既然是RPC, 自然就有客户端和服务器,当然,org.apache.hadoop.rpc也就有了类Client和类Server。在这里我们来仔细考察 org.apache.hadoop.rpc.Client。下面的图包含了org.apache.hadoop.rpc.Client中的关键类和关键 方法。
由于Client 可能和多个Server通信,典型的一次HDFS读,需要和NameNode打交道,也需要和某个/某些DataNode通信。这就意味着某一个 Client需要维护多个连接。同时,为了减少不必要的连接,现在Client的做法是拿ConnectionId(图中最右侧)来做为 Connection的ID。ConnectionId包括一个InetSocketAddress(IP地址+端口号或主机名+端口号)对象和一个用户 信息对象。这就是说,同一个用户到同一个InetSocketAddress的通信将共享同一个连接。
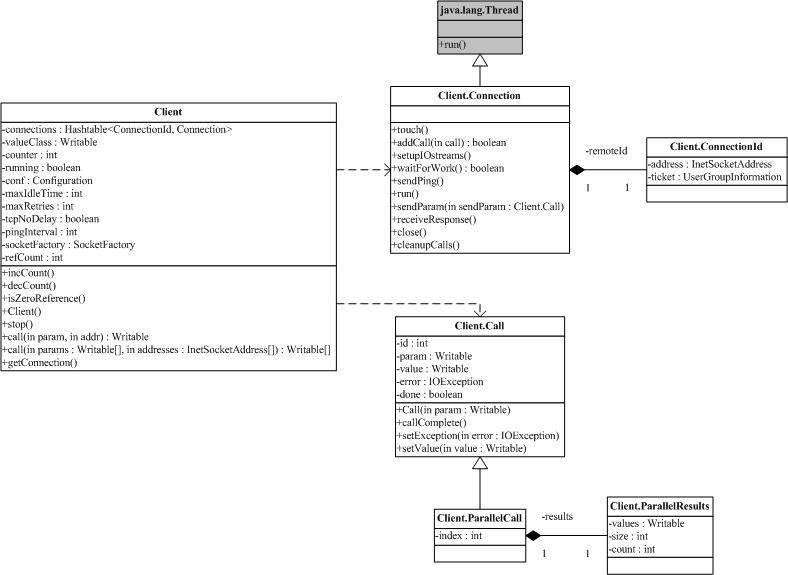
连接被封装在类Client.Connection 中,所有的RPC调用,都是通过Connection,进行通信。一个RPC调用,自然有输入参数,输出参数和可能的异常,同时,为了区分在同一个 Connection上的不同调用,每个调用都有唯一的id。调用是否结束也需要一个标记,所有的这些都体现在对象Client.Call中。 Connection对象通过一个Hash表,维护在这个连接上的所有Call:
- private Hashtable<Integer, Call> calls = new Hashtable<Integer, Call>();
一个RPC调用通过addCall,把请求加到Connection里。为了能够在这个框架上传输Java的基本类型,String和Writable接口的实现类,以及元素为以上类型的数组,我们一般把Call需要的参数打包成为ObjectWritable对象。
Client.Connection会通过socket 连接服务器,连接成功后回校验客户端/服务器的版本号(Client.ConnectionwriteHeader()方法),校验成功后就可以通过 Writable对象来进行请求的发送/应答了。注意,每个Client.Connection会起一个线程,不断去读取socket,并将收到的结果解 包,找出对应的Call,设置Call并通知结果已经获取。
Call使用Obejct的wait和notify,把RPC上的异步消息交互转成同步调用。
还有一点需要注意,一个Client会有多个Client.Connection,这是一个很自然的结果。