一、vue相关
1、为什么data是一个函数?(防止数据在组件之间共享)
组件中的 data 写成一个函数,数据以函数返回值形式定义,这样每复用一次组件,就会返回一份新的 data,类似于给每个组件实例创建一个私有的数据空间,让各个组件实例维护各自的数据。
而单纯的写成对象形式,就使得所有组件实例共用了一份 data,就会造成一个变了全都会变的结果。
2、vue的生命周期一共有beforeCreate、created、beforeMount、mounted、beforeUpdate、updated、beforeDestroy、destroyed、activated以及deactivated十个,那vue的异步请求在哪一步发起?
1、vue组件可以在created、beforeMount、mounted这三个钩子函数中进行异步请求,因为在这三个钩子函数中,data 已经创建,可以将服务端返回的数据进行赋值。 2、如果异步请求不需要 依赖 Dom , 推荐在 created 钩子函数中发起异步请求,因为在 created 钩子函数中调用异步请求有以下优点: 1> 能更快获取到服务端数据,减少页面 loading 时间; 2> SSR(服务端渲染) 不支持 beforeMount 、mounted 钩子函数,所以放在 created 中有助于一致性;
3、display:none、visibility:hidden 和 opacity:0 之间的区别?
display:none会产生回流与重绘,visibility:hidden 和 opacity:0 只会产生重绘。

4、v-if 和 v-for 为什么最好不要一起使用?
v-for 和 v-if 不要在同一个标签中一起使用,因为 v-for 比 v-if 的优先级高,解析时先解析 v-for 再解析 v-if,这意味着v-if将分别重复运行于每个v-for循环中。如果遇到需要
同时使用时可以考虑写成 计算属性 的方式。
5、怎样理解vue的单向数据流?
在Vue组件中,父子组件之间的关系可以概括为props向下传递、事件向上传递;父组件可以通过props向子组件传递数据,子组件可以通过$emit来向父组件发送消息,当父组件数据变化时,
可以传递给子组件,反之不能,防止子组件无意间修改父组件的状态,导致数据流向的不清晰性,如果子组件想修改父组件的数据,可以采用一种“闭环”的思路:父组件将数据传递给子组件,
子组件可以通过事件来通知父组件修改数据,在传递给子组件。
6、computed 和 watch 以及 methods 的区别和运用的场景
- 相同点:
都是以函数为基础
- 不同点:
-
定义
1、computed 是计算属性,属于自定义属性,依赖其他属性(依赖来自data中的值来进行计算),从而返回一个新的值;
2、watch 是一个对象,键是需要观察的表达式,值是对应回调函数,值也可以是方法名,或者包含选项的对象;
3、methods 是用来定义函数的; - 特点
1、computed 可以通过get与set方法创建数据的双向数据绑定,并且支持缓存机制,且computed的变量不可与data中的变量冲突,可以监控到数组与对象的变化(“自动”变化); 2、watch 监听的属性需要是已经存在的,存在于data中,或者是computed中;可以执行异步操作,一般使用watch做一些逻辑复杂或者是异步操作的事情,以及监听到这个数据
变化之后去做一些别的事情(“自动”的变化);3、methods 每次页面进行重新渲染的时候,都会去执行一次.这样做开销比较大,如果不希望页面有缓存的情况下,可以这么做(它需要手动调用才能执行);
- 使用场景
1、computed 语义上是计算,适用于一个数据受多个数据影响,一般用在模板渲染中; 2、watch 语义上是观察,观测某个值的变化去完成一段复杂的业务逻辑;
3、methods
-
7、vue如何检测数组和对象的变化?
- 源码解析
- 数据的初始化
//创建Vue实例的时候,Vue是一个构造函数,里面的参数是一个对象 options(选项) new Vue({ el: "#app", router, store, render: (h) => h(App), });
- 源码解析:参考文章https://www.cnblogs.com/wxh0929/p/13839758.html
- 是否能在data里面直接使用 prop 的值,为什么?
vue实例初始化状态(initState)时候的顺序依次是:prop > methods > data > computed > watch
- 数据的初始化:
function initData(vm) { let data = vm.$options.data; // 实例的_data属性就是传入的data // vue组件data推荐使用函数 防止数据在组件之间共享 data = vm._data = typeof data === "function" ? data.call(vm) : data || {}; // 把data数据代理到vm 也就是Vue实例上面 我们可以使用this.a来访问this._data.a for (let key in data) { proxy(vm, `_data`, key); } // 对数据进行观测 --响应式数据核心 observe(data); } // 数据代理 function proxy(object, sourceKey, key) { Object.defineProperty(object, key, { get() { return object[sourceKey][key]; }, set(newValue) { object[sourceKey][key] = newValue; }, }); }
- 思考:Object.defineProperty 有什么缺点???
- 数据的初始化

