使用sklearn进行数据挖掘系列文章:
- 1.使用sklearn进行数据挖掘-房价预测(1)
- 2.使用sklearn进行数据挖掘-房价预测(2)—划分测试集
- 3.使用sklearn进行数据挖掘-房价预测(3)—绘制数据的分布
- 4.使用sklearn进行数据挖掘-房价预测(4)—数据预处理
- 5.使用sklearn进行数据挖掘-房价预测(5)—训练模型
- 6.使用sklearn进行数据挖掘-房价预测(6)—模型调优
前言##
sklearn是比较流行的机器学习工具包,想必很多人都或多或少使用过,但完整的去处理数据挖掘的流程可能还需要去加强。本文将根据实际案例,利用sklearn进行一次完整的数据挖掘案例分析,通过本文的学习,将会对数据挖掘流程进行了解,以及机器学习算法的使用,模型的调参等,希望对你有帮助。
使用的数据为加利福尼亚的房价数据,数据来自加利福尼亚州人口普查,收录了20640条样本。数据包含的属性有 longitude,latitude,housing_median_age,total_rooms,total_bedrooms,population,households(家庭人数),median_income,median_house_value,ocean_proximity,其中mdeia_houese_value是我们的目标(需要预测)变量。
查看数据###
首先使用pandas加载数据
import pandas as pd
def load_housing_data():
return pd.read_csv('housing.csv')
使用pandas提供的head方法查看数据
housing = load_housing_data()
housing.head

从图中可以看出,本数据集总共包含10个特征,9个为数值类型,1个为标签类型。使用housing.info()方法能够查看数据集各个特征的详细信息
