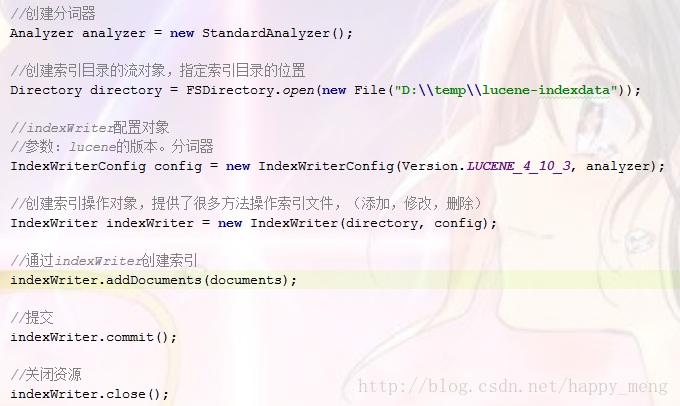
创建索引

搜索过程
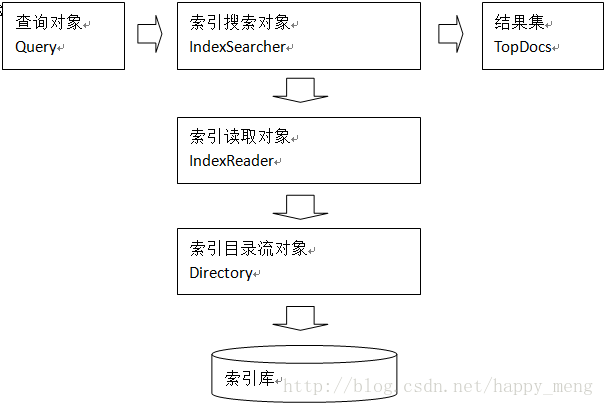 索引库返回一个TopDocs(匹配度高的前边的一些记录)
索引库返回一个TopDocs(匹配度高的前边的一些记录)
/搜索索引代码 @Test public void searchIndex() throws Exception{ //分词,所有过程使用的分析器要和索引时使用的分词器一致 Analyzer analyzer = new StandardAnalyzer(); //查询分析器 //第一个参数:指定默认搜索的域,第二个:分词器 QueryParser queryParser = new QueryParser("description",analyzer); //创建查询对象 Query query = queryParser.parse("description:java"); //创建索引目录的流对象,指定索引目录的位置 Directory directory = FSDirectory.open(new File("D:\temp\lucene-indexdata")); //索引读取对象 //指定读取索引的目录 IndexReader indexReader = IndexReader.open(directory); //索引搜索对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); //执行搜索 //第一个参数:query查询对象,第二个:取出匹配度高的前50条 TopDocs topDocs = indexSearcher.search(query,50); //取出匹配上的文档 ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc:scoreDocs){ //document的id int docID = scoreDoc.doc; //从indexReader根据docID获取document Document doc = indexReader.document(docID); //取出doc中的field域的内容 //参数指定field域名 String id = doc.get("id"); String name = doc.get("name"); float price = Float.parseFloat(doc.get("price")); String pic = doc.get("pic"); System.out.println("--------------------"); System.out.println("图书的id:"+id); System.out.println("图书的名称:"+name); System.out.println("图书的价格:"+price); System.out.println("图书的图片:"+pic); } indexReader.close(); }
Query查询方法:
Query是一个抽象类,lucene提供了很多查询对象.例如TermQuery项精确查询,NumericRangeQuery数字范围查询.BooleanQuery等等
方法1 .:直接使用query对象的构造查询方法.
Term term = new Term("name","java"); TermQuery termquery= new TermQuery(term);
NumericRangeQuery<Float> numericRangeQuery=new NumericRangeQuery("price",0f,100f,true,true)//域名,最大值,最小值,是否包括最小值,是否包括最大值
//BooleanQuery是组合查询,即根据价格查询也根据关键字查询.
BooleanQuery booleanQuery = new BooleanQuery();
booleanQuery .add(termquery,Occur.MUST); booleanQuery.add(numericRangeQuery,Occur.must);
must是and,SHOULD是or,MUST_NOT是not
方法2.使用查询解析器,构造查询语法(QueryParser),不支持数字范围,支持字符串范围.
QueryParser queryParser= new QueryParser("name",new StandardAnalyzed());
//从多个组合域中查询MultiFieldQueryParser
String [] field={"description","name"};
QueryParser queryParser= new MultiFieldQueryParser(field,analyzer);
Query query= queryParser.parse("lucene");//从description和name中查找.
Filed属性

是否分词(Tokenized) : 分词的目的是为了索引
是否索引(Indexed) : 索引的目的是为了搜索
是否存储(Stored): 存储的目的是为了将来搜索到document,显示出来.
|
Field类 |
数据类型 |
Tokenized是否分词 |
Indexed 是否索引 |
Stored 是否存储 |
说明 |
|
StringField(FieldName, FieldValue,Store.YES)) |
字符串 |
N |
Y |
Y或N |
这个Field用来构建一个字符串Field,但是不会进行分析,会将整个串存储在索引中,比如(订单号,姓名等) 是否存储在文档中用Store.YES或Store.NO决定 |
|
LongField(FieldName, FieldValue,Store.YES) |
Long型 |
Y |
Y |
Y或N |
这个Field用来构建一个Long数字型Field,进行分析和索引,比如(价格) 是否存储在文档中用Store.YES或Store.NO决定 |
|
StoredField(FieldName, FieldValue) |
重载方法,支持多种类型 |
N |
N |
Y |
这个Field用来构建不同类型Field 不分析,不索引,但要Field存储在文档中 |
|
TextField(FieldName, FieldValue, Store.NO) 或 TextField(FieldName, reader)
|
字符串 或 流 |
Y |
Y |
Y或N |
如果是一个Reader, lucene猜测内容比较多,会采用Unstored的策略. |