插入缓存
Insert Buffer
Insert Buffer是InnoDB存储引擎关键特性中最令人激动与兴奋的一个功能。不过这个名字可能会让人认为插入缓冲是缓冲池中的一个组成部分。其实不然,InnoDB缓冲池中有Insert Buffer信息固然不错,但是Insert Buffer和数据页一样,也是物理页的一个组成部分。
一般情况下,主键是行唯一的标识符。通常应用程序中行记录的插入顺序是按照主键递增的顺序进行插入的。因此,插入聚集索引一般是顺序的,不需要磁盘的随机读取。因为,对于此类情况下的插入,速度还是非常快的。(如果主键类是UUID这样的类,那么插入和辅助索引一样,也是随机的。)
如果索引是非聚集的且不唯一。在进行插入操作时,数据的存放对于非聚集索引叶子节点的插入不是顺序的,这时需要离散地访问非聚集索引页,由于随机读取的存在而导致了插入操作性能下降。这是因为B+树的特性决定了非聚集索引插入的离散性。
Insert Buffer的设计,对于非聚集索引的插入和更新操作,不是每一次直接插入到索引页中,而是先判断插入非聚集索引页是否在缓冲池中,若存在,则直接插入,不存在,则先放入一个Insert Buffer对象中。数据库这个非聚集的索引已经插到叶子节点,而实际并没有,只是存放在另一个位置。然后再以一定的频率和情况进行Insert Buffer和辅助索引页子节点的merge(合并)操作,这时通常能将多个插入合并到一个操作中(因为在一个索引页中),这就大大提高了对于非聚集索引插入的性能。
需要满足的两个条件:
- 索引是辅助索引;
- 索引不是唯一的。
辅助索引不能是唯一的,因为在插入缓冲时,数据库并不去查找索引页来判断插入的记录的唯一性。如果去查找肯定又会有离散读取的情况发生,从而导致Insert Buffer失去了意义。
Change Buffer
InnoDB从1.0.x版本开始引入了Change Buffer,可将其视为Insert Buffer的升级。从这个版本开始,InnoDB存储引擎可以对DML操作——INSERT、DELETE、UPDATE都进行缓冲,他们分别是:Insert Buffer、Delete Buffer、Purge buffer。
当然和之前Insert Buffer一样,Change Buffer适用的对象依然是非唯一的辅助索引。
对一条记录进行UPDATE操作可能分为两个过程:
- 将记录标记为已删除(Delete Buffer);
- 真正将记录删除(Purge buffer)。
因此Delete Buffer对应UPDATE操作的第一个过程,即将记录标记为删除。Purge Buffer对应UPDATE操作的第二个过程,即将记录真正的删除。同时,InnoDB存储引擎提供了参数innodb_change_buffering,用来开启各种Buffer的选项。该参数可选的值为:inserts、deletes、purges、changes、all、none。inserts、deletes、purges就是前面讨论过的三种情况。changes表示启用inserts和deletes,all表示启用所有,none表示都不启用。该参数默认值为all。
从InnoDB 1.2.x版本开始,可以通过参数innodb_change_buffer_max_size来控制Change Buffer最大使用内存的数量,innodb_change_buffer_max_size值默认为25,表示最多使用1/4的缓冲池内存空间。而需要注意的是,该参数的最大有效值为50。
在MySQL 5.5版本中通过命令SHOW ENGINE INNODB STATUS,可以观察到类似如下的内容:
mysql> SHOW ENGINE INNODB STATUSG;
……
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 34397, seg size 34399, 10875 merges
merged operations:
insert 20462, delete mark 20158, delete 4215
discarded operations:
insert 0, delete mark 0, delete 0
……
可以看到这里显示了merged operations和discarded operation,并且下面具体显示Change Buffer中每个操作的次数。insert表示Insert Buffer;delete mark表示Delete Buffer;delete表示Purge Buffer;discarded operations表示当Change Buffer发生merge时,表已经被删除,此时就无需再将记录合并(merge)到辅助索引中了。
Merge Insert Buffer
通过前面的小节读者应该已经知道了Insert/Change Buffer是一棵B+树。若需要实现插入记录的辅助索引页不在缓冲池中,那么需要将辅助索引记录插入到这棵实际B+树中。但是Insert Buffer中的记录何时合并(merge)到真正的辅助索引中呢?
