笔者最近遇到一则典型的因为sql中存在派生表造成的性能案例,通过改写SQL改善了的性能,但当时并没有弄清楚这其中的原因,派生表究竟是什么原因会导致性能上的副作用。
说来也巧,很快就无意中就看到下文中的提到的相关的派生表的介绍以及其特性之后,才发现个中缘由,本文基于此,用一个非常简单的demo来演示该问题,同时警惕MySQL中派生表的使用。
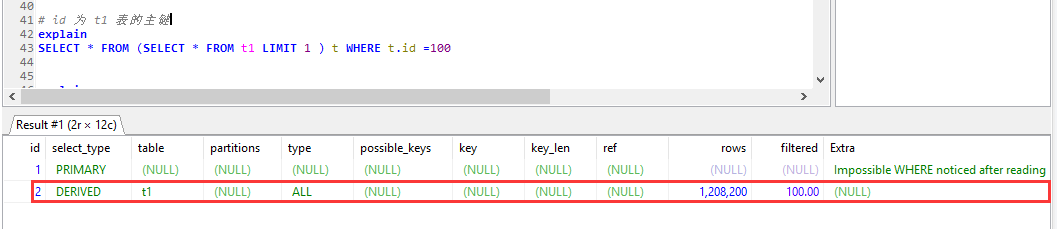
开始之前,先看一下MySQL 5.7.20下面的奇葩的现象,感受一下MySQL对派生表的支持有多弱。
如下写法,尽管id为主键的情况下,依旧会出现一个奇葩的全表扫描,
一个认为不太可能出问题的sql,他就是结结实实地出现了问题,而且还很严重,所以不服不行。
什么是派生表
关于派生表的定义,不赘述了,以下截图来自于爱可生公司的公众号中,说的非常清晰,连接地址为:https://mp.weixin.qq.com/s/CxagKla3Z6Q6RJ-x5kuUAA,侵删,谢谢。

这里我们主要关注它在与父查询join时的一些限制,如果派生表中存在distinct,group by union /union all,having,关联子查询,limit offset等,也即父查询的参数无法传递到派生表的查询中,导致一些性能上的问题。
测试场景
假设是在MySQL的关系数据中,试想有这个一个查询:一个订单表以及对应的物流信息表,关系为1:N,查询订单和其最新的1条物流信息,这个查询该怎么写(假设问题存在而不论证其是否合理)?
相信实现起来并不复杂,如果是查看单条订单的物流信息,两张表join 起来,按照时间倒序取第一条即可,如果要查询多条订单的信息,或者是某一段时间内所有的订单的该信息呢?
如果是是商业数据库或者是MySQL 8.0中有现成的分析函数可以用,如果是MySQL 5.7,没有现成的分析函数,该怎么写呢?
简单demo一下,说明问题即可:加入t1表示订单表,t2表示物流信息表,c1为订单号(关联键),t1和t2中的数据为1对多。
CREATE TABLE t1 ( id INT AUTO_INCREMENT PRIMARY key, c1 INT, c2 VARCHAR(50), create_date datetime ); CREATE TABLE t2 ( id INT AUTO_INCREMENT PRIMARY key, c1 INT, c2 VARCHAR(50), create_date datetime ); CREATE INDEX idx_c1 ON t1(c1); CREATE INDEX idx_c1 ON t2(c1);
按照1:10的比例往两张表中写入测试数据,也就是说一条订单存在10条物流信息,其订单的物流信息的创建时间随机分布在一定的时间范围。测试数据在百万级就够了。
CREATE DEFINER=`root`@`%` PROCEDURE `create_test_data`( IN `loop_count` INT ) BEGIN SET @p_loop = 0; while @p_loop<loop_count do SET @p_date = DATE_ADD(NOW(),INTERVAL -RAND()*100 DAY); INSERT INTO t1 (c1,c2,create_date) VALUES (@p_loop,UUID(),@p_date); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); INSERT INTO t2 (c1,c2,create_date) VALUES (@p_loop,UUID(),DATE_ADD(@p_date,INTERVAL RAND()*10000 MINUTE)); SET @p_loop = @p_loop+1; END while; END
这是典型的一条数据示例(订单和其物流信息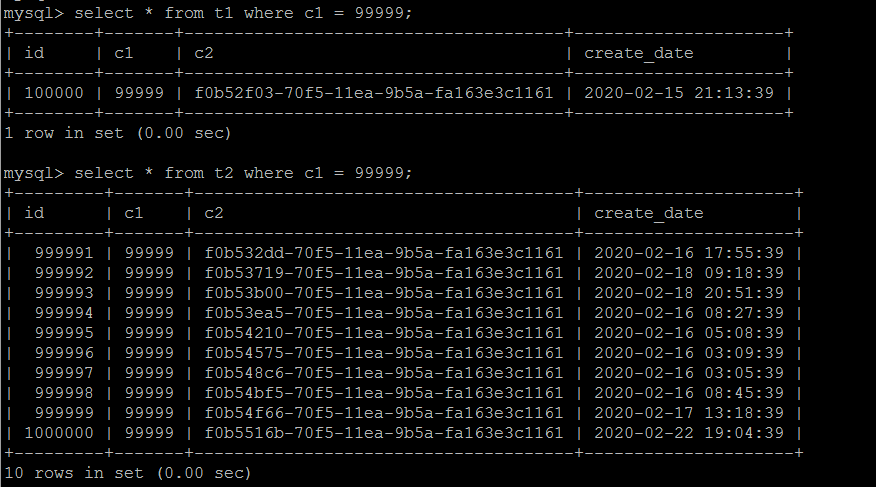
派生表的性能问题
按照最通用的写法,就是实现一个类似于商业数据库中的row_number()功能,按照订单号分组,然后求给每个订单号的物流信息排序,最后取第一条物流信息即可。
为了简单起见,这个SQL只查询一个订单的最新的物流信息。
于是就这么写了一个语句,其中通过一个派生表,用到了典型的row_number()分析函数等价实现,这个语句执行起来逻辑上当然没有什么问题,结果也完全符合预期,但是执行时间会接近3秒钟,这个是远远超出过预期的。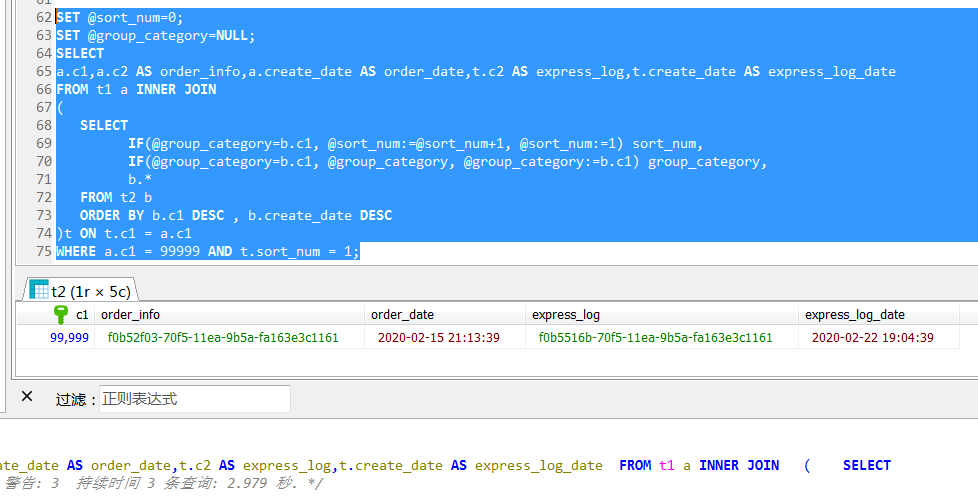
这里插一句:很多人包括面试都会问,SQL优化有哪些技巧?
