数据库,顾名思义是储存数据的仓库,常见的管理数据库的软件被称为数据库管理系统(DBMS, Database Management System), 常见的DBMS有 MySQL、PostgreSQL、SQLite、MongoDB。这些常见的DBMS我们可以把他们理解为专门负责搬运数据的管理的数据的程序。
1|01 什么是ORM?

对象关系映射(英语:(Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换 。 ORM是“对象-关系-映射”的简称。在web应用开发中ORM把底层的SQL数据实体转化成高层的Python对象。只需要通过Python代码即可完成数据库操作。
2|02 为什么要有ORM?
在web应用里使用原生的SQL语句操作数据库固然能达到处理储存数据的需求,但是会存在以下三类问题:
- 手动编写SQL语句比较复杂耗时(当然因人而异,如果热衷于原生sql,并不影响开发),并且视图函数中写大量SQL语句会降低代码的易读性。
- 比较容易出现安全问题,如SQL注入。
- 对于不同的DBMS,需要使用不同的Python接口库,语法各不相同,很难有标准化的代码流程。
使用ORM可以很大程度上解决这些问题,在python中,ORM把底层的SQL数据实体转化成高层的Python对象。这样的好处是,你甚至不需要了解SQL,只需要操作Python对象的即可完成数据库操作。
使用ORM的优势:
- 提升开发效率。从高层对象转换成原生SQL会牺牲一些性能,但这微不足道的性能牺牲换取的是巨大开发效率提升。
- 可移植性好。它实现了数据库模型与DEMS的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库。通常一个orm支持很多的DEMS,如1MySQL、PostgreSQL、Oracle、SQLite等,这极大的减轻了开发人员的工作量,不需要面对因数据库变更而导致的无效劳动。
3|03 如何在Flask应用ORM?
选择ORM框架时,在Flask中更推荐使用Flask的扩展组件Flask-SQLchemy 。Python实现的ORM有SQLAlchemy、Peewee、PonyORM等,其中SQLAlchemy是Python社区使用最广泛的ORM之一,Flask-SQLchemy正是基于SQLchemy。
3|13.1 连接数据库:
首先切入到虚拟环境 ,安装我们的 Flask-SQLchemy
这里DBMS以mysql数据库为例, 连接数据库
实例
解读:
1 从flask_sqlalchemy模块中导入SQLAlchemy类
2 app对象通过变量SQLALCHEMY_DATABASE_URI加载配置好的URI(统一资源标识符),URI内包含了各种用于连接数据库的信息,指向一个具体的库。
常用数据库的URI格式
3 SQLALCHEMY_TRACK_MODIFICATIONS这个配置变量决定是否追踪对象的修改,这用于FLask- SQLALchemy的事件通知系统。这个配置键默认值为None,如果没有特殊需要我们把它设置为Flase, 避免造成一些没必要的性能浪费。
4 SQLAlchemy类传入app类,引用app配置定位到具体的数据库,并且实例化出db对象,这个db对象代表我们的数据库,并且通过这个对象操作我们的ORM
3|23.2 数据库模型
3.2.1 什么是数据库模型?
