本次作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
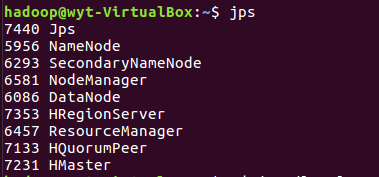
1.将爬虫大作业产生的csv文件上传到HDFS
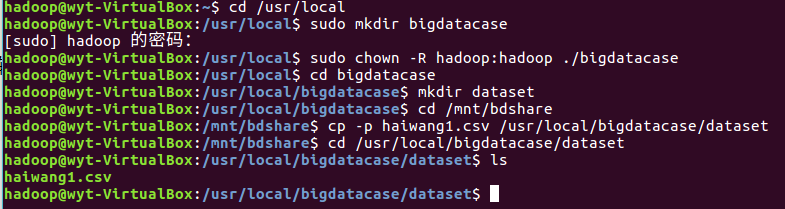
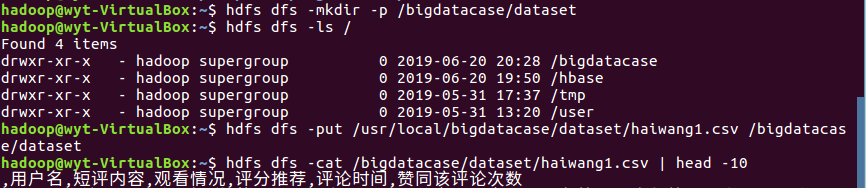
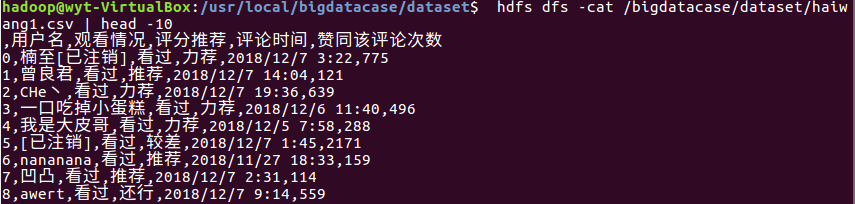
2.对CSV文件进行预处理生成无标题文本文件

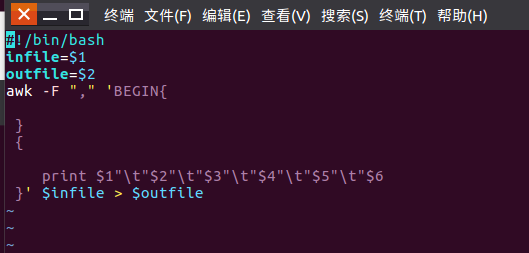
![]()

3.把hdfs中的文本文件最终导入到数据仓库Hive中
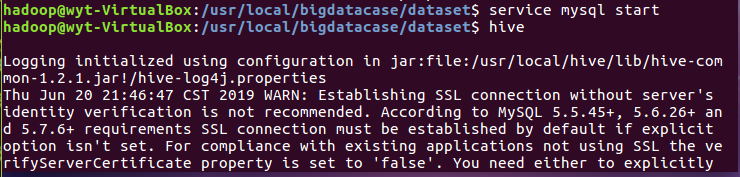
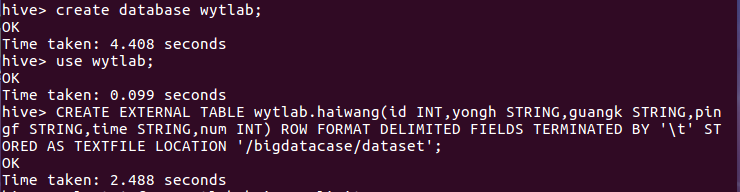
4.在Hive中查看并分析数据
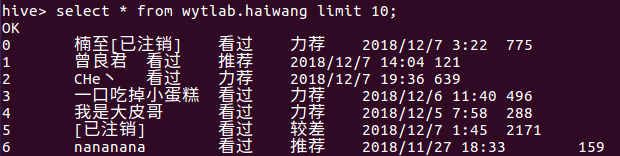

