Memcached是一款开源、高性能、分布式内存对象缓存系统,可应用各种需要缓存的场景,其主要目的是通过降低对Database的访问来加速web应用程序。许多Web应用都将数据保存到RDBMS中,应用服务器从中读取数据并在浏览器中显示。 但随着数据量的增大、访问的集中,就会出现RDBMS的负担加重、数据库响应恶化、 网站显示延迟等重大影响。这时就该memcached大显身手了。memcached一般的使用目的是,通过缓存数据库查询的结果,减少数据库访问次数,以提高动态Web应用的速度、 提高可扩展性。它是一个基于内存的"键值对"存储,用于存储数据库调用、API调用或页面引用结果的直接数据,如字符串、对象等。
其工作流程图为
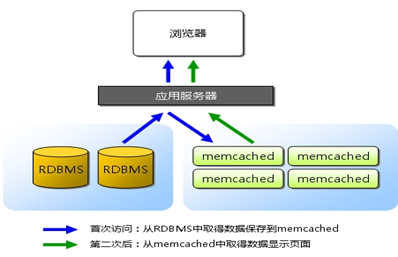
优点特征:
协议简单:使用简单的基于文本行的协议。因此,通过telnet 也能在memcached上 保存数据、取得数据。
内置内存存储方式
为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。 由于数据仅存在于内存中,因此重启memcached、重启操作系统会导致全部数据消失。 另外,内容容量达到指定值之后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存。 memcached本身是为缓存而设计的服务器,因此并没有过多考虑数据的永久性问题。
memcached默认情况下采用了名为Slab Allocator的机制分配、管理内存。 在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。 但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下, 会导致操作系统比memcached进程本身还慢。Slab Allocator就是为解决该问题而诞生的。
Slab Allocator的基本原理是按照预先规定的大小, 将分配的内存分割成各种尺寸的块(chunk), 并把尺寸相同的块分成组(chunk的集合)。各个尺寸的chunk大小是通过其增长因子(growth factor)来决定的,默认增长因子为1.25。下一个尺寸的chunk大小=之前一个chunk大小*增长因子。如下图所示:

而且,slab allocator还有重复使用已分配的内存的目的。 也就是说,分配到的内存不会释放,而是重复利用。不过由于slab Allocator分配的是特定长度的chunk,因此,当缓存的数据没有chunk长度大时,仍然会造成空间浪费
memcached尽管是"分布式"缓存服务器,但服务器端并没有分布式功能。 各个memcached不会互相通信以共享信息。那么,怎样进行分布式呢? 这完全取决于客户端的实现
Memcached的设计哲学
Memcached是一款开发工具,它既不是一个代码加速器,也不是数据库中间件。其设计哲学思想主要反映在如下方面:
1. 简单key/value存储:服务器不关心数据本身的意义及结构,只要是可序列 化数据即可。存储项由"键、过期时间、可选的标志及数据"四个部分组成;
2. 功能的实现一半依赖于客户端,一半基于服务器端:客户负责发送存储项 至服务器端、从服务端获取数据以及无法连接至服务器时采用相应的动作;服 务端负责接收、存储数据,并负责数据项的超时过期;
3. 各服务器间彼此无视:不在服务器间进行数据同步;
4. O(1)的执行效率
5. 清理超期数据:默认情况下,Memcached是一个LRU缓存,同时,它按事 先预订的时长清理超期数据;但事实上,memcached不会删除任何已缓存数据, 只是在其过期之后不再为客户所见;而且,memcached也不会真正按期限清理 缓存,而仅是当get命令到达时检查其时长;
使用telnet命令测试memcached的使用
Memcached提供一组基本命令用于基于命令行调用其服务或查看服务器状等。
查看memcached的内部状态信息
首先是要telnet连接到memcached,然后再输入stats可以获取其memcached 各种信息:
# telnet 127.0.0.1 11211
stats
STAT pid 143........
使用add命令添加数据
add命令语法格式:
add keyname flag timeout datasize
如:
add mykey 0 10 12
Hello world!
