10/11-10/16日短短五天,我和队友通过结对编程的方式完成了一个用来做“黄金点游戏”的小程序,项目地址:
https://github.com/ycWang9725/golden_point.git
黄金点游戏的基本规则
假设有M个玩家,P1,P2,…Pm
在 (0-100) 开区间内,所有玩家自由选择两个正有理数数字提交(可以相同或者不同)给服务器,
假设提交N11,N12,N21,N22,Nm1,Nm2等M*2个数字后,服务器计算:(N11+N12+N21+N22+…+Nm1+Nm2)/(M*2)*0.618 = Gnum,得到黄金点数字Gnum
查看所有玩家提交的数字与Gnum的算术差的绝对值,值最小者得M分,值最大者扣2分。其它玩家不得分
此回合结束,进行下一回合,多回合后,累计得分高者获胜。
我们的bot收到的输入是游戏当前轮和历史所有轮次的Gnum和所有玩家的预测值,输出两个对下一轮黄金点的预测值。
PSP表
在任务要求下达的当天晚上,我与队友两人便开始了讨论、设计与编码。
| PSP各个阶段 | 预估时间 | 实际记录 |
|
计划: 明确需求和其他因素,估计以下的各个任务需要多少时间
|
30 | 20 |
|
开发(包括下面 8 项子任务)
|
885 | 875 |
|
120 | 60 |
|
10 | 20 |
|
10 | 10 |
|
5 | 5 |
|
20 | 20 |
|
600 | 600 |
|
- | - |
|
120 | 180 |
| 报告 | 150 | 150 |
|
- | - |
|
30 | 30 |
|
120 | 120 |
| 总共花费时间 | 1065 | 1045 |
由于采用结对编程的工作方式,我们没有计划也没有经历代码复审阶段。需求分析阶段的预估时间和实际时间较长,是因为我与队友两人对强化学习(Q-learning方法)并不熟悉,因此将查找参考资料和学习的时间算了进去。我们的具体编码阶段并非完全用于编码,事实上,其中有大约2/3的时间在修改和验证算法的策略,我们将这些时间均算作此项。由于程序中bug大多在编码和验证过程中发现并修改,在测试阶段检测并修改的bug非常少,我们没有撰写测试报告。
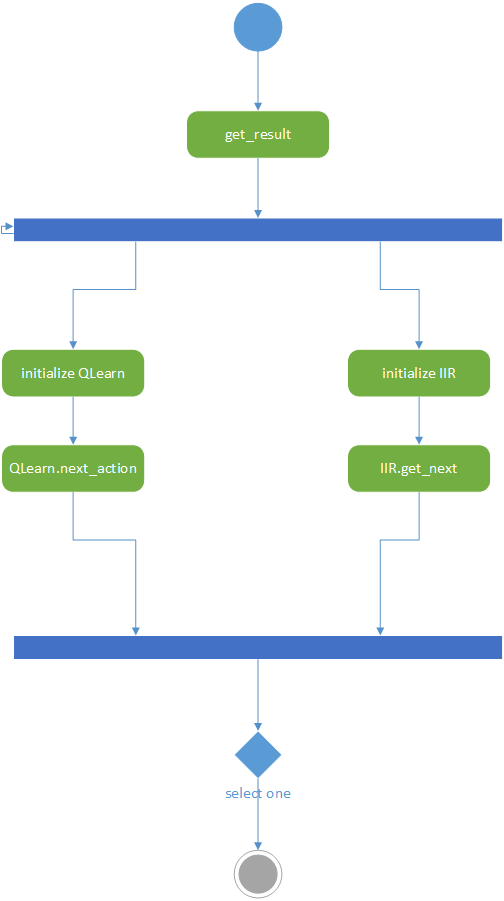
我们的bot
- get_numbers.py作为程序的输入输出接口,将程序外输入的历史数据传给Q-learning和IIR两个模型,获取两个模型的预测并根据两个模型的历史预测成功率选择其一输出。
- Q-learning模型(QLearning.py)。此模块维护一个Q-table,每步根据上一步的Gnum和Q-table得到概率最大的下一个Gnum,用softmax方法引入噪声后作为此模型对下一轮的预测,并根据当前轮Gnum更新Q-table。
- IIR滤波器(iir.py)。此模块根据游戏的历史黄金点对Gnum曲线进行滤波,得到平滑后的结果引入均匀分布的噪声后作为此模型对下一轮的预测。
get_numbers.py内部未定义类,包含的函数及功能:
| 函数 | 功能 |
| LineToNums(line, type=float) | 处理输入的历史数据行,得到可以被get_result()使用的数据结构 |
| get_result(history) | 将history数据输入到两个model之中,分别接收两个model的输出,用随机数的方式选择一个交给main()函数,并根据两个模型预测值的排名更新选择模型的阈值 |
| main() | main()函数调用前两个函数,作为与外界的输入输出接口 |
QLearning主要含一个class QLearn,包含的函数及功能(较为重要的用红色标出):
| 函数 | 功能 |
| __init__(self, load, load_path, test, bot_num, n_steps, epsilon_th, mode, rwd_fun, state_map, coding, multi_rwd) | 初始化一个QLearing对象,根据输入的参数在npy文件中load或初始化16个变量,它们被用来保存q-table, model预测的随机程度, model计算reward和rank的模式等 |
| update_epsilon(self) | 每次调用将会更新epsilon,若在预测中使用epsilon,则减小model输出随机数的可能性 |
| next_action(self, all_last_actions, curr_state) | 输入上一轮的Gnum和所有玩家的预测,调用uptate_q_table, update_epsilon, prob2action等函数,更新model的参数并输出model的预测值 |
| prob2action(self, prob) | 根据model的不同模式,输出由q_table和上一轮Gnum决定,加或不加softmax噪声的Q-table的action |
| action2outputs(self, last_action, last_gnum) | 将Q-table的action译码成输出值 |
| update_q_table(self, all_last_actions, curr_state) | 在不同模式下调用calculate_reward或calculate_multi_reward计算模型的reward,并借助Q-learning的更新公式更新q-table |
| calculate_reward(self, all_last_actions, curr_state) | 根据上一轮所有玩家的输出和Gnum,计算自己的排名,调用my_rank2score产生得分作为reward |
| rank2score(self, rank, n_bots) | 输入一个rank,根据模式的不同生成soft/norm-soft/soft-hard-avg类型的score |
| my_rank2score(self, my_rank, n_bots) | 调用rank2score,返回输入的rank list产生的score list |
| gnum2state(self, gnum) | 根据模式的不同,将输入的Gnum用不同的方式编码成Q-table的state |
| calculate_multi_reward(self, all_last_actions, curr_state) | 根据上一轮所有玩家的输出和Gnum,计算Q-table一个state的所有action的rank,由于action较多,采用了与calculate_reward中不同的计算排名的方法,调用my_rank2score产生得分作为reward |
| random_softmax(self, vector) | 用softmax的方法对输入的Q-table行进行加噪声的取Max,返回Q-table的action编号 |
IIR主要含一个class IIR,包含的函数及功能:
| 函数 | 功能 |
| __init__(self, alpha, noise_rate) | 初始化一个QLearing对象,在npy文件中load或初始化self.mem变量,它被用来保存Gnum的历史平滑值 |
| get_next(self, last_gnum) | 根据输入的上一轮Gnum和self.mem,计算出Gnum的滑动平均值并加均匀噪声输出 |
每次调用get_numbers.get_result()都将创建一个QLearing对象和一个IIR对象。然后分别调用QLearn.next_action()和IIR.get_next()得到两个输出,再根据历史表现二选一输出。
除此之外,我们还编写了几个用于测试的模块:test.py, plot_all.py, view_npy.py
我们的算法主要依赖于Q-table的学习,因此我们为它加了几个trick。
- 每次更新Q-table时,更新同一个state的所有action的概率。
- 将Q-table的state改为0.01-50的对数编码,因此在黄金点游戏很可能收敛到小值的前提下,固定state数目的Q-table可以获得更大的纵向精度
