什么是MapReduce
你想数出一摞牌中有多少张黑桃。直观方式是一张一张检查并且数出有多少张是黑桃。
MapReduce方法则是:
1.给在座的所有玩家中分配这摞牌
2.让每个玩家数自己手中的牌有几张是黑桃,几张是红桃,然后把这两组数目汇报给你
3.你把所有玩家告诉你的两组数字分别加起来,得到最后的结论
MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题. MapReduce是分布式运行的,由两个阶段组成:Map和Reduce,Map阶段是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据。Reduce阶段是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据【在这先把reduce理解为一个单独的聚合程序即可】。
MapReduce框架都有默认实现,用户只需要覆盖map()和reduce()两个函数,即可实现分布式计算,非常简单。
这两个函数的形参和返回值都是<key、value>,使用的时候一定要注意构造<k,v>。
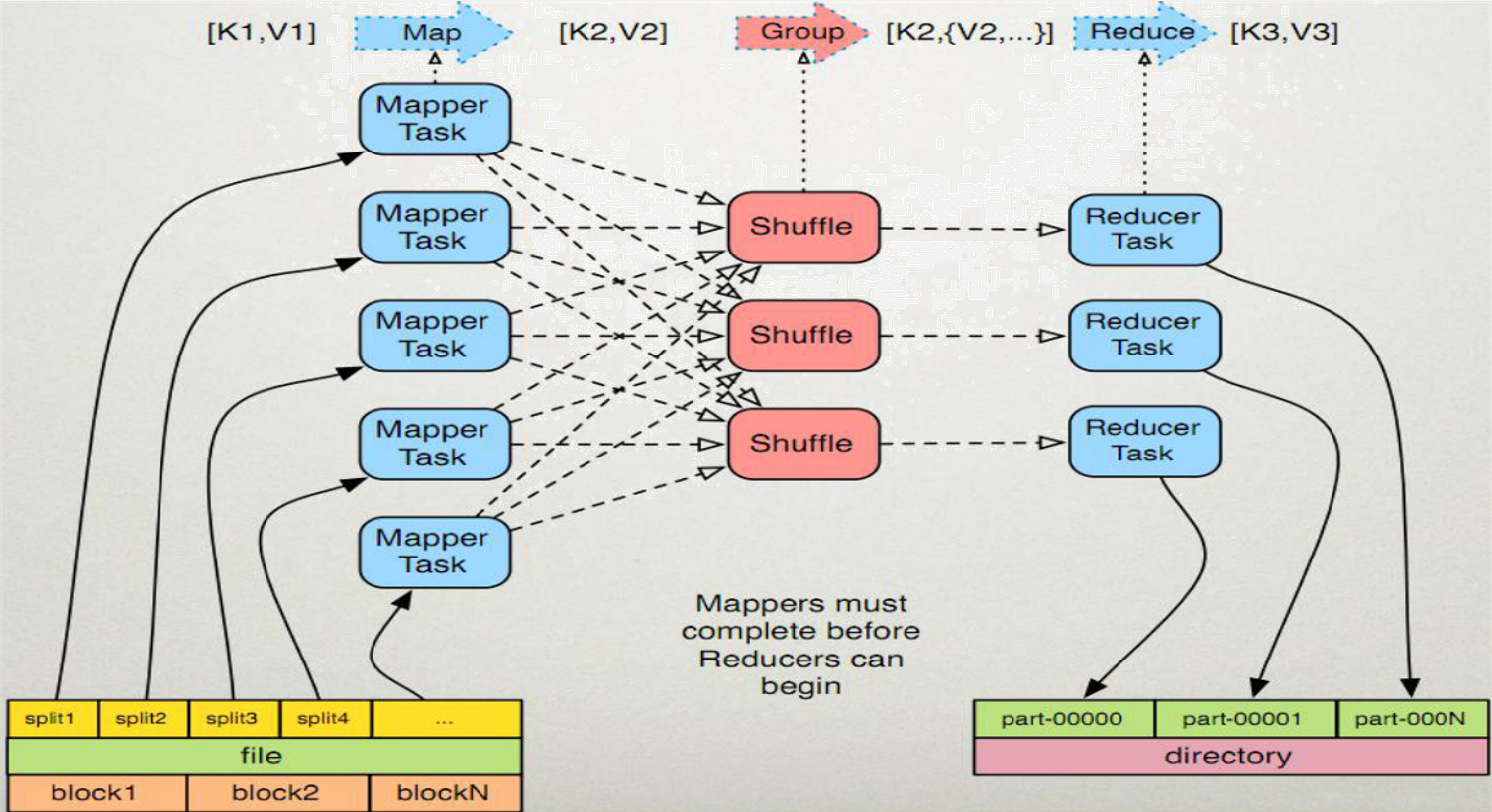
MapReduce原理
MapReduce执行过程----Map阶段
map任务处理
1.1 框架使用InputFormat类的子类把输入文件(夹)划分为很多InputSplit,默认,每个HDFS的block对应一个InputSplit。通过RecordReader类,把每个InputSplit解析成一个个<k1,v1>。默认,框架对每个InputSplit中的每一行,解析成一个<k1,v1>。
1.2 框架调用Mapper类中的map(...)函数,map函数的形参是<k1,v1>对,输出是<k2,v2>对。一个InputSplit对应一个map task。程序员可以覆盖map函数,实现自己的逻辑。
1.3
(假设reduce存在)框架对map输出的<k2,v2>进行分区。不同的分区中的<k2,v2>由不同的reduce task处理。默认只有1个分区。
