前提工作:
克隆2台虚拟机完成后:新的2台虚拟机,请务必依次修改3台虚拟机的ip地址和主机名称【建议三台主机名称依次叫做:master、node1、node2 】 上一篇博客
(三台虚拟机都要开机)
Hadoop2.6.0 的压缩包,这里我提供百度云,没有的可以进行下载
链接:https://pan.baidu.com/s/1euN5AwSHHP-mqz4U_6ldEQ
提取码:jh1m
1、设置主机名与ip的映射,修改配置文件命令:vi /etc/hosts
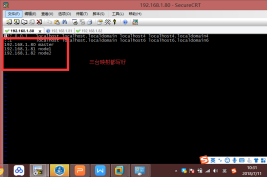
2、将hosts文件拷贝到node1和node2节点
命令:
scp /etc/hosts node1:/etc/hosts
scp /etc/hosts node2:/etc/hosts
3、上述修改完成后,请依次重启三台虚拟机:重启命令:reboot
4、关闭防火墙(三台都要操作),使用命令:service iptables stop
5、关闭防火墙的自动启动(三台都要操作),使用命令:chkconfig iptables off
6、设置ssh免密码登录(只在Master 这台主机操作)
主节点执行命令 ssh-keygen -t rsa 产生密钥 一直回车
执行命令
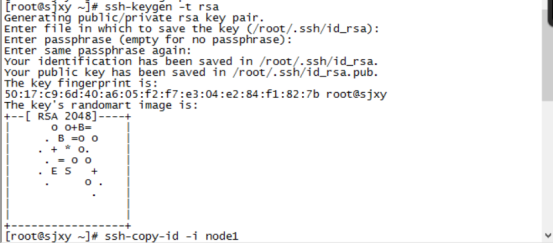
7、将密钥拷贝到其他两个子节点,命令如下:
ssh-copy-id -i node1
ssh-copy-id -i node2
实现免密码登录到子节点。
8、实现主节点master本地免密码登录
首先进入到/root 命令:cd /root
再进入进入到 ./.ssh目录下
命令:cd ./.ssh/

9、然后将公钥写入本地执行命令:
cat ./id_rsa.pub >> ./authorized_keys
如图

--------------------------------------------------------------------------以下操作都在master上进行-----------------------------------------------------------------------------------------------------------------------
10、将hadoop的jar包先上传到虚拟机/usr/local/soft目录下,主节点。可以使用xshell拖拽

11、解压。tar -zxvf hadoop-2.6.0.tar.gz 解压完后会出现 hadoop-2.6.0的目录

12、修改master中hadoop的一个配置文件/usr/local/soft/etc/hadoop/slaves
删除原来的所有内容,修改为如下(你的节点名称)
node1
node2

13、修改hadoop的几个组件的配置文件 进入cd /usr/local/soft/hadoop-2.6.0/etc/hadoop 目录下(请一定要注意配置文件内容的格式,可以直接复制过去黏贴。不要随意改 !!!!!!!!)
* 修改hadoop-env.sh文件
加上一句:
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171 (自己的jdk路径)