5.用Hive对爬虫大作业产生的进行数据分析
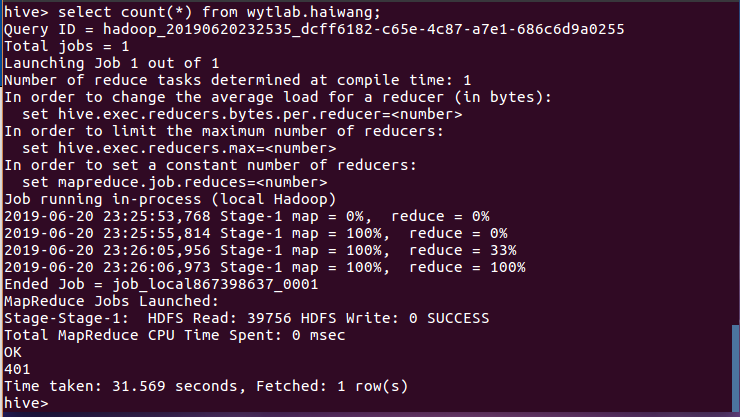
(1)查询总共有多少个评论者,结果分析知有401名评论者:
(2)查询评分推荐不重复的数据,结果分析得出只有11条评分推荐不重复的数据:

(3)查询前十名用户和赞同该用户评论的次数
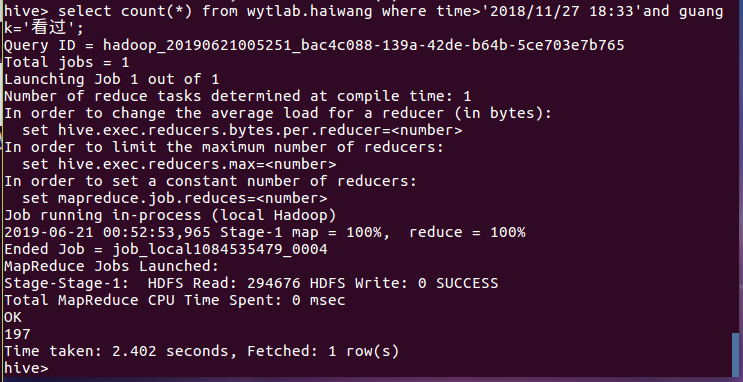
(4)查询观看情况为“看过”和评论时间大于2018/11/27 18:33的用户个数,结果分析有197人:
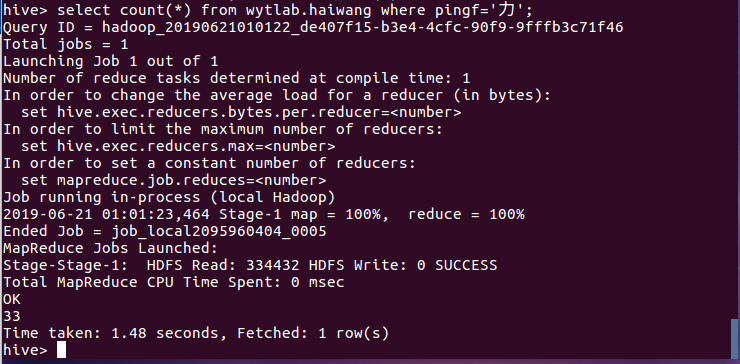
(5)查询评分推荐为力荐的人数,结果分析有33人:
(6)查询赞同评论次数大于300的数据,结果分析得出只有14条数据:
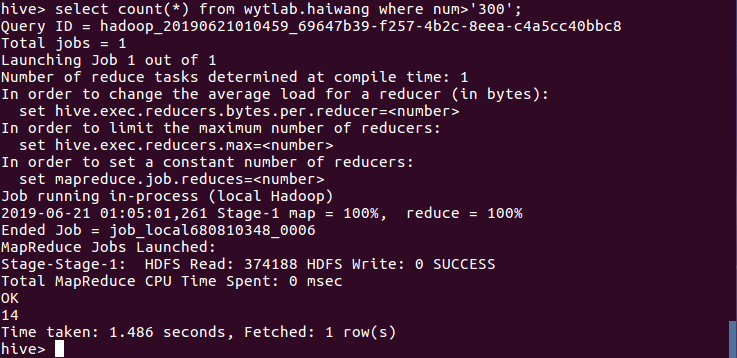
