要说数据库什么最抽象,我觉得就是这个三范式,不是很好理解,但是表在设计的时候又必须要知道这么一个规则。
首先使用最简洁的话说说这三范式:
第一范式(1NF:The First Normal Form):每一列不能再分割。
第二范式(2NF:The Second Normal Form):满足1NF条件下,每一列非主键列要完全依赖主键,不能只依赖联合主键中的一部分(因为主键可能是联合主键,有多列的,必须所有字段都用上 )
第三范式(3NF:The Third Normal Form):满足2NF条件下,非主键的列不能依赖于非主键的列;
看到这三句话肯定不理解,于是,我们用图来理解一下
1.第一范式
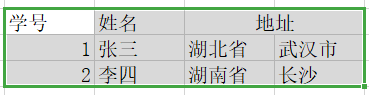
简单的来说就是不能建立下面这样的表,可以看到地址这一列是可以分割的;
一般只要是关系型数据库建立的表都会满足第一范式的。
2.第二范式
看下面这个表,这里联合主键是(学号,科目),只有确定了这两个值,才能确定其他的列;比如分数,如果只依赖学号,那么当学号为1的时候,分数有两个,不能唯一确定;如果只依赖科目,当科目为语文的时候,分数也对应有两个;
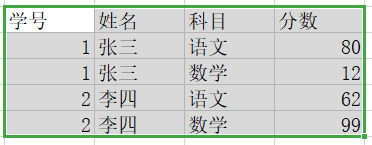
注意上面这个表中的姓名,它只是依赖学号的,根据学号就可以找对唯一对应的姓名,所以这时非主键列 “姓名” 部分依赖于联合主键“学号,科目”,不是完全依赖,所以不满足第二范式;
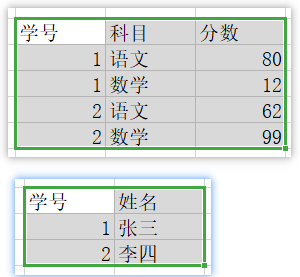
我们需要将姓名这一列给提取出来,下表所示,对于完全依赖主键的放在一张表中,展示依赖一部分主键的放在另外一张表中;
3.第三范式
什么叫做非主键列不能依赖非主键列呢?看着就看不懂...
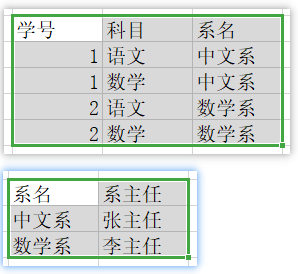
不要急,我们再看一张表:
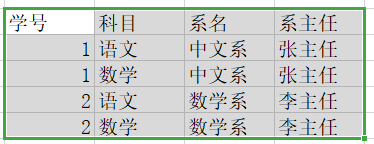
我们可以知道系名可以依赖学号,毕竟一个学生肯定对应着唯一的系,但是系主任呢?系主任肯定是依赖于系名的,不可能依赖某个学生吧,所以有这样的一个依赖关系:学号->系名->系主任,系主任间接依赖于主键,这是不满足第三范式的;
所以我们需要将系主任给拿出来,单独弄一张表:
以上就是我对三范式的理解,看了一些视频和找了一些博客总结一下的吧,其实可以使用更加专业的话来说三范式的,有兴趣的可以看看这个老哥的博客,传送门╮(╯_╰)╭ ,这个就比较专业了,哈哈
4.反三范式
按理来说按照三范式设计数据库之后,可以避免冗余数据,使得数据库结构很精简;但是有时这样的设计会使得查询表的时候需要进行关联查询,比如上面说第二范式的时候,姓名那里就不需要单独弄张表出来;
单独弄张表出来,如果有个需求要查询一个学生的名字,科目和分数,你就需要关联查询一下;但是不单独弄张表出来,你只需要查询一次就够了;
所以适当的冗余数据是可以接受的,而且可以提高查询效率,不应该为了遵守三范式而创建设计表,应该衡量自己项目的实际需要,在三范式和反三范式之间做权衡。
我这里也就是大概讲了一下我的理解,肯定有的地方不是很正确,哈哈哈,实际的项目中表肯定是非常复杂的,那就要多分析了╮(╯_╰)╭