继承了db.Model的python类,并且这个python类映射到数据库为一个表,这个python类称之为数据库模型。每个数据库模型都对应着数据库中的一个表。
3.2.2 数据库模型实例:
-
可以直接指定表名(推荐使用)。如果没有写
指定表名,此类名可以自动转化为表名(不推荐使用)。
- 类名自动转化表名的方式为
User-->user# 单个单词转换为小写UserInfo-->user_info# 多个单词转换为小写并使用下划线分隔 - 如UserInfo类在没有
__tablename__指定表名时候,UserInfo类会自动映射到数据库的表名为user_info。
- 类名自动转化表名的方式为
-
类实例化表示字段(表示数据库中的列),该类实例化出的对象被一个变量接受,该变量表示字段名。该类实例化时传入的参数表示字段的约束。
- 如:
id = db.Column(db.Integer,primary_key=True,autoincrement=True)表示该表内id字段为主键并且自动增长。
- 如:
3.2.3 常用的字段类型表:
| 字段 | 说明 | 映射到数据库对应类型 |
|---|---|---|
| Integer | 整数 | int类型 |
| String | 字符串,String类内可选择length参数的值用于设置最大字符个数 |
varchar类型 |
| Text | 用于储存较长的Unicode文本,,理论上可以储存65535个字节 | text类型 |
| Date | 日期,存储Python的datetime.date 对象 |
date类型 |
| Time | 时间,存储Python的datetime.time 对象 |
time类型 |
| DateTime | 时间和日期,存储Python 的datetime 对象 |
datetime类型 |
| Float | 浮点类型 | float类型 |
| Double | 双精度浮点类型,比浮点类型小数位精度更高。 | double类型,占据64位。 |
| Boolean | 布尔值 | tinyint类型 |
| Enum | 枚举类型 | enum类型 |
**3.2.4 **Column常用参数表:
| 约束 | 说明 |
|---|---|
| primary_key | 如果设为True,该列就是表的主键 |
| unique | 如果设为True,该列每个值唯一,也就是该字段不允许出现重复值 |
| index | 如果设为True,为这列创建索引,用于提升查询效率 |
| nullable | 如果设为True,这列允许使用空值,反之则不允许使用空值。 |
| server_default | 为这列定义默认值, 默认值只支持字符串,其他类型需要db.text()方法指定 |
| default | 为这列定义默认值,但是该约束并不会真正映射到表结构中,该约束只会在ORM层面实现(不推荐使用) |
| comment | 该字段的注释 |
| name | 可以使用该参数直接指定字段名 |
| autoincrement | 设置这个字段为自动增长的。 |
server_default常用配置
| 配置默认值类型 | 代码 |
|---|---|
| 更新datatime时间 | server_default = db.text("CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP") |
| 当前的datatime时间 | server_default = db.text("CURRENT_TIMESTAMP") |
| 数字 | server_default=“数字” |
| 布尔 | server_default=db.text('True') / server_default=db.text('False')/ server_default='数字' |
3.2.5 将写好的模型映射到数据库。
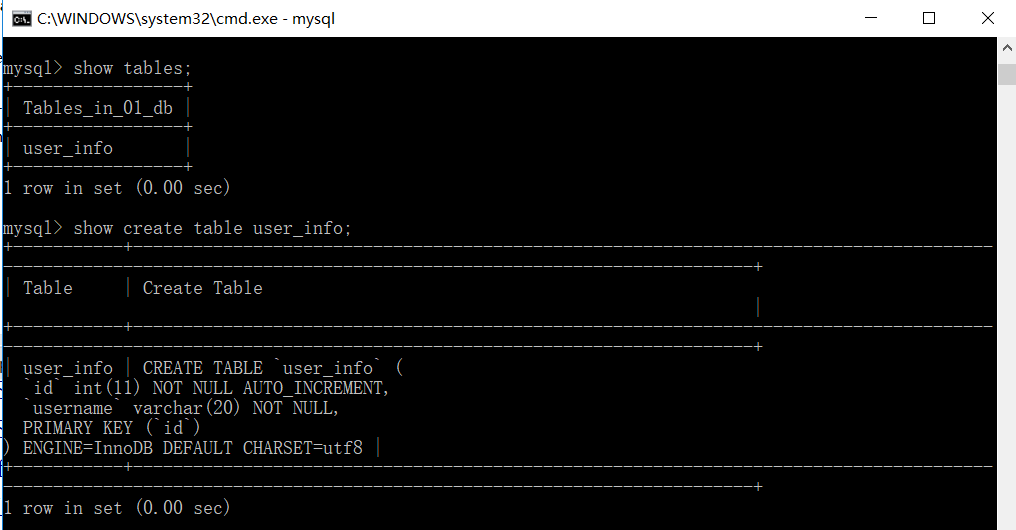