-
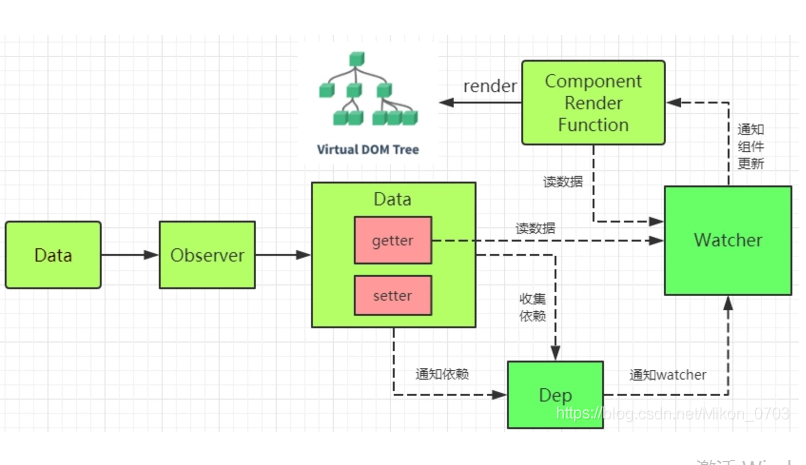
- 响应式数据的核心 ----- defineReactive 函数,主要使用 Object.defineProperty 来对数据 get 和 set 进行劫持,这里就解决了之前的问题,为啥数据变动了会自动更新视图,我们可以在 set 里面去通知视图更新(由于数组元素过多时,性能可能会受到影响,所以此方法只用来劫持对象,但是对象新增或者删除的属性无法被 set 监听到,只有对象本身存在的属性修改才会被劫持)。
// src/obserber/index.js class Observer { // 观测值 constructor(value) { this.walk(value); } walk(data) { // 对象上的所有属性依次进行观测 let keys = Object.keys(data); for (let i = 0; i < keys.length; i++) { let key = keys[i]; let value = data[key]; defineReactive(data, key, value); } } } // Object.defineProperty数据劫持核心 兼容性在ie9以及以上 function defineReactive(data, key, value) { observe(value); // 递归关键 // --如果value还是一个对象会继续走一遍odefineReactive 层层遍历一直到value不是对象才停止 // 思考?如果Vue数据嵌套层级过深 >>性能会受影响 Object.defineProperty(data, key, { get() { console.log("获取值"); return value; }, set(newValue) { if (newValue === value) return; console.log("设置值"); value = newValue; }, }); } export function observe(value) { // 如果传过来的是对象或者数组 进行属性劫持 if ( Object.prototype.toString.call(value) === "[object Object]" || Array.isArray(value) ) { return new Observer(value); } }
- 数组的观测
- 背景
- 响应式数据的核心 ----- defineReactive 函数,主要使用 Object.defineProperty 来对数据 get 和 set 进行劫持,这里就解决了之前的问题,为啥数据变动了会自动更新视图,我们可以在 set 里面去通知视图更新(由于数组元素过多时,性能可能会受到影响,所以此方法只用来劫持对象,但是对象新增或者删除的属性无法被 set 监听到,只有对象本身存在的属性修改才会被劫持)。
由于数组考虑性能方面的原因没有用 Object.defineProperty 对数组的每一项进行拦截,而是选择对数组原型上的7种(push、pop、shift、unshift、splice、sort、reverse)方法进行重写(AOP 切片思想)
所以在 Vue 中修改数组的索引和长度是无法监控到的,需要通过以上 7 种变异方法修改数组才会触发数组对应的 watcher 进行更新
8、vue的父子组件生命周期钩子函数的执行顺序?
1>加载渲染过程 父 beforeCreate->父 created->父 beforeMount->子 beforeCreate->子 created->子 beforeMount->子 mounted->父 mounted 2>子组件更新过程 父 beforeUpdate->子 beforeUpdate->子 updated->父 updated 3>父组件更新过程 父 beforeUpdate->父 updated 4>销毁过程 父 beforeDestroy->子 beforeDestroy->子 destroyed->父 destroyed
9、虚拟Dom是什么,有什么优缺点?
- 概念:虚拟Dom 本质就是用一个原生的 JS 对象去描述一个 DOM 节点,是对真实 DOM 的一层抽象;
- 为什么虚拟Dom会提高性能?
因为虚拟Dom相当于在js和真实的Dom中间加了一个缓存,利用Dom diff算法避免了没有必要的Dom操作,从而提高性能,具体的实现步骤: 1、用JavaScript对象结构表示Dom树的结构,然后用这个树构建一个真正的Dom树,插到文档中; 2、当状态变更的时候,重新构造一颗新的对象树,然后用新的树和旧的树进行比较,记录两棵树的差异; 3、把2所记录的差异应用到步骤1所构建的真正的Dom树上,视图就更新了;
- 虚拟Dom 的缺点
1、无法进行极致优化: 虽然虚拟 DOM + 合理的优化,足以应对绝大部分应用的性能需求,但在一些性能要求极高的应用中虚拟 DOM 无法进行针对性的极致优化; 2、首次渲染大量 DOM 时,由于多了一层虚拟 DOM 的计算,会比 innerHTML 插入慢; - diff算法?
1、把树形结构按照层级分解,只比较同级元素; 2、给列表结构的每个单元添加唯一的key属性,方便比较;
3、React只会匹配相同class的component(class指的是组件的名字)
4、合并操作,调用component的setState方法的时候,React将其标记为dirty,到每一个事件循环结束,React会检查所有标记dirty的component重新绘制;
5、选择性子树渲染,开发人员可以重写shouldComponentUpdate提高diff算法的性能;
10、vue-router的两种模式的区别(核心:跳转URL更新视图但不重新请求/加载页面)
-
hash模式:
在浏览器中符号“#”,#以及#后面的字符称之为hash,用window.location.hash读取; 特点:hash虽然在URL中,但不被包括在HTTP请求中;用来指导浏览器动作,对服务端安全无用,hash不会重加载页面。 hash 模式下,仅 hash 符号之前的内容会被包含在请求中,如
http://www.xiaogangzai.com,因此对于后端来说,即使没有做到对路由的全覆盖,也不会返回 404 错误。history模式:这种模式充分利用
history.pushStateAPI 来完成 URL 跳转而无须重新加载页面history采用HTML5的新特性;且提供了两个新方法:pushState(),replaceState()可以对浏览器历史记录栈进行修改,以及popState事件的监听到状态变更。 history 模式下,前端的 URL 必须和实际向后端发起请求的 URL 一致,如
http://www.xxx.com/items/id。后端如果缺少对 /items/id 的路由处理,将返回 404 错误。Vue-Router 官网里如此描述:“不过这种模式要玩好,还需要后台配置支持……所以呢,你要在服务端增加一个覆盖所有情况的候选资源:如果 URL 匹配不到任何静态资源,则应该返回同一个 index.html 页面,这个页面就是你 app 依赖的页面。” - 参考文章
11、Vue.mixin的原理
当组件初始化时会调用 mergeOptions 方法进行合并,采用策略模式针对不同的属性进行合并。当组件和混入对象含有同名选项时,这些选项将以恰当的方式进行“合并”
12、nextTick的原理
- 主要思路就是采用 微任务优先的方式(
Promise -> MutationObserver -> setImmediate -> setTimeout
) 调用异步方法 去执行 nextTick 包装的方法,如果多次调用nextTick 只会执行一次异步 等异步队列清空之后再把标志变为false; -
// src/util/next-tick.js let callbacks = []; let pending = false; function flushCallbacks() { pending = false; //把标志还原为false // 依次执行回调 for (let i = 0; i < callbacks.length; i++) { callbacks[i](); } } let timerFunc; //定义异步方法 采用优雅降级 if (typeof Promise !== "undefined") { // 如果支持promise const p = Promise.resolve(); timerFunc = () => { p.then(flushCallbacks); }; } else if (typeof MutationObserver !== "undefined") { // MutationObserver 主要是监听dom变化 也是一个异步方法 let counter = 1; const observer = new MutationObserver(flushCallbacks); const textNode = document.createTextNode(String(counter)); observer.observe(textNode, { characterData: true, }); timerFunc = () => { counter = (counter + 1) % 2; textNode.data = String(counter); }; } else if (typeof setImmediate !== "undefined") { // 如果前面都不支持 判断setImmediate timerFunc = () => { setImmediate(flushCallbacks); }; } else { // 最后降级采用setTimeout timerFunc = () => { setTimeout(flushCallbacks, 0); }; }
13、keep-alive
- 概念:
keep-alive是一个抽象组件:它自身不会渲染一个 DOM 元素,也不会出现在父组件链中,使用keep-alive包裹动态组件时,会缓存不活动的组件实例,而不是销毁它们。
- 属性:
include定义缓存白名单,keep-alive会缓存命中的组件;exclude定义缓存黑名单,被命中的组件将不会被缓存;max定义缓存组件上限,超出上限使用 LRU的策略 置换缓存数据。
- LRU(最近最少使用算法----队列)
LRU 的核心思想是如果数据最近被访问过,那么将来被访问的几率也更高,所以我们将命中缓存的组件 key 重新插入到 this.keys 的尾部,这样一来,this.keys 中越往头部的数据
即将来被访问几率越低,所以当缓存数量达到最大值时,我们就删除将来被访问几率最低的数据,即 this.keys 中第一个缓存的组件(头部数据丢失)。 - 根据组件 ID 和 tag 生成缓存 Key,并在缓存对象this.cache中查找是否已缓存过该组件实例。如果存在,直接取出缓存值并更新该 key 在 this.keys 中的位置
- 参考文章
14、首屏加载优化的方案
1 Vue-Router路由懒加载(利用Webpack的代码切割)(如果使用了一些UI库,采用按需加载) 2 使用CDN加速,将通用的库从vendor进行抽离 3 Nginx的gzip压缩、Webpack开启gzip压缩 4 Vue异步组件 5 服务端渲染SSR 6 如果首屏为登录页,可以做成多入口 7 Service Worker缓存文件处理 8 使用link标签的rel属性设置 prefetch(这段资源将会在未来某个导航或者功能要用到,但是本资源的下载顺序权重比较低,prefetch通常用于加速下一次导航)、
preload(preload将会把资源得下载顺序权重提高,使得关键数据提前下载好,优化页面打开速度)
15、SSR
- 概念
SSR 也就是服务端渲染,也就是将 Vue 在客户端把标签渲染成 HTML 的工作放在服务端完成,然后再把 html 直接返回给客户端;
- 优点
- 更好的 SEO,由于搜索引擎爬虫抓取工具可以直接查看完全渲染的页面;请注意,截至目前,Google 和 Bing 可以很好对同步 JavaScript 应用程序进行索引。在这里,同步是关键。如果你的应用程序初始展示 loading 菊花图,然后通过 Ajax 获取内容,抓取工具并不会等待异步完成后再行抓取页面内容。也就是说,如果 SEO 对你的站点至关重要,而你的页面又是异步获取内容,则你可能需要服务器端渲染(SSR)解决此问题;
- 首屏加载速度快:首屏的渲染是node发送过来的html字符串,并不依赖于js文件了,这就会使用户更快的看到页面的内容。尤其是针对大型单页应用,打包后文件体积比较大,普通客户端渲染加载所有所需文件时间较长,首页就会有一个很长的白屏等待时间。
- 缺点
-
服务端压力较大:本来是通过客户端完成渲染,现在统一到服务端node服务去做。尤其是高并发访问的情况,会大量占用服务端CPU资源;
- 开发条件受限:在服务端渲染中,created和beforeCreate之外的生命周期钩子不可用,当我们需要一些外部扩展库时需要特殊处理,服务端渲染应用程序也需要处于 Node.js 的运行环境;
- 学习成本相对较高:除了对webpack、Vue要熟悉,还需要掌握node、Express相关技术。相对于客户端渲染,项目构建、部署过程更加复杂。
-
16、v-model的原理
- 示例:
 View Code
View Code/ 定义 v-model 示例组件 Vue.component('bindData', { template:` <div> <p>this is bindData component!</p> <button @click="handleChange">change input value</button> <input type="text" v-model="inputValue" /> <p>{{inputValue}}</p> </div> `, data() { return { inputValue: 'hello' } }, methods:{ // 点击按钮改变 input 的值 handleChange() { this.inputValue = `I'm changed`; } } }); const app=new Vue({ el: '#app', template: ` <div> <bindData /> </div> ` });
View Code// 定义 v-model 示例组件改写 Vue.component('bindData1', { template:` <div> <p>this is bindData1 component!</p> <button @click="handleChange">change input value</button> <input type="text" :value="inputValue" @change="handleInputChange" /> <p>input 中的值为:{{inputValue}}</p> </div> `, data() { return { inputValue: 'hello' } }, methods:{ // 处理 input 输入 change 事件 handleInputChange(e) { this.inputValue = e.target.value; }, // 点击按钮改变 input 的值 handleChange() { this.inputValue = `I'm changed`; } } }); const app=new Vue({ el: '#app', template: ` <div> <bindData1 /> </div> ` });
第二个主要改动:
-
1、将 input 标签上的 v-model 指令去掉了,换成了用 v-bind:value(缩写 :value) 指令来绑定 inputValue 属性,并且加上了一个 v-on:change(缩写 ) 事件;
-
2、添加了一个 input change 处理函数,函数逻辑是将 当前 input 标签的值 赋值给 $data 的 inputValue 属性
-
- 总结