(7)查询统计观看情况为看过的数据,结果分析得到200条:
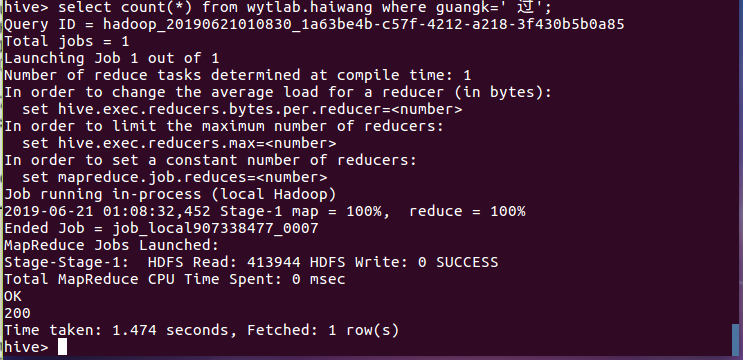
(8)查询赞同评论次数并排序:
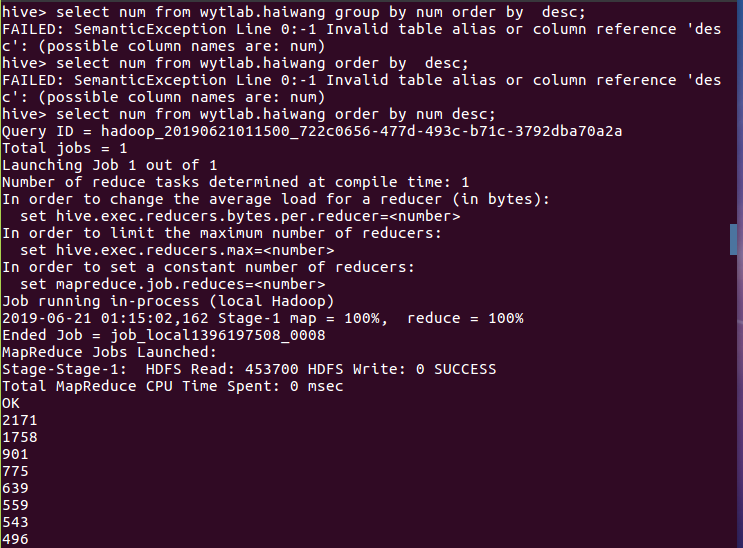
(9)查询统计观看情况并排序:
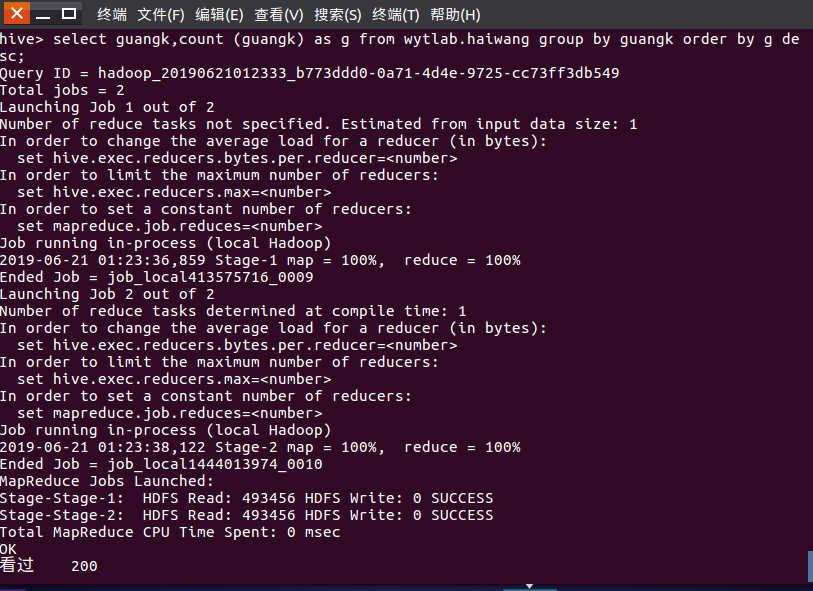
(10)查询用户名为“零点”的评论者:

总结:这次数据分析主要是对之前的爬虫大作业爬到《海王》的影评信息进行HDFS上传、 csv文件预处理生成无标题文本文件并导入数据仓库Hive再进行分析查询数据。爬取的数据不算太大,数据处理分析时间适宜,通过Hive的数据分析,我们可以清楚的知道有多少评论者、前十的用户数据等等。总的来说,这次数据分析还算顺利,希望能分析更大更繁杂的数据。