1. 管道相关命令
1.1 cut
cut:以某种方式按照文件的行进行分割
参数列表:
| 参数 | 英文 | 含义 |
|---|---|---|
| -c | characters | 按字符选取 |
| -b | 按字节选取 忽略多字节字符边界,除非也指定了 -n 标志 | |
| -d '分隔符' | delimiter | 自定义分隔符,默认为制表符。 |
| -f 'n1,n2' | fields | 与-d一起使用,指定显示哪个区域。 |
范围控制:
| 范围 | 含义 |
|---|---|
| n | 只显示第n项 |
| n- | 显示从第n项一直到行尾 |
| n-m | 显示从第n项到第m项(包括m) |
准备工作
vim 1.txt
111:aaa:bbb:ccc
222:ddd:eee:fff
333:ggg:hhh
444:iii
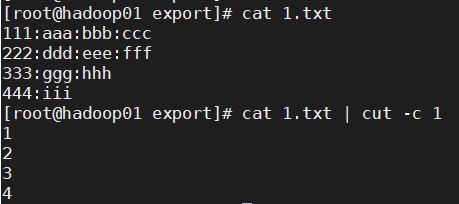
实例1:截取出1.txt文件中5行的第1个字符
cat 1.txt | cut -c 1
结果显示:
练习1:截取出1.txt文件中前2行的第5个字符
答案:
head -2 1.txt | cut -c 5
结果显示:

练习2 截取出1.txt文件中前2行以”:”进行分割的第1,2段内容
答案:
head -2 1.txt | cut -d ':' -f 1,2
或者
head -2 1.txt | cut -d ':' -f 1-2
结果显示:

练习3
截取出1.txt文件中前2行以”:”进行分割的第1,2,3段内容
答案:
head -2 1.txt | cut -d ':' -f 1,2,3
或者
head -2 1.txt | cut -d ':' -f 1-3
结果显示:

1.2 sort 的 工作原理
1.2.1 基本使用
sort将文件的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
[root@node01 tmp]# cat 01.txt
banana
apple
pear
orange
pear
[root@node01 tmp]# sort 01.txt
apple
banana
orange
pear
pear
1.2.2 sort的-u选项(去重)
| 参数 | 英文 | 含义 |
|---|---|---|
| -u | unique | 去掉重复的 |
它的作用很简单,就是在输出行中去除重复行。
[root@node01 tmp]# sort -u 01.txt
apple
banana
orange
pear
pear由于重复被-u选项无情的删除了。
1. 2.3 sort的-r 和 -n选项(对数值排序)
| 参数 | 英文 | 含义 |
|---|---|---|
| -n | numeric-sort | 按照数值大小排序 |
| -r | reverse | 使次序颠倒 |
- 准备数据
[root@node01 tmp]# cat 02.txt
1
3
5
7
11
2
4
6
10
8
9
sort默认的排序方式是升序
[root@node01 tmp]# sort 02.txt
1
10
11
2
3
4
5
6
7
8
9
排序程序将这些数字按字符来排序了,排序程序会先比较1和2,显然1小,所以就将10放在2前面
[root@node01 tmp]# sort -n 02.txt
1
2
3
4
5
6
7
8
9
10
11
-r表示降序,n表示按数字进行排序
[root@node01 tmp]# sort -n -r 02.txt
11
10
9
8
7
6
5
4
3
2
1
合并式
[root@node01 tmp]# sort -nr 02.txt
11
10
9
8
7
6
5
4
3
2
1
1.2.4 对成绩排序
| 参数 | 英文 | 含义 |
|---|---|---|
| -t | field-separator | 指定字段分隔符 |
| -k | key | 根据那一列排序 |
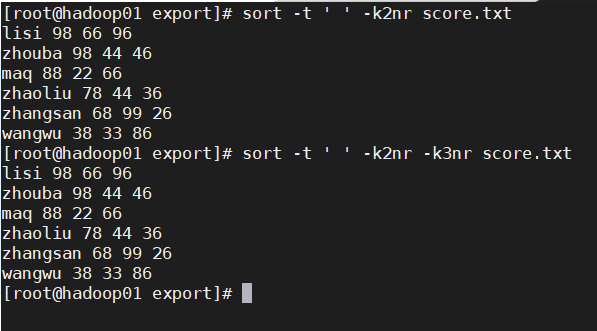
# 根据第二段成绩 进行倒序显示 所有内容
sort -t ' ' -k2nr score.txt
sort -t ' ' -k2nr -k3nr score.txt
输出结果显示:
1.3 wc命令
wc命令用于计算字数。
利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。
1.3.1 语法
wc 文件名 //显示指定文件行数, 单词数,字节数信息。
参数:
- -c或--bytes或--chars 只显示Bytes数。
- -l或--lines 只显示行数。
- -w或--words 只显示字数。
- --help 在线帮助。
- --version 显示版本信息。
1.3.2 准备工作
[root@hadoop01 export]# cat 4.txt
111
222 bbb
333 aaa bbb
444 aaa bbb ccc
555 aaa bbb ccc ddd
666 aaa bbb ccc ddd eee
1.3.3 需求: 统计指定文件行数 字数 字节数
在默认的情况下,wc将计算指定文件的行数、字数,以及字节数。使用的命令为:
wc 文件名
使用 wc统计,结果如下:
[root@hadoop01 ~]# wc 01.txt
6 21 85 01.txt
wc 01.txt # 01.txt 文件的统计信息
6 21 85 01.txt # 01.txt文件: 行数为6, 单词数为 21, 字节数为 85
其中,3 个数字分别表示 01.txt文件的行数、单词数,以及该文件的字节数。
[root@hadoop01 export]# wc -c 4.txt //只显示字节数
85 4.txt
[root@hadoop01 export]# wc -w 4.txt //只显示单词数
21 4.txt
[root@hadoop01 export]# wc -l 4.txt //只显示行数
6 4.txt
1.3.4 需求: 统计多个文件的 行数 单词数 字节数
如果想同时统计多个文件的信息,例如同时统计01.txt 、02.txt 、03.txt,可使用如下命令:
[root@hadoop01 ~]# wc 01.txt 02.txt 03.txt
6 21 85 01.txt
2 3 12 02.txt
3 6 25 03.txt
11 30 122 总用量
[root@hadoop01 export]# wc *.txt //统计以.txt为后缀的文件的行数,单词数,字节数
5 5 30 01.txt
11 11 24 02.txt
6 21 85 4.txt
6 24 94 score.txt
28 61 233 总用量
1.3.5 需求: 查看/etc目录下有多少个文件
[root@hadoop01 ~]# ls /
bin cgroup etc lib lost+found misc net proc sbin srv tmp var
boot dev home lib64 media mnt opt root selinux sys usr
[root@hadoop01 ~]# ls / | wc -w
23
1.4 uniq
uniq 命令用于检查及删除文本文件中重复出现的行,一般与 sort 命令结合使用。
1参数说明:
| 参数 | 英文 | 含义 |
|---|---|---|
| -c | count | 统计每行内容出现的次数 |
2 准备工作
vim 5.txt
张三 98
李四 100
王五 90
赵六 95
麻七 70
李四 100
王五 90
赵六 95
麻七 70
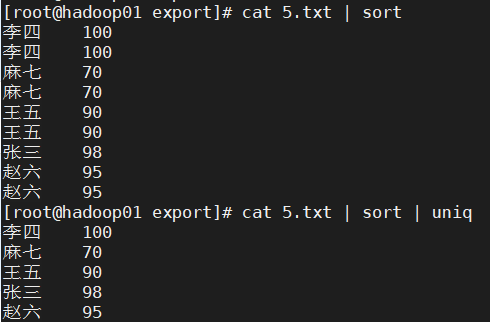
练习1 去除5.txt中重复的行
答案:
cat 5.txt | sort | uniq
结果显示:
练习2 统计5.txt中每行内容出现的次数
答案:
cat 5.txt | sort | uniq -c
结果显示:

练习3 将结果通过管道符追加到
a.txt文件中
[root@hadoop01 export]# cat 5.txt | sort | uniq -c >> a.txt
结果显示:

1.5 tee
5.1 目标
- 通过tee可以将命令结果通过管道输出到多个文件中
5.2 实现
| 命令 | 含义 |
|---|---|
| 命令结果 | tee 文件1 文件2 文件3 | 通过tee可以将命令结果通过管道输出到多个文件中 |
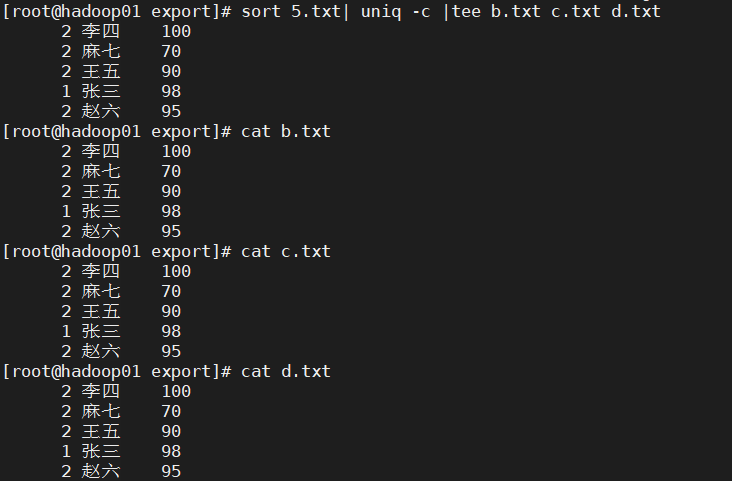
- 将去重统计的结果 放到a.txt、b.txt、c.txt文件中
cat 5.txt | sort | uniq -c | tee b.txt c.txt
结果显示:
1.6 tr
1.6.1 tr介绍
- 通过tr命令用于替换或删除文件中的字符。
1.6.2 步骤
- 第一步:实现替换效果
- 第二步:实现删除效果
- 第三步:完成单词计数实例
1.6.3 实现
第一步:实现替换效果
| 命令 | 英文 | 含义 |
|---|---|---|
| 命令结果 | tr 被替换的字符 新字符 | translate | 实现替换效果 |
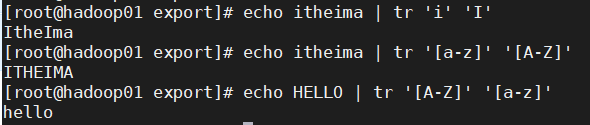
# 将小写i替换成大写I
echo itheima | tr 'i' 'I'
# 把itheima的转换为大写
echo itheima | tr '[a-z]' '[A-Z]'
# 把HELLO转成小写
echo HELLO | tr '[A-Z]' '[a-z]'
结果显示:
第二步:实现删除效果
| 命令 | 英文 | 含义 |
|---|---|---|
| 命令结果 | tr -d 被删除的字符 | delete | 删除指定的字符 |
- 需求:和三处abc1d4e5中的数字
echo abc1d4e5 | tr -d '[1-9]'
结果显示:

第三步:单词计数
- 准备工作
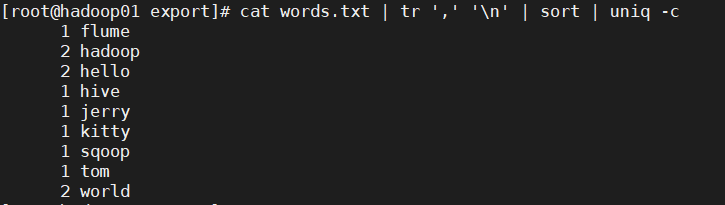
[root@hadoop01 export]# cat words.txt
hello,world,hadoop
hive,sqoop,flume,hello
kitty,tom,jerry,world
hadoop
- 处理步骤
# 1. 将,换成换行
tr ',' '
'
# 2. 排序
sort
# 3. 去重
uniq
# 4. 计数
uniq -c
- 统计每个单词出现的次数
cat words.txt | tr ',' '
' | sort | uniq -c
结果显示:
1.7 split
1.7.1 split介绍
- 通过split 命令将大文件切分成若干小文件
1.7.2 步骤
- 第一步:按字节将大文件切分成若干个小文件
- 第二步:按行数将大文件切分成若干个小文件
1.7.3 实现
- 准备工作
# 查看 /etc目录下 以.conf为结尾的文件内容
cat -n /etc/*.conf
# 将命令结果追加到 /export/v.txt文件中
cat -n /etc/*.conf >> /ecport/v.txt
第一步:按字节将大文件切分成若干个小文件
| 命令 | 英文 | 含义 |
|---|---|---|
| split -b 10k 文件 | byte | 将大文件切分成若干个10KB的小文件 |
第二步:按行数将大文件切分成若干个小文件
| 命令 | 英文 | 含义 |
|---|---|---|
| split -l 1000 文件 | lines | 将大文件切分成若干个1000行的小文件 |
1.8 awk
1.8.1 目标
- 通过
awk实现模糊查询,按需提取字段,还可以进行判断和简单的运算等。
1.8.2 步骤
- 第一步:模糊查询
- 第二步:指定分割符,根据下标显示内容
- 第三步:指定输出字段的分割符
- 第四步:调用awk提供的函数
- 第五步:通过if语句判断$4是否及格
- 第六步:段内容 求和
8.3 实现
-
准备工作:
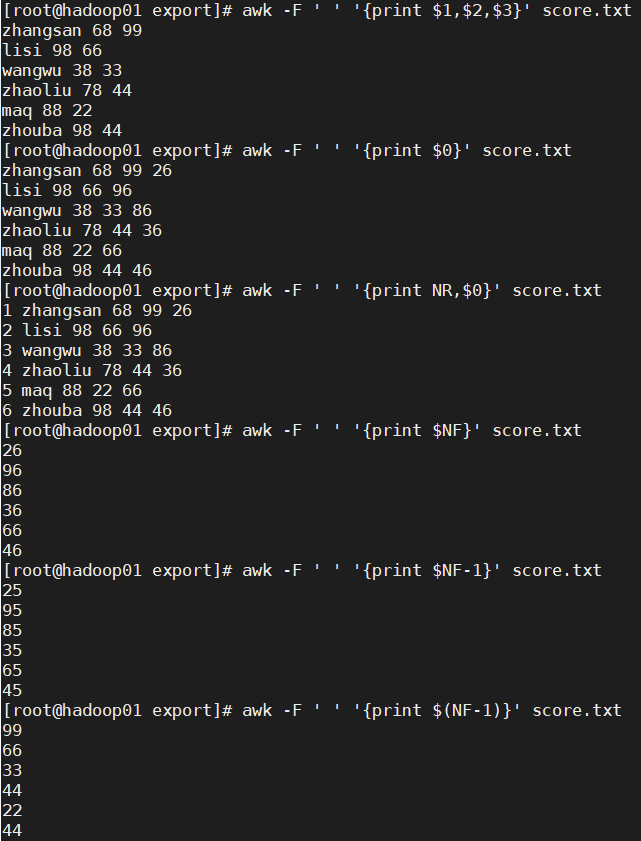
vim score.txt
zhangsan 68 99 26
lisi 98 66 96
wangwu 38 33 86
zhaoliu 78 44 36
maq 88 22 66
zhouba 98 44 46
第一步:搜索 zhangsan 和 lisi 的成绩
| 命令 | 含义 |
|---|---|
| awk '/^zh | li/' score.txt | 模糊查询 |
PS:
- 加 ^ 符号表示以......开头。
第二步: 指定分割符,根据下标显示内容
| 命令 | 含义 |
|---|---|
| awk -F ',' '{print $1,$2,$3}' 1.txt | 操作1.txt文件,根据逗号分割,打印 第一段 第二段 第三段内容 |
选项:
| 选项 | 英文 | 含义 |
|---|---|---|
| -F ',' | field-separator | 使用指定字符分割 |
| $ + 数字 | 获取第几段内容 | |
| $0 | 获取当前行内容 | |
| NF | 表示当前行共有多少个字段 | |
| $NF | 代表最后一个字段 | |
| $(NF-1) | 代表倒数第二个字段 | |
| NR | 代表处理的是第几行 |
结果显示:
第三步:指定分割符,根据下标显示内容
| 命令 | 含义 |
|---|---|
| awk -F ' ' '{OFS="==="}{print $1, $2, $3}' 1.txt | 操作1.txt文件,根据逗号分割,打印第一段 第二段 第三段 内容 |
选项:
| 选项 | 英文 | 含义 |
|---|---|---|
| OFS="字符" | output field separator | 向外输出时的段分割字符串 |
输出结果显示:

第四步:调用 awk 提供的函数
| 命令 | 含义 |
|---|---|
| awk -F ',' '{pring toupper($2)}' 1.txt | 操作1.txt文件,根据逗号分割,打印第一段 第二段 第三段 内容 |
常用函数如下:
| 函数名 | 含义 | 作用 |
|---|---|---|
| toupper() | upper | 字符转成大写 |
| tolower() | lower | 字符转成小写 |
| length() | length | 返回字符长度 |
输出结果显示:

第五步:if语句 查询及格的学生信息
| 命令 | 含义 |
|---|---|
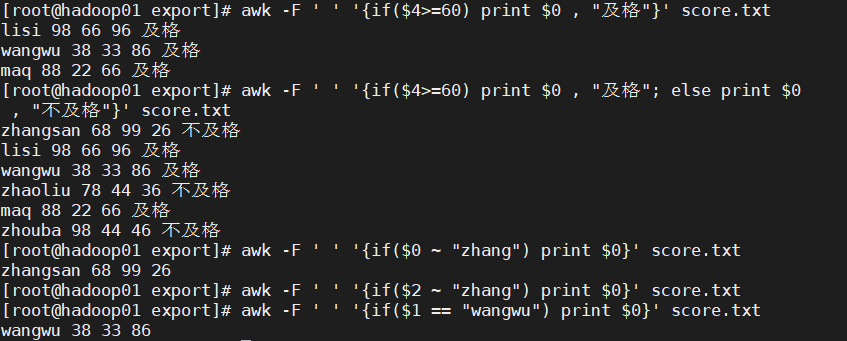
| awk -F ',' '{if($4>=60) print $1, $4} ' scoer.txt | 如果及格,就显示$1, $4 |
| awk -F ',' '{if($4>=60) print $1,$4, "及格"; else print $1,$4,"不及格"}' score.txt | 显示 姓名,$4,是否及格 |
选项:
| 参数 | 含义 |
|---|---|
| if($0 ~ "aa") print $0 | 如果这一行包含"aa",就打印这一行内容 |
| if($1 ~ "aa") print $0 | 如果第一段包含"aa",就打印这一行内容 |
| if($1 == "lisi") print $0 | 如果第一段等于"lisi",就打印这一行内容 |
输出结果显示:
第六步:段内容 求平均分
| 命令 | 含义 |
|---|---|
| awk 'BEGIN(初始化操作){每行都执行} END{结束时操作}' 文件名 | BEGIN{这里面放的是执行前的语句} {这里面放的是处理每一行时要执行的语句} END{这里面放的是处理完所有的行后要执行的语句} |
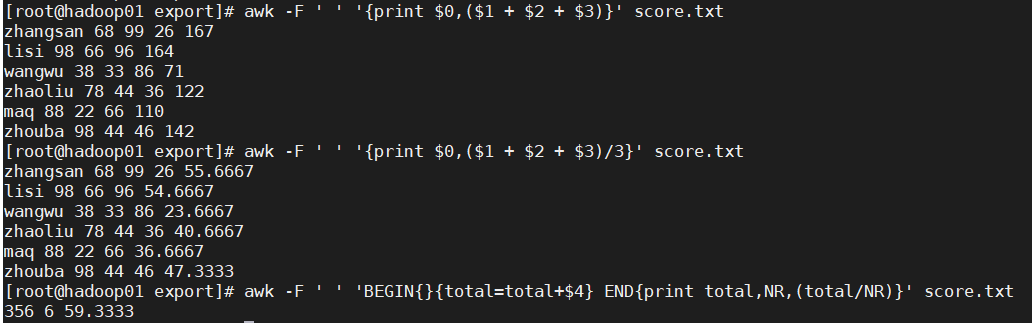
awk -F ' ' 'BEGIN{}{total=total+$4} END{print total,NR,(total/NR)}' score.txt
