预想实现selenium+Python的UI自动化,需要如下步骤
一、搭建好Python环境+Pycharm工具
二、安装selenium库、webdriver库
pip install selenium
pip install pywin32
三、安装浏览器及webdriver
1、webdriver下载地址
chrome--需要下载与浏览器版本一致的驱动版本 http://chromedriver.storage.googleapis.com/index.html https://registry.npmmirror.com/binary.html?path=chromedriver/ fixfox--只需下载对应平台的驱动即可 https://github.com/mozilla/geckodriver/releases Edge:--需要下载与浏览器版本一致的驱动版本 https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
2、将下载的driver.exe文件,放到python目录中,并配置好环境变量
例如我的目录是:D:\software\Python3.6
3、在python中使用webdriver
a)通过Pycharm工具使用Python语言导入所需库
from selenium import webdriver
from selenium.webdriver.common.by import By
b)指定webdriver
driver = webdriver.Chrome('D:\workspace\web_selenium\chromedriver.exe')# 若配置了环境变量,则不用传webdriver路径,直接()即可,如下:
driver = webdriver.Firefox()
driver = webdriver.Ie()
c)设置窗口大小web窗口最大化
# 将web窗口最大化 方法:maximize_window() 示例:
driver.maximize_window() # 将浏览器窗口设置固定大小 示例:
driver.set_window_size(540,960)
d)输入被测域名
方法:driver.get(url)
示例:driver.get('https://www.baidu.com/')
四、元素定位
webdriver提供了如下8种元素定位方法,我们这里重点讲XPATH方法
1、元素定位方法
By.XPATH(),采用XPATH方式进行定位--重点讲解
By.ID(),采用id属性进行定位
By.NAME(),采用name属性进行定位
By.LINK_TEXT()
By.PARTIAL_LINK_TEXT()
By.TAG_NAME()
By.CLASS_NAME()
By.CSS_SELECTOR()
2、使用XPATH方法定位元素
元素定位步骤:
a)浏览器F12
b)使用元素定位功能,点击需要操作的位置
c)查看Elements中的前端源代码,通过标签进行定位
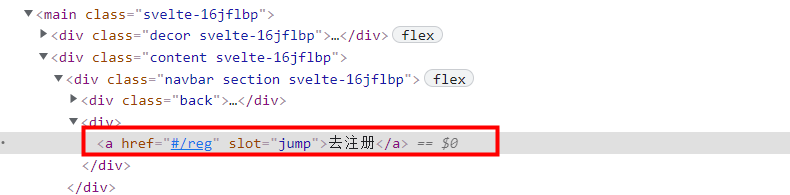
以上图为例,可以通过以下方式定位到元素: //a[text()="去注册"] //a[@href="#/reg"] //a[@slot="jump"]
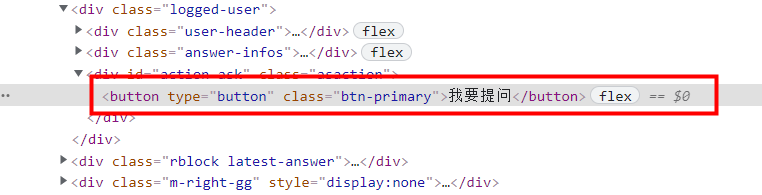
以上图为例,可以通过以下方式定位到元素: //button[@type="button"] //button[@class="btn-primary"] //button[text()="我要提问"]
3、查找到的元素在python的使用
语法: driver.find_element(By.XPATH,'//button[@type="button"]').click() driver.find_element(By.XPATH,'//button[@class="btn-primary"]').click() driver.find_element(By.XPATH,'//button[text()="我要提问"]').click()
4、这里推荐一个chrome的XPATH定位插件,可以测试精准的定位到元素,再放到代码中,更容易排查问题
工具:XPath Helper

5、使用其他的定位方式
语法示例: diver.find_element(By.CLASS_NAME, 'download').click() diver.find_element(By.ID, 'download').click() 复数定位: 假设同一个元素定位后存在多个结果,可以使用find_elements方法+下标的方式定位到想要定位的位置,如: diver.find_elements(By.ID, 'download')[3].click()
五、模拟常见操作
1、打开网页
方法:get(url) 示例:driver.get('https://www.xxx.com/')
2、等待时间
需要使用python自带的time模块,传入秒数 import time 示例:time.sleep(5)
3、点击操作
方法:click() 示例:driver.find_element(By.XPATH,'//span[text()="登录/注册"]').click()
4、输入内容
方法:send_keys() 示例:
driver.find_element(By.XPATH,'//input[@type="tel"]').send_keys('xxx') driver.find_element(By.XPATH,'//input[@type="password"]').send_keys('xxx')
5、清空内容
方法:clear() 示例: driver.find_element(By.XPATH,'//input[@type="password"]').clear()
6、回退到上一页、前进到下一页
后退方法:back()
示例:
driver.back()
前进方法:forward()
示例:
driver.forward()
7、模拟键盘操作--Keys类
| 输入空格 |
.send_keys(Keys.SPACE) |
| 点击退格(调用一次点击一次) |
.send_keys(Keys.BACK_SPACE) |
| 全选操作ctrl+a |
.send_keys(Keys.CONTROL,'a')
|
| 复制操作ctrl+c |
.send_keys(Keys.CONTROL,'c') |
| 剪切操作ctrl+x |
.send_keys(Keys.CONTROL,'x') |
| 粘贴操作ctrl+v |
.send_keys(Keys.CONTROL,'v') |
| 通过回车来代替单击操作 |
.send_keys(Keys.ENTER) |
| F1--F12 |
.send_keys(Keys.F1) |
| 还有很多键盘上的其他操作,使用时可以通过Keys.py类进行查看 | |
# 需要导入Keys()类,该类提供了键盘上几乎所有的按键方法,可以用来模拟键盘按键,包括各种组合键,如Ctrl+A, Ctrl+X,Ctrl+C, Ctrl+V 等等 from selenium.webdriver import Keys 示例: # 先定位元素,在操作复制,ctrl+c ,方法:.send_keys(Keys.CONTROL,'c') driver.find_element(By.XPATH,'//input[@id="payeeAccount"]').send_keys(Keys.CONTROL,'c') # 先定位元素,在操作粘贴,ctrl+v ,方法:.send_keys(Keys.CONTROL,'v') driver.find_element(By.XPATH,'//input[@id="payeeAccount"]').send_keys(Keys.CONTROL,'v')
9、模拟鼠标操作--ActionChains类
a)鼠标悬停
# 需要使用ActionChains库,代码示例: from selenium.webdriver import ActionChains # 找到需要悬停的页面元素 link1 = self.driver.find_element(By.XPATH, '//img[@src="xxx/assets/头像@3x.afb74138.png"]') # 找到第二个需要悬停的页面元素 link2 = self.driver.find_element(By.XPATH, '//span[text()="小白菜无花果"]') # 模拟鼠标悬停操作 ActionChains(self.driver).move_to_element(link1).perform() time.sleep(3) # 在悬浮框中点击元素 ActionChains(self.driver).move_to_element(link2).click() time.sleep(3)
b)鼠标双击
el = driver.find_element(By.XPATH, '//a[text()="登录"]') ActionChains(driver).double_click(el).perform()
c)滚动条操作
# 滑动至目标可见--向下滑动至元素可见 element = self.driver.find_element(By.XPATH,'//a[text()="隐私保护政策"]') self.driver.execute_script("arguments[0].scrollIntoView();", element) time.sleep(6) # 滑动至目标可见--向上滑动至元素可见 element2 = self.driver.find_element(By.XPATH,'//h2[text()="一个平台 链接全球"]') self.driver.execute_script("arguments[0].scrollIntoView(false);",element2) time.sleep(3)
10、对页面进行截屏
方法:get_screenshot_as_file() 示例: driver.get_screenshot_as_file("D:\\b1.png")
11、刷新页面
方法:refresh()
示例:
driver.refresh()
12、关闭当前标签页
方法:close()
示例:
diver.close()
13、关闭新打开的标签网页
参照:https://jingyan.baidu.com/article/6c67b1d6b849822787bb1e00.html
代码示例: # 浏览器窗口句柄,原网页为句柄0,新网页为句柄1,依此类推 windows = self.diver.window_handles
# 定位到预想关闭的浏览器标签中 diver.switch_to.window(windows[1]) # 对这个句柄为1的标签操作关闭 diver.close() sleep_time(2) # 回到原标签中,继续后续操作 diver.switch_to.window(windows[0]) sleep_time()
而如果是打开多个网页。首先打开网页1,再点击网页1上一个链接,在新窗口打开新网页2,同理点击新网页2上一个链接,新窗口打开新网页3等等,这是按打开顺序为网页编号。实际网页对应句柄如下图所示,即第一个打开网页一直是句柄0,而最新打开的网页记为句柄1,依次序编号。

14、关闭浏览器,释放进程
方法:quit()
示例:
diver.quit()