二级索引的本质就是建立各列值与行键之间的映射关系
HBASE是在hadoop之上构建非关系型,面向列存储的开源分布式结构化数据存储系统。
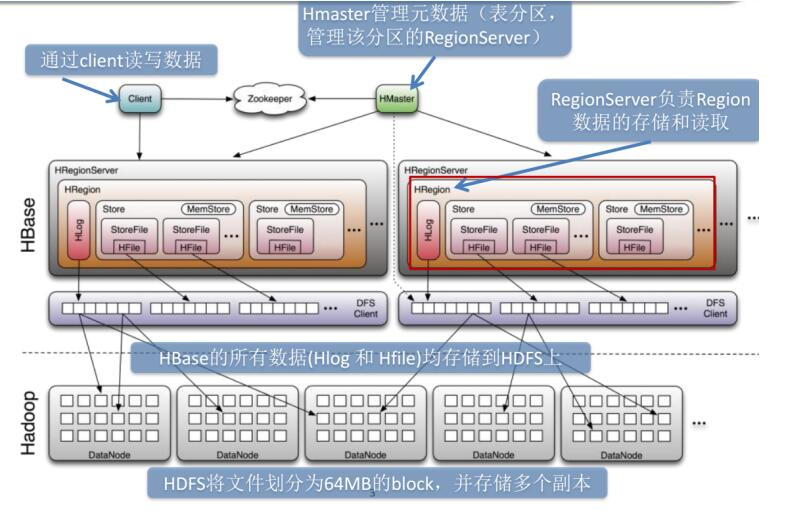
Hbase的局限性:
HBase本身只提供基于行键和全表扫描的查询,而行键索引单一,对于多维度的查询困难。
所以我们引进一个二级索引的概念
常见的二级索引:
HBase的一级索引就是rowkey,我们只能通过rowkey进行检索。如果我们相对hbase里面列族的列列进行一些组合查询,就需要采用HBase的二级索引方案来进行多条件的查询。
1. MapReduce方案
2. ITHBASE(Indexed-Transanctional HBase)方案
3. IHBASE(Index HBase)方案
4. Hbase Coprocessor(协处理器)方案
5. Solr+hbase方案
6. CCIndex(complementalclustering index)方案
二级索引的种类
1、创建单列索引
2、同时创建多个单列索引
3、创建联合索引(最多同时支持3个列)
4、只根据rowkey创建索引
单表建立二级索引
1.首先disable ‘表名’ 2.然后修改表 alter 'LogTable',METHOD=>'table_att','coprocessor'=>'hdfs:///写好的Hbase协处理器(coprocessor)的jar包名|类的绝对路径名|1001' 3. enable '表名'
二级索引的设计思路

二级索引的本质就是建立各列值与行键之间的映射关系
如上图1,当要对F:C1这列建立索引时,只需要建立F:C1各列值到其对应行键的映射关系,如C11->RK1等,这样就完成了对F:C1列值的二级索引的构建,当要查询符合F:C1=C11对应的F:C2的列值时(即根据C1=C11来查询C2的值,图1青色部分)
其查询步骤如下:
1. 根据C1=C11到索引数据中查找其对应的RK,查询得到其对应的RK=RK1
2. 得到RK1后就自然能根据RK1来查询C2的值了 这是构建二级索引大概思路,其他组合查询的联合索引的建立也类似。
Mapreduce的方式创建二级索引
使用整合MapReduce的方式创建hbase索引。主要的流程如下:
1.1扫描输入表,使用hbase继承类TableMapper
1.2获取rowkey和指定字段名称和字段值
1.3创建Put实例, value=” “, rowkey=班级,column=学号
1.4使用IdentityTableReducer将数据写入索引表
实例:
1、在hbase中创建索引表 student_index
create 'student_index','info'
2、编写mapreduce代码
package com.wyh.Hbase_MR; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.hbase.mapreduce.TableMapper; import org.apache.hadoop.hbase.mapreduce.TableReducer; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import java.io.IOException; /** * 建立索引表 * */ public class HbaseToIndex { /** * Map段 将读取到的数据,设置班级+学号当作key */ public static class IndexMap extends TableMapper<Text,NullWritable>{ @Override protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException { String id = Bytes.toString(key.get()); String clazz = Bytes.toString(value.getValue("info".getBytes(), "clazz".getBytes())); String key1 = id+"_"+clazz; context.write(new Text(key1),NullWritable.get()); } } /** * Reduce段 获取Map传过来的key */ public static class IndexReduce extends TableReducer<Text,NullWritable,NullWritable>{ @Override protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { String[] split = key.toString().split("_"); String id = split[0]; String clazz = split[1]; Put put = new Put(clazz.getBytes()); put.add("info".getBytes(),id.getBytes(),"".getBytes()); context.write(NullWritable.get(),put); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); conf.set("hbase.zookeeper.quorum","master:2181,node1:2181,node2:2181"); Job job = Job.getInstance(conf); job.setJobName("HbaseToIndex"); job.setJarByClass(HbaseToIndex.class); Scan scan = new Scan(); scan.addFamily("info".getBytes()); TableMapReduceUtil.initTableMapperJob("students",scan,IndexMap.class,Text.class,NullWritable.class,job); TableMapReduceUtil.initTableReducerJob("student_index",IndexReduce.class,job); job.waitForCompletion(true); } }
3、打成jar包上传到hadoop中运行
hadoop jar hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.wyh.Hbase_MR.HbaseToIndex
4、编写查询代码,测试结果
package com.wyh.Hbase_MR; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.util.Bytes; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.IOException; import java.util.ArrayList; import java.util.List; public class OpIndex { private Configuration conf; private HConnection connection; private HBaseAdmin admin; /** * 连接到Hbase */ @Before public void Cline(){ try { conf = new Configuration(); conf.set("hbase.zookeeper.quorum","master:2181,node1:2181,node2:2181"); connection = HConnectionManager.createConnection(conf); admin = new HBaseAdmin(conf); System.out.println("建立连接成功。。。"+connection); } catch (IOException e) { e.printStackTrace(); } } /** * 通过索引表进行查询数据 */ @Test public void scanData(){ try { //创建一个集合存放查询到的学号 ArrayList<Get> gets = new ArrayList<>(); //获取到索引表 HTableInterface student_index = connection.getTable("student_index"); Get get = new Get("理科二班".getBytes()); Result result = student_index.get(get); List<Cell> cells = result.listCells(); for (Cell cell : cells) { String id = Bytes.toString(CellUtil.cloneQualifier(cell)); gets.add(new Get(id.getBytes())); } //获取到学生表 HTableInterface students = connection.getTable("students"); Result[] results = students.get(gets); for (Result result1 : results) { String id = Bytes.toString(result1.getRow()); String name = Bytes.toString(result1.getValue("info".getBytes(), "name".getBytes())); String age = Bytes.toString(result1.getValue("info".getBytes(), "age".getBytes())); String gender = Bytes.toString(result1.getValue("info".getBytes(), "gender".getBytes())); String clazz = Bytes.toString(result1.getValue("info".getBytes(), "clazz".getBytes())); System.out.println(id+" "+name+" "+age+" "+gender+" "+clazz); } } catch (IOException e) { e.printStackTrace(); } } @After public void Close(){ if(admin!=null){ try { admin.close(); System.out.println("admin已经关闭。。。。"); } catch (IOException e) { e.printStackTrace(); } } if(connection!=null){ try { connection.close(); System.out.println("connection已经关闭。。。。"); } catch (IOException e) { e.printStackTrace(); } } } }
运行结果:
