针对SRGAN提出的几点改进,获得了PIRM2018视觉质量的第一名。
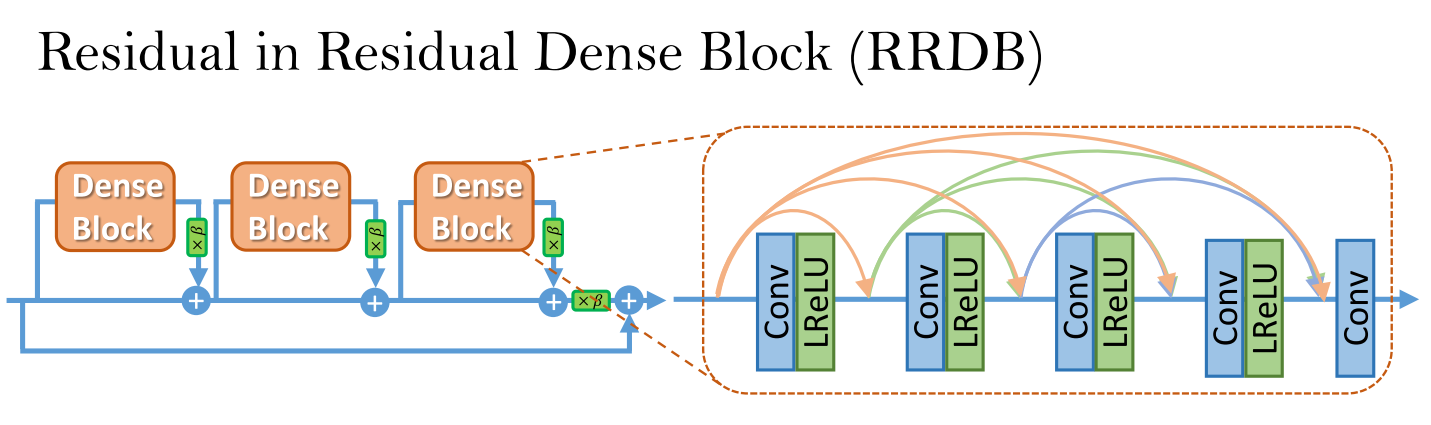
首先是使用去掉BN层的Residual in Residual Dense Block作为网络的basic unit。并且使用residual scling 和 smaller initialization帮助训练更深的网络。
第二点改进是使用了Relativistic Discriminator来预测真实图像$x_r$比生成图像$x_f$更真实的可能性,而不是简单判断某个图片是否是真实图像。$D_{R_a}(x_r, x_f)=sigma(C(x_r)-E_{x_f}[C(x_f)])$, $sigma$为sigmoid函数,$E_{x_f}[cdot]$是取mini-batch中所有fake data的平均, $C(x)$为non-transformed discriminator的输出。那么GAN的loss就对应为:
$L_D^{Ra}=-E_{x_r}[log(D_{Ra}(x_r, x_f))]-E_{x_f}[log(1-D_{Ra}(x_f, x_r)], L_G^{Ra}=-E_{x_r}[log(1-D_{Ra}(x_r, x_f))]-E_{x_f}[log(D_{Ra}(x_f, x_r))]$这样的loss使得generator可以同时从生成数据和真实数据的梯度中受益。
第三点改进是在loss中使用activation之前的特征,而不是使用activation后的特征。特征经过activation后非常的稀疏,特别是对于网络深度深的情况。实验发现使用activation后的特征会造成亮度上的不一致。


训练时先训练一个PSNR-oriented 网络$G_{PSNR}$再用fine-tuning的方法获得一个GAN-based 网络$G_{GAN}$。这样的方式可以避免generator落入local optima,使discriminator最开始就得到相对好的图像帮助他更关注于区分纹理从何得到视觉上更好的效果。为了平衡$G_{PSNR}$和$G_{GAN}$的效果,使用了network interpolation。作者也尝试使用其他两种方法:直接interpolate输出图像,这种方法无法达到a good trade-off between noise and blur;调整content loss和adversarial loss之间的权重,这种方式需要对网络进行微调,过于costly。