14、修改 core-site.xml
将下面的配置参数加入进去修改成对应自己的
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> //这里的master是我的主机名 </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/soft/hadoop-2.6.0/tmp</value> //你的Hadoop路径 </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property> </configuration>
15、修改 hdfs-site.xml 将dfs.replication设置为1 (因为我这里就只有一个主节点和两个子节点)
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
16、修改文件yarn-site.xml
1 <configuration> 2 <property> 3 <name>yarn.resourcemanager.hostname</name> 4 <value>master</value> //你的主机名 5 </property> 6 <property> 7 <name>yarn.nodemanager.aux-services</name> 8 <value>mapreduce_shuffle</value> 9 </property> 10 <property> 11 <name>yarn.log-aggregation-enable</name> 12 <value>true</value> 13 </property> 14 <property> 15 <name>yarn.log-aggregation.retain-seconds</name> 16 <value>604800</value> 17 </property> 18 <property> 19 <name>yarn.nodemanager.resource.memory-mb</name> 20 <value>20480</value> 21 </property> 22 <property> 23 <name>yarn.scheduler.minimum-allocation-mb</name> 24 <value>2048</value> 25 </property> 26 <property> 27 <name>yarn.nodemanager.vmem-pmem-ratio</name> 28 <value>2.1</value> 29 </property> 30 </configuration>
17、(将mapred-site.xml.template 复制一份为 mapred-site.xml
命令:cp mapred-site.xml.template mapred-site.xml) 然后修改 mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> //我的主节点名字叫master </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> //我的主节点名字叫master </property> </configuration>
18、将hadoop的安装目录分别拷贝到其他子节点
scp -r /usr/local/soft/hadoop-2.6.0 node1:/usr/local/soft/
scp -r /usr/local/soft/hadoop-2.6.0 node2:/usr/local/soft/
19、启动hadoop
首先看下hadoop-2.6.0目录下有没有tmp文件夹。
如果没有 执行一次格式化命令:
cd /usr/local/soft/hadoop-2.6.0目录下
执行命令:
./bin/hdfs namenode -format
会生成tmp文件。
20、/usr/local/soft/hadoop-2.6.0目录下
启动执行:./sbin/start-all.sh
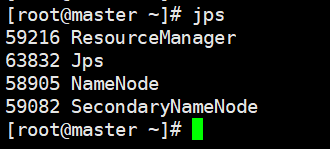
21、启动完成后通过jps命令查看验证进程:jps
主节点进程为下面几个(下面是进程名称,不是命令):
Namenode
secondarnamenode
resourcemanager
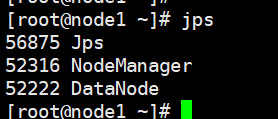
22、子节点进程 (在node1和node2上分别输入命令:jps)
datanode
nodenodemanager
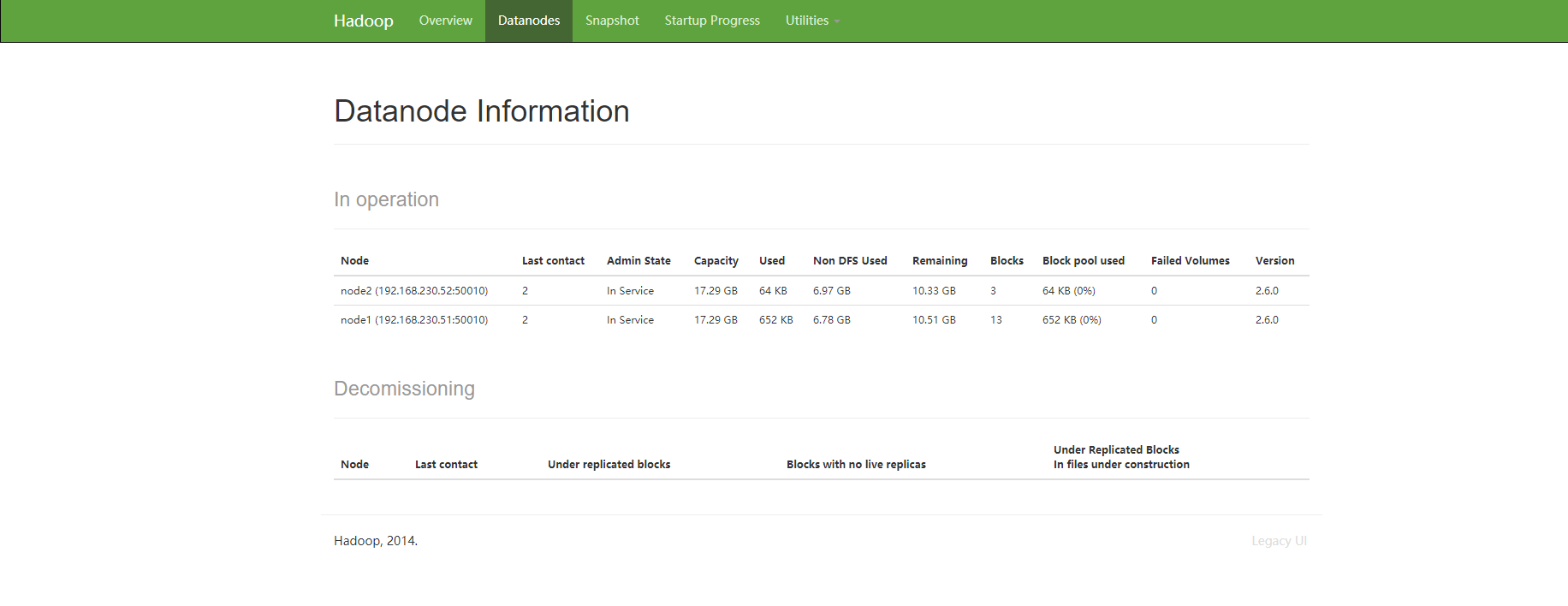
23、验证hdfs:
可以windows电脑登录浏览器(强烈建议chrome浏览器)
地址:192.168.1.80:50070 (ip地址是master的地址)
看到下面页面证明 hdfs装好了
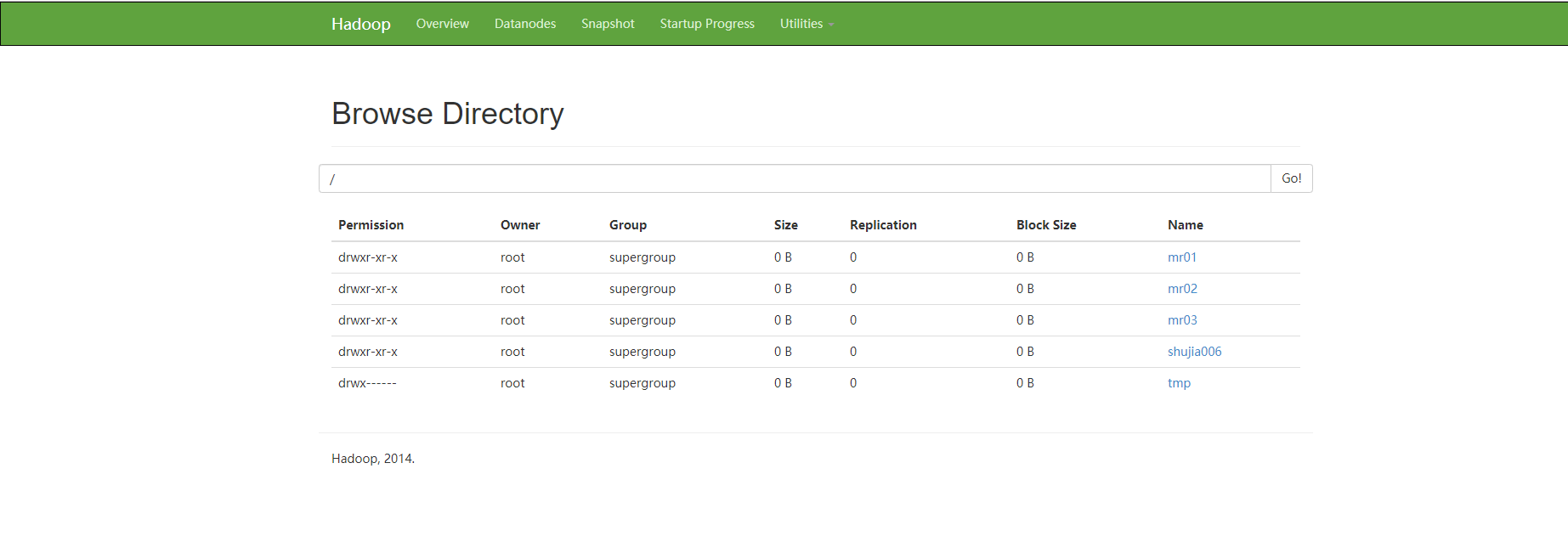
下图是我已经创建了一个hdfs上的目录,刚装好的hadoop应该是空的什么都没有
******* 如果第一次启动失败了,请重新检查配置文件或者哪里步骤少了。
再次重启的时候
1需要手动将每个节点的tmp目录删除:
rm -rf /usr/local/soft/hadoop-2.6.0/tmp
然后执行将namenode格式化
2在主节点执行命令:
./bin/hdfs namenode -format

如果在put文件的过程中出现了_COPYING_ could only be replicated to 0 nodes instead of minReplication (=1).
的报错
1 格式化重来
2 如果不行,看下时间,防火墙
3 修改 hosts文件,把里面那两条删了