如果你已经定义好了一个继承db.Model的类,把这个类称之为模型。想把这个模型映射到数据库中,也就是在数据库中创建这个模型所描述的一张表,使用db.create_all()可以实现把继承了该db.model的所有模型创建到数据库中。查看数据库的时候会发现多了一张user_info表。
3.2.6 更新模型
如果要更新一个模型,并且想把这个新的模型映射到数据库中,直接使用db.create_all()会无效,因为原来已经存在了这张表,为了解决这个问题可以先db.drop_all()删除该库下的所有继承了db.model的模型表,然后再db.create_all()使得继承了db.model的所有模型表映射到数据库中,从而创建更新的表。这种方式的原理是先删除数据库中原来所有的模型表,然后在新建所有需要映射的模型表,这种方式的弊端是它把数据库中原有的数据都销毁了。
为了解决这种更新模型导致删除掉原来的数据的弊端。下一章介绍一种更好的方式用于更新数据库。
3|33.3 数据库操作
3.3.1 增
模型表 映射到数据中
实例3.3.1.1: 新增实例
新增四条记录映射到数据库中
提示:数据库会话db.session和后面介绍的Flasksession对象没有关系。db.session是数据库会话也称为事务。
- 实例化模型类创建对象,该对象作为一条记录,实例化的过程传入的参数为字段内容。
- 把新创建的记录添加到数据库会话。
- 提交数据库会话
查看数据库

提示1 :如果add多条记录可以使用add_all()一次添加包含多条记录的列表
如:db.session.add_all([school_01,school_02,school_03,school_04])
3.3.2 查
在flask中db.session出的对象调用query属性,可以通过query属性调用各种过滤方法完成查询。
常用过滤器表:
| 过滤器 | 说明 |
|---|---|
| filter() | 使用指定的规则过滤记录相当于sql的where约束条件,返回一个新查询 |
| filter_by() | 同filter原理,不同的是查询的时要使用关键字参数,返回一个新查询 |
| limit() | 使用指定的值限制原查询返回的结果的数量,返回一个新查询 |
| offset() | 偏移原查询返回的结果,返回一个新查询 |
| order_by() | 根据指定条件对原查询结构进行排序,返回一个新查询 |
| group_by() | 根据指定条件对原来查询结构进行分组,返回一个新查询 |
实例3.3.2.1: 查询实例
下面几个查询案例需要在实例3.3.1完成的基础上操作
all()返回一个列表,列表里存放所有符合条件的记录
first()返回符合条件的第一条记录:
get()返回指定主键值(id字段)的记录:
filter() 使用指定的规则过滤记录相当于sql的where约束条件,返回新产生的查询对象。
filter_by:同filter()效果一样,查询的时候使用关键字参数查询(无法进行多表复杂查询,不推荐使用)
db.session.qury(模型类)等价于模型类.query,db.session.qury功能更强大一些,可以进行多表查询。
提示:其他的过滤器会在接下来的章节具体根据实际案例讲解
3.3.3 改
实例3.3.3.1: 修改实例
修改北京大学的录取成绩

更新一条记录分为一下几部:
-
找到对应的记录对象
-
修改记录对象的属性
-
直接调用
db.session.commit()提交会话提示:只有要插入新的记录或要将现有的记录添加到会话中时才需要使用add()方法。只是更新现有记录的时可以修改记录对象属性后直接提交会话
3.3.4 删
实例3.3.4.1: 删除实例
从数据库中删除清华大学相关信息

删除一条记录分为以下几步:
- 找到对应的记录对象
- 需要调用
delete()方法在会话中标识需要删除的记录,具体是把该记录对象传入db.session.delete(记录对象)实现标识。 - 调用
db.session.commit()提交会话。