分区的作用
分区是将一个表的数据按照某种方式,比如按照时间上的月份,分成多个较小的,更容易管理的部分,但是逻辑上仍是一个表。
个人理解起来,分区跟性能没有必然关系,分区更多的是从管理的角度出发的。
MySQL分区表对分区字段的限制
分区的字段,必须是表上所有的唯一索引(或者主键索引)包含的字段的子集
换句话说就是:(所有的)字段必须出现在(所有的)唯一索引或者主键索引的字段中,
或者更通俗讲就是,一个表上有一个或者多个唯一索引的情况下,分区的字段必须被包含在所有的主键或者唯一索引字段中。
关于这个限制,笔者是根据官方文档中的示例,理解了好久,以下参考官方的示例。
示例1(如下语句报错,无法创建分区表):
CREATE TABLE t1 ( col1 INT NOT NULL, col2 DATE NOT NULL, col3 INT NOT NULL, col4 INT NOT NULL, UNIQUE KEY (col1, col2) ) PARTITION BY HASH(col3) PARTITIONS 4;
分区字段是col3, 主键是(col1, col2),col3没有出现在主键字段中,因此不满足“分区的字段,必须是唯一索引字段的子集”,无法创建分区表
如果要想按照col3分区,可以把col3加入到unique key中。
示例2(如下语句报错,无法创建分区表):
CREATE TABLE t2 ( col1 INT NOT NULL, col2 DATE NOT NULL, col3 INT NOT NULL, col4 INT NOT NULL, PRIMARY KEY (col1), UNIQUE KEY (col3) ) PARTITION BY HASH(col1 + col3) PARTITIONS 4;
分区字段是col1 + col3, 两个unique key分别是col1和col3,分区字段没有出现在任何一个unique(primary) key中,因此无法按照(col1 + col3)分区
如果要想按照ccol1 + col3,分区,创建一个col1 + col3的unique key(唯一索引),如果是col1+col3的唯一索引,那只能有一个了,不能两个unique key的字段完全一致。
因此分区字段是 “所有的(如果有多个)” “索引唯一索引(或者主键索引)”的中字段的子集(或者全集)。
示例3(如下语句报错,无法创建分区表):
如下情况下,无法为t4表分区,因为有两个唯一索引,且唯一索引的字段没有交集,
那么任何情况下,都不符合:分区字段是 “所有的(如果有多个)” “索引唯一索引(或者主键索引)”的子集(或者全集)
CREATE TABLE t4 ( col1 INT NOT NULL, col2 INT NOT NULL, col3 INT NOT NULL, col4 INT NOT NULL, UNIQUE KEY (col1, col3), UNIQUE KEY (col2, col4)、 );
MySQL是局部分区,意思是一个分区中,包含分区的数据和其对应的索引,而不是索引是一个索引统一存放在一个地方,仅分区数据这种方式。
想一下,为什么MySQL的分区表会有这个么一个奇怪的要求:一个表上有一个或者多个唯一索引的情况下,分区的字段必须被包含在所有的主键或者唯一索引字段中?
分区类型
range分区,分区字段必须是整型或者转换为整型
按照字段的区间划分数据的归属,典型的就是按照时间维度的月份分区
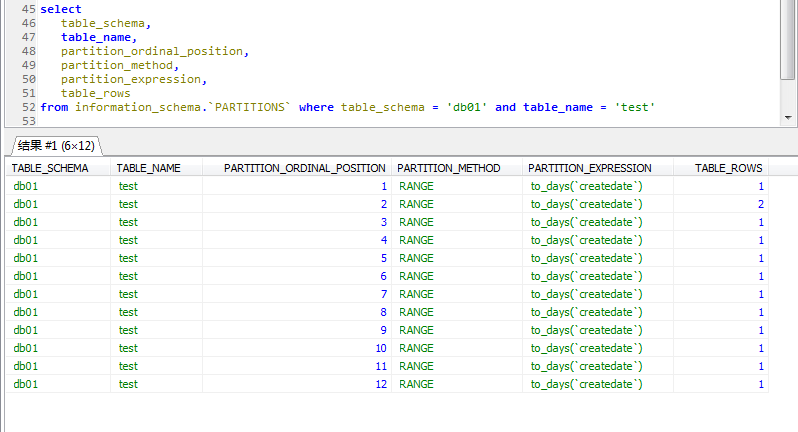
CREATE TABLE test_range_partition( id INT auto_increment, createdate DATETIME, primary key (id,createdate) ) PARTITION BY RANGE (TO_DAYS(createdate) ) ( PARTITION p201801 VALUES LESS THAN ( TO_DAYS('20180201') ), PARTITION p201802 VALUES LESS THAN ( TO_DAYS('20180301') ), PARTITION p201803 VALUES LESS THAN ( TO_DAYS('20180401') ), PARTITION p201804 VALUES LESS THAN ( TO_DAYS('20180501') ), PARTITION p201805 VALUES LESS THAN ( TO_DAYS('20180601') ), PARTITION p201806 VALUES LESS THAN ( TO_DAYS('20180701') ), PARTITION p201807 VALUES LESS THAN ( TO_DAYS('20180801') ), PARTITION p201808 VALUES LESS THAN ( TO_DAYS('20180901') ), PARTITION p201809 VALUES LESS THAN ( TO_DAYS('20181001') ), PARTITION p201810 VALUES LESS THAN ( TO_DAYS('20181101') ), PARTITION p201811 VALUES LESS THAN ( TO_DAYS('20181201') ), PARTITION p201812 VALUES LESS THAN ( TO_DAYS('20190101') ) ); insert into test_range_partition (createdate) values ('20180105'); insert into test_range_partition (createdate) values ('20180205'); insert into test_range_partition (createdate) values ('20180206'); insert into test_range_partition (createdate) values ('20180305'); insert into test_range_partition (createdate) values ('20180405'); insert into test_range_partition (createdate) values ('20180505'); insert into test_range_partition (createdate) values ('20180605'); insert into test_range_partition (createdate) values ('20180705'); insert into test_range_partition (createdate) values ('20180805'); insert into test_range_partition (createdate) values ('20180905'); insert into test_range_partition (createdate) values ('20181005'); insert into test_range_partition (createdate) values ('20181105'); select table_schema, table_name, partition_name, partition_ordinal_position, partition_method, partition_expression, table_rows from information_schema.`PARTITIONS` where table_schema = 'db01' and table_name = 'test_range_partition';
对应的物理文件
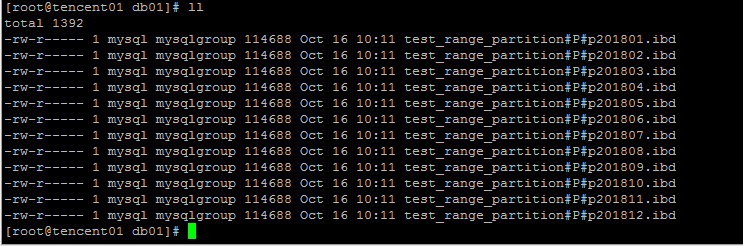
查看每个分区的信息
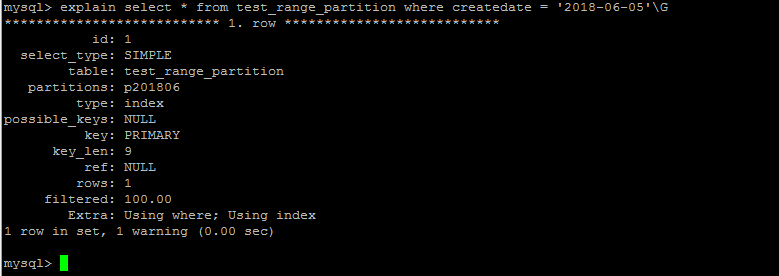
分区在查询中的优化体现
并不是说一个表只要分区了,对于任何查询都会实现查询优化,只有查询条件的数据分布在某一个分区的时候,查询引擎只会去某一个分区查询,而不是遍历整个表
在管理层面,如果需要删除某一个分区的数据,只需要删除对应的分区即可
增加与删除分区
ALTER TABLE test ADD PARTITION (PARTITION p201902 VALUES LESS THAN ( TO_DAYS('20190301') )); ALTER TABLE test DROP PARTITION p20180201;
