dynamic inference指的是根据输入调整预测的过程,通过对简单样本减少计算开销来减少总的开销。这篇文中就是dynamic inference方面的一个工作。将静态CNN模型转换为支持dynamic inference的模型后,通过NAS进行搜索,这种方法可以generalize到大部分的CNN结构中,并且最终得到的网络也可以使用现有的深度学习框架部署到硬件设备中。
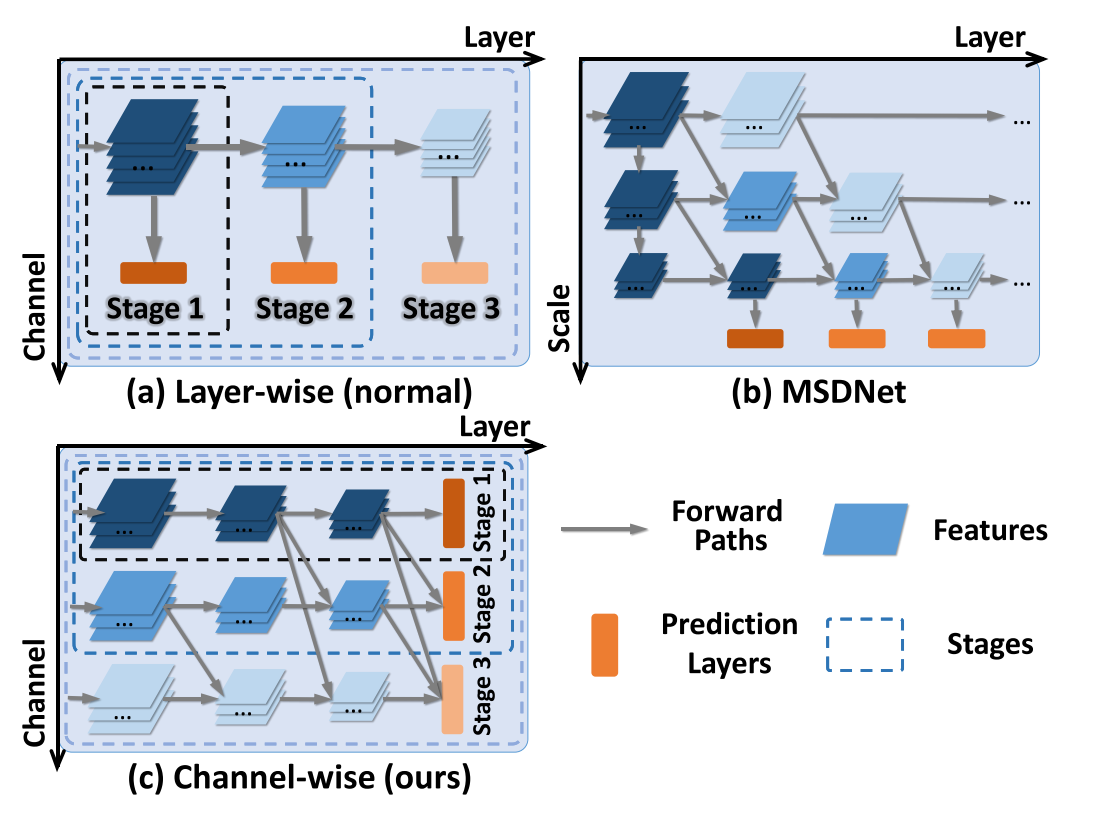
最初的dynamic inference方法通过设计一些策略动态地跳过一些操作(比如通过在原模型中加入额外的controller),这种方法的缺点是在channel level或spatial level引入了不规则的计算,使得在现有的软件和硬件中计算不高效。针对这一缺点,有人提出直接跳过某些层的方法,但这种方法只能应用于残差网络中。之后产生了一种“early exiting”的方法,就是在CNN中的不同层加入中间预测层,当中间预测层的预测置信度大于某一阈值时就直接退出。这种方法的缺点是浅层stage的分类器无法利用网络深层的语义层面的特征信息。MSDNet在这一缺点上做出改进,引入了一个二维多尺度的结构,保留了各层粗细粒度的特征信息,但这种方法需要对网络结构进行特殊设计不能generalize到其他CNN结构中。
本文是在MSDNet的基础上提出的一种方法,称为S2DNAS。按照channel将网络划分为多个stage,只有最后一层有prediction层。包括两个模块:S2D,将网络从静态转为动态结构;NAS,使用强化学习算法在动态结构中搜素最优结构。
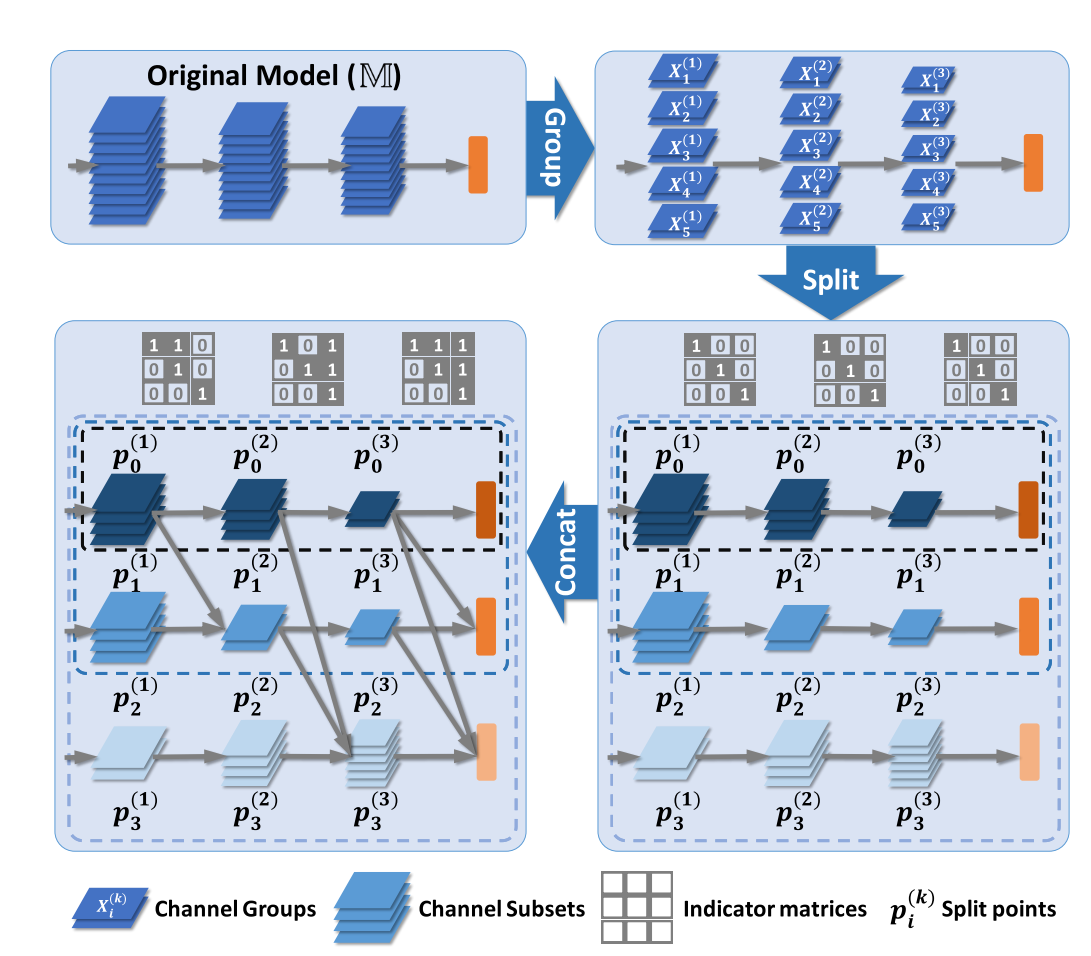
S2D模块包含两个操作:split和concat。
split操作将模型按照channel划分为多个子集,并分配到每个stage的分类器中。为了减小后续的搜索空间,按组进行划分。$p_i^{(k)}$表示第k层第i个stage的划分点。
concat操作使用一个indicator matrics来指示是否使用某个位置的feature。$m_{ij}^{(k)}inI^{(k)}$表示在第j个stage使用第i个stage第k层的特征,$m_{ij}^{(k)}=0, j<i, forall k<L$
NAS模块用基于policy gradient 的强化学习算法,优化目标可以形式化的表示为:其中$pi$为policy, $ heta_a$为模型a的权重, R为reward function
 这包含了两个问题:在$ heta_a*$固定时优化$pi$, 在结构a固定时优化$ heta_a$。第一个问题使用一个customized RNN为CNN模型的每一层生成不同transformation settings的分布, 再用policy gradient based algorithm优化RNN中的参数以最大化reward $R(a, heta_a, D)=ACC(a, heta_a, D) imes COST(a, heta_a, D)^w$。模型确定之后优化模型权重使用损失函数$L=sum_{(s, y)in D_{train}}sum_{i=1}^{s}alpha_iCE(f_i(x, heta_a), y)$, CE为交叉熵。
这包含了两个问题:在$ heta_a*$固定时优化$pi$, 在结构a固定时优化$ heta_a$。第一个问题使用一个customized RNN为CNN模型的每一层生成不同transformation settings的分布, 再用policy gradient based algorithm优化RNN中的参数以最大化reward $R(a, heta_a, D)=ACC(a, heta_a, D) imes COST(a, heta_a, D)^w$。模型确定之后优化模型权重使用损失函数$L=sum_{(s, y)in D_{train}}sum_{i=1}^{s}alpha_iCE(f_i(x, heta_a), y)$, CE为交叉熵。
本文在ResNet,VGG,MobileNetv2上都机型了实验,选用数据集CIFAR10和CIFAR100。并选择了训练集中的10%的数据作为validation set。与LCCL, BlockDrop, Naive, BranchyNet, MSDNet进行比较。结论:
- 一些方法(如BlockDrop)甚至由于增加了controller而增加了computational cost
- 一些方法只能应用于有残差连接的网络
- 与MSDNet相比,相同FLOPS下表现很接近, 15MFLOPS之后开始比不上MSDNet。但是MSDNet需要人工对网络结构进行设计,而S2DNAS可以应用于多种CNN
- threshold setting $t=t_1, ..., t_s$的影响:对于所有网络, computational cost的增加都可以带来表现的提升。因此在实际使用中,可以根据conputational budget来设置threshold。
- 查看了测试集样本在什么阶段退出模型,ResNet20 on CIFAR10/100有50%在前两个stage退出。前一阶段的准确率比后一阶段准确率要搞,说明早退出的样本时比较简单的,也说明了简单样本可以需要更少的计算资源。