v-model 只是一种封装或者语法糖,负责监听用户的输入事件以更新数据,并对一些极端场景进行特殊处理,v-model 在不同的 HTML 标签上会使用v-bind监控不同的属性和使用v-on抛出不同的事件。
text 和 textarea 元素使用
value属性和input事件;checkbox 和 radio 使用
checked属性和change事件;select 字段将
value作为 prop 并将change作为事件
17、vue.set的原理
- 原理
class Observer { // 观测值 constructor(value) { Object.defineProperty(value, "__ob__", { // 值指代的就是Observer的实例 value: this, // 不可枚举 enumerable: false, writable: true, configurable: true, }); } }
给每个响应式数据增加了一个不可枚举的__ob__属性,并且指向了 Observer 实例 ,那么我们 首先 可以根据这个属性来防止已经被响应式观察的数据反复被观测 ,其次 响应式数据可以使用__ob__来获取 Observer 实例的相关方法这对数组很关键,当给对象新增不存在的属性 首先会把新的属性进行响应式跟踪 然后会触发对象__ob__的 dep 收集到的 watcher 去更新,当修改数组索引时我们调用数组本身的 splice 方法去更新数组
19、vue自定义指令的原理
- 理解
指令本质上是装饰器,是vue对HTML元素的扩展,给HTML元素增加自定义功能,语义化HTML标签。vue编译DOM时,会执行与指令关联的JS代码,即找到指令对象,执行指令对象的相关方法
-
1.在生成 ast 语法树时,遇到指令会给当前元素添加 directives 属性
2.通过 genDirectives 生成指令代码
3.在 patch 前将指令的钩子提取到 cbs 中,在 patch 过程中调用对应的钩子
4.当执行指令对应钩子函数时,调用对应指令定义的方法
20、
21、
二、js相关
1、什么是闭包?
- 作用域:作用域就是一套规则,用于确定在何处以及如何查找变量(标识符)的规则 ----- 严格来讲是变量可以被访问到的空间;
- 作用域的分类:ES5包括(函数作用域以及全局作用域),ES6新增了块级作用域;
- 作用域链:每个函数都有一个作用域,查找变量或者函数时,需要从局部作用域到全局作用域依次查找,这些作用域的集合称 作用域链;
- 参考文章:
- 闭包的基本原理
在正常情况下,外界是无法访问函数内部的变量的,因为在函数执行完毕之后,上下文即将被销毁。但是如果我们在函数中,返回了另一个函数,且这个返回的函数使用了函数内的变量,
那么外界便可以通过这个返回的函数获取原函数内部的变量值,这就是闭包的基本原理 ; - 闭包的概念
有权访问另一个函数作用域中变量的函数,闭包的存在形式在于在一个函数中返回了另一个函数,并且通过另一个函数访问函数内部的变量;
- 闭包的特点
1 函数内嵌套函数; 2 内部的函数可以访问外部的参数和变量; 3 外部的参数和变量不会被垃圾回收机制回收;
- 闭包的优点
1 突破了作用域链,将函数内部的参数和变量传递到外部; - 闭包的缺点
- 什么是内存泄漏
内存空间明明已经不在被使用,但由于某种原因并没有被释放的现象,内存泄漏的危害非常直观,它会直接导致程序运行缓慢,甚至崩溃。
- JS哪些操作会引起内存泄漏???
- 意外的全局变量引起的内存泄漏
- 闭包引起的内存泄漏,参考文章:https://blog.csdn.net/Leo____Wang/article/details/80115050
var a = []; for(var i = 0;i < 10;i++){ a[i] = function(){ console.log(i) } } a[6]()// 10 //解析:var声明的变量在全局范围内有效,所以全局只有一个变量i 解决方法 1、加一层闭包,i 以函数参数形式传递给内层函数,自执行函数,第一个i是函数的形参,是私有变量,与外面的i没有关系,被私有作用域保护起来了,
第二个i才是函数中外面的i(也就是说第一个i只是一个迷惑人的量,你改成k也是一样的结果,只不过是把i赋给k而已) var a = []; for(var i = 0;i < 10;i++){ (function(i){ a[i] = function(){ console.log(i) } })(i) } 2、加一层闭包,返回一个函数作为响应事件 var a = []; for(var i = 0;i < 10;i++){ a[i] = function(){ return function(){ console.log(i) } }(i) } 3、找个属性将i值保存起来 4、let - 没有清理的Dom元素引用
var element = document.getElementById("element"); element.marked = "marked"; //移除节点 function remove(){ element.parentNode.removeChild(element); } //解析:只是移除了dom节点,但是element变量依然存在,需要添加element = null;
- 被遗忘的定时器或者回调
function foo(){ let name = 'lucas'; window.setInterval(()=>{ console.log(name); },1000) } foo(); //解析:一般函数执行完毕之后,上下文即将被销毁,但是由于存在window.setInterval,所以name的内存空间始终无法释放,所以我们要在合适的时机使用
clearInterval对其进行清理 - 子元素存在引起的内存泄漏
var element = document.getElementById("element"); element.innerHTML = '<button id = 'button'>点击</button>' var button = document.getElementById("button"); button.addEventListener('click',function(){ }) element.innerHTML = '' //解析:element.innerHTML = ''表示button已经从dom中移除,但是事件处理程序还在,所以变量依旧没有办法回收,所以我们需要添加removeEventListener移除事件,
防止内存泄漏
- 闭包总结
所以无论通过哪种方式将内部的函数传递到所在的词法作用域以外,它都会持有对原始作用域的引用,无论在何处执行这个函数都会使用闭包;
- 闭包的注意事项
1、因为闭包可以使函数中的参数和变量都保存在内存中,造成很大的内存消耗,所以如果不是某些特定的任务需要使用闭包,我们不要滥用它。 2、使用不当的闭包会在 IE(IE9)之前 造成内存泄漏问题。因为它的JavaScript引擎 使用的垃圾回收算法是引用计数法,对于循环引用将会导致GC无法回收“应该被回收”的内存。
造成了无意义的内存占用,也就是内存泄漏。
2、垃圾回收机制GC(Garbage Collection)
- 内存管理:是指对内存生命周期的管理,而内存的生命周期无外乎分配内存、读写内存、释放内存,对于分配内存和读写内存的行为,所有语言都较为一致,但是释放内存的行为在不同语言之间有差异;
- 内存空间的类型
1 栈空间(操作系统自动分配释放,内存大小固定) 2 堆空间(开发者分配释放,内存大小不一定,也不一定会自动释放)
- 垃圾回收的概念
GC把程序不用的内存空间视为垃圾,找到它们并且将它们回收,让程序员可以再次利用这部分空间,当然,不是所有的语言都有GC,一般存在于高级语言中,如Java、JavaScript、Python
。那么在没有GC的世界里,程序员就比较辛苦,只能手动去管理内存,比如在C语言中我们可以通过malloc/free,在C++中的new/delete来进行管理 - 垃圾回收算法
-
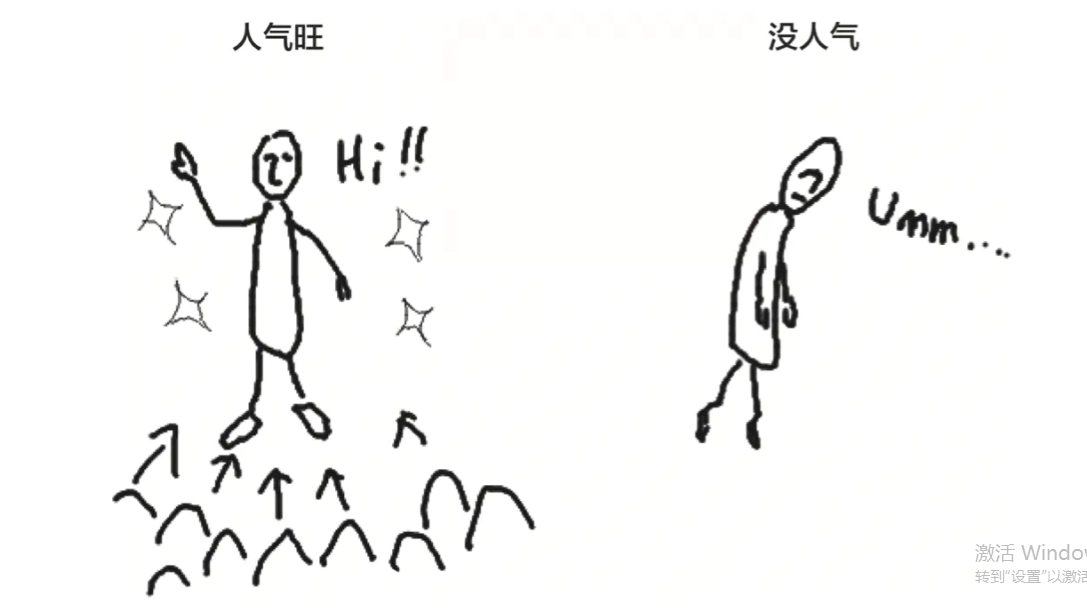
- 引用计数法
-
-
- 概念
引入了计数器的概念,通过计数器来表示对象的“人气指数”,也就是有多少个程序引用了这个对象。当计数器(引用数)为0时,垃圾立刻被回收
- 优点
1、可以立即回收垃圾,当被引用数值为0时,对象马上会把自己作为空闲空间连到空闲链表上,也就是说。在变成垃圾的时候就立刻被回收。
2、因为是即时回收,那么‘程序’不会暂停去单独使用很长一段时间的GC,那么最大暂停时间很短。
3、不用去遍历堆里面的所有活动对象和非活动对象 - 缺点
1、计数器需要占很大的位置,因为不能预估被引用的上限,打个比方,可能出现32位即2的32次方个对象同时引用一个对象,那么计数器就需要32位。 2、最大的劣势是无法解决循环引用无法回收的问题 这就是前文中IE9之前出现的问题 - 举例 ----- 循环引用
function f(){ var o = {}; var o2 = {}; o.a = o2; // o 引用 o2,o2的引用次数是1 o2.a = o; // o2 引用 o,o的引用此时是1 return "azerty"; } f();
解析:
fn在执行完成之后理应回收fn作用域里面的内存空间,但是因为
o里面有一个属性引用o2,导致o2的引用次数始终为1,o2也是如此,而又非专门当做闭包来使用,所以这里就应该使o和o2被销毁。因为算法是将引用次数为0的对象销毁,此处都不为0,导致GC不会回收他们,那么这就是内存泄漏问题。该算法已经逐渐被 ‘标记-清除’ 算法替代,在V8引擎里面,使用最多的就是
标记-清除算法
- 概念
-
-
- GC标记-清除算法:是一个定时运行的任务(会按照固定的时间间隔周期性的进行),也就是说当程序运行一段时间后,统一GC
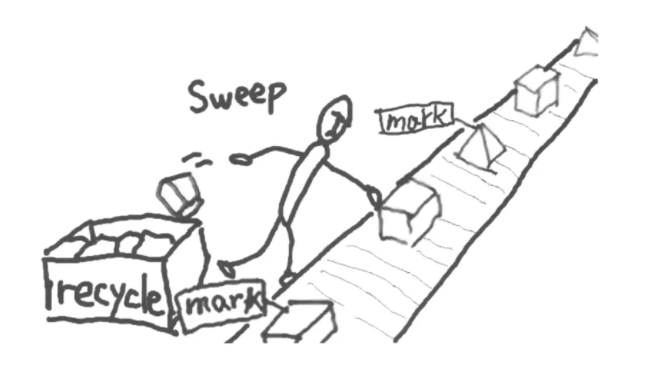
由标记阶段和清除阶段构成,标记阶段将所有的活动对象做上相应的标记,清除阶段把那些没有标记的对象,也就是非活动对象进行回收。在搜索对象并进行标记的时候使用了深度优先搜索,尽可能的从深度上搜索树形结构
-
-
- 活动对象与非活动对象
var a = {name: 'bar'} // '这个对象'被a引用,是活动对象。 a=null; // ‘这个对象’没有被a引用了,这个对象是非活动对象。 - 工作流程
- 活动对象与非活动对象
-
标记阶段:
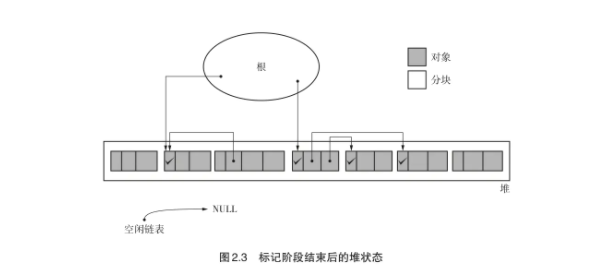
解析:
根可以理解成我们的全局作用域,GC从全局作用域的变量,沿作用域 逐层往里遍历(深度遍历或者深度优先搜索),当遍历到堆中对象时,说明该对象被引用着,则打上一个标记,继续递归遍历(因为肯定存在堆中对象引用另一个堆中对象),直到遍历到最后一个(最深的一层作用域)节点

清除阶段:遍历整个堆,回收没有打上标记的对象
-
-
- 优点
1、实现简单,打标记也就是打或者不打两种可能,所以就一位二进制位就可以表示2、解决了循环引用的问题,因为两个对象从全局对象出发无法获取。因此,他们无法被标记,他们将会被垃圾回收器回收。
- 优点
-

-
-
- 缺点
1、造成碎片化(有点类似磁盘的碎片化),导致无数的小分块散布在堆的各个地方;2、分配速度,由于分块的不连续性,算法每次分配的时候都需要遍历空闲链表(保存堆中所有空闲地址空间的地址形成的链表)为了找到足够大的分块,这样最糟糕的情况就是遍历到最后才找到合适的分 块,影响了分配速度;
- 举例
- 缺点
-
3、箭头函数与普通函数的区别?
- 箭头函数的特点
1 语法更简洁 2 没有this 3 捕获其所在上下文的 this 值,作为自己的 this 值 4 箭头函数作为匿名函数,是不能作为构造函数的,不能使用 new 5 箭头函数没有原型属性,prototype是undefined 6 不能简单返回对象,如果要返回对象时需要用小括号包起来,因为大括号被占用解释为代码块了 7 箭头函数不能换行 8 箭头函数不能当做Generator函数,不能使用yield关键字 9 不绑定arguments,使用时报错arguments is not undefined,所以用 rest参数...解决 10 /*箭头函数使用reset参数...解决*/ 11 let test3=(...a)=>{console.log(a[1])} //22 12 test3(33,22,44); 13 由于 this 已经在词法层面完成了绑定,通过 call() 或 apply() 方法调用一个函数时,只是传入了参数而已,对 this 并没有什么影响
-
var a = ()=>{ return 1 } function b(){ return 2 } console.log(a.prototype) console.log(b.prototype)

4、判断参数是否是数组的方式
1 Array.isArray(arr) 2 Object.prototype.toString.call(arr) === '[Object Array]' 3 arr instanceof Array 4 array.constructor === Array
5、判断类型的方式
1 typeof 2 //解析:只能区分基本类型,对于null、array、function、object来说,使用typeof都会统一返回object字符串 3 4 instanceof:用来判断对象是不是某个构造函数的实例。会沿着原型链找的 5 6 7 Object.prototype.toString.call() 8 //解析:判断某个对象属于哪种内置类型 9 var toString = Object.prototype.toString; 10 11 toString.call(new Date); // [object Date] 12 toString.call(new String); // [object String] 13 toString.call(Math); // [object Math] 14 toString.call([]); // [Object Array] 15 toString.call(new Number) // [object Number] 16 toString.call(true) // [object Boolean] 17 toString.call(function(){}) // [object Function] 18 toString.call({}) // [object Object] 19 toString.call(new Promise(() => {})) // [object Promise] 20 21 toString.call(new Map) // [object Map] 22 toString.call(new RegExp) // [object RegExp] 23 toString.call(Symbol()) // [object Symbol] 24 toString.call(function *a(){}) // [object GeneratorFunction] 25 toString.call(new DOMException()) // [object DOMException] 26 toString.call(new Error) // [object Error] 27 28 toString.call(undefined); // [object Undefined] 29 toString.call(null); // [object Null] 30 31 // 还有 WeakMap、 WeakSet、Proxy 等
6、在浏览器输入URL点击回车之后发生了什么?
- 参考链接
7、new操作符具体干了什么?

function Fn(){
}
let fn= new Fn();new共经历了四个过程: 1、创建了一个空对象 let obj = new Object(); 2、设置原型链,此时便建立了 obj 对象的原型链:obj->Fn.prototype->Object.prototype->null obj.__proto__ = Fn.prototype; 3、让Fn的this指向obj,并执行Fn的函数体 let result = Fn.call(obj); 4、判断Fn的返回值类型,如果是值类型,返回obj,如果是引用类型,就返回这个引用类型的对象 if(typeof(result) === 'object){ fn = result }else{ fn = obj }
8、TCP的三次握手与四次挥手?(发生在传输层)来源:@bear鲍的熊
- TCP协议是面向连接的运输层协议在数据传输前必须建立连接,数据传输之后释放连接;
- TCP提供全双工通信所谓全双工是指一端既可以是客户端,也可以是服务器;
- TCP的三次握手:

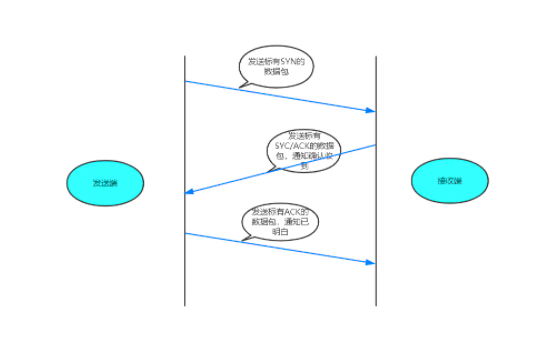
1、第一次握手:起初两端都处于CLOSED关闭状态,Client将标志位SYN置为1,随机产生一个值seq=x,并将该数据包发送给Server,Client进入SYN-SENT状态,等待Server确认; 2、第二次握手:Server收到数据包后由标志位SYN=1得知Client请求建立连接,Server将标志位SYN和ACK都置为1,ack=x+1,随机产生一个值seq=y,并将该数据包发送给Client以
确认连接请求,Server进入SYN-RCVD状态,此时操作系统为该TCP连接分配TCP缓存和变量; 3、第三次握手:Client收到确认后,检查ack是否为x+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=y+1,并且此时操作系统为该TCP连接分配TCP缓存和变量,并将该数据包发
送给Server,Server检查ack是否为y+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client和Server就可以开始传输数据。
- TCP的四次挥手:
假设Client端发起中断连接请求,也就是发送FIN报文。Server端接到FIN报文后,意思是说"我Client端没有数据要发给你了",但是如果你还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以你先发送ACK,"告诉Client端,你的请求我收到了,但是我还没准备好,请继续你等我的消息"。这个时候Client端就进入FIN_WAIT状态,继续等待Server端的FIN报文。当Server端确定数据已发送完成,则向Client端发送FIN报文,"告诉Client端,好了,我这边数据发完了,准备好关闭连接了"。Client端收到FIN报文后,"就知道可以关闭连接了,但是他还是不相信网络,怕Server端不知道要关闭,所以发送ACK后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传。“,Server端收到ACK后,"就知道可以断开连接了"。Client端等待了2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,我Client端也可以关闭连接了。Ok,TCP连接就这样关闭了!

