Hadoop 基本概念
一、Hadoop出现的前提环境
随着数据量的增大带来了以下的问题
(1)如何存储大量的数据?
(2)怎么处理这些数据?
(3)怎样的高效的分析这些数据?
(4)在数据增长的情况下如何构建一个解决方案?
在大数据领域提出了两个概念
(1)分布式文件系统 用于存储大量的数据
(2)分布式计算框架MapReduce高效的分析数据
以上的两个概念组成一个名词 Hadoop
二、Hadoop的起源
谷歌发布了三篇论文 : GFS 分布式存储系统 , MapReduce 分布式计算框架 , BigTable
Hadoop Google
HDFS GFS
MapReduce MapReduce
Hbase BigTable
三、Hadoop与其他的分布式系统比较
(1)Hadoop集群的数据首先先进行分布式的存储
(2)Hadoop集群上通过HDFS分布式文件系统,会把存储的数据复制多份,保证了数据的安全性
(3)提供了一个简单的易用的分布式计算框架
(4)Hadoop扩展容易
四、Hadoop中的版本
Hadoop存在版本的区别:
Hadoop1x版本中核心组件就是为 HDFS ,MapReduce
Hadop2x 版本依然存在HDFS,MapReduce,新增加了一个YARN
五、YARN介绍
(1)云操作系统,理解为资源管理器,管理集群中的资源在增加了YARN操作系统之后,MapReduce任务就可以跑在YARN平台上,通过YARN平台进行MapReduce任务的管理,资源的分配
(2)例如 也可以通过YARN平台运行Spark任务,包括可以读取HDFS上的数据文件
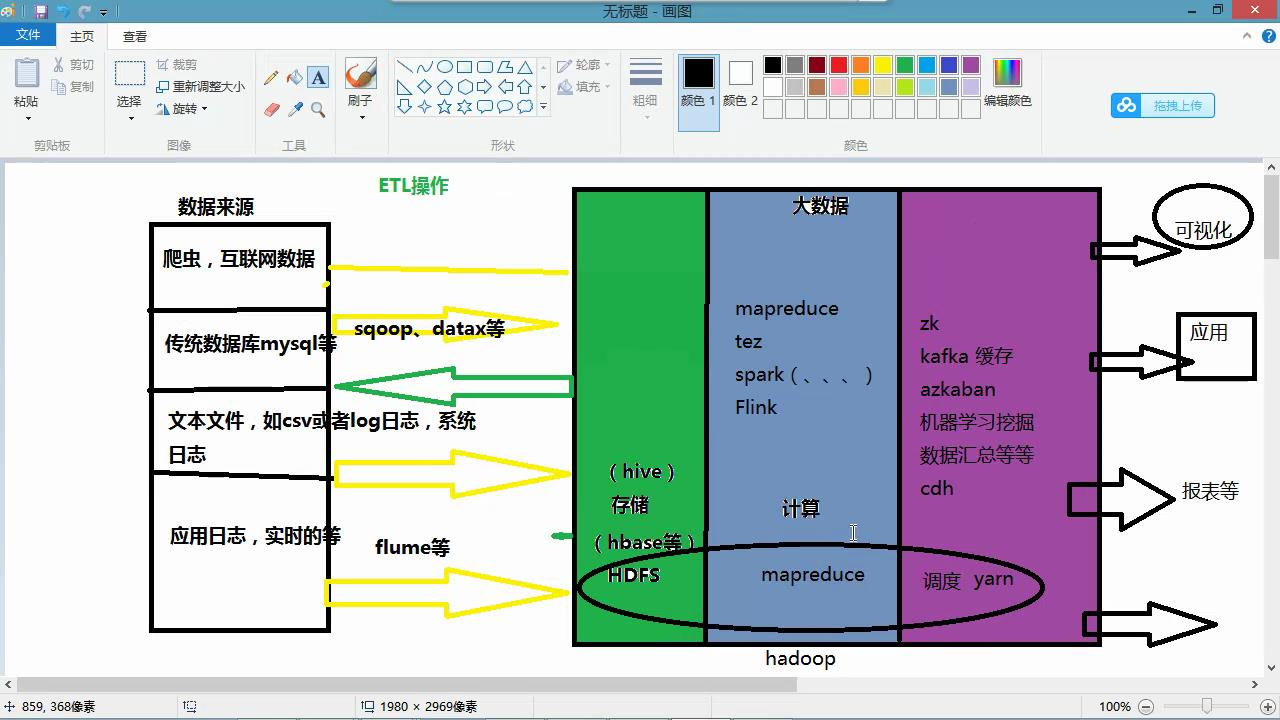
六、Hadoop生态圈的介绍
数据的来源,在企业中一般数据来源分为两种,第一种是企业内部的数据
例如:业务数据(保存在关系型数据库中),应用的服务器日志(日志文件),结构化数据
第二种是外部渠道获得:用户的行为记录(可以作为推荐系统的实现),通过搜索关键字,消费记录,爬虫技术,非结构化数据
数据要进行清洗 hive sqoop flume hbase hdfs mapreduce zookeeper
七、Hadoop的使用案例
现在使用Hadoop进行数据分析的公司越来越多,主要包括以下几种:
(1)为银行和信用卡公司进行欺诈性的检测
(2)社交媒体市场的分析
(3)电商网站的购物模式分析,用户行为分析
(4)城市的发展交通的模式识别
八、Hadoop的企业级应用主要包括四个层次
(1)存储层(HDFS Hbase)
(2)数据处理层 (Hive MapReduce)
(3)实时访问层(Spark Flink)
九、Hadoop中的组件信息
Hadoop中核心组件HDFS,YARN ,MapReduce
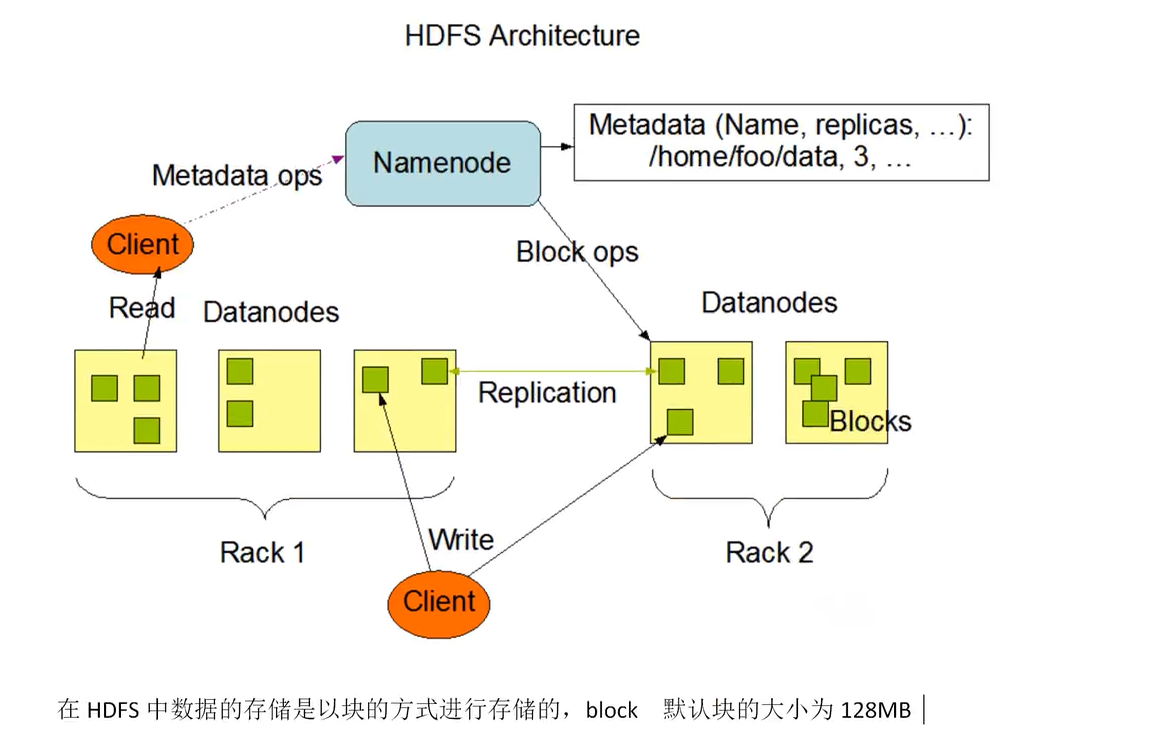
(1)HDFS架构
分布式存储系统,分布式的架构上存在 主/从 的架构关系在HDFS文件系统上存在主节点,以及从节点
主节点:namenode 负责管理HDFS集群文件中的元数据(文件的名称,文件的位置,文件的副本)
从节点:datanode负责存储真正的数据
(2)YARN架构
分布式的架构,分为主从架构
主节点 resourceManager负责管理集群中的所有资源(cpu,内存,磁盘,网络I/O)
从节点 nodeManager负责管理集群中每一台服务器的资源

(3)MapReduce 架构 核心思想 分而治之
Map端和Reduce端进行数据分析
数据在Map阶段进行分开处理,处理完成之后,再交给reduce进行统计,在Map和Reduce中间的阶段通过shuffle来进行连接。