(假设reduce不存在)框架对map结果直接输出到HDFS中。
1.4 (假设reduce存在)框架对每个分区中的数据,按照k2进行排序、分组。分组指的是相同k2的v2分成一个组。注意:分组不会减少<k2,v2>数量。
1.5 (假设reduce存在,可选)在map节点,框架可以执行reduce归约。
1.6 (假设reduce存在)框架会对map task输出的<k2,v2>写入到linux 的磁盘文件中。 至此,整个map阶段结束
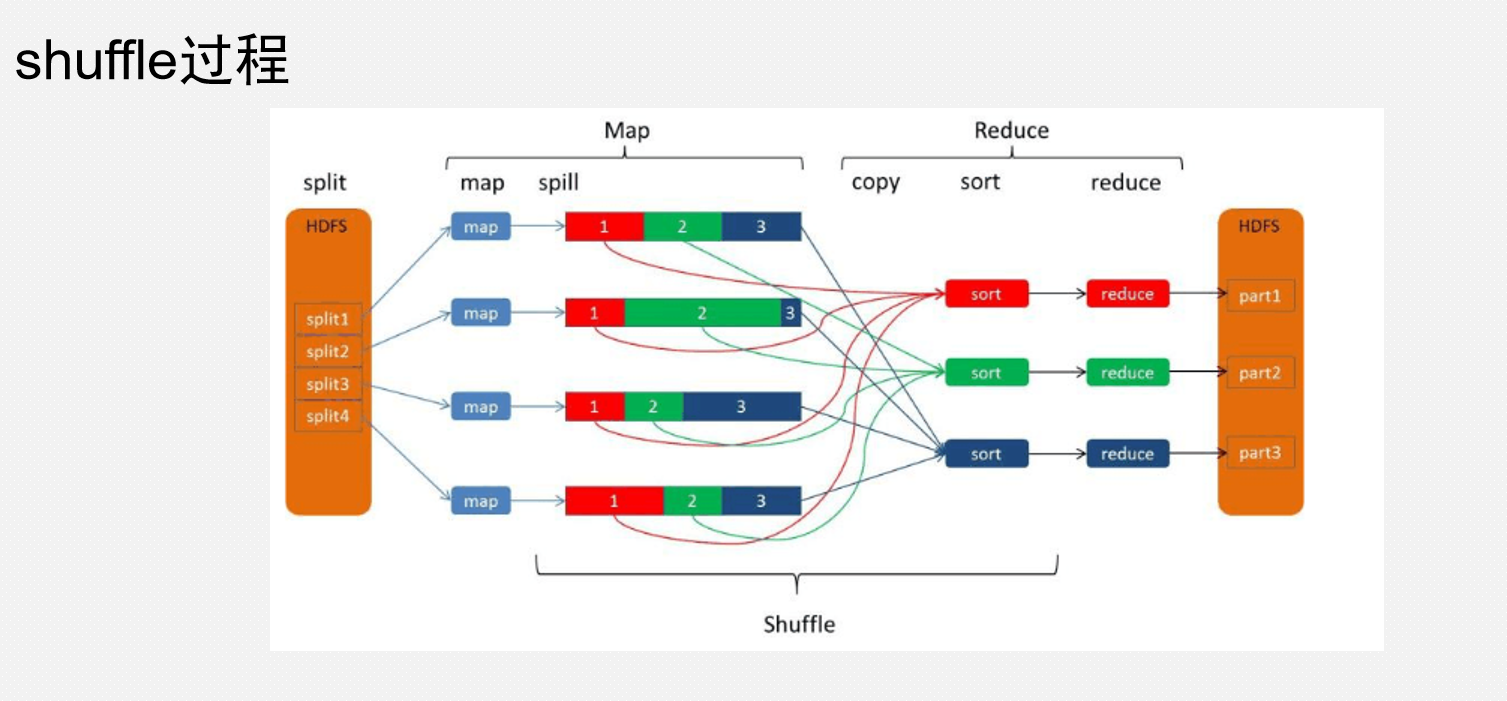
Shuffle过程(Reduce拉取数据的过程)
1.每个map有一个环形内存缓冲区,用于存储map的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线程把内容溢写到(spill)磁盘的指定目录(mapred.local.dir)下的一个新建文件中。
2.写磁盘前,要partition,sort。如果有combiner,combine排序后数据。
3.等最后记录写完,合并全部文件为一个分区且排序的文件。 =========================================================
1.Reducer通过Http方式得到输出文件的特定分区的数据。
2.排序阶段合并map输出。然后走Reduce阶段。
3.reduce执行完之后,写入到HDFS中。
MapReduce执行过程----Reduce阶段
reduce任务处理
2.1 框架对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。这个过程称作shuffle。
2.2 框架对reduce端接收的[map任务输出的]相同分区的<k2,v2>数据进行合并、排序、分组。
2.3 框架调用Reducer类中的reduce方法,reduce方法的形参是<k2,{v2...}>,输出是<k3,v3>。一个<k2,{v2...}>调用一次reduce函数。程序员可以覆盖reduce函数,实现自己的逻辑。
2.4 框架把reduce的输出保存到HDFS中。
至此,整个reduce阶段结束。 例子:实现WordCountApp
MapReduce默认处理类
InputFormat
抽象类,只是定义了两个方法。
FileInputFormat
FileInputFormat是所有以文件作为数据源的InputFormat实现的基类,
FileInputFormat保存作为job输入的所有文件,并实现了对输入文件计算splits的方法。至于获得记录的方法是有不同的子类——TextInputFormat进行实现的。
TextInputFormat
是默认的处理类,处理普通文本文件
文件中每一行作为一个记录,他将每一行在文件中的起始偏移量作为key,每一行的内容作为value
默认以 或回车键作为一行记录
RecordReader
每一个InputSplit都有一个RecordReader,作用是把InputSplit中的数据解析成Record,即<k1,v1>。
在TextInputFormat中的RecordReader是LineRecordReader,每一行解析成一个<k1,v1>。其中,k1表示偏移量,v1表示行文本内容
InputSplit
在执行mapreduce之前,原始数据被分割成若干split,每个split作为一个map任务的输入。
当Hadoop处理很多小文件(文件大小小于hdfs block大小)的时候,由于FileInputFormat不会对小文件进行划分,所以每一个小文件都会被当做一个split并分配一个map任务,会有大量的map task运行,导致效率底下
例如:一个1G的文件,会被划分成8个128MB的split,并分配8个map任务处理,而10000个100kb的文件会被10000个map任务处理
Map任务的数量
一个InputSplit对应一个Map task
InputSplit的大小是由Math.max(minSize, Math.min(maxSize,blockSize))决定
单节点建议运行10—100个map task
map task执行时长不建议低于1分钟,否则效率低
特殊:一个输入文件大小为140M,会有几个map task?
