知识内容:
1.数据库系统概述
2.关系数据库的系统模型与设计理论
3.数据库设计方法
4.结构化查询语言SQL
5.SqlServer数据库系统与SqlServer系统应用及管理
6.Transact-SQL语言结构及Transact-SQL程序设计
7.数据库安全与维护
一、数据库系统概述
1.基本概念
- DB(数据库):存储数据的容器(相关数据的集合)
- DBMS(数据库管理系统):对数据库系统进行管理的软件系统
- DBS(数据库系统):DB+DBMS
- 数据模型:层次模型、网状模型、关系模型
- 数据库系统三级模式:模式(概念模式)、外模式(用户模式、数据库中的视图)和内模式
- 数据库系统二级映射:外模式与模式之间的映射、模式与内模式之间的映射
- 数据管理技术的四个阶段:人工管理阶段、文件管理阶段、数据库系统阶段和高级数据库系统阶段
2.数据库系统的特点
- 数据库中数据是结构化的
- 数据冗余度小,易扩充
- 较高的数据和程序独立性
- 数据库为用户提供了方便的接口
- 数据的最小存取单位是数据项
3.物理独立性和逻辑独立性
物理独立性:依赖于数据的存储结构与逻辑结构之间的关系,当数据存储结构改变时,数据的逻辑结构不用改变,从而应用程序不用改变
逻辑独立性:依赖于数据的总体逻辑结构与某类应用涉及的局部逻辑结构之间的关系,当总体逻辑结构改变时,局部逻辑结构可以不变
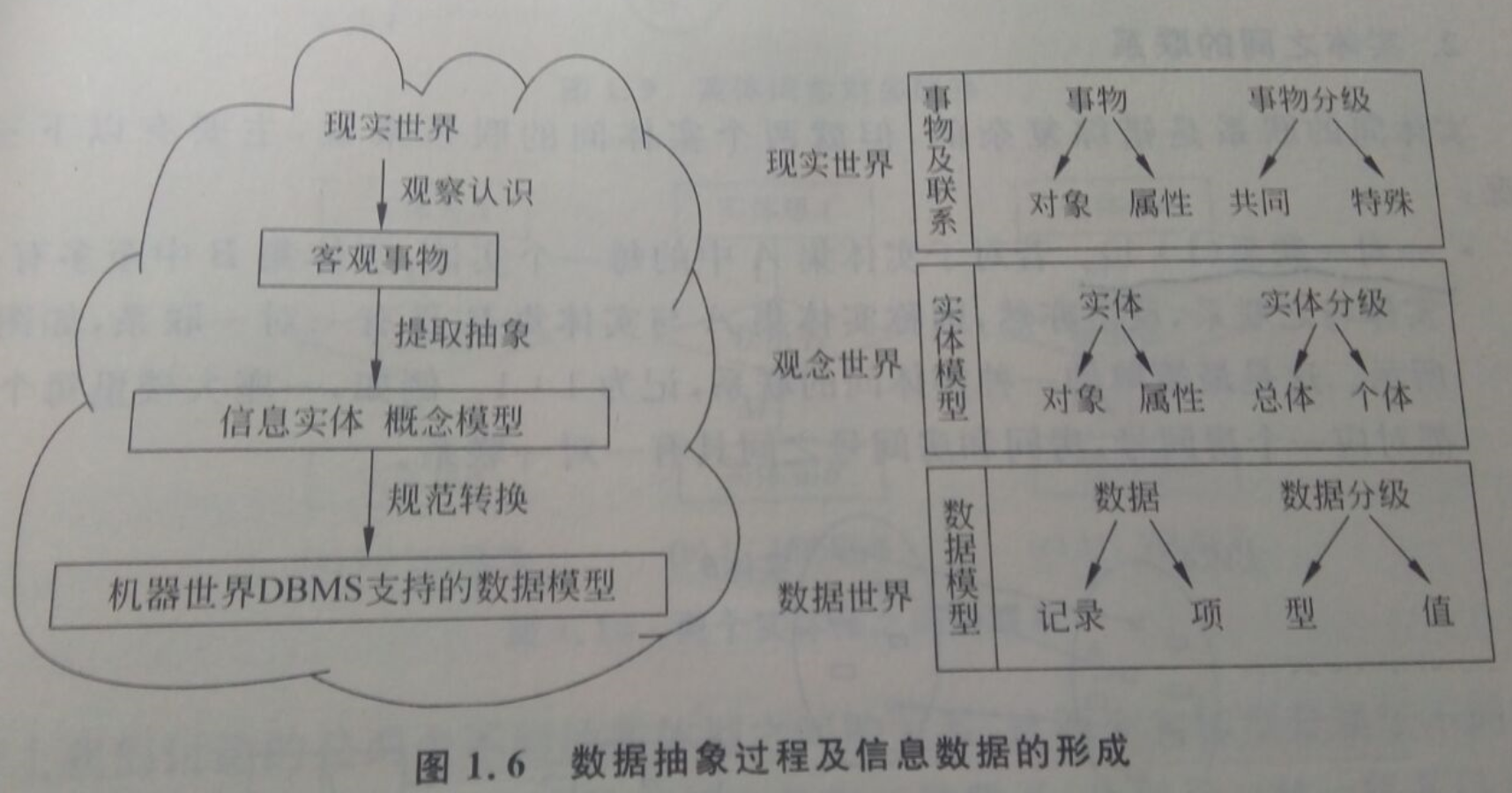
4.概念模型
概念模型是对现实世界的抽象反映,它不依赖于具体的计算机系统,是现实世界到机器世界的一个层次
5.DBMS(数据库管理系统)的功能
- 数据库定义功能
- 数据存取功能
- 数据库运行功能
- 数据库的建立和维护功能
- 数据字典
二、关系数据库的系统模型与设计理论
1.关系模型的组成部分
- 数据结构
- 关系操作
- 关系的完整性
2. 关系的完整性
- 实体完整性
- 参照完整性
- 用户定义的完整性
3.传统的集合运算与专门的关系运算
集合运算:
- 并:∪
- 差:-
- 交:∩
关系运算:
- 选择运算:
- 投影运算:
- 连接运算:
- 自然连接:
4.实体之间的关系
- 一对一关系(1:1)
- 一对多关系(1:m)
- 多对多关系(m:n)
5.函数依赖
- 部分函数依赖:单主键情况下不存在部分函数依赖;(A,B)->C,B->C为部分函数依赖,例如学号和课程名可以得出姓名,但是学号也可以得出姓名,这是部分函数依赖
- 传递函数依赖:A->B,B->C,B不->A(B不属于A)为传递函数依赖,例如学号可以得出系名,系名可以得出系主任名,但是系名不可以得出学号,这是传递函数依赖
6.范式
- 第一范式(1NF):关系中的属性为原子项,不可再分
- 第二范式(2NF):不存在部分依赖
- 第三范式(3NF):不存在部分依赖,不存在传递依赖
7.关系模式的分解
(1)保持函数依赖分解
类似以下的分解就是保持函数依赖的分解
R(A, B, C): A->B、B->C 分解为 R1(A,B)、R2(B,C)
注:冗余的依赖不需要保持下来!
实例:

1 例如2NF关系模式SL(Sno,Sdept,Sloc)中有下列函数依赖:
2 Sno→Sdept
3 Sdept→Sloc
4 Sno→Sloc
5
6 由于关系模式SL存在传递函数依赖,会出现插入异常、数据冗余、删除异常等问题
7
8 关系模式SL出现上述问题的原因是Sloc传递函数依赖于Sno。为了消除该传递函数依赖,我们可以采用投影分解法(保持函数依赖分解),把SL分解为两个关系模式:
9 SL(Sno,Sdept,Sloc)
10 SD(Sno,Sdept) SD的码为Sno
11 DL(Sdept,Sloc) DL的码为Sdept
(2)无损分解(可以还原)
无损分解:指将一个关系模式分解成若干个关系模式后,通过自然连接和投影等运算仍能还原到原来的关系模式
实例:
1 学生(学号, 姓名, 性别, 专业号, 专业名)
2 这个关系模式明显存在问题,主键为学号和专业号,但是存在部分函数依赖
3
4 解决这些问题的方法就是采取无损分解将以上的关系模式分解为两个关系模式:
5 学生(学号,姓名,性别,专业号)
6 专业(专业号,专业名)
三、数据库设计方法
1.数据库系统的设计过程
- 需求分析:数据流图、数据字典、需求说明书
- 概念设计:E-R图
- 逻辑设计:关系模式
- 物理设计
- 数据库的实施
- 数据库的运行和维护
2.命名冲突
- 同名异义
- 异名同义
3.概念模型向关系模型的转换
- 一个实体类型转化成一个关系模式 eg: 学生 -> 学生(学号,姓名,系别,专业、、、)
- 一个一对一(1:1)联系至少转化成两个关系模式
- 一个一对多(1:n)联系至少转化成两个关系模式
- 一个多对多(m:n)联系转化成至少转化成三个关系模式
4.非规范化的关系模式的问题
- 数据冗余
- 更新异常
- 插入异常
- 删除异常
四、结构化查询语言SQL
1.SQL定义索引
定义索引:
1 CREATE [UNIQUE] INDEX 索引名 ON 基表名 2 (列名1 [ASC/DESC][, 列名2 [ASC/DESC]]...)
实例:
1 CREATE UNIQUE INDEX XID_card ON Student(ID_Card DESC) 2 CREATE UNIQUE INDEX XID_card ON Student(ID_Card DESC, Sschool_number ASC)
2.select查询语句
select语句:
1 SELECT [all|distinct|top] 列名1,列名2... 2 FROM 表名/视图名 3 [WHERE 条件表达式] 4 [ 5 GROUP BY 分组列 6 [HAVING 分组筛选条件表达式] 7 ] 8 [ORDER BY 列名1 [ASC|DESC], 列名2 [ASC|DESC]... ] 9 以上[]中的内容为可选,语法中的第一行用于指定查询结果需要返回的列: 可以逐个列出所有列名 10 也可以用*表示返回所有列
关于select语句中的条件表达式:条件表达式有许多种,常见的有算术运算符(+、-、*、/),逻辑运算符(AND、OR、NOT)和比较运算符(=、>、>=、<、<=、<>)
还有如下形式:
- <列名> IS [NOT] NULL:列值是否为空
- <表达式1> [NOT] BETWEEN <表达式2> AND <表达式3>:表达式1的值是否在表达式2和表达式3之间
- <表达式> [NOT] IN (目标表列):表达式的值是否是目标表列中的一个值
- <列名> [NOT] LIKE <'字符串'>:列值是否包含在字符串中 字符串可以用通配符(?和_表示任一字符,*和%表示任一串字符)
3.视图的优点
- 使用户操作数据更灵活、方便
- 视图对于数据库的重构造提供了一定程度的逻辑独立性
- 简化了用户观点
- 使用户以不同的方式看待同一数据
- 对机密数据提供了自动的安全保护功能
4.授权语句与撤销授权语句
GRANT语句:授权
REVOKE语句:回收授权
1 授权语句
2 GRANT 权力1[,权力2…][ON 对象类型 对象名]TO 用户1[,用户2…][WITH GRANT OPTION];
3
4 回收授权语句
5 REVOKE 权力1[,权力2…] [ON 对象类型 对象名] FROM 用户1[,用户2…];
实例:
1 GRAND UPDATE(学号),SELECT ON TABLE 学生 TO USER1; 2 GRAND SELECT ON TABLE 成绩单 TO PUBLIC; 3 REVOKE UPDATE(学号),SELECT ON TABLE 学生 FROM USER1; 4 REVOKE SELECT ON TABLE FROM PUBLIC;
五、SqlServer数据库系统与SqlServer系统应用及管理
1.SqlServer数据库文件分类
- 主要数据文件(.mdf)
- 次要数据文件(.ndf)
- 日志文件(.ldf)
- 每个数据库都必须有一个主要数据文件,对次要数据文件不做要求,每个数据库最少有一个日志文件
2.SqlServer系统数据库
SqlServer系统数据库包含以下数据库(以SqlServer2014为例):
- master
- model
- msdb
- tempdb
3.增删改查
(1)增-INSERT语句
格式:
INSERT table_name (column_list) VALUES (expression)
实例:
1 INSERT INTO 2 users(username,password,email) 3 VALUES 4 ("wyb", "xxx", "abc@woz.cc");
(2)改-UPDATE语句
格式:
UPDATE table_name
SET column_name = expression, 、、、
WHERE search_condition
实例:
1 UPDATE 2 users 3 SET 4 email='xxx', username='xxx' 5 WHERE 6 `id`=6
(3)删-DELETE语句
格式:
DELETE FROM table_name WHERE search_condition
实例:
1 DELETE FROM 2 users 3 WHERE 4 id=3
(4)查-SELECT语句
格式:
SELECT select_list
[INTO new_table]
FROM table_source
[WHERE search_condition]
[GROUP BY group_by_condition]
[HAVING search_condition]
[ORDER BY order_expression [ASC|DESC]]
实例:
1 select 年龄 from 学生 order by 年龄; -- 排序数据(默认升序排列) 2 select 学号, 年龄, 专业号 from 学生 order by 年龄 desc; -- 指定降序排序数据 3 select 学号,专业号, 籍贯 from 学生 -- 检索多个列 4 select distinct 专业号 from 学生; -- 检索不同的值 5 select top 5 专业号 from 学生; -- 检索学生表中前五行
注:
- GROUP BY用于对数据进行分组以便于汇总计算; having是group by的可选项,用于对汇总结果进行筛选。汇总计算是指统统计记录的个数、计算某列的平均值等
- ORDER BY用于指定返回结果的记录按某个或某几列的大小排序,ASC->从小到大排序(默认) DESC->从大到小排序
1 GROUP BY〈组合列表〉[,〈组合列表〉…]:分组查询。
2 查询中的行组取决于一个或多个列的值。〈组合列表〉可以是普通数据库字段名,一个包含SQL字段函数的字段成一个指定查询结果中数据库的列位置的数值表达式,但不能是字段表达式。
3
4 HAVING 〈过滤条件〉与GROUP BY一起使用指定查询结果中的组必须满足的条件。
5 可以根据需要设置多个过滤条件,彼此间用AND或OR连接。还可用NOT求反。
注意下面图中的问题:

六、Transact-SQL语言结构及Transact-SQL程序设计
1.声明变量并赋值
1 DECLARE @name char(10) 2 SET @name = 'wyb' 3 PRINT @name
2.循环结构与注释
(1)Transact-SQL语言的循环结构 -> WHILE...CONTINUE...BREAK
语法格式:
1 语法格式: 2 WHILE<条件表达式> 3 BEGIN 4 <命令行或程序块> 5 [BREAK] 6 [CONTINUE] 7 [命令行或程序块] 8 END
实例:
1 显示字符串“China”中每个字符和其ASCII值: 2 DECLARE @position int, @string char(5) 3 SET @position = 1 4 SET @string = 'China' 5 WHILE @position <= DATALENGTH(@string) 6 BEGIN 7 SELECT SUBSTRING(@string, @position, 1) , 8 ASCII(SUBSTRING(@string, @position, 1)) 9 SET @position = @position + 1 10 END
1 求1到100的累加和,当和超过1000时停止累加,显示累加和以及累加到的位置: 2 DECLARE @i int,@a int 3 SET @i=1 4 SET @a=0 5 WHILE @i <= 100 6 BEGIN 7 SET @a=@a+@i 8 IF @a>=1000 BREAK 9 SET @i=@i+1 10 END 11 SELECT @a AS 'a', @i AS 'i'
(2)Transact-SQL语言的注释
Transact-SQL语言的注释有以下两种:
- ANSI标准的注释符“--”用于单行注释
- 与C语言相同的程序注释符号,即“/*……*/”,可在程序中将多行文字标示为注释
3.Transact-sql数据类型
- 整数数据类型:bigint、int、smallint、tinyint
- 浮点数据类型:real、float、decimal、numeric
- 二进制数据类型:binary、varbinary、image
- 逻辑数据类型:bit
- 字符数据类型:char、nchar、varchar、nvarchar
- 文本和图像数据类型:text、ntext、image
- 日期和时间数据类型:datetime、smalldatetime
4.索引类型
索引可以分为以下两种:
- 聚簇索引,这种类型的索引顺序与数据表的物理顺序相同
- 非聚簇索引,这种类型的索引顺序与数据表的物理顺序不同
5.视图与表的区别
(1)视图的定义
数据库中的数据都是存储在表中的,而视图只是一个或多个表依照某个条件组合而成的结果集,一般来说你可以用update,insert,delete等sql语句修改表中的数据,而对视图只能进行select操作。但是也存在可更新的视图,对于这类视图的update,insert和delete等操作最终会作用于与其相关的表中数据。因此表是数据库中数据存储的基础,而视图只是为了满足某种查询要求而建立的一个对象。
表是物理存在的,你可以理解成计算机中的文件!视图是虚拟的内存表,你可以理解成Windows的快捷方式!
视图是数据库数据的特定子集。可以禁止所有用户访问数据库表,而要求用户只能通过视图操作数据,这种方法可以保护用户和应用程序不受某些数据库修改的影响
(2)视图和表的区别和联系
区别:
- 视图是已经编译好的sql语句。而表不是
- 视图没有实际的物理记录。而表有
- 表是内容,视图是窗口
- 表只用物理空间而视图不占用物理空间,视图只是逻辑概念的存在,表可以及时对它进行修改,但视图只能有创建的语句来修改
- 表是内模式,视图是外模式
- 视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合。从安全的角度说,视图可以不给用户接触数据表,从而不知道表结构
- 表属于全局模式中的表,是实表;视图属于局部模式的表,是虚表
- 视图的建立和删除只影响视图本身,不影响对应的基本表
联系:
视图(view)是在基本表之上建立的表,它的结构(即所定义的列)和内容(即所有数据行)都来自基本表,它依据基本表存在而存在。一个视图可以对应一个基本表,也可以对应多个基本表。视图是基本表的抽象和在逻辑意义上建立的新关系。
6.函数
常用函数:

(1)汇总数据
1 select avg(成绩) as avg from 成绩单 where 课程号 = 01054010; -- avg函数
2 select count(*) as num_cust from 成绩单; -- count函数
3 select count(课程号) as num_cust from 成绩单; -- count函数
4 select max(成绩) as max_grade from 成绩单; -- max函数
5 select min(成绩) as min_grade from 成绩单; -- min函数
6 select sum(基本工资) as sum_salary from 教师 where 职称='教授'; --sum函数
7 select sum(基本工资) as sum_salary from 教师 where 职称='副教授'; --sum函数
8 select sum(基本工资) as sum_salary from 教师 where 职称='讲师'; --sum函数
9 select avg(distinct 成绩) as avg from 成绩单 where 课程号 = 01054010; -- distinct
10 select avg(成绩) as avg, max(成绩) as max, min(成绩) as min from 成绩单 where 课程号 = 01054010; -- 组合聚集函数
(2)分组数据
1 select count(*) as num_prods from 学生 where 学号 like '0305%'; -- 数据分组
2 select 年龄, count(*) as num_prods from 学生 group by 年龄; -- 创建分组
3 select 年龄, count(*) as num_prods from 学生 group by 年龄 order by 年龄 desc; -- 创建分组并以年龄降序排列
4 select 年龄, count(*) as num_prods from 学生 group by 年龄 having count(*) >= 3; -- 过滤分组
5 select 年龄, count(*) as num_prods from 学生 where 民族 = '汉' group by 年龄 having count(*)>=3; -- having和where同时使用
group和having:
1 GROUP BY〈组合列表〉[,〈组合列表〉…]:分组查询。
2 查询中的行组取决于一个或多个列的值。〈组合列表〉可以是普通数据库字段名,一个包含SQL字段函数的字段成一个指定查询结果中数据库的列位置的数值表达式,但不能是字段表达式。
3
4 HAVING 〈过滤条件〉与GROUP BY一起使用指定查询结果中的组必须满足的条件。
5 可以根据需要设置多个过滤条件,彼此间用AND或OR连接。还可用NOT求反。
注意下面图中的问题:

7.存储过程
存储过程是一组已被编辑在一起、存储在服务器上、执行某种功能的预编译SQL语句。它是一种封装重复任务操作的方法,支持用户提供的参数变量,具有强大的编程能力
8.事务和锁
事务的属性(ACID):
- 原子性
- 一致性
- 隔离性
- 持久性
七、数据库安全与维护
登录账号与用户与角色的区别:
- 登录账号:Windows登录账号 or SqlServer登录账号,登录账号是系统信息
- 用户:一个或多个登录对象在数据库中的映射,可以对用户对象进行授权,以便为登录对象提供对数据库的访问权限。用户定义信息存放在每个数据库的sysusers表中
- 角色:角色代表一系列权限的集合,如果将某个角色分配给某个用户,则这个用户就拥有了这一系列的权限