使用get命令获取指定key所对应的数据
get命令语法格式为:
get keyname
如:get mykey
VALUE mykey 0 12
Hello world!
memcached的常用选项说明
-l <ip_addr>:指定进程监听的地址;
-d: 以服务模式运行;
-u <username>:以指定的用户身份运行memcached进程;
-m <num>:用于缓存数据的最大内存空间,单位为MB,默认为64MB;
-c <num>:最大支持的并发连接数,默认为1024;
-p <num>: 指定监听的TCP端口,默认为11211;
-U <num>:指定监听的UDP端口,默认为11211,0表示关闭UDP端口;
-t <threads>:用于处理入站请求的最大线程数,仅在memcached编译时开启了支 持线程才有效;
-f <num>:设定Slab Allocator定义预先分配内存空间大小固定的块时使用的增长因 子;
-M:当内存空间不够使用时返回错误信息,而不是按LRU算法利用空间;
-n: 指定最小的slab chunk大小;单位是字节;
分布式Memcache缓存集群调度算法
-
取模计算hash,简单但是添加、移除mc服务器时,缓存会重新组合,影响命中率
-
一致性hash:主机的可分布在0-2^32任意一个节点,key值经过hash来确定要访问数据的区域。这种方式能够很好解决增加或删除mc节点带来缓存重组的问题

memcache的数据操作
格式<command name> <key> <flags> <exptime> <bytes>
参数
<command name> 操作命令:set/add/replace
<key> 缓存的键值
<flags> 客户机使用它存储关于键值对的额外信息
<exptime> 缓存过期时间 单位为秒 0 表示永远存储
<bytes> 缓存值的字节数
get 命令 获取一个键或多个键的值 多个键以空格分开
添加add、set
替换replace,数据必须存在
删除命令 delete
stats 显示memcachd状态
flush_all 清空所有项目 #数据并没有真正删除
append后续追加、prepend前面插入命令
python操作memcached
在python中使用memcache,需要先安装memcached的python client,这里列出了很多,你可以选择一个来安装。yum install python-memcached.noarch -y
import memcache
mc = memcache.Client(['192.168.0.1:11211'], debug=0)
写入缓存:
mc.set("key", "value")
第三个参数默认为0,也就是数据永不超时。
如果这样设置:mc.set("key", "value", 1) 表示一秒后超时
读取缓存
value = mc.get("key")
print value
删除缓存
mc.delete("key")
自增和自减
mc.set("key", "1")
mc.incr("key")
mc.decr("key")
状态:
mc.get_stats()
memcache监控
使用memcache.php、memadmin
也可使用脚本来监控,一方面stat状态echo stats | nc 127.0.0.1 11211,另一方面进程保证alive。
|
pid |
memcache服务器的进程ID |
|
uptime |
服务器已经运行的秒数 |
|
time |
服务器当前的unix时间戳 |
|
version |
memcache版本 |
|
pointer_size |
当前OS的指针大小(32位系统一般是32bit) |
|
rusage_user |
进程的累计用户时间 |
|
rusage_system |
进程的累计系统时间 |
|
curr_items |
服务器当前存储的items数量 |
|
total_items |
从服务器启动以后存储的items总数量 |
|
bytes |
当前服务器存储items占用的字节数 |
|
curr_connections |
当前打开着的连接数 |
|
total_connections |
从服务器启动以后曾经打开过的连接数 |
|
connection_structures |
服务器分配的连接构造数 |
|
cmd_get |
get命令(获取)总请求次数 |
|
cmd_set |
set命令(保存)总请求次数 |
|
get_hits |
总命中次数 |
|
get_misses |
总未命中次数 |
|
evictions |
为获取空闲内存而删除的items数(分配给memcache的空间用满后需要删除旧的items来得到空间分配给新的items),分配内存不足 |
|
bytes_read |
总读取字节数(请求字节数) |
|
bytes_written |
总发送字节数(结果字节数) |
|
limit_maxbytes |
分配给memcache的内存大小(字节) |
|
threads |
当前线程数 |
使用mc注意的一些问题
考虑当多个MC服务器宕机,数据未命中增多,从而导致的穿透的问题,在这种情况下,可以临时考虑封掉一些请求,防止后端进一步恶化。另外后期可以把缓存的数据写两份
注意剔除数evictions,高的话,可能内存不足 ;