FileInputFormat类中的getSplits
输入类-FileInputFormat源码分析:
1 if (isSplitable(job, path)) { 2 long blockSize = file.getBlockSize(); 3 long splitSize = computeSplitSize(blockSize, minSize, maxSize); 4 5 long bytesRemaining = length; 6 while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { 7 int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); 8 splits.add(makeSplit(path, length-bytesRemaining, splitSize, 9 blkLocations[blkIndex].getHosts(), 10 blkLocations[blkIndex].getCachedHosts())); 11 bytesRemaining -= splitSize; 12 }
什么是序列化,为什么要序列化
序列化 (Serialization)将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。 当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为对象。
把对象转换为字节序列的过程称为对象的序列化。
把字节序列恢复为对象的过程称为对象的反序列化。
说的再直接点,序列化的目的就是为了跨进程传递格式化数据
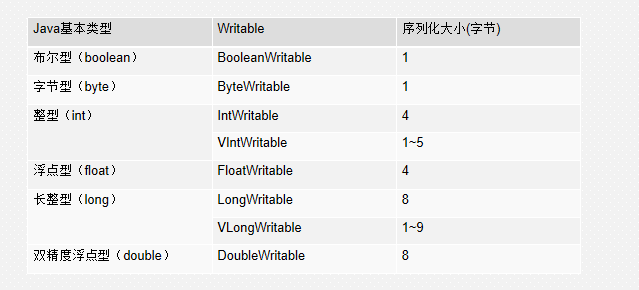
map-Reduce键值对格式
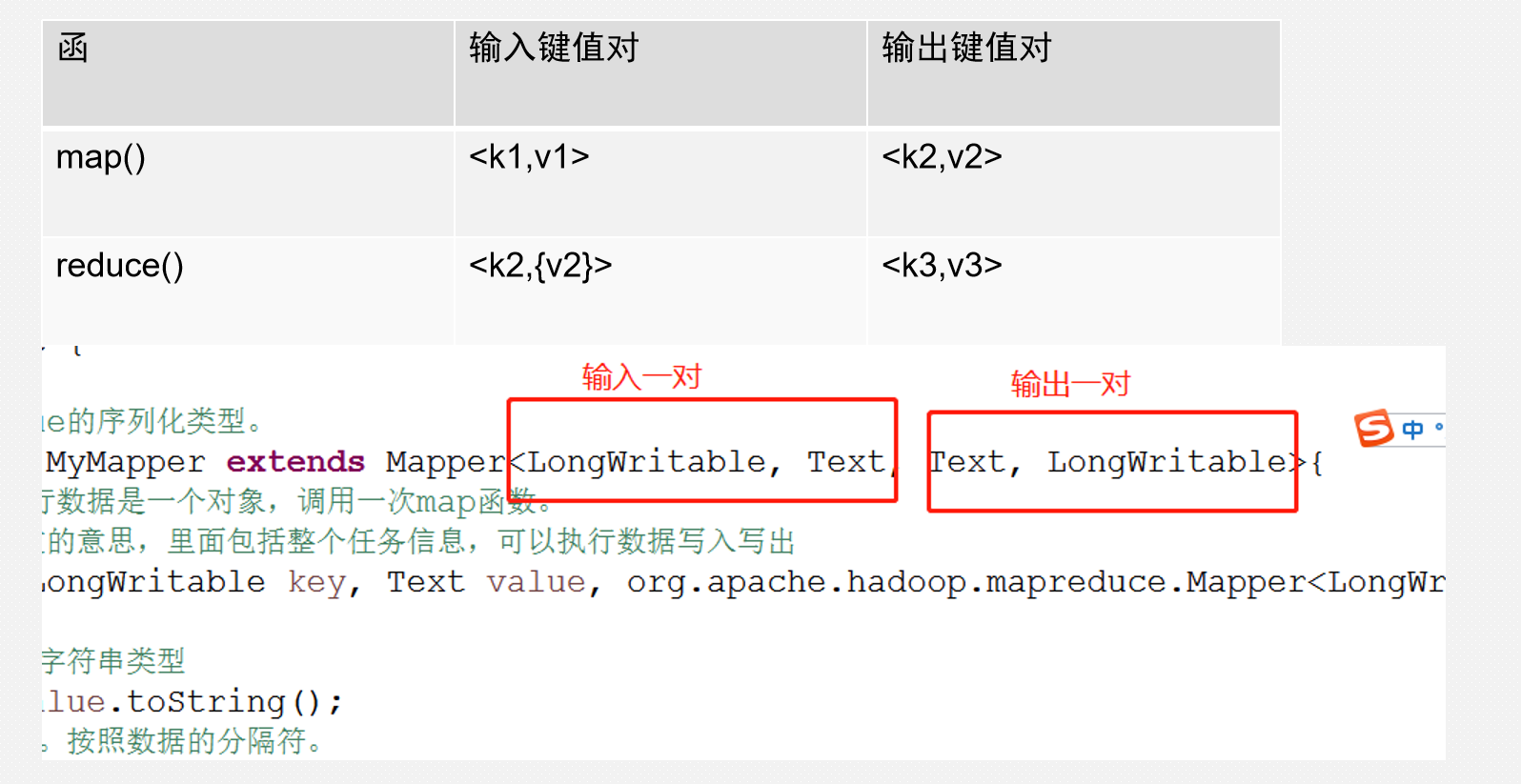
常用的数据类型在Hadoop中
补充一个,字符串类型是 Text
编写WordCount程序
该程序在大数据道路上就相当于学习Java时的 HelloWorld!!!!!!!!!!!
1 package com.wyh.shujia006; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.Path; 7 import org.apache.hadoop.io.LongWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Job; 10 import org.apache.hadoop.mapreduce.Mapper; 11 import org.apache.hadoop.mapreduce.Reducer; 12 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 13 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 14 15 /** 16 17 * 创建时间:2019年12月17日 下午3:14:11 18 19 * 项目名称:shujia006 20 21 * @author WYH 22 23 * @version 1.0 24 25 * @since JDK 1.8.0 26 27 * 文件名称:WordCount.java 28 29 * 类说明: 30 31 */ 32 33 public class WordCount { 34 //创建内部类 MyMap 35 public static class MyMap extends Mapper<LongWritable, Text, Text, LongWritable>{ 36 @Override 37 protected void map(LongWritable K1, Text V1, 38 Mapper<LongWritable, Text, Text, LongWritable>.Context context) 39 throws IOException, InterruptedException { 40 String s1 = V1.toString(); 41 String[] words = s1.split(","); 42 for(String word1 : words){ 43 Text word = new Text(word1); 44 context.write(word, new LongWritable(1l)); 45 } 46 } 47 } 48 49 //创建内部类MyReduce 50 public static class MyReduce extends Reducer<Text, LongWritable, Text, LongWritable>{ 51 @Override 52 protected void reduce(Text K2, Iterable<LongWritable> V2s, 53 Reducer<Text, LongWritable, Text, LongWritable>.Context context) 54 throws IOException, InterruptedException { 55 Long sum = 0l; 56 for(LongWritable V2 : V2s){ 57 sum += V2.get(); 58 } 59 context.write(K2, new LongWritable(sum)); 60 } 61 } 62 63 //主体函数 64 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 65 //加载hadoop的配置参数 66 Configuration conf = new Configuration(); 67 //创建任务的对象 68 Job job = Job.getInstance(conf, WordCount.class.getSimpleName()); 69 //========================================================================= 70 //设置打包的类 71 job.setJarByClass(WordCount.class); 72 //========================================================================= 73 //设置读取文件的hdfs路径 74 FileInputFormat.addInputPath(job, new Path(args[0])); 75 //========================================================================= 76 //指定需要执行的map类 77 job.setMapperClass(MyMap.class); 78 //指定map输出的序列化类 79 job.setMapOutputKeyClass(Text.class); 80 job.setMapOutputValueClass(LongWritable.class); 81 //========================================================================= 82 //指定需要执行的reduce类 83 