不排除一部分人的言外之意就是要你列举出来一些”固定的套路”,比如where条件怎么样了,索引怎么建了,什么乱七八糟的,列举出来一大堆,这么多年过去了,这中套路式的列举依然是我最最最讨厌的套路。
实际情况千变万化,固定的套路可能会好使,但是更多的时候,需要根据是情况做具体分析,而不是死套套路,如果真的有一个(系列)规则可以套,那么执行计划是不是又回到最原始的RBO模式了?
面对一个需要优化的SQL,弄清楚这个sql的逻辑之后:先不管它实际上是怎么执行的,首先自己心中要有一个执行计划,要有一个预期的执行方式,理论上是相对较好的一种执行方式(计划)。
1,如果按照预期的方式执行,但是性能并没有达到预期,需要反思是什么因素造成的?
2,如果没有按照预期的方式执行,同样需要反思了,为什么没有按照预期的方式执行,可能会是什么原因造成的?
对于这个SQL,我个人倾向于先通过派生表对子表做一个清晰的排序实现,然后父查询进行过滤(筛选最新的一条数据),
我个人臆测的执行计划如下:
因为join条件是t.c1 = a.c1,where条件是a.c1 = 99999,按道理来说,是比较清晰的逻辑,既然a.c1 = 99999又t.c1 = a.c1,这个筛选条件会直接推进到子查询(派生表内部),筛选一下就完事了
这个性能表面,实际的执行计划很可能不是这么走的,其实却是出乎意料的。
可以看到,派生表内部是一个全表扫描,也就是说跟t2做做一个全表扫描,然后对每个订单的物流信息排序,然后再根据外层的查询进行订单号的筛选(where a.c1 = 99999)
这个可以说是完全出乎意料的,一开始并不知道外层的查询条件,是无法能推进到派生表内部来做过滤的。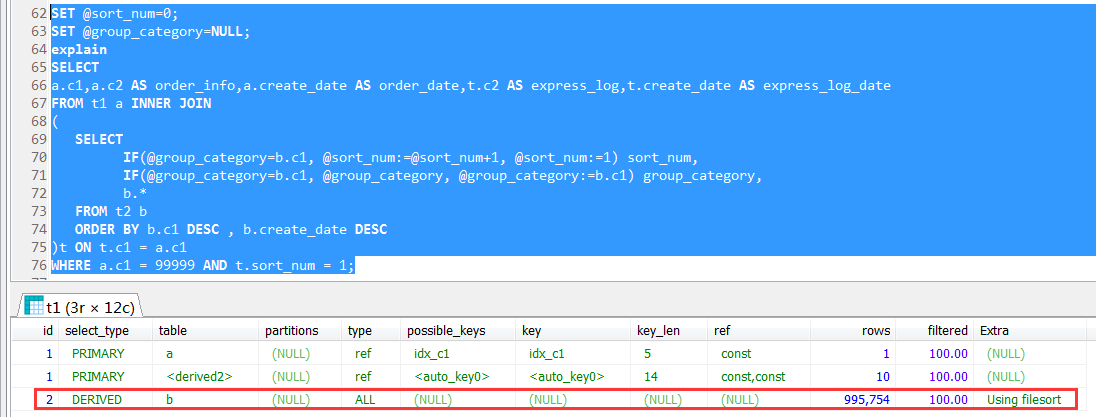
这里涉及到一个derived_merge相关的实现,
指的是一种查询优化技术,作用就是把派生表合并到外部的查询中,提高数据检索的效率。这个特性在MySQL5.7版本中被引入(参考https://blog.csdn.net/sun_ashe/article/details/89522394)。
举一个实际的例子,比如对于select * from (select * from table_name)t where id= 100;
用土话说就是,外层查询的条件会推进到派生表的子查询中,实际的执行过程就变为:select * from (select * from table_name where id =100)t where id= 100,
在商业数据库中,这一切都是非常的自然的一个过程,在MySQL中是不一定的,所以不得不承认MySQL的优化器太弱了。
基于此重新改写了一下SQL,如下,主表和子表先join起来,同时对子表进行排序,然后再外层筛选最新的一条信息(t.sort_num = 1),
改写之后,这个查询只需要0.125秒,大概有20倍+的提升,这是没有任何外界条件的变化的情况下。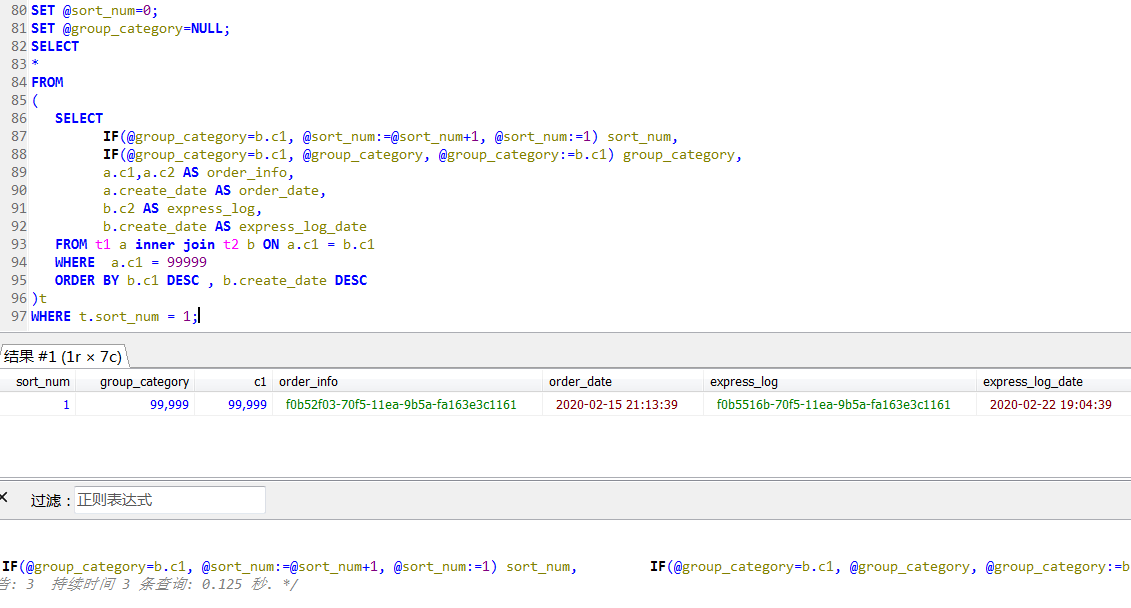
其实这个执行计划,才是上面提到的“预期的”执行计划,筛选条件同时应用到了两张表中,进过筛选之后再做逻辑上的排序计算。
至于为什么第一次没有用到这些写法,其实写SQL每个人都有自己的习惯,个人的思路就是首先可以做到不牵涉任何join的时候,先对目标对象进行排序计算等等,完成份内的事之后,然后再join主表取数据。
个人认为这是一种写法的逻辑看上去更加清晰易懂,尤其是在较多的表join的时候,每一步先完成自己份内的事,然后再跟其他表join(当然这也是一个见仁见智的问题,个人思路都可能不一样,这里有点跑偏了)
如果上上述第一种写法,在SqlServer或者其他关系数据库中,是完全等价于第二种写法的,所以一开始是没有预料到这种巨大的性能差异的。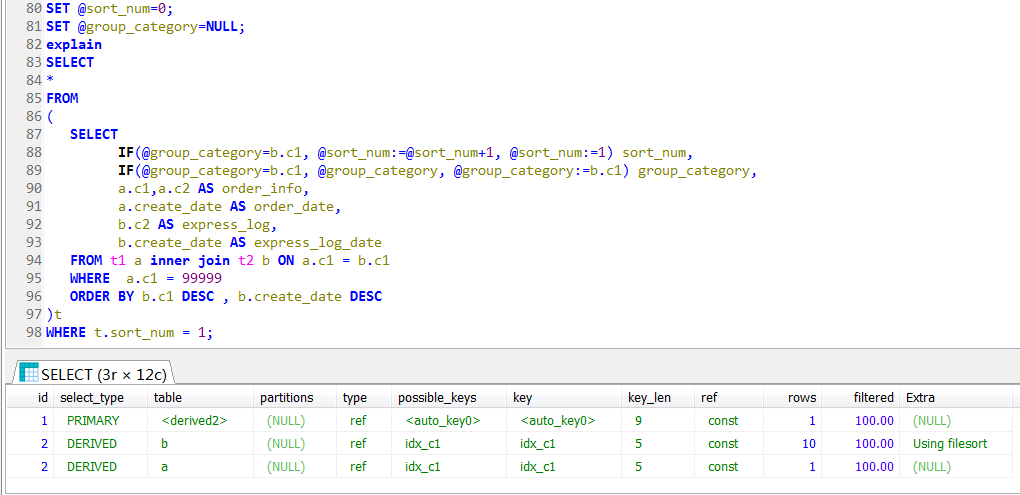
其实这里就可以不回归到本文一开始提到的派生表的限制了,这个截图来自于这里:https://blog.csdn.net/sun_ashe/article/details/89522394,侵删。
任何走到continue中的逻辑,都是无法实现外层查询筛选条件推进到派生表的子查询的。
也就是说派生表中存在distinct,group by union /union all,having,关联子查询,limit offset,变量等情况下,无法进行derived_merge。
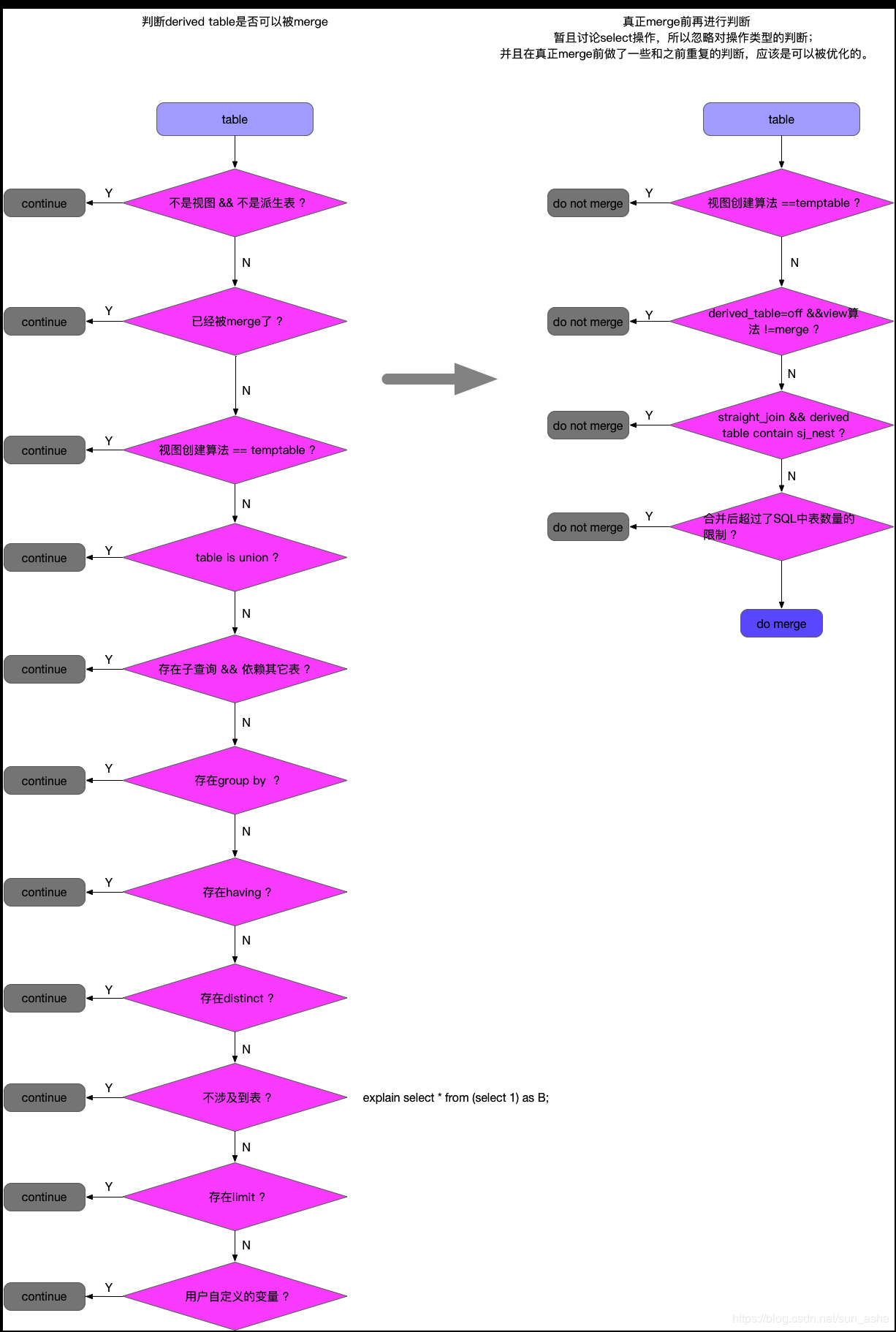
可以认为,任何一个走向continue的分支的情况,都是无法使用derived_merge的。
其实本文中的示例SQL继续简化一下,就非常明显了,这里不去join任何表,仅对t2表做一个分析查询,然后刻意基于派生表实现筛选,其执行计划并不是理想中的索引查找
也就是说,select * from (select * from table_name)t where id= 100在某些条件下是无法转换为select * from (select * from table_name where id =100)t where id= 100的,外层查询条件无法推进到内层查询中。
上文中的查询,与join的参与并无关系,其实就派生表中有用户变量造成的,这里看到执行计划走的是一个全表扫描
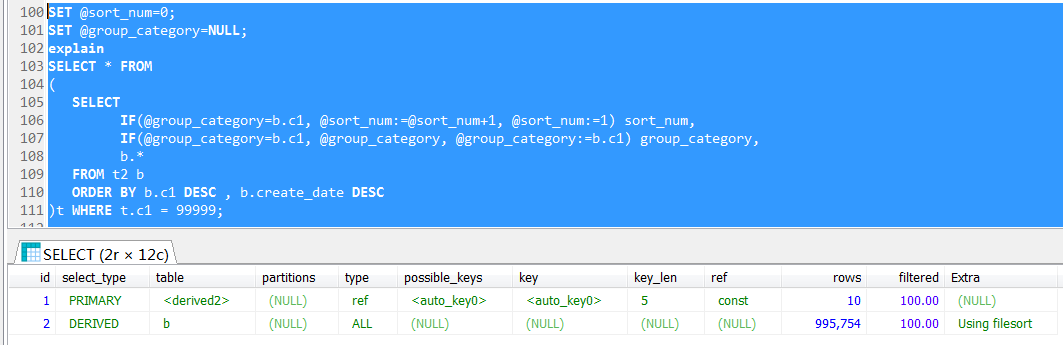
如果不使用派生表的方式,其执行计划就是索引查找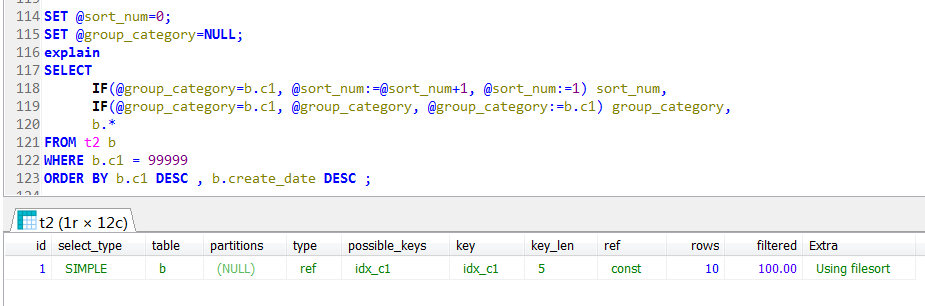
MySQL 8.0的分析函数
其实之前的写法都是为了实现row_number这个分析函数的功能,如果直接采用MySQL 8.0分析函数,SQL会极大地地得到简化,性能也会飞起来。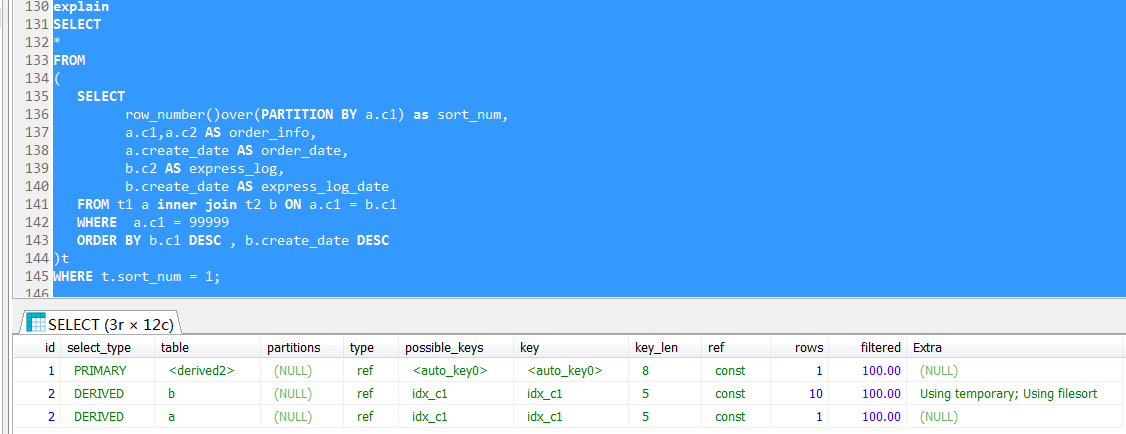
总结
以上通过一个简单的案例,来说了了derived_merge的限制,可能这些在其他数据库上不是问题的问题,在MySQL上都是问题,实际上MySQL优化器还是需要提升的。
如果一旦有类似派生表的情况,可能会遇到有性能问题,还是需要值得注意的。
demo的sql
SET @sort_num=0; SET @group_category=NULL; SELECT a.c1,a.c2 AS order_info,a.create_date AS order_date,t.c2 AS express_log,t.create_date AS express_log_date FROM t1 a INNER JOIN ( SELECT IF(@group_category=b.c1, @sort_num:=@sort_num+1, @sort_num:=1) sort_num, IF(@group_category=b.c1, @group_category, @group_category:=b.c1) group_category, b.* FROM t2 b ORDER BY b.c1 DESC , b.create_date DESC )t ON t.c1 = a.c1 WHERE a.c1 = 99999 AND t.sort_num = 1; SET @sort_num=0; SET @group_category=NULL; SELECT * FROM ( SELECT IF(@group_category=b.c1, @sort_num:=@sort_num+1, @sort_num:=1) sort_num, IF(@group_category=b.c1, @group_category, @group_category:=b.c1) group_category, a.c1,a.c2 AS order_info, a.create_date AS order_date, b.c2 AS express_log, b.create_date AS express_log_date FROM t1 a inner join t2 b ON a.c1 = b.c1 WHERE a.c1 = 99999 ORDER BY b.c1 DESC , b.create_date DESC )t WHERE t.sort_num = 1; SELECT * FROM ( SELECT row_number()over(PARTITION BY a.c1 ORDER BY b.create_date desc) as sort_num, a.c1, a.c2 AS order_info, a.create_date AS order_date, b.c2 AS express_log, b.create_date AS express_log_date FROM t1 a inner join t2 b ON a.c1 = b.c1 WHERE b.c1 = 99999 )t WHERE t.sort_num = 1;