这一节使用TF搭建一个简单的神经网络用于分类任务,首先把需要的包引入,另外为了防止在多次运行中一些图中的tensor在内存中影响实验,采取重置操作:
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
def reset_graph(seed=42):
tf.reset_default_graph()
tf.set_random_seed(seed)
np.random.seed(seed)
reset_graph()
plt.figure(1,figsize=(8,6))
为了方便观察随机生成一组两维数据
x0 = np.random.normal(1,1,size=(100,2)) #[(x1,x2),()]
y0 = np.zeros(100)
x1 = np.random.normal(-1,1,size=(100,2))
y1 = np.ones(100)
x = np.concatenate((x0,x1),axis = 0)
y = np.concatenate((y0,y1),axis = 0)
plt.scatter(x[:,0],x[:,1],c=y,cmap='RdYlGn')
plt.show()
上面生成的两个类别的数据,均值分别为1和-1方差都为1

接下来就是训练模型
#模型
tf_x = tf.placeholder(tf.float32,x.shape)
tf_y = tf.placeholder(tf.int32,y.shape)
output = tf.layers.dense(tf_x,10,tf.nn.relu,name="hidden")
output = tf.layers.dense(output,2,name="output")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf_y,logits=output)
loss = tf.reduce_mean(xentropy,name="loss")
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1)
training_op = optimizer.minimize(loss)
#evaluate
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(output,y,1)
accuracy = tf.reduce_mean(tf.cast(correct,tf.float32))
init = tf.global_variables_initializer()
plt.ion()
plt.figure(figsize=(8,6))
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
for step in range(100):
_,acc,pred = sess.run([training_op,accuracy,output],feed_dict={tf_x:x,tf_y:y})
plt.cla()
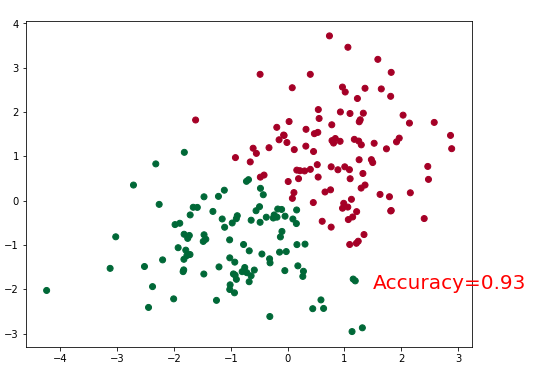
plt.scatter(x[:,0],x[:,1],c=pred.argmax(1),cmap='RdYlGn')
plt.text(1.5, -2, 'Accuracy=%.2f' % acc, fontdict={'size': 20, 'color': 'red'})
saver.save(sess, './model', write_meta_graph=False) #保存模型
plt.ioff()
plt.show()
上面创建了一个隐含层的网络,使用的是elu,也可以尝试使用其他的激活函数。需要注意的是tf.layers.dense的作用是outputs = activation(inputs.kernel + bias),可以看出在输出层是没有使用激活函数的,如果activation=None就表示使用的是线性映射。模型训练完毕后,我们将其持久化,方便以后的使用。我们来看下最终的结果: