- HDFS甘薯以及设计目标
- HDFS架构
- HDFS副本机制
- HDFS读取文件和写入文件
1.Windows与Hadoop的文件管理的不同
- windows的文件管理系统是NTFS,Hadoop的文件管理系统是 HDFS
2.HDFS设计概念:
- 当数据集的大小超过单挑计算机的存储能力时,就有必要进行分区并存储到若干台单独的计算机上,而管理网络中跨多台计算机存储的文件系统成为分布式文件系统。Hadoop有一个抽象的我呢间系统概念,HDFS 只是其中的一个实现
- HDFS的特点
- 适合存储超大文件
- 运行于廉价硬件之上
- 易扩展,为用户提供性能不错的文件存储服务
- 流式数据访问
- HDFS的缺点
- 实时数据访问弱(如果要求访问时间在毫秒,做不到。针对数据吞吐量做了优化牺牲了速度。可以考虑:HBase)
- 大量的小文件
- 多用户写入,任意修改文件
3.HDFS架构
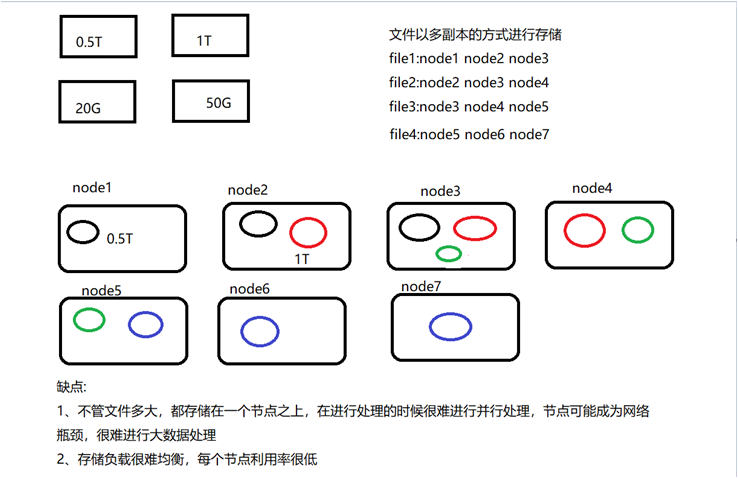
1.普通分布式文件系统的设计思路:
2.HDFS的架构:
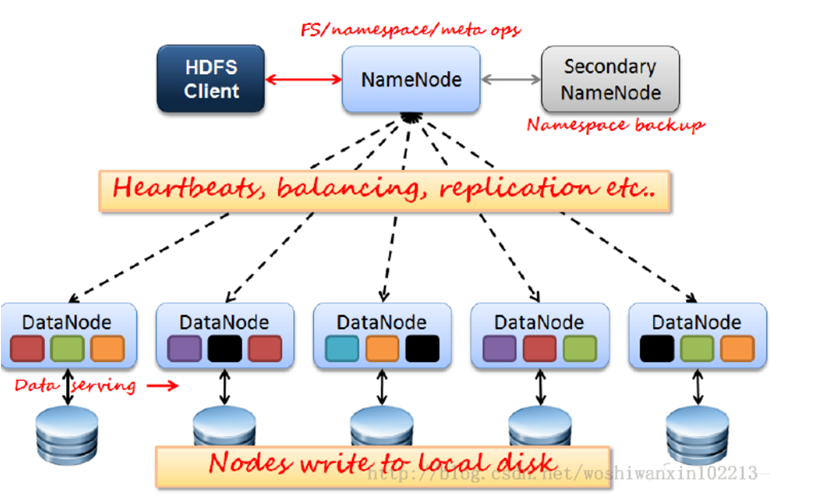
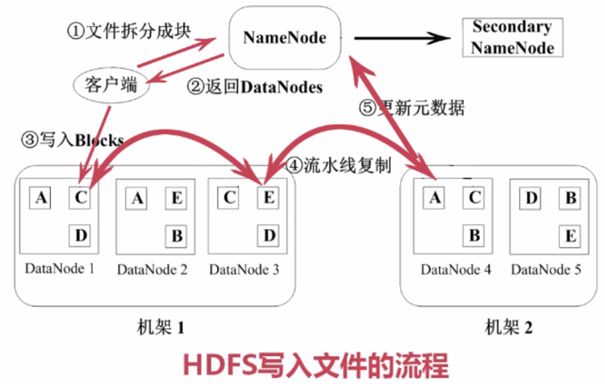
- 一个完整的HDFS运行在一些节点之上,这些节点运行着不同类型的守护进程,如:Namenode,DataNode,SecondaryNameNode不同类型的节点相互配合,相互协作,在集群中扮演不同的角色一起构建了HDFS。
- 一个典型的HDFS 集群中,有要有一个NameNode,一个SecondarrNode和至少一个DataNode,而HDFS客户端并没有限制,所有的数据均存放在运行DataNode进程的节点块(block)里
3.块
块是HDFS文件系统中组织的最小单位,默认64MB,可随着需求而变化,配置项为hafd-site.xml文件中的dfs.block.size项,
块的好处:
-
- 可以保存比存储节点单一磁盘大的文件
- 简化存储子系统
- 容错性高
4.NameNode和SecondaryNameNode
- 1.NameNode也被称为名子节点,是HDFS的主从架构的主角色的扮演者。