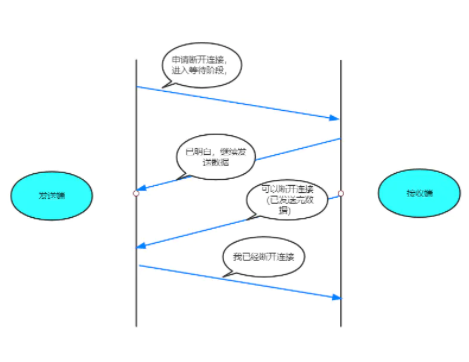
1、A的应用进程先向其TCP发出连接释放报文段(FIN=1,序号seq=u),并停止再发送数据,主动关闭TCP连接,进入FIN-WAIT-1(终止等待1)状态,等待B的确认。
2、B收到连接释放报文段后即发出确认报文段,(ACK=1,确认号ack=u+1,序号seq=v),B进入CLOSE-WAIT(关闭等待)状态,此时的TCP处于半关闭状态,A到B的连接释放。
3、A收到B的确认后,进入FIN-WAIT-2(终止等待2)状态,等待B发出的连接释放报文段。
4、B没有要向A发出的数据,B发出连接释放报文段(FIN=1,ACK=1,序号seq=w,确认号ack=u+1),B进入LAST-ACK(最后确认)状态,等待A的确认。
5、A收到B的连接释放报文段后,对此发出确认报文段(ACK=1,seq=u+1,ack=w+1),A进入TIME-WAIT(时间等待)状态。此时TCP未释放掉,需要经过时间等待计时器设置的时间2MSL后,
A才进入CLOSED状态。
- 参考链接
- TCP可以二次握手吗?
- **主要为了防止已失效的连接请求报文段突然又传送到了B,因而产生错误。**如A发出连接请求,但因连接请求报文丢失而未收到确认,于是A再重传一次连接请求。后来收到了确认,建立了连接。数据传输完毕后,就释放了连接,A发出了两个连接请求报文段,其中第一个丢失,第二个到达了B,但是第一个丢失的报文段只是在某些网络结点长时间滞留了,延误到连接释放以后的某个时间才到达B,此时B误认为A又发出一次新的连接请求,于是就向A发出确认报文段,同意建立连接,不采用三次握手,只要B发出确认,就建立新的连接了,此时A不理睬B的确认且不发送数据,则B一致等待A发送数据,浪费资源
- Server端易受到SYN泛洪攻击?
服务器端的资源分配是在二次握手时分配的,而客户端的资源是在完成三次握手时分配的,所以服务器容易受到SYN泛洪攻击,SYN攻击就是Client在短时间内伪造大量不存在的IP地址,并向Server不断地发送SYN包,Server则回复确认包,并等待Client确认,由于源地址不存在,因此Server需要不断重发直至超时,这些伪造的SYN包将长时间占用未连接队列,导致正常的SYN请求因为队列满而被丢弃,从而引起网络拥塞甚至系统瘫痪。
防范SYN攻击措施:降低主机的等待时间使主机尽快的释放半连接的占用,短时间受到某IP的重复SYN则丢弃后续请求。
- 为什么 A 在TIME-WAIT状态必须等待2MSL的时间?(MSL最长报文段寿命Maximum Segment Lifetime,MSL=2)
原因:1)**保证A发送的最后一个ACK报文段能够到达B。**这个ACK报文段有可能丢失,使得处于LAST-ACK状态的B收不到对已发送的FIN+ACK报文段的确认,B超时重传FIN+ACK报文段,而A能在2MSL时间内收到这个重传的FIN+ACK报文段,接着A重传一次确认,重新启动2MSL计时器,最后A和B都进入到CLOSED状态,若A在TIME-WAIT状态不等待一段时间,而是发送完ACK报文段后立即释放连接,则无法收到B重传的FIN+ACK报文段,所以不会再发送一次确认报文段,则B无法正常进入到CLOSED状态。
原因:2)防止“已失效的连接请求报文段”出现在本连接中。A在发送完最后一个ACK报文段后,再经过2MSL,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失,使下一个新的连接中不会出现这种旧的连接请求报文段。
- 为什么连接的时候是三次握手,关闭的时候却是四次握手?
因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,"你发的FIN报文我收到了"。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手
- 优化,我们可以通过修改系统参数来优化服务器
tcp_tw_reuse: 是否重用处于TIME_WAIT状态的TCP链接 (设为true) tcp_max_tw_buckets: 处于TIME_WAIT状态的SOCKET最大数目 (调大,这个参数千万不要调小了) tcp_fin_timeout: 处于FIN_WAIT_2的时间 (调小)
9、使用JSON.parse(JSON.stringify(obj))实现深拷贝应该注意的坑
- 当对象里面有时间对象,深拷贝后时间将变成字符串的格式
View Code
/** * 当对象里面有时间对象 */ let obj = { name: "wxh", data: [new Date(), new Date()], }; let objClone = JSON.parse(JSON.stringify(obj)); obj.name = "wxh1234"; console.log(obj); console.log(typeof obj.data[0]); console.log("---------"); console.log(objClone); console.log(typeof objClone.data[0]);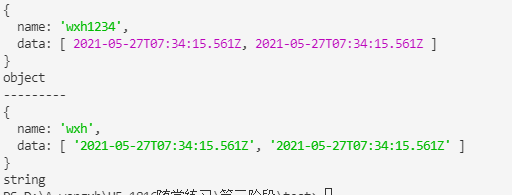
- 当对象里面有RegExp、Error对象,深拷贝后将变成空对象
View Code
let obj = { name: "wxh", data: [new RegExp(/w+/), new Error("1234")], }; let objClone = JSON.parse(JSON.stringify(obj)); obj.name = "wxh1234"; console.log(obj); console.log("---------"); console.log(objClone);
- 当对象里面有Function和undefined时,深拷贝将会丢失,也就是如果元素在数组中,这一项变成null
View Code
let obj = { name: "wxh", data: function () { console.log("function"); }, data2: undefined, }; let objClone = JSON.parse(JSON.stringify(obj)); obj.name = "wxh1234"; console.log(obj); console.log("---------"); console.log(objClone);
- 当对象里面有NAN时,深拷贝将会变成null
View Code
let obj = { name: "wxh", data: NaN, }; let objClone = JSON.parse(JSON.stringify(obj)); obj.name = "wxh1234"; console.log(obj); console.log("---------"); console.log(objClone);
- 当对象里面的一个参数是由构造函数生成的,则会丢失constructor
View Code
function Person() { this.name = "wxh"; } let person = new Person(); let obj = { name: "wxh", data: person, }; let objClone = JSON.parse(JSON.stringify(obj)); obj.name = "wxh1234"; console.log(obj); console.log(obj.__proto__.constructor); console.log("---------"); console.log(objClone); console.log(objClone.__proto__.constructor);

10、Object.create()、new Object()和 {} 的区别
字面量和new关键字创建的对象是Object的实例,原型指向Object.prototype,继承内置对象Object
- 字面量的方式:字面量是创建对象最简单的一种形式,目的在于简化创建包含大量属性的对象的过程,由若干属性名与属性值成对组成的映射表,映射表用 {} 包起来;
var objA = {}; objA.name = 'a'; objA.sayName = function() { console.log(`My name is ${this.name} !`); } // var objA = { // name: 'a', // sayName: function() { // console.log(`My name is ${this.name} !`); // } // } objA.sayName(); console.log(objA.__proto__ === Object.prototype); // true console.log(objA instanceof Object); // true
- 构造函数的方式:
var objA = new Object(); objA.name = "a"; objA.sayName = function () { console.log(`My name is ${this.name} !`); }; objA.sayName(); console.log(objA.__proto__ === Object.prototype); // true console.log(objA instanceof Object); // true
- Object.create(proto,[propertiesObject])方法创建一个新对象,使用现有的对象来提供新创建的对象的__proto__(原型对象);
const person = { name: "wxh", show: function () { console.log(`My name is ${this.name}.My age is ${this.age}.`); }, }; person.show(); //My name is wxh.My age is undefined. const me = Object.create(person); // me.__proto__ === person me.name = "kevin"; // 继承的属性可以被重写 me.age = 22; // me.show(); // My name is kevin.My age is 22. console.log(me.__proto__ === Object.prototype); // false console.log(me.__proto__ === person); // true console.log(me instanceof Object); // true
当第一个参数为null时,生成的对象为空对象,没有原型,不继承任何内置对象
const me = Object.create(null); console.log(me.__proto__); //undefined console.log(me.__proto__ === Object.prototype); // false console.log(me instanceof Object); // false
11、Event Loop
-
1、第一步确认宏任务,微任务 宏任务:script,setTimeout,setImmediate,promise中的executor(是同步函数,立即执行的一个函数) 微任务:promise.then,process.nextTick 2、第二步解析“拦路虎”,出现async/await不要慌,他们只在标记的函数中能够作威作福,出了这个函数还是跟着大部队的潮流 3、第三步,根据Promise中then使用方式的不同做出不同的判断,是链式还是分别调用
4、最后一步记住一些特别事件:比如,process.nextTick优先级高于Promise.then - 参考文章:
12、HTTP与HTTPS的区别
- HTTP的URL由
http://起始且默认使用端口80,而HTTPS的URL由https://起始且默认使用端口443; - HTTP是超文本传输协议,信息是明文传输,HTTPS则是具有安全性的 SSL 加密传输协议;
- HTTP的连接很简单,是无状态的,HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 http 协议安全;
13、
三、算法相关
- Promise.all
View Code
/** * IsInterator 是否含有Interator接口 * @param {*} iterators */ function IsInterator(target){ return typeof target[Symbol.iterator] === 'function' } /** * Promise.all方法的特点 * 1、参数必须是一个部署了iterator接口的对象 * 2、参数中的每个实例都必须是promise的实例,如果不是,如果不是,使用Promise.resolve方法将其转换 * 3、如果全部成功,状态变为 resolved,返回值将组成一个数组传给回调 * 4、只要有一个失败,状态就变为 rejected,返回值将直接传递给回调 * 5、返回值是一个Promise对象 */ var promiseAll = function (iterators) { if (!IsInterator(iterators)) throw new Error('arguments is not contain interators structure'); const resolveAry = []; let rejectAry = []; const len = iterators.length; let counter = 0; return new Promise((resolve, reject) => { // 保证循环的顺序 for (let data of iterators) { if (!(data instanceof Promise)) { data = Promise.resolve(data); } data.then((res) => { counter++; resolveAry.push(res); if (counter === len) { return resolve(resolveAry); } }).catch((err) => { rejectAry.push(err) reject(rejectAry) }); } }); }; //测试 let res1 = promiseAll(1); //结果:Error: arguments is not contain interators structure let res2 = promiseAll([1,2,3,new Promise((resolve,reject)=>{ reject("no"); })]); //结果: fail [ 'no' ] let res3 = promiseAll([new Promise((resolve,reject)=>{ resolve("success1"); }),new Promise((resolve,reject)=>{ resolve("success2"); })]) //结果: success [ 'success1', 'success2' ] res3.then((data)=>{ console.log('success') console.log(data) }).catch((err)=>{ console.log('fail') console.log(err) })
Promise.race
View Codevar promiseRace = function (iterators) { if (!IsInterator(iterators)) throw new Error("arguments is not contain interators structure"); return new Promise((resolve, reject) => { for (let data of iterators) { if (!(data instanceof Promise)) { data = Promise.resolve(data); } data .then((res) => { resolve(res); }) .catch((e) => { reject(e); }); } }); }; let res4 = Promise.race([ new Promise((resolve, reject) => { setTimeout(() => { resolve("quickly"); }, 1000); }), new Promise((resolve, reject) => { setTimeout(() => { reject("man man "); }, 500); }), ]) .then((data) => { console.log("race success----"); console.log(data); }) .catch((e) => { console.log("race fail----"); console.log(e); });

- 实现千分位分隔符
View Code
/** * formatMoney 金额的格式化函数 * @param {Number/String} num 要格式化的金额数值 * @param {Number} n 要保留的小数位数,默认值为2 * @param {String} symbol 千分位分隔符 */ var formatMoney = function (num, n = 2, symbol = ",") { if (n < 0 || n > 20) throw new Error("argument error"); /** * 输入多个 0 的情况 */ if (Number(num) === 0) return 0; num = Number(num); /** * true表示是小数 */ let hasDot = parseInt(num) !== num; /** * */ let m = n !== undefined && n !== null ? n : 1; /** * 1、我们的思路是:通过 . 为参考方向来匹配多个连接的三位数字来加千分位,因此当n === 0时,确保有一个 . * 2、判断是否是小数,如果是小数,且指定小数位数n,则四舍五入,若是小数没有指定小数位数,则返回原值 * 3、若传入的值是整数,n === 0 的情况在第一种,n 不传值 以及 n > 0 */ num = m === 0 ? num.toFixed(m) + "." : hasDot ? n ? num.toFixed(n) : num : num.toFixed(m); console.log(num); /** * 默认的千分位分隔符 */ // symbol = symbol || ","; /** * 用正则来匹配千分位分隔符:语法 x(?=y): 正向肯定查找,匹配后面带有y的x项目 * 这个正则用来查找一个和 . 之间带有一个或者多个 连续三位数字的数字x */ let regExp = /(d)(?=(d{3})+.)/g; num = num.toString().replace(regExp, function (match, p1, p2) { /** * match与p1是匹配到的 x,p2是 y */ console.log(match); console.log(p1); console.log(p2); return p1 + symbol; }); /** * 如果n为0,或者传入的整数没有指定整数的保留位数,则去掉前面操作的整数位 */ if (n === 0 || (!hasDot && !n)) { num = num.substring(0, num.indexOf(".")); } return num; }; console.log(formatMoney(7654321, 0));
- 防抖
View Code
/** * debounce 防抖:在事件被触发n秒后再执行回调,如果在这n秒内又被触发,则重新计时 * 适用场景: * 1、按钮提交场景:防止多次提交按钮,只执行最后提交的一次 * 2、服务端验证场景:表单验证需要服务端配合,只执行一段连续的输入事件的最后一次,还有搜索联想词功能类似 */ var debounce = function (fn, delay) { let timer = null; return function () { // 中间态进行清除 if (timer) { clearTimeout(timer); } timer = setTimeout(() => { console.log("防抖"); console.log(this); console.log(arguments); fn.apply(this, arguments); }, delay); }; }; console.log(1); let fn = debounce(() => { console.log("submit按钮多次提交或者搜索"); }); fn(); console.log(2);节流:
View Code/** * 节流:规定在一个单位时间内,只能触发一次函数。如果这个单位时间内触发多次函数,只有一次生效 * 适用场景: * 1、拖拽场景:固定时间内只执行一次,防止超高频次触发位置变动 * 2、缩放场景:监控浏览器resize * 3、动画场景:避免短时间内多次触发动画引起性能问题 */ /** * 定时器版本:优缺点,首次不会执行,会有delay的延迟 */ var throttle = function (fn, delay = 500) { let flag = false; return () => { if (flag) return; //正在执行,不允许发送其他操作 flag = true; //发送前,设置关卡,其他时间就不能执行了 setTimeout(() => { console.log("节流"); fn.apply(this, arguments); flag = false; }, delay); }; }; /** * 时间戳来处理首次和间隔执行问题,定时器来确保最后一次状态改变执行 * @param {Function} fn 函数 * @param {Number} delay 时间间隔 * @returns */ var throttling = function (fn, delay = 500) { let lastTime = 0; let timer = null; return function () { let nowTime = new Date().getTime(); let timeDiff = nowTime - lastTime; //间隔时间 if (lastTime && timeDiff < delay) { // 为了响应用户的最后一次操作: timer && clearTimeout(timer); timer = setTimeout(() => { lastTime = new Date().getTime(); fn.apply(this, arguments); }, delay - timeDiff); return; } // 首次或到时间了 lastTime = now; fn.apply(this, arguments); timer && clearTimeout(timer); }; };一般使用第三方库lodash来进行防抖与节流
- 实现instanceof
View Code
/** * 模拟instanceOf方法 * @param {*} L 实例 * @param {*} R 构造函数 * @returns */ var instanceOf = function (L, R) { let __proto__ = L.__proto__; let prototype = R.prototype; while (true) { if (__proto__ === null) return false; if (__proto__ === prototype) { return true; } __proto__ = __proto__.__proto__; } }; let obj = { name: "wxh" }; console.log(instanceOf(obj, Array)); //false console.log(instanceOf(obj, Object)); //true - 模拟new
View Code
/** * 1、创建一个空对象 * 2、设置原型链 * 3、改变this指向 * 4、返回值 */ var newMethod = function () { let obj = new Object(); console.log(arguments); //{ '0': [Function: Person], '1': 'wxh' } // 获取构造函数,以便实现作用域的绑定,并且会改变数组本身 let Constructor = Array.prototype.shift.call(arguments); //Person console.log(Constructor); obj.__proto__ = Constructor.prototype; console.log(arguments); //{ '0': 'wxh' } let result = Constructor.apply(obj, arguments); return typeof result === "object" ? result : obj; }; function Person(name) { this.name = name; } Person.prototype.say = function () { console.log(`my name is ${this.name}`); }; var person = newMethod(Person, "wxh"); person.say(); - 两个数组的并集与差集
var unionMetod = function (nums1, nums2) {// return [...nums1, ...nums2];// return nums1.concat(nums2);// for (let data of nums2) {// nums1.push(data);// }// return nums1;nums1.push.apply(nums1, nums2);return nums1;};//let nums1 = [1, 2, 2, 1, 3]; let nums2 = [2, 2]; 结果[1, 2, 2, 1, 3,2,2] var complementaryMethod = function (nums1, nums2) { let arr1 = new Set(nums1); let arr2 = new Set(nums2); return [...arr1].filter((item) => !arr2.has(item));//let nums1 = [1, 2, 2, 1, 3]; let nums2 = [2, 2]; 结果[1,3] }; - 两个数组的交集(
要求:输出结果中每个元素的出现次数,应与元素在两个数组中出现次数的最小值一致;并且不考虑元素的输出顺序)
// let nums1 = [1, 2, 2, 1, 3]; // let nums2 = [2, 2]; //结果[2,2] let nums1 = [4, 9, 5]; let nums2 = [9, 4, 9, 8, 4]; //结果[9,4]
View Code/** * 哈希表 * intersectionMethods 求两个数组的交集,输出结果中每个元素的出现次数,应与元素在两个数组中出现次数的最小值一致 * @param {*} nums1 * @param {*} nums2 */ var intersectionHash = function (nums1, nums2) { let map = new Map(); let finalAry = []; /** * 将数组中出现的元素映射成哈希表 */ for (let data of nums1) { if (map.has(data)) { let index = map.get(data); map.set(data, ++index); } else { map.set(data, 1); } } for (let item of nums2) { if (map.has(item) && map.get(item) > 0) { finalAry.push(item); let index2 = map.get(item); map.set(item, --index2); } } return finalAry; }; /** * 排序 + 双指针 * @param {*} nums1 * @param {*} nums2 */ var intersectionPointer = function (nums1, nums2) { nums1.sort((a, b) => { return a - b; }); nums2.sort((a, b) => { return a - b; }); let p1 = 0; let p2 = 0; let finalAry = []; while (p1 < nums1.length && p2 < nums2.length) { if (nums1[p1] < nums2[p2]) { p1++; } else if (nums1[p1] > nums2[p2]) { p2++; } else { finalAry.push(nums1[p1]); p1++; p2++; } } return finalAry; };
二、求两个数组的交集并去重:输出的每个元素是唯一的,不考虑输入结果的顺序
let nums1 = [1, 2, 2, 1, 3]; let nums2 = [2, 2]; //结果[2] // let nums1 = [4, 9, 5]; // let nums2 = [9, 4, 9, 8, 4]; //结果[9,4]/** * 根据Set结构中元素的唯一性 求交集并去重 * @param {*} nums1 * @param {*} nums2 */ var intersectionSet = function (nums1, nums2) { let arr1 = new Set(nums1); let arr2 = new Set(nums2); return [...arr1].filter((item) => arr2.has(item)); }; var intersectionIncludes = function (nums1, nums2) { return [...new Set(nums1.filter((item) => nums2.includes(item)))]; }; - 动态规划算法
- 特点:动态规划三要素【最优子结构】【边界】和【状态转移公式】;
- 参考文献
- call的模拟实现
View Code
/** * 1、将函数设为对象的属性 * 2、执行 && 删除这个函数 * 3、指定this到函数 并 传入给定参数 执行函数 * 4、如果不传入参数(null),默认指向为 window */ Function.prototype.callHandler = function (ctx) { // this 参数可以传 null,当为 null 的时候,视为指向 window var ctx = ctx || window; // 首先要获取调用call的函数,用this可以获取 ctx.fn = this; let args = []; // 从 Arguments 对象中取值,取出第二个到最后一个参数,然后放到一个数组里 for (let i = 1; i < arguments.length; i++) { args.push("arguments[" + i + "]"); } let result = eval("ctx.fn(" + args + ")"); //支持返回值, args 会自动调用 Array.toString() 这个方法 delete ctx.fn; return result; }; let value = "2"; let obj = { value: 1, }; function test(name, age) { console.log(name); console.log(age); console.log(this.value); } test.callHandler(obj, "wxh1", "22-1"); console.log("--------"); test.call(obj, "wxh2", "22-2");

- apply的模拟实现
View Code
/** * */ Function.prototype.applyHandler = function (ctx, args) { var ctx = Object(ctx) || window; ctx.fn = this; let argument = []; let result; if (!args) { result = ctx.fn(); } else { for (let i = 0; i < args.length; i++) { argument.push("args[" + i + "]"); } result = eval("ctx.fn(" + argument + ")"); } delete ctx.fn; return result; }; let obj = { flag: true, }; function test(name, age) { console.log(name); console.log(age); console.log(this.flag); } test.applyHandler(obj, ["wxh", "22"]);
- bind的模拟实现
View Code
/** * 1、会创建一个新函数 * 2、第一个参数将作为它运行时的 this,之后的一序列参数将会在传递的实参前传入作为它的参数 * 3、当返回的函数作为构造函数的时候,bind 时指定的 this 值会失效,但传入的参数依然生效 */ Function.prototype.bindHandler = function (ctx) { // 首先要获取调用 bind 的函数,用this可以获取 let self = this; if (typeof this !== "function") { throw new Error( "Function.prototype.bind - what is trying to be bound is not callable" ); } // 获取bindHandler函数从第二个参数到最后一个参数 let bindArgs = Array.prototype.slice.call(arguments, 1); //[ 'wxh' ] let tempFn = function () {}; let returnFn = function () { //回调函数的话 arguments 为 bindHandler的参数 // 获取bindHandler 返回的函数 let finalArys = Array.prototype.slice.call(arguments); // 当作为构造函数时,this 指向实例,此时结果为 true,将绑定函数的 this 指向该实例,可以让实例获得来自绑定函数的值 // 以上面的是 demo 为例,如果改成 `this instanceof fBound ? null : context`,实例只是一个空对象,将 null 改成 this ,实例会具有 habit 属性 // 当作为普通函数时,this 指向 window,此时结果为 false,将绑定函数的 this 指向 context return self.apply( this instanceof tempFn ? this : ctx, bindArgs.concat(finalArys) ); }; // 直接修改 returnFn.prototype 的时候,也会直接修改绑定函数的 prototype。这个时候,我们可以通过一个空函数来进行中转 tempFn.prototype = this.prototype; // 修改返回函数的 prototype 为绑定函数的 prototype,实例就可以继承绑定函数的原型中的值 returnFn.prototype = new tempFn(); return returnFn; }; let obj = { value: 1, }; function test(name, age) { console.log(arguments); console.log(name); console.log(age); console.log(this.value); } let fun = test.bindHandler(obj, "wxh"); fun("22"); - 模拟Object.create
View Code
Object.prototype.createHandler = function (__proto__, properties) { function F() {} F.prototype = __proto__; if (properties) { Object.defineProperties(F, properties); } return new F(); }; var hh = Object.createHandler( { a: 11 }, { b: { value: 3, writable: true, configurable: true, }, } ); console.dir(hh.__proto__);
- 模拟JSON的方法
View Code
var json = '{"name":"cxk", "age":25}'; console.log(json); console.log(JSON.parse(json)); /** * eval函数的作用:把字符串转换为合适的表达式,并输出表达式的值 * 但是容易造成 XSS(跨站脚本攻击):想办法“教唆”用户的浏览器去执行一些这个网页中原本不存在的前端代码。 * 1、窃取网页浏览中的cookie值 2、劫持流量实现恶意跳转 * 为什么要加括号呢? 因为js中{}通常是表示一个语句块,eval只会计算语句块内的值进行返回。加上括号就变成一个整体的表达式 */ console.log(eval("(" + json + ")")); /** * 对参数 json 做校验,只有真正符合 JSON 格式,才能调用 eval, */ var rx_one = /^[],:{}s]*$/; var rx_two = /\(?:["\/bfnrt]|u[0-9a-fA-F]{4})/g; var rx_three = /"[^"\ ]*"|true|false|null|-?d+(?:.d*)?(?:[eE][+-]?d+)?/g; var rx_four = /(?:^|:|,)(?:s*[)+/g; if ( rx_one.test( json.replace(rx_two, "@").replace(rx_three, "]").replace(rx_four, "") ) ) { var obj = eval("(" + json + ")"); console.log(obj); } /** * 使用递归手动扫描每个字符 */ var jsonStr = '{"name":"cxk", "age":22}', json = new Function("return " + jsonStr)(); console.log(json);

JSON.stringify()
View Code/** * 把json对象转换为json字符串 */ let obj1 = { flag: true, Number: 1, String: "111", data: { name: "wxh", }, }; console.log(obj1); console.log(JSON.stringify(obj1)); /** * 1、当对象为数字,null,boolean的时候,直接转换为相应的字符串就可以了 * 2、当对象为string,function,undefined,object,array等,需要特殊处理 * @param {*} obj * @returns */ function jsonStringify(obj) { let type = typeof obj; if (type !== "object") { if (/string|function/.test(type)) { return '"' + String(obj).replace('"', '\"') + '"'; } else if (type === undefined) { return "undefined"; } else { return String(obj); } } else { let json = []; let isArray = Array.isArray(obj); for (let k in obj) { let v = obj[k]; let type = typeof v; if (/string|function/.test(type)) { v = '"' + String(v).replace('"', '\"') + '"'; } else if (type === undefined) { v = "undefined"; } else if (type === "object") { v = jsonStringify(v); } json.push((isArray ? "" : '"' + k + '":') + String(v)); } return (isArray ? "[" : "{") + String(json) + (isArray ? "]" : "}"); } } console.log(jsonStringify(obj1));

- 正则相关
- 去除字符串前后的空格
let str1 = " 111 222 333 "; console.log(str1.length); function deleteSpace(str) { let reg = /^s+|s+$/g; return str.replace(reg, ""); } console.log(deleteSpace(str1)); console.log(deleteSpace(str1).length);

- 让首字母大写
let str2 = "hi man good luck"; function capitalize(str) { return str.replace(/w+/g, function (match) { return match.substr(0, 1).toUpperCase() + match.substr(1); }); } console.log(capitalize(str2));