- 将Q-table的action改为0.3-3的对数差分编码,使得Q-table在同一个state下获得更大的横向精度,也使model的输出保持在上一轮黄金点的0.3-3倍范围内,保证了输出的稳定性。
- 不同于黄金点游戏的“赢者通吃”的得分规则,我们为Q-learning设计的reward是soft-reward,即是说让玩家的排名与得到的reward成线性关系,第一名得M分,最后一名得-2分,其余名次也可以得到(-2, M)的不等的分数。
事实上,除了上面的setting,我们还尝试了不同的更新策略、编码策略、reward策略,从中选择了表现最好的作为QLearning model的最终版本。
另外,在测试中我们发现,虽然为精度做了改进,但固定state和action的QLearning model还是无法很好地handle随着游戏进行Gnum收敛到波动范围在1%以下的情况,因此为了保证此类情况下bot的适应性,我们添加了一个IIR模型。IIR模型输出历史Gnum的滑动平均±最近十个Gnum的标准差区间内的均匀分布的随机数。我们在get_numbers.get_result()中设置了一个选择阈值,根据根据两个模型的上一轮预测是否进入前三名来更新阈值,并作为选择QLearning model/IIR model的依据。
UML
Code Contract
契约式设计的好处在于:能够将前提条件和后继条件以及不变量分开处理,明确了调用方和被调用方的权利与义务,避免了双方的权利或义务的重叠,有助于使得整体的代码条理更清晰、功能划分更明确、避免冗余的判断。在结对编程中,假设需要我和队友各自写具有相互调用关系的类时,双方都会在函数最开始用assert指出必须满足的前置条件,并对后继条件不符的情况进行异常处理,同时对于不变量进行检查。
代码规范
程序的代码规范主要是依靠Pycharm的内置代码规范。在结对编程活动的一开始,我们确定了使用python语言之后,就发现我们都非常喜欢Pycharm的代码规范,因此立刻确定了下来。
关于设计规范,我们尽量做到最小单元设计,即每个函数仅完成一项工作。这样写在我们后期调试模型的模式、添加/删改trick的时候显示了巨大的优势,让我们在修改时能够专心于算法的策略而非一边想算法一边重构代码。
由于本次结对编程任务比较单一,可能发生的异常情况也比较少,因此我们的异常处理主要是针对我们程序输出的结果加了保护使其在合规范围内,还有在测试过程中的异常处理,这个我们并没有花很多心思,只是pass掉了。
界面部分
本次结对编程任务主要是脚本输入输出,我们并没有为其适配UI,因此此部分略去。
结对的过程
Day 1
下午接到任务,两人都感到棘手,于是一起在吃饭的时候讨论了一下,当晚就开始了工作。
由于我们对强化学习并不熟悉,于是先一起学习了一下Q-learning的思想和算法。然后我们规划了一下接下来的工作方向,决定先实现最基础的Q-learning,state和action的都只有0-100均匀分布的100个,然后让我们的bot之间比赛,选择其中表现最好的。当时我和队友两人针对在实际比赛过程中是否需要实时train bot意见稍有不同,于是我们搁置分歧,决定先实现基本算法再说。这个问题在结对编程进行时自然而然地解决了,因为比赛时地Gnum走势与自己训练时不可能完全相同,所以放开让算法自己学习才是最好的。
然后我们开始设计实现Q-learning的伪代码,并将其转化成QLearn class的函数名(。。。)。这之后,我们试图将这些函数写满,实现最基本的Q-learning算法,但是时间有限只写了一部分就结束了。中间我们还尝试使用了模拟复盘程序。
Day 2
我们在这天晚上埋头工作四小时,实现了最基本的Q-learning算法。在使用模拟复盘程序查看效果的过程中,我们发现结果很差,但用C#编写的模拟程序调用我们的脚本,debug十分不方便,于是用python编写了test.py和view_npy.py来debug和查看Q-table。
然而,当我们做完这些后,仍然发现我们的bot仅仅停留在可以运行的状态,在模拟复盘程序中的表现十分辣眼。由于时间太晚,我们决定回去休息,周日再战。
Day 3
与联培班的其他同学奋斗在北京城郊另一战场。
Nothing Done.