概括地说,Merge Insert Buffer的操作可能发生在以下几种情况下:
- 辅助索引页被读取到缓冲池时;
- Insert Buffer Bitmap页追踪到该辅助索引页已无可用空间时;
- Master Thread。
第一种情况为当辅助索引页被读取到缓冲池中时,例如这在执行正常的SELECT查询操作,这时需要检查Insert Buffer Bitmap页,然后确认该辅助索引页是否有记录存放于Insert Buffer B+树中。若有,则将Insert Buffer B+树中该页的记录插入到该辅助索引页中。可以看到对该页多次的记录操作通过一次操作合并到了原有的辅助索引页中,因此性能会有大幅提高。
Insert Buffer Bitmap页用来追踪每个辅助索引页的可用空间,并至少有1/32页的空间。若插入辅助索引记录时检测到插入记录后可用空间会小于1/32页,则会强制进行一个合并操作,即强制读取辅助索引页,将Insert Buffer B+树中该页的记录及待插入的记录插入到辅助索引页中。这就是上述所说的第二种情况。
还有一种情况,之前在分析Master Thread时曾讲到,在Master Thread线程中每秒或每10秒会进行一次Merge Insert Buffer的操作,不同之处在于每次进行merge操作的页的数量不同。
两次写
doublewrite应用场景
我们知道,innodb的数据页一般大小是16KB,MySQL存取数据的最小单位也是页,而操作系统并不能保障一个数据页的原子性,也就是说当写入数据时,有可能在一个页中写入一半时(比如8K)数据库宕机,这种情况称为部分写失效(partial page write),从而导致数据丢失。
大家也许会问,难道我不可以根据redo log进行数据恢复吗?答案是肯定的也是否定的,要分为两种情况:1、数据库宕机,物理文件完好无损,是可以通过redo log进行崩溃恢复。2、数据库宕机,正在刷新到磁盘的页发生partial page write,而正好在磁盘上的这个数据页由于宕机发生损坏,这时就无法通过redo log进行数据恢复了,为什么?我们必须要清楚的认识到,redo log里记录的是对页的物理操作!比如一条redo记录"page number xx,偏移量 800 写记录 “this is abc”",那当页损坏时,这条redo记录还有意义吗?于是在这种特殊情况下,doublewrite就派上用场啦!
doublewrite体系结构及工作流程
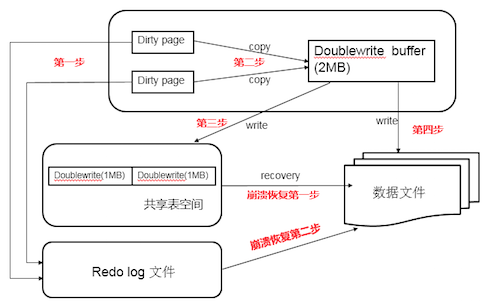
doublewrite由两部分组成,一部分为内存中的doublewrite buffer,其大小为2MB,另一部分是磁盘上共享表空间(ibdata x)中连续的128个页,即2个区(extent),大小也是2M。doublewrite工作流程如下:
- 当一系列机制(main函数触发、checkpoint等)触发数据缓冲池中的脏页进行刷新时,并不直接写磁盘,而是会通过memcpy函数将脏页先复制到内存中的doublewrite buffer,之后通过doublewrite buffer再分两次、每次1MB顺序写入共享表空间的物理磁盘上。
- 马上调用fsync函数,同步脏页进磁盘。由于在这个过程中,doublewrite页的存储时连续的,因此写入磁盘为顺序写,性能很高;完成doublewrite后,再将脏页写入实际的各个表空间文件,这时写入就是离散的了。各模块协作情况如下图(第一步应为脏页产生的redo记录logbuffer,然后logbuffer写入redo log file,为简化次要步骤直接连线表示):
查看doublewrite工作情况,可以执行命令:
mysql> show global status like 'innodb_dblwr%'G
*************************** 1. row ***************************
Variable_name: Innodb_dblwr_pages_written
Value: 61932183
*************************** 2. row ***************************
Variable_name: Innodb_dblwr_writes