- NameNode是HDFS的大脑,他维护着整个文件系统的目录树,以及目录树里所有的文件和目录,这些信息以两种文件存储在本地文件中:一种是命名空间镜像(FSImage)即HDFS元数据的完整快照,每次NameNode启动的时候,默认加载最新的FSImage,另一种是命名空间镜像的编写日志(edit.log)
- 2.SecondaryNameNode
- SecondaryNameNode也称为第二名子节点,用于定期合并命名空间镜像和命名空间镜像的编辑日志的辅助守护进程。每个HDFS集群都有一个。SecondaryNameNode在生产环境下,一般SecondaryNameNode也会单独执行在一台服务器上
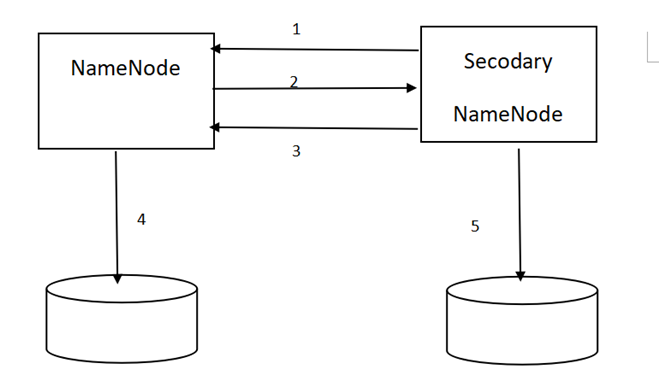
- 3.NameNode和SecondaryNode的交互

- 4. DataNode
- DataNode被称为数据节点,他是HDFS的主从框架的从角色的扮演者它在NameNode的指导下完成I/O任务。存放在HDFS的文件都是由HDFS的块组成,所有的块都存放在DataNode节点。对于DataNode来讲,块就是一个普通文件。DataNode会不断的向NameNode报告。初始化时,每个DataNode将当前存储的块告知NameNode,在集群正常工作时,DataNode任然会更新NameNode为之提供本地修改的相关信息,同时接受来自NameNode的指令,创建,移动或者删除本地磁盘上的块
- 5.HDFS客户端
- HDFS的客户端是指用户和HDFS交互的手段,HDFS提供了非常多的客户端,包括命令行接口,javaAPI
- 6.HDFS容错机制(使文件系统能够容忍节点故障且不丢失任何数据)
- 心跳机制(在NameNode和DataNode之间维持心跳检测)
- 检查文件块的完整性
- 集群的负载均衡
- NameNode上的FSImage和编辑日志文件
- 文件的删除
- 7.HDFS的副本机制
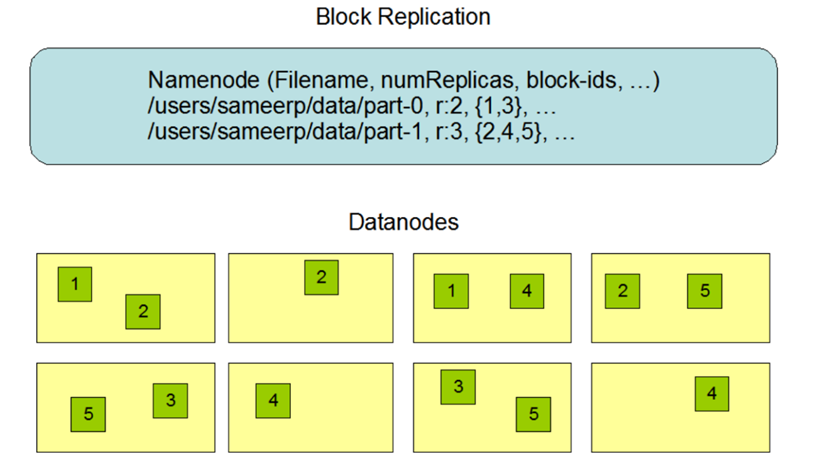
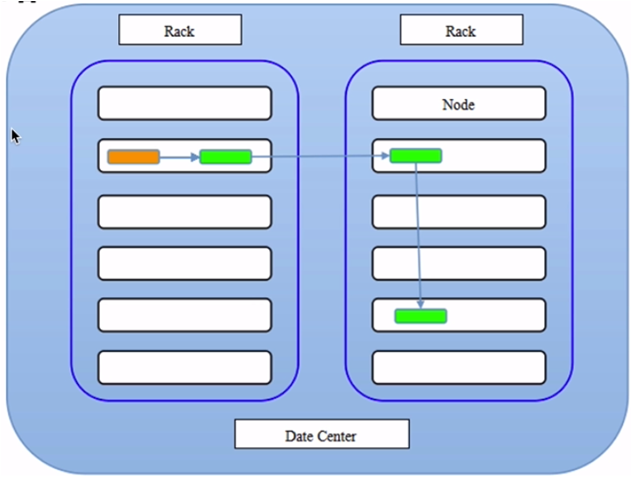
- 8.HDFS读取文件和写入文件
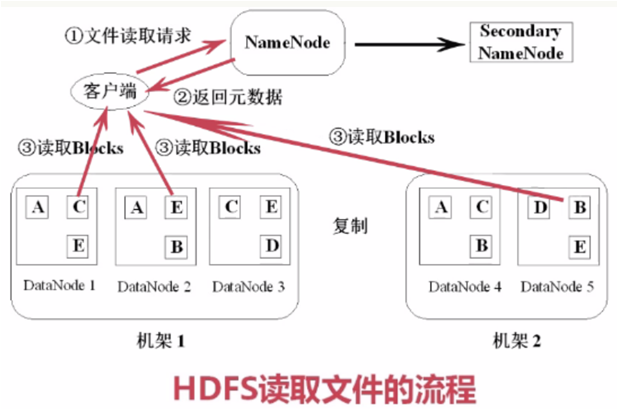

- 9.通过HDFS写入文件