输出结果显示:
1.9 sed
1.9.1 目标
- 通过sed可以实现过滤和替换功能。
1.9.2 路径
-
第一步:实现 查询 功能
-
第二步:实现 删除 功能
-
第三步:实现 修改 功能
-
第四步:实现 替换 功能
-
第五步:实现 原文件 进行操作
-
第六步:综合 练习
1.9.3 实现
-
准备工作
vim 1.txt
aaa java root
bbb hello
ccc rt
ddd root nologin
eee rtt
fff ROOT nologin
ggg rttt
第一步:实现 查询 功能
| 命令 | 含义 |
|---|---|
| sed 可选项 目标文件 | 对目标文件进行过滤查询或替换 |
可选参数
| 可选项 | 英文 | 含义 |
|---|---|---|
| p | 打印 | |
| $ | 代表最后一行 | |
| -n | 仅显示处理后的结果 | |
| -e | expression | 根据表达式进行处理 |
- 练习1 列出1.txt的1~5行的数据
sed -n -e '1,5p' 1.txt
- 练习2 列出1.txt的所有数据
sed -n -e '1,$p' 1.txt
- 练习3 列出1.txt的所有数据且显示行号
| 可选项 | 含义 |
|---|---|
| = | 打印当前行号 |
sed -n -e '1,$=' -e '1,$p' 1.txt
cat -n 1.txt | sed -n -e '1,$p' # 简化版
- 练习4:查找1.txt中包含root行
sed -n -e '/root/p' 1.txt
- 练习5:列出1.txt中包含root的内容,root不区分大小写
| 可选项 | 英文 | 含义 |
|---|---|---|
| I | ignore | 忽略大小写 |
sed -n -e '/root/Ip' 1.txt
- 练习6:查找出1.txt中字母r后面是多个t的行,并显示行号
| 可选项 | 英文 | 含义 |
|---|---|---|
| -r | regexp-extended | 识别正则 |
sed -n -r -e '/r+t/p' 1.txt
或
nl 1.txt | sed -nre '/r+t/p'
第二步:实现 删除 功能
- 练习1:删除1.txt中前3行数据,并显示行号
| 可选项 | 英文 | 含义 |
|---|---|---|
| d | delete | 删除指定内容 |
nl 1.txt | sed -e '1,3d'
- 练习2:保留1.txt中前4行数据,并显示行号
nl 1.txt | sed -e '5,$d'
或
nl 1.txt | sed -ne '1,4p'
第三步:实现 修改 功能
- 练习1:在1.txt的第二行后添加aaaaaaaa并显示行号
| 参数 | 英文 | 含义 |
|---|---|---|
| i | insert | 目标前面插入内容 |
| a | append | 目标后面追加内容 |
nl 1.txt | sed -e '2a aaaaaaaa'
- 练习2:在1.txt的第二行前面添加bbbbbb并显示行号
nl 1.txt | sed -e '2i bbbbbb'
第四步:实现 替换 功能
- 练习1:把1.txt中的nologin替换成为huawei.并显示行号
| 参数 | 英文 | 含义 |
|---|---|---|
| s/oldString/newString/ | replace | 替换 |
nl 1.txt | sed -e 's/nologin/huawei/'
- 练习2:把1.txt中的1,2行替换为aaa,并显示行号
| 参数 | 英文 | 含义 |
|---|---|---|
| 2c 新字符串 | replace | 使用新字符串 替换 选中的行 |
nl 1.txt | sed -e '1,2c aaaaaaaaaaaaaaa'
第五步:对 原文件 进行操作
- 练习1:在1.txt中把nologin替换为huawei
| 参数 | 英文 | 含义 |
|---|---|---|
| -i | in-place | 替换原有文件内容 |
sed -i -e 's/nologin/huawei/' 1.txt
- 练习2:在1.txt文件中第2、3行替换为aaaaaa
sed -i -e '2,3c aaaaaa' 1.txt
- 练习3:删除1.txt中前2行数据,并且删除源文件中的数据
sed -i -e '1,2d' 01.txt
nl passwd 查看数据
第六步:综合 练习
- 练习1 获取ip地址
ip a | grep 'inet 192'|sed -e 's/^.*inet//' | sed -e 's/brd//' | sed -e 's/192.168.1.255.*$//'
- 练习2 从01.txt中提出数据,匹配出包含root的内容,再把nologin替换成itheima
nl 1.txt | sed -n -e '/root/Ip' | sed -e 's/nologin/itheima/'
或者
nl 1.txt | grep 'root' | sed -e 's/nologin/itheima/'
或者
nl 1.txt | sed -n -e '/root/{s/nologin/itheima/p}'
- 练习3 从1.txt中提出数据,删除前5行,并把nologin替换成itheima,并显示行号
nl 1.txt | sed -e '1,5d' | sed -e 's/nologin/itheima/'
2. shell编程
2.1简介
shell是一个用c语言编写的程序,通过Shell用户可以访问操作系统内核服务。
Shell既是一种命令语言,又是一种程序设计语言。
Shell script是一种shell编写的脚本程序。Shell编程一般指shell脚本程序,不能指开发shell自身。
Shell编程跟java、php编程一样,只要有一个能编写代码的文本编辑器和一个能解释执行的脚本解释器就可以了。
Linux的Shell解释器种类众多,一个系统可以存在多个shell,可以通过cat/etc/shells命令查看系统中安装的shell解释器。
Bash由于易用和免费,在日常工作中被广泛使用。同时,Bash也是大多数Linux系统默认的Shell。
Shell解释器
java需要虚拟机解释器,同理shell脚本也需要解析器。
[root@hadoop01 ~]# cat /etc/shells
/bin/sh
/bin/bash
/sbin/nologin
/usr/bin/sh
/usr/bin/bash
/usr/sbin/nologin
2.2 快速入门
2.2.1 编写脚本
新建 /export/hello.sh 文件
#!/bin/bash
echo 'hello world'
!是一个约定的标记,它告诉系统这个脚本需要什么解释器来执行,即使用哪一种Shell。
echo命令用于向窗口输出文本。
2.2.2 执行shell脚本
- 执行方式一
[root@hadoop01 ~]# /bin/sh 01.sh
hell world
[root@hadoop01 ~]# /bin/bash 01.sh
hell world

- 问题:bash和sh是什么关系

sh是bash的快捷方式
- 执行方式二
方式一的简化方式
[root@hadoop01 export]# bash hello.sh
hello shell
[root@hadoop01 export]# sh hello.sh
hello shell

- 问题:请思考问什么可以省略/bin/

因为PATH环境变量中增加了/bin/目录,所有使用/bin/sh等类似指令时,可以省略/bin
- 执行方式三
./文件名
[root@hadoop01 export]# ll
总用量 4
-rw-r--r--. 1 root root 31 1月 26 23:38 hello.sh
[root@hadoop01 export]# ./hello.sh
bash: ./hello.sh: 权限不够
- 权限不够怎么办
[root@hadoop01 export]# ll
总用量 4
-rwxr-xr-x. 1 root root 31 1月 26 23:38 hello.sh
[root@hadoop01 export]# chmod 755 hello.sh
[root@hadoop01 export]# ll
总用量 4
-rwxr-xr-x. 1 root root 31 1月 26 23:38 hello.sh
[root@hadoop01 export]# ./hello.sh
hello shell

2.3 shell变量
2.3.1 简介
在shell脚本定义中,定义变量时,变量名不加美元符号($),如:
your_name="runoob.com"
注意:变量名和等号之间不能有空格,这可能和你熟悉的所有编程语言都不一样。
同时,变量名的命名须遵循如下规则:
- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。
- 中间不能有空格,可以使用下划线(_)。
- 不能使用标点符号。
- 不能使用bash里的关键字(可用help命令查看保留关键字)。
有效的shell变量名例如下:
RUNOOB
Ld_LIBRARY_PATH
_var
_var2
无效的变量名:
?var=123
user*name=runoob
除了显示地直接赋值,还可以用语句给变量赋值,如:

for file in 'ls /etc'
或
for file in $(ls /etc)
以上语句将/etc下目录的文件名循环出来。
2.3.2 使用变量
使用一个定义过的变量,之哟啊在变量名前面加美元符号即可,如:
your_name="zhangsan"
echo $your_name
echo ${your_name}
变量名外面的花括号是可选的,加不加都行,加花括号是为了帮助解释器识别变量的边界,比如下面这种情况:
for skill in java php python;do
echo "I am good at ${skill}script"
done
如果不给skill变量加花括号,写成echo "I am good at $skillscript",解释器就会把$skillScript 当成一个变量(其值为空),代码执行结果就不是我们期望的样子了。
推荐给所有变量加上花括号,这是个好的编程习惯。
已定义的变量,可以被重新定义,如:
you_name="tom"
echo $your_name
your_name="alibaba"
echo $your_name
这样写是合法的,但注意,第二次赋值的时候不能写$your_name="alibaba",使用变量的时候才加美元符($).
2.3.3 删除变量
使用unset命令可以删除变量。语法:
unset variable_name
变量被删除后不能被再次使用。unset命令不能删除只读变量。
实例
#!/bin/bash
myurl="http://www.runoob.com"
unset myUrl
echo $myUrl
以上实例执行将没有任何输出。
2.3.4 只读变量
使用readonly命令可以将变量定义为只读变量,只读变量的值不能被改变。
下面的例子尝试更改只读变量,结果报错:
#!/bin/bash
myUrl="http://www.baidu.com"
readonly myUrl
myUrl="http://www.google.com"
运行脚本,结果如下:
/bin/sh: NAME: This varible is read only.
2.3.5 字符串
字符串是shell编程中最常用最有用的数据类型(除了数字和字符串,也没啥其他类型好用了),字符串可以用单引号,也可以用双引号,也可以不用引号。
单引号
skill='java'
str='Iam goot at $skill'
echo $str
输出结果为:
I am goot at $skill
单引号字符串的限制:
- 单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;
- 单引号字符串中不能出现单独一个的单引号(对单引号使用转义字符后也不行),但可成对出现,作为字符串拼接使用。
双引号
skill='java'
str="I am goot at $skill"
echo $str
输出结果为:
I am goot at java
双引号的优点:
- 双引号里可以有变量
- 双引号里可以出现转义字符
获取字符串长度
skill = 'java'
echo ${skill} # 输出结果:java
echo ${skill} # 输出结果:4
提取子字符串
一下实例从字符串第2个字符开始截取4个字符;
str="I am goot at $skill"
echo ${str:2} # 输出结果为: am good at java
echo ${str:2:2} #输出结果为: am
查找子字符串
查找字符i或o的位置(那个字母先出现就计算那个):
str="I am goot at $skill"
echo `expr index "$str" am` #输出是: 3
注意:以上脚本中 ` 是反引号(ESC下面的),而不是单引号',不要看错了哦。
2.3.6 传递参数
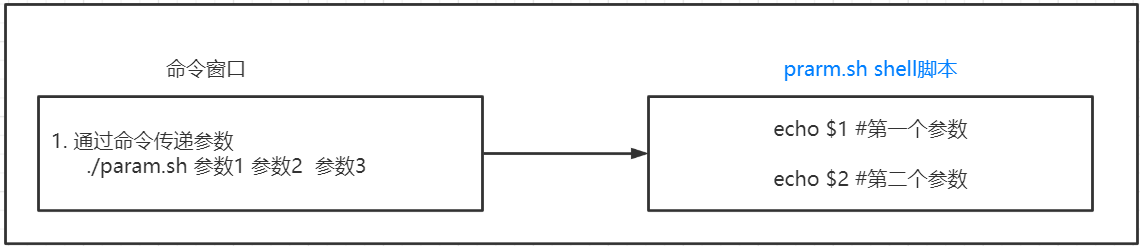
我们可以在执行shell脚本时,向脚本传递参数,脚本内获取参数的格式为:Sn。
n 代表一个数字,1为执行脚本的第一个参数,2为执行脚本的第二个参数,以此类推······
实例:
一下实例我们向脚本传递三个参数,并分别输出,其中$0为执行的文件名:
vim /export/param.sh
echo "============= 获取参数值 ================="
echo "第一个参数: $1"
echo "第二个参数: $2"
echo "第三个参数: $3"
echo "获取文件名: $0"
echo "获取参数的个数: $#"
# $* 表示将所有参数组组成一个更长的字符串
echo "获取所有的参数: $*"
for i in "$*"; do
echo "$* 获取元素:$i"
done
# $@ 表示将所有的参数都存放到一个容器中
echo "获取所有的参数2: $@"
for i in "$@"; do
echo "$@ 获取元素:$i"
done
为脚本设置可执行权限,并且执行脚本,输出结果如下所示:
chmod 755 param.sh
2.4 Shell算术运算符
2.4.1 简介
Shell 和其他编程一样,支持包括:算术、关系、布尔、字符串等运算符。
原生bash不支持简单的数学运算,但是可以通过其他命令来实现,例如expr。
expr是一款表达式计算工具,使用它能完成表达式的求值操作。
例如,两个数相加:
val=`expr 2 + 2`
echo $val
注意:
表达式和运算符之间要有空格,例如2+2是不对的,必须写成2 + 2。
完整的表达式要被 ` 包含,注意不是单引号,在Esc键下边。
下表列出了常用的算术运算符,假定变量a为20,变量b为10:
| 运算符 | 说明 | 举例 |
|---|---|---|
| + | 加法 | expr $a + $b 结果为30。 |
| - | 减法 | expr $a - $b 结果为10。 |
| * | 乘法 | expr $a * $b 结果为200。 |
| / | 除法 | expr $a / $b 结果为2。 |
2.4.2 例子
#!/bin/bash
a=4
b=20
echo '==========Shell 运算符==========='
echo ' '
echo '# 加法运算'
a1=`expr $a + $b`
echo 'expr $a + $b' = $a1
echo '$((a + b))' = $a1
echo '$[a + b]' = $a1
echo ' '
echo '# 减法运算'
a2=`expr $a - $b`
echo 'expr $a - $b' = $a2
echo '$((a + b))' = $a2
echo '$[a + b]' = $a2
echo ' '
echo '# 乘法运算'
a3=`expr $a * $b`
echo 'expr $a * $b' = $a3
echo '$((a + b))' = $a3
echo '$[a + b]' = $a3
echo ' '
echo '# 除法运算'
a4=`expr $a / $b`
echo 'expr $a / $b' = $a4
echo '$((a + b))' = $a4
echo '$[a + b]' = $a4
2.5 流程控制
2.5.1 if else
if
if语句语法格式:
if condition(条件);then
command1(命令)
command2(命令)
...
