要做自动化,首先要了解页面结构,要了解页面结构,就要了解页面元素的定位方法
在使用selenium webdriver进行元素定位时,通常使用findElement或findElements方法结合By类返回的元素句柄来定位元素。
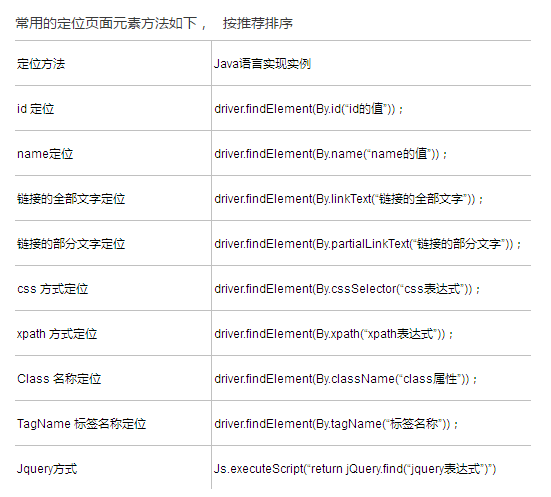
常用的元素定位方法如下:
如何选择 定位方法
策略是:选择简单,稳定的定位方法。
1. 当页面元素有id属性的时候, 尽量使用id来定位。 没有的话,再选择其他定位方法
2. cssSelector 执行速度快, 推荐使用
3. 定位超链接的时候,可以考虑linkText或partialLinkText:但是要注意的是 , 文本经常发生改变, 所以不推荐用
4. xpath 功能最强悍。 但是执行速度慢,因为需要查找整个页面元素, 所以尽量少用。 实在没有办法的时候,才使用xpath
部分定位详解,因为其他都比较简单
1、By.tagName()
通过tagName来搜索元素的时候,会返回多个元素. 因此需要使用findElements()
WebDriver driver = new FirefoxDriver();
driver.get("http://www.cnblogs.com");
List<WebElement> buttons = driver.findElements(By.tagName("div"));
System.out.println("Button:" + buttons.size());
注意: 如果使用tagName, 要注意很多HTML元素的tagName是相同的,
比如单选框,复选框, 文本框,密码框.这些元素标签都是input. 此时单靠tagName无法精确获取我们想要的元素, 还需要结合type属性,才能过滤出我们要的元素
WebDriver driver = new FirefoxDriver();
driver.get("http://www.cnblogs.com");
List<WebElement> buttons = driver.findElements(By.tagName("input"));
for (WebElement webElement : buttons) {
if (webElement.getAttribute("type").equals("text")) {
System.out.println("input text is :" + webElement.getText());
}
}
2、Xpath定位
2.1.什么是xpath:xpath 是XML Path的简称, 由于HTML文档本身就是一个标准的XML页面,所以我们可以使用Xpath 的用法来定位页面元素。
2.2.xpath定位的缺点 xpath 这种定位方式, webdriver会将整个页面的所有元素进行扫描以定位我们所需要的元素, 这是个非常费时的操作, 如果脚本中大量使用xpath做元素定位的话, 脚本的执行速度可能会稍慢
例如 testXpath.html 代码如下
<html>
<head><title>Test Xpath</title></head>
<body>
<div id="div1">
<input name="div1input"></input>
<a href="http://www.sogou.com">搜狗搜索</a>
<img alt="div1-img1" src="http://www.sogou.com/images/logo/new/sogou.png" href="http://www.sogou.com">搜狗图片</img>
<input type="button" value="查询"></input>
</div>
<br />
<div name="div2">
<input name="div2iniput" /></input>
<a href="http://www.baidu.com">百度搜索</a>
<img alt="div2-img2" src="http://www.baidu.comn/img/bdlogo.png" href="http:/www.baidu.com">百度图片</img>
</div>
</body>
</html>
绝对路径定位方式
在被测试网页中, 查找第一个div标签中的按钮
在chrome浏览器中,使用开发者工具,在需要定位的那段网页源代码上选中,右键--copy,会显示一个copy xpath,得到的类似如下:
XPath的表达式:/html/body/div/input[@value="查询"]
WebElement button = driver.findElement(By.xpath("/html/body/div/input[@value='查询']"));
绝对路径的缺点
1. 一旦页面结构发生改变,改路径也随之失效,必须重新。 所以不推荐使用绝对路径的写法
绝对路径和相对路径的区别
绝对路径 以 "/" 开头, 让xpath 从文档的根节点开始解析
相对路径 以"//" 开头, 让xpath 从文档的任何元素节点开始解析
相对路径定位方式
在被测试网页中,查找第一个div标签中的按钮
XPath的表达式://input[@value="查询"]
WebElement button = driver.findElement(By.xpath("//input[@value='查询']"));
3、表格定位
举例1:
driver.navigate().to("http://www.w3school.com.cn/html/html_tables.asp");
//获取所有的tr集合
List<WebElement> rows=driver.findElements(By.className("dataintable"));
//验证表格的行数
// assertEquals(11, rows.size());
//打印出所有单元格的数据
for(WebElement row : rows){
//等到当前tr里的td集合
List<WebElement> cols=driver.findElements(By.tagName("td"));
for(WebElement col : cols){
System.out.println(col.getText()); //得到td里面的文本
}
System.out.println();
}
举例2:
思路:层级定位,先定位table,在定位tr,在定位td
String url="table的地址";
driver.get(url);
String str="第一行第一列";
String str1="第三行第一列";
WebElement Table = driver.findElement(By.tagName("table"));
//java里打印元素类型 Sydtem.out.print(driver.findElement(By.tagName("table")).getClass());
//table有那么多行,定位在哪一行呢?--》默认都是第一行
// 所以就不能用 Table.findElement(By.tagName("tr")),findElement是定位单一的一个元素的方法,定位一组用findElements
// Table.findElement(By.tagName("tr"));//这种方式取到的是一个数组,就不是一个对象了,所以以下方法是正确的
List < WebElement> rows = Table.findElements(By.tagName("tr"));
for( WebElement row : rows){
List <WebElement> tds = row.findElements(By.tagName("td"));
for( WebElement td : tds){
// System.out.print(td.getText()+"
"); //取出所有元素
String value=td.getText();
// if(value==str){ 为什么不能用= =,因为value是一个对象
if(value.equals(str) || value.equal(str1)){
System.out.print(value+"
");
}else{
System.out.print("error"+"
");
}
}
}
4、JS定位
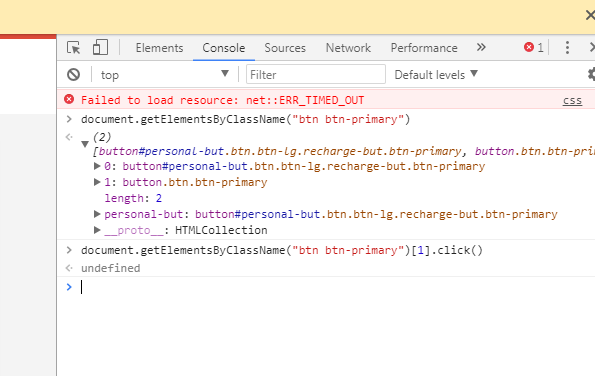
((JavascriptExecutor) driver).executeScript("document.getElementsByClassName("fa fa-circle-o")[1].click()");
例如利用JS在百度输入框输入selenium,然后在点击百度,以下可执行