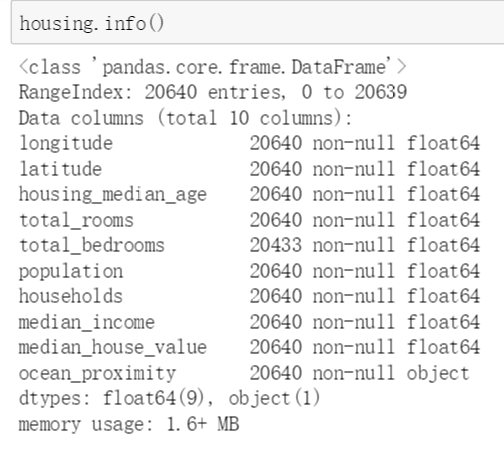
本数据集包含20640个样本,算是一个比较小的数据集了。total_bedrooms只有20433个非空样本,也就意味着有207个样本这一特征数据缺失。使用describe()方法查看数据集的详细信息。
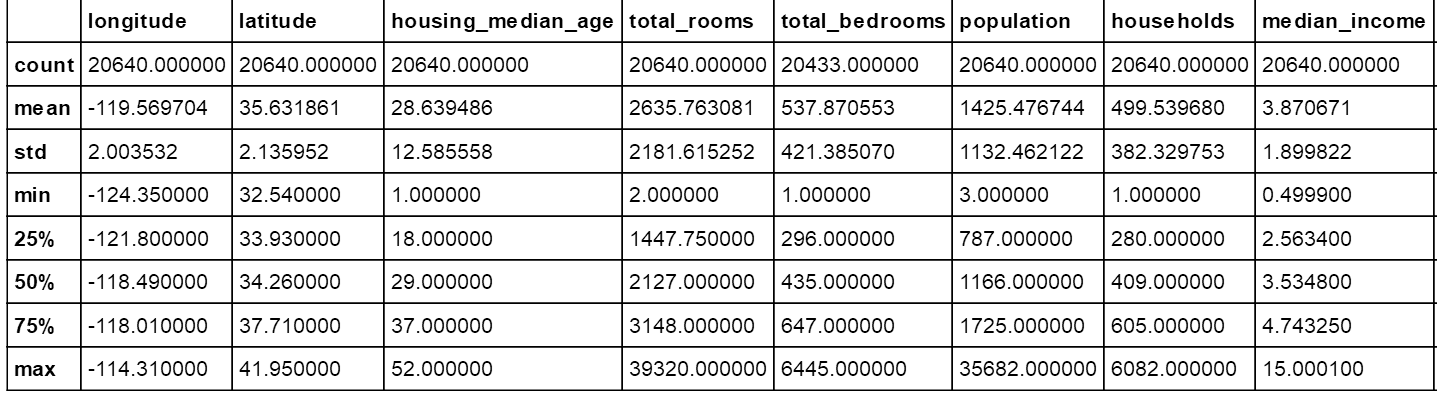
强大的pandas给出了数值类型特征的数值信息,std是标准差,表示数据集的分布广度;三个百分数25、50、75是四分位点,熟悉箱线图的朋友应该知道。例如housing_median_age这一特征,大约有25%的样本小于18、50%的小于29。
对于标称类型特征查看其取值类型
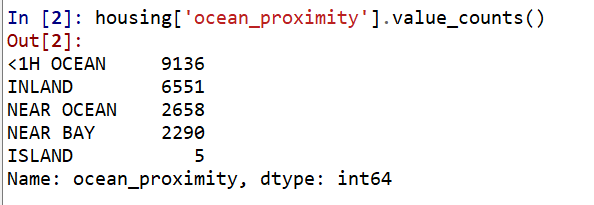
人们对于数值或许不够敏感,从上面的系列表格看不出数据的特点,那么我们可以通过绘制直方图的形式将特征的数值分布展示出来
import matplotlib.pyplot as plt
housing.hist(bins=50,figsize=(15,10))#bins 柱子个数
#plt.savefig('a.jpg') #保存图片
plt.show()
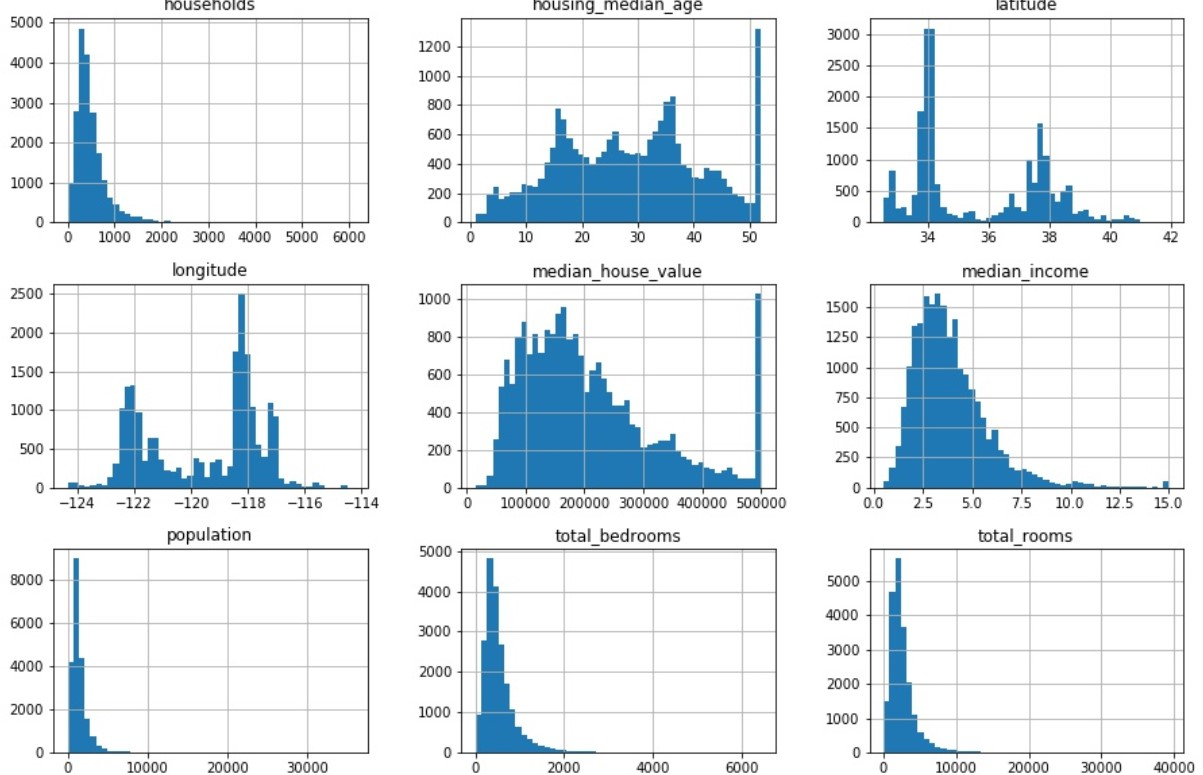
从上图中我们可以得出以下结论:
- 1.发现media income这一维度的值被缩放到[0.5,15]范围区间内,数值的放缩经常被用到机器学习任务中。
- 2.house media age 和 media house value这两个维度也是被缩放过的,其中
media house value是我们的目标属性。 - 3.不同的特征有着不同的尺度(scale),在后面的部分我们将对特征缩放进行讨论。
- 4.从上面的图可以看出,特征趋向于长尾分布,在机器学习任务中我们更加希望特征的分布趋近于正态分布。我们将使用一些方法对这些特征进行转换