一:链表基础
1、链表基础----------------摘录自百度百科
在创建链表之前,我们需要需要了解一下专业术语:
首节点:存放第一个有效数据的节点;
尾节点:存放最后一个有效数据的节点;
头节点:头节点的数据类型与首节点的数据类型相同,并且头节点是首节点前面的那个节点,并不存放有效数据;头节点的存在只是为了方便链表的插入和删除等操作。
头指针:指向头节点的指针;
尾指针:指向尾节点的指针;
1、数据元素的存储结构形式有两种:顺序存储和链式存储。
顺序存储结构:是把数据元素存放在地址连续的存储单元里,其数据间的逻辑关系和物理关系是一致的。
链式存储结构:是把数据元素存放在任意的存储单元里,这组存储单元可以是连续的,也可以是不连续的。
很显然,这样说的话链式存储结构的数据元素存储关系并不能反映其逻辑关系,因此需要用一个指针存放数据元素的地址,这样子通过地址就可以找到相关联数据元素的位置。
2、数据元素之间的关系:
(1)集合关系
(2)线形关系
(3)树形关系
(4)图形关系
3、
算法是解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列,并且每条指令表示一个或多个操作。对于给定的问题,是可以有多种算法来解决的。
算法具有五个基本特征:输入、输出、有穷性、确定性和可行性。
(1)输入
算法具有零个或多个输入。
尽管对于绝大多数算法来说,输入参数都是必要的。但是有些时候,像打印“I love fishc.com”,就不需要啥参数啦。
(2)输出
算法至少有一个或多个输出。
算法是一定要输出的,不需要它输出,那你要这个算法来干啥?
输出的形式可以是打印形式输出,也可以是返回一个值或多个值等。
(3)有穷性
指算法在执行有限的步骤之后,自动结束而不会出现无限循环,并且每一个步骤在可接受的时间内完成。
一个永远都不会结束的算法,我们还要他来干啥?
(4)确定性
算法的每一个步骤都具有确定的含义,不会出现二义性。
算法在一定条件下,只有一条执行路径,相同的输入只能有唯一的输出结果。
算法的每个步骤都应该被精确定义而无歧义。
(5)可行性
算法的每一步都必须是可行的,也就是说,每一步都能够通过执行有限次数完成。
好的算法应该具备时间效率高和存储量低的特点。
4、
算法效率一般是指算法的执行时间,判断一个算法的效率时,函数中的常数和其他次要项常常可以忽略,而更应该关注主项(最高项)的阶数。
5、
算法时间复杂度的定义:在进行算法分析时,语句总的执行次数T(n)是关于问题规模n的函数,进而分析T(n)随n的变化情况并确定T(n)的数量级。
算法的时间复杂度,也就是算法的时间量度,记作:T(n)= O(f(n))。
它表示随问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同,称作算法的渐近时间复杂度,简称为时间复杂度。其中f(n)是问题规模n的某个函数。
一般情况下,随着输入规模n的增大,T(n)增长最慢的算法为最优算法。
6、怎么推导大O阶呢?
用常数1取代运行时间中的所有加法常数。
在修改后的运行次数函数中,只保留最高阶项。
如果最高阶项存在且不是1,则去除与这个项相乘的常数。
得到的最后结果就是大O阶。
[线性阶]
一般含有非嵌套循环涉及线性阶,线性阶就是随着问题规模n的扩大,对应计算次数呈直线增长。
int i , n = 100, sum = 0;
for( i=0; i < n; i++ )
{
sum = sum + i;
}
上面这段代码,它的循环的时间复杂度为O(n),因为循环体中的代码需要执行n次。
[平方阶]
刚才是单个循环结构,那么嵌套呢?
int i, j, n = 100;
for( i=0; i < n; i++ )
{
for( j=0; j < n; j++ )
{
printf(“I love FishC.comn”);
}
}
n等于100,也就是说外层循环每执行一次,内层循环就执行100次,那总共程序想要从这两个循环出来,需要执行100*100次,也就是n的平方。所以这段代码的时间复杂度为O(n^2)。
那如果有三个这样的嵌套循环呢?
没错,那就是n^3啦。所以我们很容易总结得出,循环的时间复杂度等于循环体的复杂度乘以该循环运行的次数。
刚刚我们每个循环的次数都是一样的,如果:
int i, j, n = 100;
for( i=0; i < n; i++ )
{
for( j=i; j < n; j++ )
{
printf(“I love FishC.comn”);
}
}
分析下,由于当i=0时,内循环执行了n次,当i=1时,内循环则执行n-1次……当i=n-1时,内循环执行1次,所以总的执行次数应该是:
n+(n-1)+(n-2)+…+1 = n(n+1)/2
大家还记得这个公式吧?恩恩,没错啦,就是搞死先生发明的算法丫。
那咱理解后可以继续,n(n+1)/2 = n^2/2+n/2
用我们推导大O的攻略,第一条忽略,因为没有常数相加。第二条只保留最高项,所以n/2这项去掉。第三条,去除与最高项相乘的常数,最终得O(n^2)。
[对数阶]
对数,属于高中数学内容啦,对于有些鱼油可能对这玩意不大理解,或者忘记了,也没事,咱分析的是程序为主,而不是数学为主,不怕。
int i = 1, n = 100;
while( i < n )
{
i = i * 2;
}
由于每次i*2之后,就距离n更近一步,假设有x个2相乘后大于或等于n,则会退出循环。
于是由2^x = n得到x = log(2)n,所以这个循环的时间复杂度为O(logn)。
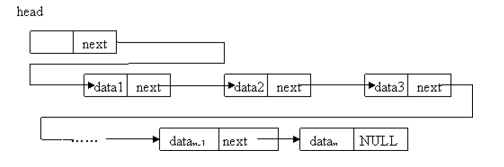
头指针
头指针是指链表指向第一个结点的指针,若链表有头结点,则是指向头结点的指针。
头指针具有标识作用,所以常用头指针冠以链表的名字(指针变量的名字)。
无论链表是否为空,头指针均不为空。
头指针是链表的必要元素。
头结点
头结点是为了操作的统一和方便而设立的,放在第一个元素的结点之前,其数据域一般无意义(但也可以用来存放链表的长度)。
有了头结点,对在第一元素结点前插入结点和删除第一结点起操作与其它结点的操作就统一了。
头结点不一定是链表的必须要素。
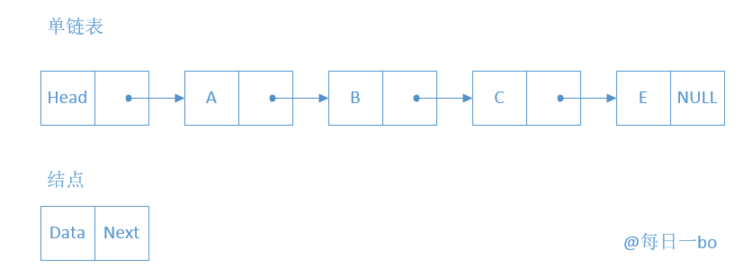
单链表图例:

单链表图例
空链表图例:

空链表图例
获得链表第i个数据的算法思路:
声明一个结点p指向链表第一个结点,初始化j从1开始;
当j<i时,就遍历链表,让p的指针向后移动,不断指向一下结点,j+1;
若到链表末尾p为空,则说明第i个元素不存在;
否则查找成功,返回结点p的数据。
单链表的插入
我们先来看下单链表的插入。假设存储元素e的结点为s,要实现结点p、p->next和s之间逻辑关系的变化,大家参考下图思考一下:

单链表的插入
我们思考后发觉根本用不着惊动其他结点,只需要让s->next和p->next的指针做一点改变。
s->next = p->next;
p->next = s;
我们通过图片来解读一下这两句代码。

单链表的插入
那么我们考虑一下大部分初学者最容易搞坏脑子的问题:这两句代码的顺序可不可以交换过来?
先 p->next = s;
再 s->next = p->next;
大家发现没有?如果先执行p->next的话会先被覆盖为s的地址,那么s->next = p->next其实就等于s->next = s了。
所以这两句是无论如何不能弄反的,这点初学者一定要注意咯~
单链表第i个数据插入结点的算法思路:
声明一结点p指向链表头结点,初始化j从1开始;
当j<1时,就遍历链表,让p的指针向后移动,不断指向下一结点,j累加1;
若到链表末尾p为空,则说明第i个元素不存在;
否则查找成功,在系统中生成一个空结点s;
将数据元素e赋值给s->data;
单链表的插入刚才两个标准语句;
返回成功。
代码示例:
单链表的删除
现在我们再来看单链表的删除操作。

单链表的删除
假设元素a2的结点为q,要实现结点q删除单链表的操作,其实就是将它的前继结点的指针绕过指向后继结点即可。
那我们所要做的,实际上就是一步:
可以这样:p->next = p->next->next;
也可以是:q=p->next; p->next=q->next;
单链表第i个数据删除结点的算法思路:
声明结点p指向链表第一个结点,初始化j=1;
当j<1时,就遍历链表,让P的指针向后移动,不断指向下一个结点,j累加1;
若到链表末尾p为空,则说明第i个元素不存在;
否则查找成功,将欲删除结点p->next赋值给q;
单链表的删除标准语句p->next = q->next;
将q结点中的数据赋值给e,作为返回;
释放q结点。
效率PK
我们最后的环节是效率PK,我们发现无论是单链表插入还是删除算法,它们其实都是由两个部分组成:第一部分就是遍历查找第i个元素,第二部分就是实现插入和删除元素。
从整个算法来说,我们很容易可以推出它们的时间复杂度都是O(n)。
再详细点分析:如果在我们不知道第i个元素的指针位置,单链表数据结构在插入和删除操作上,与线性表的顺序存储结构是没有太大优势的。
但如果,我们希望从第i个位置开始,插入连续10个元素,对于顺序存储结构意味着,每一次插入都需要移动n-i个位置,所以每次都是O(n)。
而单链表,我们只需要在第一次时,找到第i个位置的指针,此时为O(n),接下来只是简单地通过赋值移动指针而已,时间复杂度都是O(1)。
显然,对于插入或删除数据越频繁的操作,单链表的效率优势就越是明显啦~