对于range分区,分区字段必须是整型或者转换为整型,如果分区字段是日期类型的字段,那么就必须将日期类型的字段转换成整型类型
对于日期类型的转换,优化器只支持year(),to_days,to_seconds,unix_timestamp()函数的转换,其他的并不支持,
也就是说,在按日期字段分区的时候,如果不是使用上述几个函数转换的,查询优化器将无法对相关查询进行优化。
List分区,分区字段必须是整型或者转换为整型
按照某个字段上的规则,不同的数据离散地分布在不同的区中。
create table test_list_partiotion ( id int auto_increment, data_type tinyint, primary key(id,data_type) )partition by list(data_type) ( partition p0 values in (0,1,2,3,4,5,6), partition p1 values in (7,8,9,10,11,12), partition p2 values in (13,14,15,16,17) );
对于List分区,分区字段必须是已知的,如果插入的字段不在分区时枚举值中,将无法插入
Hash分区,分区字段必须是整型或者转换为整型
Hash分区可以将数据均匀地分不到预先定义的分区中,使得各个分区的数据量分布基本上一致。同样,分区字段必须是整型或者转换为整型
drop table test_hash_partiotion; create table test_hash_partiotion ( id int auto_increment, create_date datetime, primary key(id,create_date) )partition by hash(year(create_date)) partitions 10;
一个很明显的问题就是,如果分区字段本身的分布不匀均,那么hash分区之后存储的分区也是不均匀的,hash分区时对于hash的字段,需要慎重。
对于单个值的查询hash分区可以定位到某一个分区
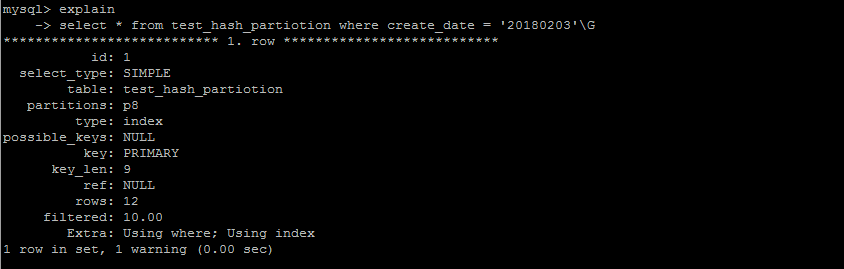
hash分区在查询优化方面,无法优化范围查询,因为无法确定一个某个字段经过hash计算之后究竟分布了在哪个分区之中。
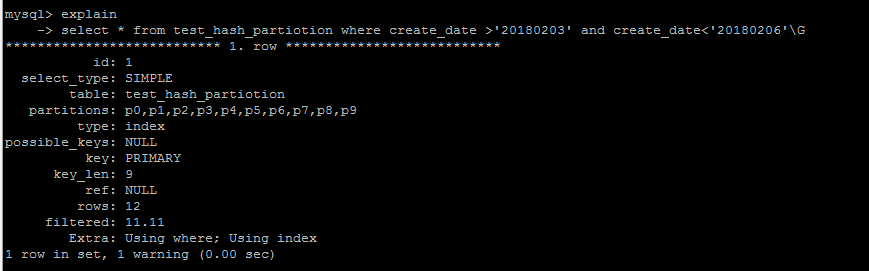
Key分区,分区字段必须是整型或者转换为整型
与hash分区不用的是,key分区使用MySQL自定义的库函数进行分区,不需要hash分区那样对字段整型进行转换,同样,分区字段必须是整型或者转换为整型
create table test_key_partiotion ( id int auto_increment, create_date datetime, primary key(id,create_date) )partition by key(create_date) partitions 10;
对于查询优化,Key分区的特点与Hash分区一致,对于单个字段可以
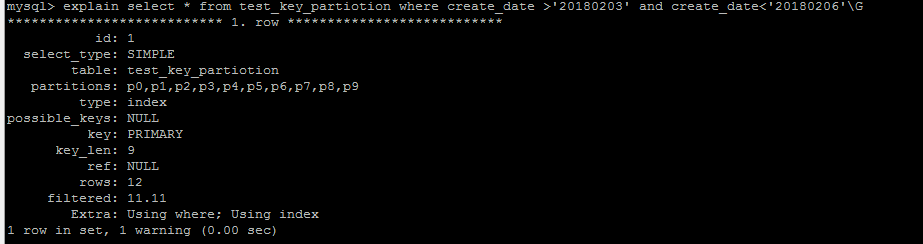
column 分区
解决了分区字段必须是整型或者必须转换为整型的限制,可以对整型,date或者datetime进行支持。
create table test_column_partiotion ( id int auto_increment, data_type datetime, primary key(id,data_type) )partition by range columns(data_type) ( partition p0 values less than ('20180101'), partition p1 values less than ('20180201'), partition p2 values less than ('20180301'), partition p3 values less than ('20180401'), partition p4 values less than ('20180501'), partition p5 values less than ('20180601'), partition p6 values less than ('20180701'), partition p7 values less than ('20180801') );