job.setReducerClass(MyReduce.class); 84 //指定reduce的序列化类 85 job.setOutputKeyClass(Text.class); 86 job.setOutputValueClass(LongWritable.class); 87 //========================================================================= 88 //指定输出的hdfs路径 89 FileOutputFormat.setOutputPath(job, new Path(args[1])); 90 //========================================================================= 91 //提交任务,等待执行完成,并打印执行日志 92 job.waitForCompletion(true); 93 94 95 } 96 97 98 99 100 101 102 103 }
1、编写号之后,我们右击这个程序导出jar包
2、将jar包上传到Linux中

3、编写测试程序上传到HDFS中,我这里写的程序是以逗号分割的,可以更改。 上传命令是 hadoop fs -put 你要上传的文件路径 HDFS上的路径
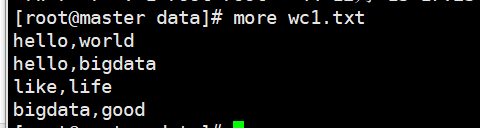
4、编写命令进行测试

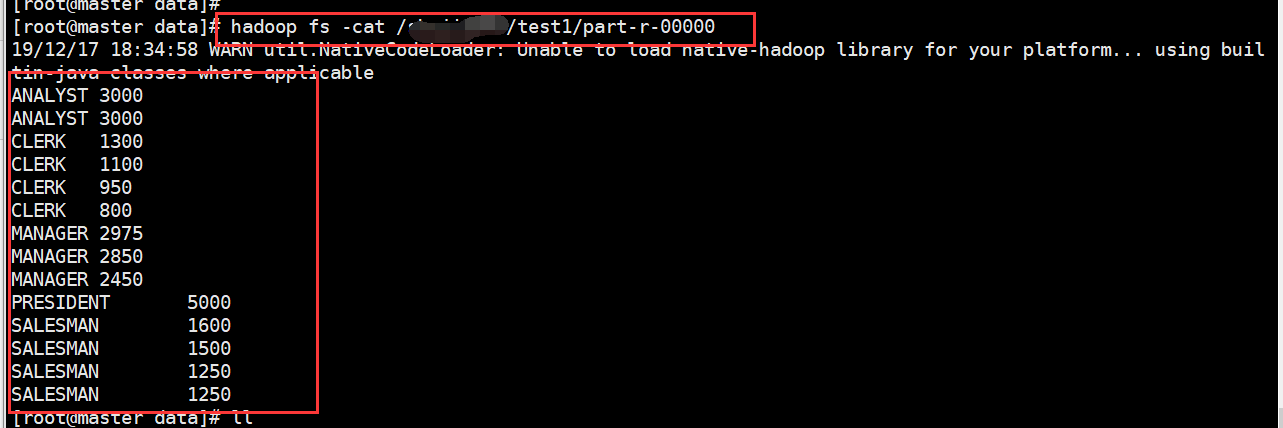
5、查看结果
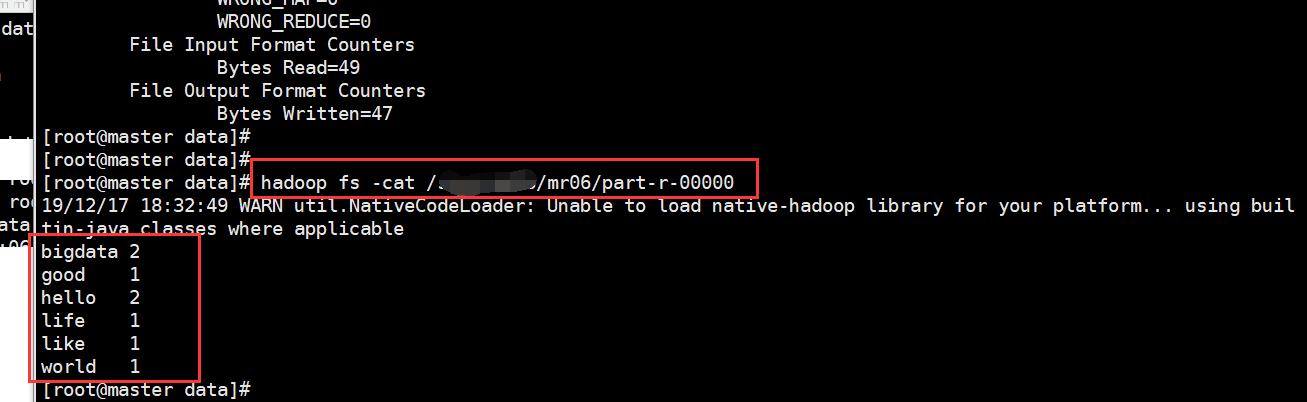
改进扩展:将员工数据拿出来,每个岗位的工资进行倒叙排序
1、编写代码
1 package com.wyh.shujia006; 2 3 import java.io.IOException; 4 import java.util.ArrayList; 5 import java.util.Arrays; 6 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.fs.Path; 9 import org.apache.hadoop.io.LongWritable; 10 import org.apache.hadoop.io.Text; 11 import org.apache.hadoop.mapreduce.Job; 12 import org.apache.hadoop.mapreduce.Mapper; 13 import org.apache.hadoop.mapreduce.Reducer; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 17 /** 18 19 * 创建时间:2019年12月17日 下午7:42:54 20 21 * 项目名称:shujia006 22 23 * @author WYH 24 25 * @version 1.0 26 27 * @since JDK 1.8.0 28 29 * 文件名称:test.java 30 31 * 类说明: 32 33 */ 34 35 public class test { 36 public static class empMap extends Mapper<LongWritable, Text, Text, LongWritable>{ 37 @Override 38 protected void map(LongWritable k1, Text v1, 39 Mapper<LongWritable, Text, Text, LongWritable>.Context context) 40 