Value: 15237891
2 rows in set (0.00 sec)
以上数据显示,doublewrite一共写了 61932183个页,一共写了15237891次,从这组数据我们可以分析,之前讲过在开启doublewrite后,每次脏页刷新必须要先写doublewrite,而doublewrite存在于磁盘上的是两个连续的区,每个区由连续的页组成,一般情况下一个区最多有64个页,所以一次IO写入应该可以最多写64个页。而根据以上我这个系统Innodb_dblwr_pages_written与Innodb_dblwr_writes的比例来看,大概在4左右,远远还没到64,所以从这个角度也可以看出,系统写入压力并不高。
崩溃恢复
如果操作系统在将页写入磁盘的过程中发生崩溃,如上图,在恢复过程中,innodb存储引擎可以从共享表空间的doublewrite中找到该页的一个最近的副本,将其复制到表空间文件,再应用redo log,就完成了恢复过程。因为有副本所以也不担心表空间中数据页是否损坏。
自适应哈希索引
哈希是一种非常快的查找方法,在一般情况时间复杂度为O(1)。而B+树的查找次数,取决于B+树的高度,在生成环境中,B+树的高度一般为3-4层,不需要查询3-4次。
InnoDB存储引擎会监控对表上各索引页的查询。如果观察到简历哈希索引可以提升速度,这简历哈希索引,称之为自适应哈希索引(Adaptive Hash Index, AHI)。AHI是通过缓冲池的B+树页构造而来的。因此建立的速度非常快,且不要对整张表构建哈希索引。InnoDB存储哟inquiry会自动根据房屋的频率和陌生来自动的为某些热点页建立哈希索引。
AHI有一个要求,对这个页的连续访问模式(查询条件)必须一样的。例如联合索引(a,b)其访问模式可以有以下情况:
- WHERE a=XXX;
- 2.WHERE a=xxx AND b=xxx。
若交替进行上述两张查询,InnoDB存储引擎不会对该页构造AHI。此外AHI还有如下要求:
- 以该模式访问了100次;
- b.页通过该模式访问了N次,其中N=页中记录/16。
根据官方文档显示,启用AHI后,读取和写入的速度可以提高2倍,负责索引的链接操作性能可以提高5倍。其设计思想是数据库自由化的,无需DBA对数据库进行人为调整。
异步IO
为了提高磁盘操作性能,当前的数据库系统都采用异步IO的方式来处理磁盘操作。InnoDB也是如此。
与AIO对应的是Sync IO,即每进行一次IO操作,需要等待此次操作结束才能继续接下来的操作。但是如果用户发出的是一条索引扫描的查询,那么这条SQL语句可能需要扫描多个索引页,也就是需要进行多次IO操作。在每扫描一个页并等待其完成再进行下一次扫描,这是没有必要的。用户可以在发出一个IO请求后立即再发出另外一个IO请求,当全部IO请求发送完毕后,等待所有IO操作完成,这就是AIO。
AIO的另外一个优势是进行IO Merge操作,也就是将多个IO合并为一个IO操作,这样可以提高IOPS的性能。
在InnoDB 1.1.x之前,AIO的实现是通过InnoDB存储引擎中的代码来模拟的。但是从这之后,提供了内核级别的AIO的支持,称为Native AIO。Native AIO需要操作系统提供支持。Windows和Linux都支持,而Mac则未提供。在选择MySQL数据库服务器的操作系统时,需要考虑这方面的因素。
MySQL可以通过参数innodb_use_native_aio来决定是否启用Native AIO。在InnoDB存储引擎中,read ahead方式的读取都是通过AIO完成,脏页的刷新,也是通过AIO完成。
刷新邻接页
InnoDB存储引擎在刷新一个脏页时,会检测该页所在区(extent)的所有页,如果是脏页,那么一起刷新。这样做的好处是通过AIO可以将多个IO写操作合并为一个IO操作。该工作机制在传统机械磁盘下有显著优势。但是需要考虑下吧两个问题:
- 是不是将不怎么脏的页进行写入,而该页之后又会很快变成脏页?
- 固态硬盘有很高IOPS,是否还需要这个特性?
为此InnoDB存储引擎1.2.x版本开始提供参数innodb_flush_neighbors来决定是否启用。对于传统机械硬盘建议使用,而对于固态硬盘可以关闭。