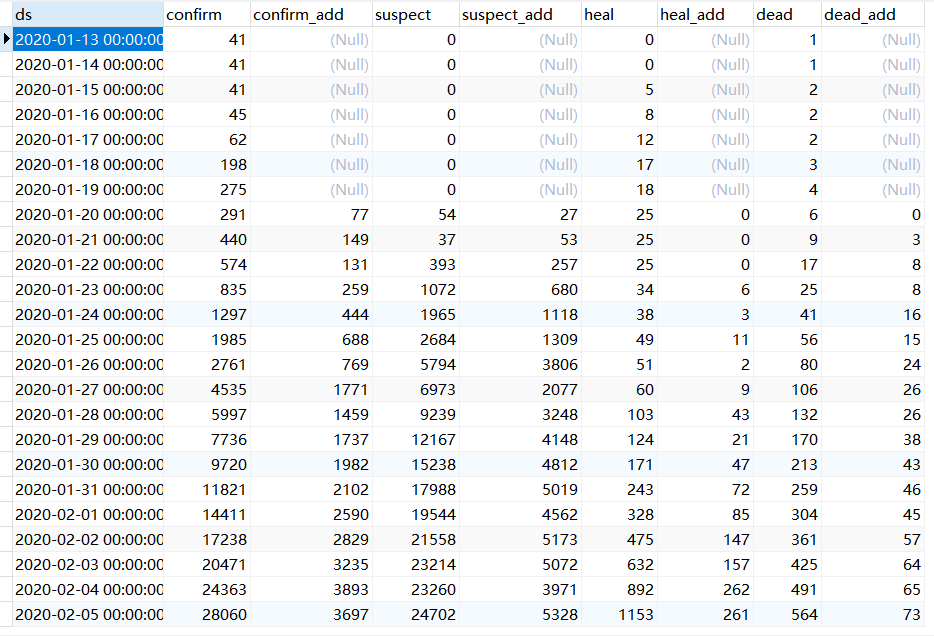
4.数据库
detail表
history表
六、开发项目的心路历程与收获,并评价结对队友
1.心路历程与收获
221701309:如果把我的心路历程看成是心电图的话,那一定是一条直线(卒)——从一开始就没有生命迹象!从设计疫情可视化的原型开始,我就开始害怕和担忧疫情可视化的实现(因为我似乎没有一件能拿得出手技能,我对于具体时间毫无头绪)。再到发布具体作业要求,deadline只有一星期的时候,我更是心慌和束手无策(一个星期的时间,我连懊悔自己什么都不会的机会都没有,就立马开始学习),在这一个星期里,我花了三分之二的时间在学习各种知识——python语言,爬虫,flask架构,数据库(之前掌握的不够熟悉)等等,而且因为自己的学习能力低下,哪怕自己抓紧一切时间学习,但是各种新知识都无法掌握透彻,无法应用自如。因此,在“一个星期”的压力之下,在队友的帮助下,我最后只完成了功能一地图部分数据的显示(日期部分也没有完成)。总体而言,这次的任务完成情况我自认为非常糟糕,若要说收获,那应该是满满的反省,通过这次作业,我深刻的认识到自己在专业领域与同专业的同学已经落后很多,脱离大队伍的感觉真的太可怕了!所以,未来,我会尽力去学习,让自己掌握更多的技能。最后,我想说,虽然我们这次任务完成的不够理想,但是,我们真的已经尽力了。
221701403:这次结队任务让我有机会去深入了解并掌握python、flask,等不熟悉的知识领域,并且让我深刻认识到数据可视化在如今这个数据爆炸的年代是多么的有用。但是由于水平有限,许多在原型设计中设想好的功能并没有实现,这让我十分遗憾。同时也让我认识到自己在开发这一块确实非常薄弱,可能也是硬件设施限制了我,希望到时回校了,能将代码完善。
2.对队友的评价:
221701309:我的队友很努力,而且也没有因为我能力问题而抛弃我,我们一直都在相互帮助,相互学习,相互激励。虽然,她缺乏硬件设备,但是她一直尽她所能协助我完成任务,她为我查阅各种学习资料,编辑文档,是我强大的后援。我相信未来我们会共同成长。

221701403:我的队友十分勤奋,而且非常上进,时不时会鞭策我去学习,希望我能向他靠拢。