throws IOException, InterruptedException { 41 String line = v1.toString(); 42 String[] split = line.split(","); 43 Text job = new Text(split[2]); 44 LongWritable sal = new LongWritable(Long.parseLong(split[5])); 45 context.write(job, sal); 46 } 47 } 48 49 public static class empReduce extends Reducer<Text, LongWritable, Text, LongWritable>{ 50 @Override 51 protected void reduce(Text k2, Iterable<LongWritable> v2s, 52 Reducer<Text, LongWritable, Text, LongWritable>.Context context) 53 throws IOException, InterruptedException { 54 55 ArrayList<Long> arrays = new ArrayList<Long>(); 56 for(LongWritable sal : v2s){ 57 arrays.add(sal.get()); 58 } 59 //倒序(从大到小) 60 Object[] array = arrays.toArray(); 61 Arrays.sort(array); 62 for(int x = array.length-1;x>=0;x--){ 63 Long salss = (Long)array[x]; 64 context.write(k2, new LongWritable(salss)); 65 } 66 //顺序(从小到大) 67 /*for(Object sals : array){ 68 Long salss = (Long)sals; 69 context.write(k2, new LongWritable(salss)); 70 }*/ 71 } 72 } 73 74 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 75 Configuration conf = new Configuration(); 76 Job job = Job.getInstance(conf, test.class.getSimpleName()); 77 78 job.setJarByClass(test.class); 79 FileInputFormat.addInputPath(job, new Path(args[0])); 80 81 job.setMapperClass(empMap.class); 82 job.setMapOutputKeyClass(Text.class); 83 job.setMapOutputValueClass(LongWritable.class); 84 85 job.setReducerClass(empReduce.class); 86 job.setOutputKeyClass(Text.class); 87 job.setOutputValueClass(LongWritable.class); 88 89 FileOutputFormat.setOutputPath(job, new Path(args[1])); 90 job.waitForCompletion(true); 91 92 93 94 } 95 96 }
(忽略了打包上传过程同上)
2、进行测试