前言:
transformer用于图像方面的应用逐渐多了起来,其主要做法是将图像进行分块,形成块序列,简单地将块直接丢进transformer中。然而这样的做法忽略了块之间的内在结构信息,为此,这篇论文提出了一种同时利用了块内部序列和块之间序列信息的transformer模型,称之为Transformer-iN-Transformer,简称TNT。
主要思想
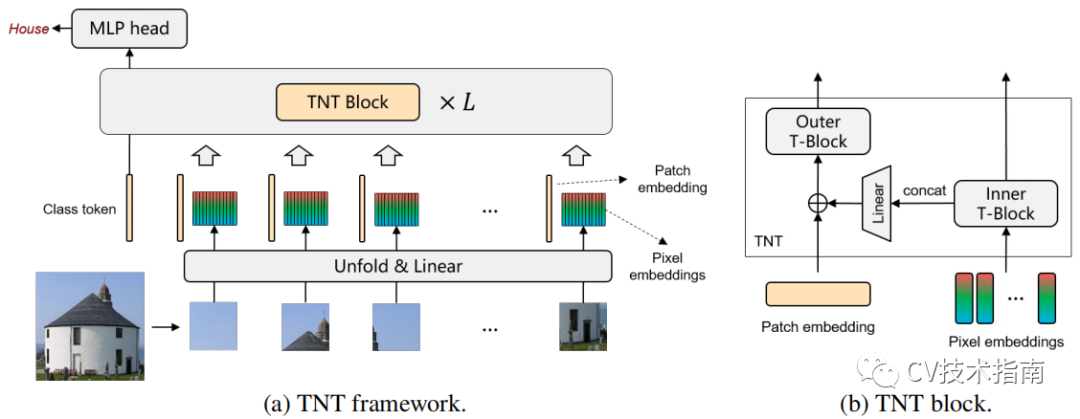
![]()
TNT模型把一张图像分为块序列,每个块reshape为像素序列。经过线性变换可从块和像素中获得patch embedding和pixel embedding。将这两者放进堆叠的TNT block中学习。
在TNT block中由outer transformer block和inner transformer block组成。
outer transformer block负责建模patch embedding上的全局相关性,inner block负责建模pixel embedding之间的局部结构信息。通过把pixel embedding线性映射到patch embedding空间的方式来使patch embedding融合局部信息。为了保持空间信息,引入了位置编码。最后class token通过一个MLP用于分类。
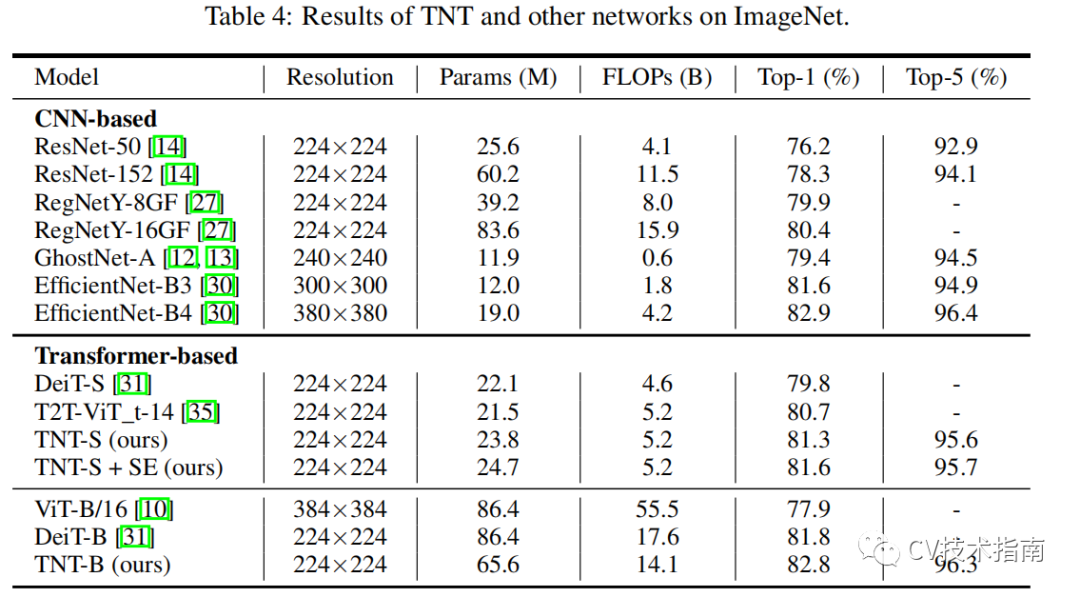
通过提出的TNT模型,可以把全局和局部的结构信息建模,并提高特征表示能力。在精度和计算量方面,TNT在ImageNet和downstream 任务上有非常优异的表现。例如,TNT-S所在ImageNet top-1上在只有5.2B FLOPs的前提下实现了81.3%,比DeiT高了 1.5%。
一些细节
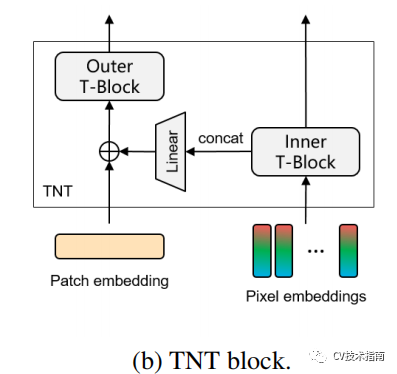
![]()
对照这个图,用几个公式来介绍。
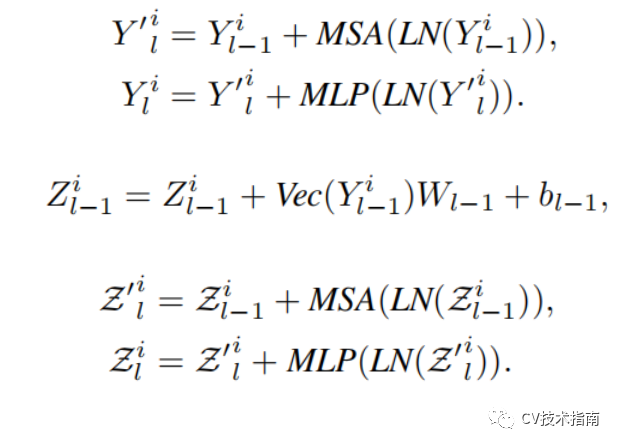
![]()
MSA为Multi-head Self-Attention。
MLP为Multi Layer Perceptron。
LN为Layer Normalization。
Vec为flatten。
加号表示残差连接。
前两个公式是inner transformer block,处理块内部的信息,第三个公式是将块内部的信息通过线性映射到patch embedding空间,最后两个公式是outer transformer block,处理块之间的信息。
位置编码的方式看下面的图就足了。
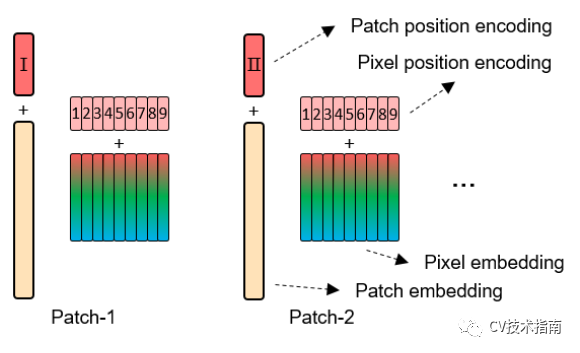
![]()
模型参数量和计算量如下表所示:

![]()
Conclusion
![]()
最近把公众号(CV技术指南)所有的技术总结打包成了一个pdf,在公众号中回复关键字“技术总结”可获取。

![]()
本文来源于公众号CV技术指南的技术总结系列,更多内容请扫描文末二维码关注公众号。

![]()