commandN
fi
dome01:
[root@hadoop01 export]# cat if_test1.sh
#!/bin/bash
a=20
if [ $a -gt 10 ]; then
echo 'a 大于 b'
fi
末尾的fi就是倒过来拼写,后面还会遇到类似的。
if else
if else 语法格式:
if condition(条件);then
command1(命令)
command2(命令)
...
commandN
else
command
fi
if elif else
if else-if else 语法格式:
if condition1; then
command1
elif condition2; then
command2
else
commandN
fi
以下实例判断两个变量是否相等:
[root@hadoop01 export]# cat if_test01.sh
#!/bin/bash
a=20
b=10
# 需求1:判断 a 是否大于 100
if [ $a -gt 100 ];then
echo "$a 大于 100"
else
echo "$a 小于或等于 100"
fi
# 需求2:判断 a 与 b 的关系
if [ $a -lt $b ];then
echo "$a 小于 $b"
elif [ $a -eq $b ];then
echo "$a 等于 $b"
else
echo "$a 大于 $b"
fi
# 需求3:判断(a + 5)是否等于 (b * b)
if test $[ a + 5 ] - eq $[ b * b ]; then
echo "(a + 5) 等于 (b * b)"
else
echo "(a + 5) 不等于 (b * b)"
fi
2.5.2 关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字
下表列出了常见的关系运算符,假定变量a为10,变量b为20;
| 运算符 | 说明 | 英文 | 举例 |
|---|---|---|---|
| -eq | 检测两个数是否相等,相等返回true | equal | [ $a -eq $b ]返回false。 |
| -ne | 检测两个数是否不相等,不相等返回true | not equal | [ $a -ne $b]返回true。 |
| -gt | 检测左边的数是否大于右边的,如果是,则返回true。 | greater than | [ $a -gt $b ]返回false。 |
| -lt | 检测左边的数是否小于右边的,如果是,则返回true。 | less than | [ $a -lt $b ]返回false。 |
| -ge | 检测左边的数是否大于等于右边的,如果是,则返回true。 | Greater than or equal to | [ $a -ge $b ]返回false。 |
| -le | 检测左边的数是否小于等于右边的,如果是,则返回true | Less than or equal to | [ $a -le $b]返回true。 |
2.5.3 for 循环
格式
for variable in (list); do
command
command
...
done
随堂练习
# 需求1:遍历1-5
# 需求2:遍历1-100
# 需求3:遍历1-100之间的奇数
# 需求4:遍历1-100之间的偶数
# 需求5:遍历 根目录 下的内容
代码如下:
[root@hadoop01 export]# cat for_test01.sh
#!/bin/bash
# 需求1:遍历1~5
for i in 1 2 3 4 5; do
echo $i
done
# 需求2:遍历 1~100
for i in {1..100}; do
echo $i
done
# 需求3:遍历1~100之间的奇数
for i in {1..100..2}; do
echo $i
done
# 需求4:遍历1~109之间的偶数
for i in {1..100}; do
if test $[ ($i%2) ] -eq 0 ; then
echo $i
fi
done
# 需求5:遍历根目录下的内容
for i in `ls /`; do
echo $i
done
2.5.4 while 语句
while循环用于不断执行一系列命令,也用于从输入文件中读取数据,命令通常为测试条件,其格式为:
while condition; do
command
done
需求1:计算1-100的和
[root@hadoop01 export]# ./while_test.sh
#!/bin/bash
# 需求1:计算1-100之间的和
i=1
sum=0
while [ $i -le 100 ]; do
# echo $i #测试命令
sum=$[ sum + i ]
i=$[i + 1]
done
echo $sum
运行脚本,输出:
5050
使用中使用了Bash let命令,它用于执行一个或多个表达式,变量计算中不需要加上$来表示变量,具体可查阅:Bash let 命令。
无限循环
无限循环语法格式:
while true; do
command
done
需求2:每隔1秒 打印一次当前时间
代码如下:
while true; do
sleep 1
date +"%Y-%m-%d %H:%M:%S"
done
2.5.5 case
Shell case 语句为多选择语句。可以用case语句匹配一个值与一个模式,如果匹配成功,执行相匹配的命令。case语句格式如下:
case 值 in
模式1)
command1
command2
...
commandN
;;
模式2)
command1
command2
...
commandN
;;
esac
ease工作方式如上所示。取值后必须为单词in,每一模式必须以右括号结束。取值可以为变量或常数。匹配发现取值符合某一模式后,其间所有命令开始执行直至;;。
取值将检测匹配的每一个模式。一旦模式匹配,则执行完匹配模式相应命令后不在执行其他模式。如果无一匹配模式,使用星号*捕获该值,在执行后面的命令。
下面的脚本指示输入1到4,将每一种模式进行匹配:
代码如下:
#!/bin/bash
echo "请输入1~4之间的数字"
read aNum #用来接收输入的数字
case $aNum in
1) echo "您输入的数字是1"
;;
2) echo "您输入的数字是2"
;;
3) echo "您输入的数字是3"
;;
4) echo "您输入的数字是4"
;;
*) echo "您输入的数字有误"
;;
esac
输入不同的内容,会有不同的结果,例如:
请输入1~4之间的数字
3
您输入的数字是3
2.5.6 跳出循环
在循环过程中,有时候需要在未达到循环结束条件时强制跳出循环,Shell使用两个命令来实现该功能;break和continue。
break 命令
break命令允许跳出所有循环(终止执行后面的所有循环)。
需求:执行死循环 每隔1秒打印当前时间,执行10次停止
代码如下:
i=0
while true; do
sleep 1
echo $i `date +"%Y-%m-%d %H:%M:%S"`
i=$[ i + 1 ]
if [ $i -eq 10 ];then
break
fi
done
continue
continue命令与break命令类似,只有一点差别,它不会跳出所有循环,仅仅跳出当前循环。
需求:打印 1~30,注意跳过3的倍数
代码如下:
#!/bin/bash
for i in {1..30}; do
if test $[ i % 3 ] -eq 0; then
continue
fi
echo $i
done
2.5.7 函数使用
1、函数的快速入门
-
格式
[ function ] funname() { action; [return int;] }- 可以带function fun() 定义,也可以直接fun()定义,不带任何参数。
- 参数返回,可以显示加:return 返回,如果不加,将以最后一条命令运行结果,作为返回值。return后跟数值(0-255)
-
快速入门
function demoFun(){ echo "这是我的第一个 shell 函数!=====================" return 100; } demoFun # 获取方法的返回值 echo "方法的返回值: $?" #获取参数内容 function demo2Fun(){ echo "这是我的第一个 shell 函数!=====================" echo "第一个参数:$1" echo "第一个参数:$2" echo "第一个参数:$3" echo "获取当前文件名:$0" echo "获取全部参数 第一种方法:$*" #这是一个字符串 echo "获取全部参数 第二种方法:$@" #这是一个容器 } demo2Fun sd daf gag
2.5.8 数组
定义数组
数组中可以存放多个值,Bash Shell 只支持一维数组(不支持多维数组),初始化时不需要定义数组大小(PHP类似)。
与大部分编程语言类似,数组元素的下标由0开始。
Shell数组用括号来表示,元素用“空格”符号分割开,语法格式如下:
array_name=(value1 value2 value3 ... valuen)
实例一
# 1 定义数组
arr1=(A B C D)
# 2 修改元素内容
arr1[0]="AAAAAAAAAAAAAAAAAAA"
# 3 获取元素内容
echo "第一个元素:${arr1[0]}"
echo "第二个元素:${arr1[1]}"
echo "第三个元素:${arr1[2]}"
echo "第四个元素:${arr1[3]}"
# 4 一次性打印所有的数组元素
echo "一次性打印出所有的数组元素 方式一:${arr1[*]}"
echo "一次性打印出所有的数组元素 方式二:${arr1[@]}"
# 5 获取数组的长度
echo "获取数组的长度 方式一:${#arr1[*]}"
echo "获取数组的长度 方式二:${#arr1[@]}"
# 6 遍历数组
echo "遍历数组 方式一 ===================="
for e in ${arr1[*]};do
echo $e
done
echo "遍历数组 方式二 ===================="
for ((i=0; i<${#arr1[*]}; i++)) {
echo ${arr1[$i]}
}
2.5.9 加载其他文件文件的变量
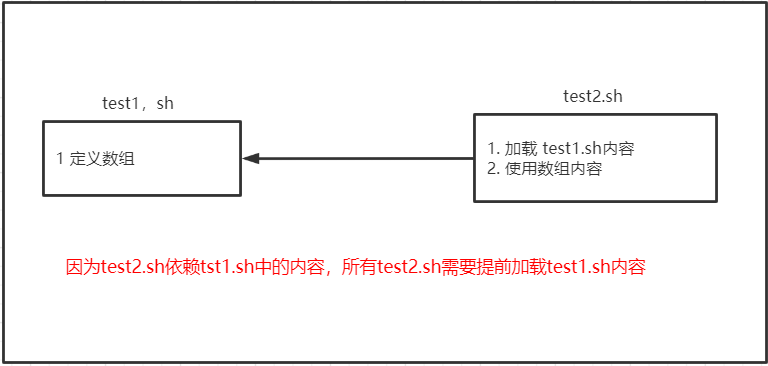
简介
和其他语言一样,Shell也可以包含外部脚本。这样可以很方便的封装一些公用的代码作为一个独立的文件。
Shell文件包含的语法格式如下:
. filename # 注意点号(.)和文件名中间有一个空格
或
source filename
练习
定义两个文件test1.sh和test2.sh,在test1中定义一个变量arr=(AAA BBB CCC),在test2中对arr进行循环打印输出。
第一步:vim test1.sh
#!/bin/bash
# 1 定义一个数组
arr1=(AAA BBB CCC DDD)
第二步:vim test2.sh
#!/bin/bash
# 1 加载test1.sh的内容
. /export/test1.sh
# 2 使用文件test1.sh的数组 循环数组的第一种方法
for i in ${arr1[*]}; do
echo $i
done
# 2 使用文件test1.sh的数组 循环数组的第2种方法
for ((i=0;i<${#arr1[*]};i++)){
echo ${arr1[$i]}
}