Pass
Day -2
午饭后开始工作,由于我的公司的电脑断网,而我在周五晚上没有将代码传到云端或共享给队友,导致我们足不出户调算法的梦想几乎破灭,赶紧去公司共享给队友,再回去调。吸取这次教训,我决定以后每次工作完成都将代码共享给队友(然而并没有用,因为我的电脑总是断网,事实上后来的工作都是在队友的电脑上完成的)
依照最初的计划,我们先build了是个QLearn bot,让它们比赛。输出结果后发现txt形式的log肉眼是观察不出太多规律的,于是我们编写了plot_all.py脚本来观察每个bot的表现。
从此我们就开始了漫长的调QLearn模式的过程。
我们让自己的bot比了好多场,终于选出了一个效果最好的,决定让它到模拟复盘中跑一下。随着程序上得分的飞速跳跃,我们的心情非常复杂。
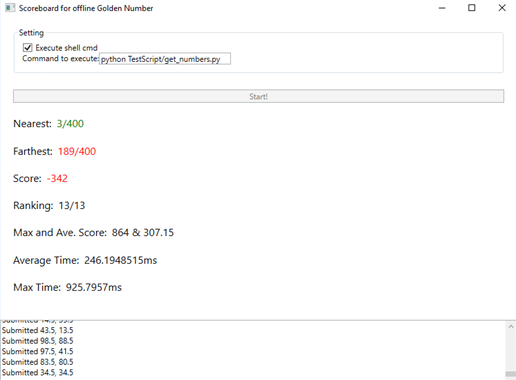
。。。
此时已经很晚了,我们赶紧debug查看Q-table,发现我们的Q-table更新过的值太少、太离散了,导致在比赛过程中我们的bot基本在瞎猜,很不靠谱,而且由于均匀分布在0-50的100个state和均匀分布在0-100的100个action,即使我们猜对了精度也只在小数点以前。
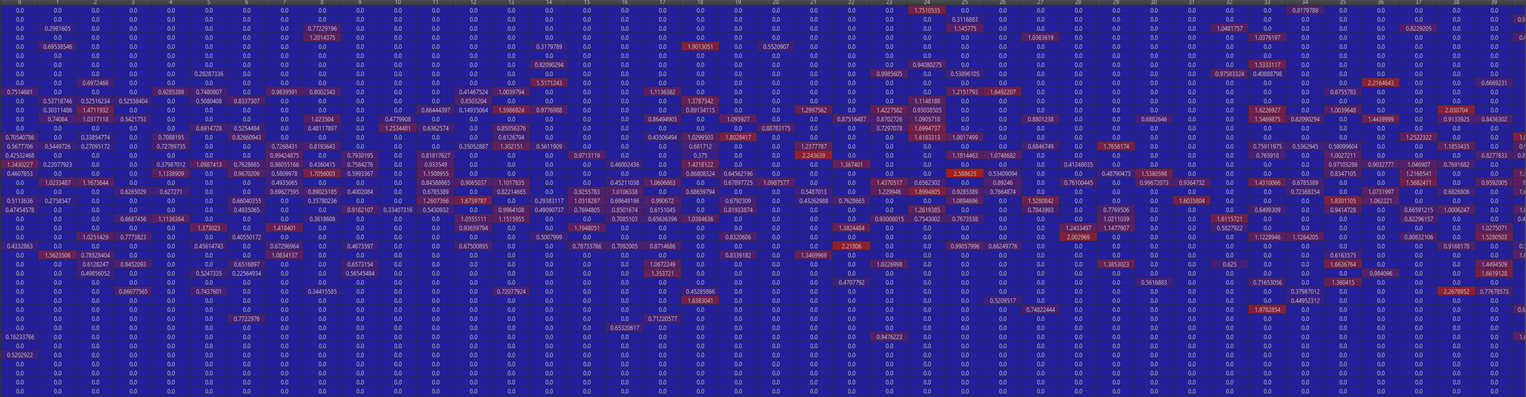
既然如此,优化算法势在必行。经过讨论,我们决定在两个方向优化算法:
- 模拟历史学习,增大Q-table更新的范围
- 对数编码Q-table,增大精度
有了优化方向,我们心情轻松下来,也感到了疲惫,于是决定明天再继续。
Day -1
这天我们感到非常紧张,晚上八点钟左右开始工作,一直做到凌晨两点(这里向被吵到的我和队友的室友表示歉意)。我们将之前想到过的所有想法都实现并尝试了,以至于QLearn class的初始化需要11个参数,如果我们当时还理智的话,就把他们包起来了,但当时我们两人都很感到很急,所以没有心思做这一点。还是需要改进,应该从init函数需要两个参数的时候就开始打包。
这晚我们的bot终于能够在模拟复盘程序中得分了,但我们分析提供的两轮数据发现,第一轮数据的Gnum收敛到波动<1%,而第二轮数据的波动可以超过100%,我们的bot在第二轮数据中表现不错,第一轮数据中的表现就差强人意。分析原因,虽然我们在Q-table上使用了对数编码,但是在黄金点收敛得数值较大且波动非常小时,精度仍然不够。此时已是凌晨一点多,我们决定临时加一个简单的滑动平均模型用来与Q-learning互补。
Day DDL!
当天我们发现了好几个bug,差一点就导致比赛的时候我们输出随机数了。。
下午调整好程序,保存了稳定版,其实又冒出了一些新想法,不过简单尝试后效果不好,也没时间优化了,就提交了稳点版。
比赛!
上半场比赛中我们的bot表现差强人意,中盘时我们观察别人的输出和黄金点的走势,总是不得要领,后来队友打开我们的Q-table发现,由于比赛数据与模拟数据的区别,我们的Q-table不能区分度很小,于是我们在softmax时增大了指数倍数(代码中*150的部分),使得输出的结果更接近于Q-table最大值所在的action。
def random_softmax(self, vector):
mean = np.mean(vector)
vector = vector - mean
vector = np.exp(vector * 150)
sum_exp = np.sum(vector)
vector = vector/sum_exp
accumulate_vector = 0
random = np.random.rand()
for i in range(np.size(vector)):
accumulate_vector += vector[i]
if random < accumulate_vector:
return i
return np.size(vector) - 1
下半场开始几十轮后我们的bot的表现像我们的预期一样开始走高,最终拿到第一名。我和队友都很开心。
总结这次结对编程,我感到收获非常大:
- 首先,我的队友非常优秀,我在与他合作过程中学习到了很多东西,例如在算法中使用数学思维,例如一些python工具的使用,例如代码设计,还有一款好用的文件管理app和一家味道不错的外卖店。
- 其次,这次的编程任务让我学习到了以前没有接触过的强化学习,并且实践了Q-learning算法,开阔了解决问题的思路。
- 而且,虽然这次结对编程过程中,我更多的时候是担任“领航员”的角色,代码主要是由队友敲出来的,但是我也深刻地体会到了结对编程实时复审代码的高效,和两人合作解决问题的奇妙之处
如果说结对编程有什么缺点,那就是在我们尝试是个bot比赛时跑一次需要20分钟,那时我们两人要一起干等,有点浪费时间。
讲一讲我认为的我们两人各自的优缺点:
我:
- 比较擅长查找参考资料
- 对代码的检查比较仔细
- 可以很快地想到现有模型的缺点
- 缺点:python代码量不够,numpy等包不是很熟,实际编码速度极慢
- 缺点:存在懒惰心理
队友:
- 代码、算法能力强
- 数学底子好,有将数学应用到算法中的思路
- 有把事情做到最好的习惯,不满足于中庸的结果
- 缺点:似乎不太愿意为编码的问题上网搜索,基本的数学函数没有用过会想要自己实现

学习Q-Learning过程中的参考资料
[1] CJCH Watkins, P Dayan, Q-learning, Machine learning, 1992 - Springe
[2] https://baijiahao.baidu.com/s?id=1597978859962737001&wfr=spider&for=pc(机器之心:通过 Q-learning 深入理解强化学习)