什么是Hive? 我来一个短而精悍的总结(面试常问)
1:hive是基于hadoop的数据仓库建模工具之一(后面还有TEZ,Spark)。
2:hive可以使用类sql方言,对存储在hdfs上的数据进行分析和管理。
Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL ),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL ,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
Hive的表其实就是HDFS的目录,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
Hive相当于hadoop的客户端工具,部署时不一定放在集群管理节点中,可以放在某个节点上。
Hive与传统数据库比较
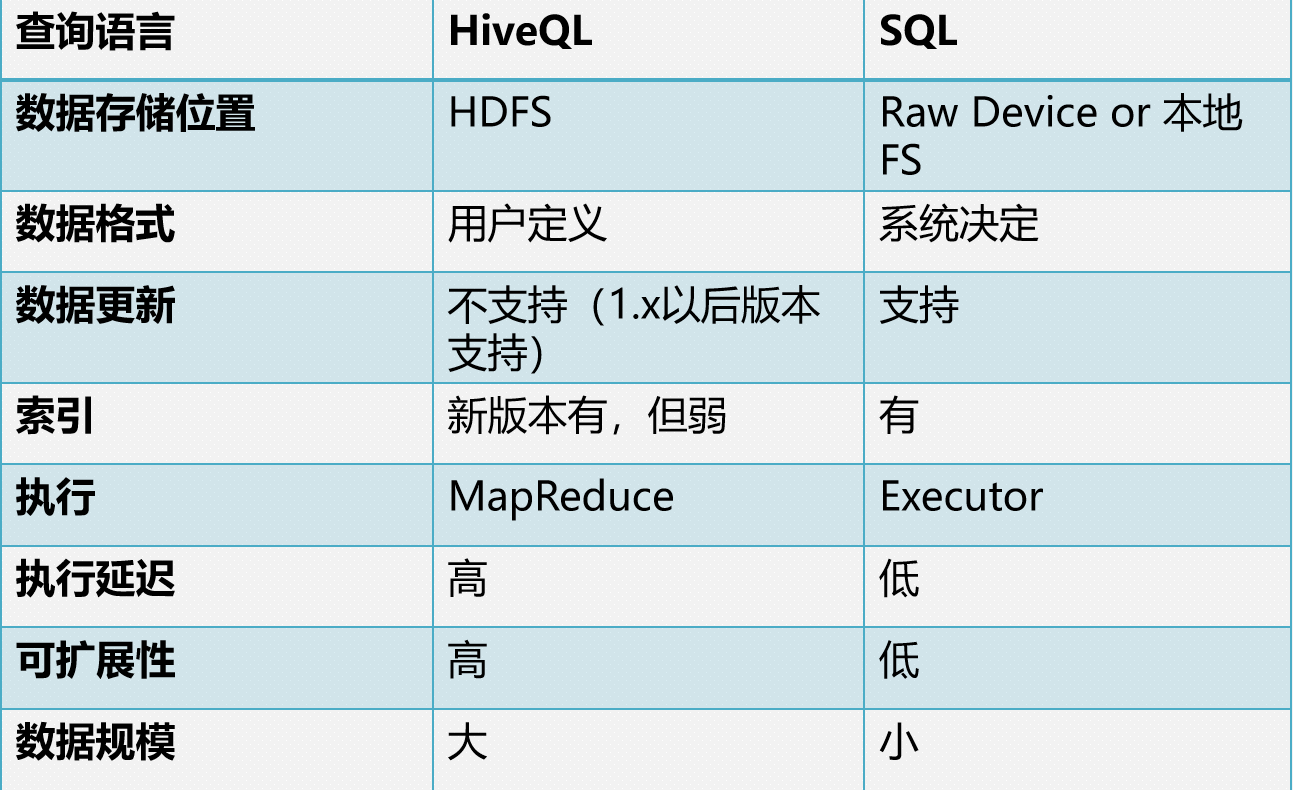
Hive与传统数据库比较
1. 查询语言。类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
2. 数据存储位置。所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
3. 数据格式。Hive 中没有定义专门的数据格式。而在数据库中,所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
4. 数据更新。Hive 对数据的改写和添加比较弱化,0.1.4版本之后支持,需要启动配置项。而数据库中的数据通常是需要经常进行修改的。
5. 索引。Hive 在加载数据的过程中不会对数据进行任何处理。因此访问延迟较高。数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
6. 执行计算。Hive 中执行是通过 MapReduce 来实现的而数据库通常有自己的执行引擎。
7. 数据规模。由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
Hive的存储格式
Hive的数据存储基于Hadoop HDFS。
Hive没有专门的数据文件格式,目前主流使用有三种:
TextFile
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。 可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分。从而无法对数据进行并行操作。
RCFile
RCFILE是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取
SequenceFile
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。
Hive操作客户端
常用的2个:CLI,JDBC/ODBC
CLI,即Shell命令行 JDBC/ODBC 是 Hive 的Java,与使用传统数据库JDBC的方式类似。
Hive 将元数据存储在数据库中(metastore),目前只支持 mysql、derby。
Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from table 不会生成 MapRedcue 任务,记住,其实这里的不产生mapreduce的原因是hive自己的数据抓取策略默认是不开启mapreduce任务的,如果开启可以设置,但是谁想变慢呢,所以一般默认就好)
Hive的metastore
metastore是hive元数据的集中存放地。
metastore默认使用内嵌的derby数据库作为存储引擎
Derby引擎的缺点:一次只能打开一个会话
使用MySQL作为外置存储引擎,多用户同时访问
元数据库详解见:查看mysql SDS表和TBLS表
可参考 https://blog.csdn.net/haozhugogo/article/details/73274832