- 相邻字符去重
function deleteDuplicate(str) { return str.replace(/([A-Za-z]{1})(1)+/g, "$1"); } console.log(deleteDuplicate("aaabbbcdfgghhjjkkk"));

- 模拟模板字符串
View Code
/** * render JS实现模板字符串 * @param {String} templateString 字符串的表达式 * @param {*} data * @returns */ function render(templateString, data) { let reg = /{{(w+)}}/g; let matchArgs = reg.exec(templateString); if (matchArgs !== null && matchArgs[0]) { const dataReg = new RegExp(matchArgs[0], "g"); // {{name}} let propertiesReg = new RegExp(/w+/, "g"); let matchPropertiers = propertiesReg.exec(matchArgs[0])[0]; //name templateString = templateString.replace(dataReg, data[matchPropertiers]); return render(templateString, data); // 递归的渲染并返回渲染后的结构 } return templateString; } let templateString = "我是{{name}},年龄{{age}},性别{{sex}}"; let data = { name: "wxh", age: 18, }; console.log(render(templateString, data)); // 我是wxh,年龄18,性别undefined
- 是否是邮箱
function isEmail(email) { var regx = /^([a-zA-Z0-9_-])+@([a-zA-Z0-9_-])+(.[a-zA-Z0-9_-])+$/; return regx.test(email); }
-
是否是身份证
function isCardNo(number) { var regx = /(^d{15}$)|(^d{18}$)|(^d{17}(d|X|x)$)/; return regx.test(number); }
-
文件命名
View Codelet str4 = "get-element-by-id"; function f(str) { return str.replace(/-w/g, function (match, p1, p2) { return match.substr(1).toUpperCase(); }); } console.log(f(str4)); //getElementById function s(str) { return str.replace(/[A-Z]/g, function (match) { return "-" + match.toLowerCase(); }); } console.log(s("getElementById")); //get-element-by-id
- 去除字符串前后的空格
- 111
四、设计模式
1、发布-订阅模式
- 概念
发布-订阅模式其实是一种对象间一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都将得到状态改变的通知。
订阅者(Subscriber)把自己想订阅的事件注册(Subscribe)到调度中心(Event Channel),当发布者(Publisher)发布该事件(Publish Event)到调度中心,也就是该事件触发时,由调度中心统一调度(Fire Event)订阅者注册到调度中心的处理代码。
- 优缺点
1. 优点 对象之间解耦 异步编程中,可以更松耦合的代码编写 2. 缺点 创建订阅者本身要消耗一定的时间和内存 虽然可以弱化对象之间的联系,多个发布者和订阅者嵌套一起的时候,程序难以跟踪维护
- 实现一个EventListener
View Code
/** * 1、创建一个对象 * 2、在该对象上创建一个缓存列表(调度中心) * 3、on 方法用来把函数 fn 都加到缓存列表中(订阅者注册事件到调度中心) * 4、emit 方法取到 arguments 里第一个当做 event,根据 event 值去执行对应缓存列表中的函数 * 发布者发布事件到调度中心,调度中心处理代码) * 5、off 方法可以根据 event 值取消订阅(取消订阅) * 6、once 方法只监听一次,调用完毕后删除缓存函数(订阅一次) */ class EventEmitter { constructor() { // 储存事件/回调键值对 相当于调度中心,是一个列表 this._events = this._events || new Map(); this._maxListeners = this._maxListeners || 10; // 设立监听上限 } } /** * 在 EventEmitter 中监听的每一类事件都有最大监听个数,超过了这个数值,事件虽然可以正常执行 * 但是会发出警告信息,其目的是为了防止内存泄露。 */ EventEmitter.defaultMaxListeners = 10; /** * 设置同类型事件监听最大个数 * @param {*} count */ EventEmitter.prototype.setMaxListeners = function (count) { this._count = count; }; // 获取同类型事件监听最大个数 EventEmitter.prototype.getMaxListeners = function () { return this._count || EventEmitter.defaultMaxListeners; }; /** * emit 发布 ----- 触发名为 event 的事件 * @param {*} event * @param {...any} args */ EventEmitter.prototype.emit = function (event, ...args) { // 从储存事件键值对的this._events中 获取对应事件 回调函数 let handler = this._events.get(event); if (handler) { if (Array.isArray(handler)) { // 是数组,说明有多个监听者,需要进行依此触发 for (let listener of handler) { listener.call(this, ...args); } } else { handler.call(this, ...args); } } }; /** * addListener/on 监听/订阅 名为 event 的事件 * @param {*} event * @param {*} fn */ EventEmitter.prototype.addListener = function (event, fn) { // 兼容继承不存在 _events 的情况 if (!this._events) this._events = new Map(); let handler = this._events.get(event); //如果不存在event,则返回undefined if (!handler) { this._events.set(event, fn); } else if (handler && typeof handler === "function") { // 如果handler是函数说明只有一个监听者 this._events.set(event, [handler, fn]); // 多个监听者我们需要用数组储存 } else { handler.push(fn); // 已经有多个监听者,那么直接往数组里push函数即可 // 获取事件最大监听个数 let maxListeners = this.getMaxListeners(); // 判断 type 类型的事件是否超出最大监听个数,超出打印警告信息 if (handler.length - 1 === maxListeners) { console.error( `MaxListenersExceededWarning: ${ maxListeners + 1 } ${type} listeners added` ); } } }; EventEmitter.prototype.on = EventEmitter.prototype.addListener; /** * once 只监听一次,调用完毕后删除缓存函数(订阅一次) * @param {*} event * @param {*} fn */ EventEmitter.prototype.once = function (event, fn) { // 先绑定,调用后删除 function on(...args) { fn(...args); this.removeListener(event, on); } // 自定义属性,存储 fn,确保单独使用 removeListener 删除传入的 fn 时可以被删除掉 on.listen = fn; this.addListener(event, on); }; /** * removeListener/off 根据 event 值取消订阅(取消订阅) * @param {*} event * @param {*} fn * @returns */ EventEmitter.prototype.removeListener = function (event, fn) { let handler = this._events.get(event); if (handler) { if (fn) { if (typeof handler === "function") { if (handler === fn) { this._events.delete(event); } else { return false; } } else { handler = handler.filter((listener) => { return listener !== fn; }); // 如果清除后只有一个函数,那么取消数组,以函数形式保存 if (handler.length === 1) { this._events.set(event, handler[0]); } else { this._events.set(event, handler); } } } else { // 当不传fn时,所有的回调函数都会取消订阅 this._events.delete(event); } } else { return false; } }; EventEmitter.prototype.off = EventEmitter.prototype.removeListener; const myEmitter = new EventEmitter(); // 订阅 let user1 = function (data) { console.log("用户1 订阅了"); console.log(data); }; let user2 = function (data) { console.log("用户2 订阅了"); console.log(data); }; let user3 = function (data) { console.log("用户3 订阅了"); console.log(data); }; let user4 = function (data) { console.log("用户4 订阅了"); console.log(data); }; myEmitter.on("南派三叔", user1); myEmitter.addListener("南派三叔", user2); myEmitter.off("南派三叔", user1); myEmitter.once("南派三叔", user3); myEmitter.addListener("南派三叔", user4); // 发布 myEmitter.emit("南派三叔", { title: "阴山古楼", section: "话音未落,闷油瓶直接就窜了出去,我根本没反应过来,他瞬间就到了包的面前一下抓住包的背带。他猛地一拽背包....", }); myEmitter.emit("南派三叔", { title: "万山极夜", section: "话音未落,闷油瓶直接就窜了出去,我根本没反应过来,他瞬间就到了包的面前一下抓住包的背带。他猛地一拽背包....", });

- 参考文章
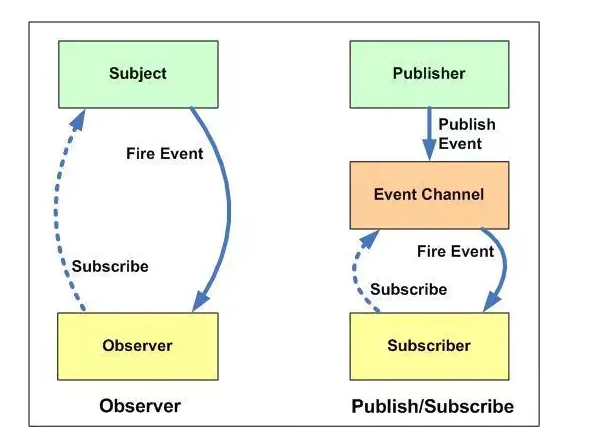
2、观察者模式
- 概念
观察者(Observer)直接订阅(Subscribe)主题(Subject),而当主题被激活的时候,会触发(Fire Event)观察者里的事件;
- 区别
1、在观察者模式中,观察者是知道 Subject 的,Subject 一直保持对观察者进行记录。然而,在发布订阅模式中,发布者和订阅者不知道对方的存在。它们只有通过消息代理进行通信。 2、在发布订阅模式中,组件是松散耦合的,正好和观察者模式相反。 3、观察者模式大多数时候是同步的,比如当事件触发,Subject 就会去调用观察者的方法。而发布-订阅模式大多数时候是异步的(使用消息队列)。 4、观察者模式需要在单个应用程序地址空间中实现,而发布-订阅更像交叉应用模式。
3、
Webpack开启gzip压缩