synchronized和ReentrantLock有什么区别呢?
典型回答
synchronized 是 Java 内建的同步机制,所以也有人称其为 Intrinsic Locking,它提供了互斥的语义和可见性,当一个线程已经获取当前锁时,其他试图获取的线程只能等待或者阻塞在那里。
在 Java 5 以前,synchronized 是仅有的同步手段,在代码中, synchronized 可以用来修饰方法,也可以使用在特定的代码块儿上,本质上 synchronized 方法等同于把方法全部语句用 synchronized 块包起来。
ReentrantLock,通常翻译为再入锁,是 Java 5 提供的锁实现,它的语义和 synchronized 基本相同。再入锁通过代码直接调用 lock() 方法获取,代码书写也更加灵活。与此同时,ReentrantLock 提供了很多实用的方法,能够实现很多 synchronized 无法做到的细节控制,比如可以控制 fairness,也就是公平性,或者利用定义条件等。但是,编码中也需要注意,必须要明确调用 unlock() 方法释放,不然就会一直持有该锁。
synchronized 和 ReentrantLock 的性能不能一概而论,早期版本 synchronized 在很多场景下性能相差较大,在后续版本进行了较多改进,在低竞争场景中表现可能优于 ReentrantLock。
考点分析
题目考察并发编程的常见基础题,下面给出的典型回答算是一个相对全面的总结。
对于并发编程,不同公司或者面试官面试风格也不一样,有个别大厂喜欢一直追问你相关机制的扩展或者底层,有的喜欢从实用角度出发,所以你在准备并发编程方面需要一定的耐心。
锁作为并发的基础工具之一,至少需要掌握:
- 理解什么是线程安全。
synchronized、ReentrantLock等机制的基本使用与案例。
更近一步,你还需要:
- 掌握
synchronized、ReentrantLock底层实现;理解锁膨胀、降级;理解偏斜锁、自旋锁、轻量级锁、重量级锁等概念。 - 掌握并发包中
java.util.concurrent.lock各种不同实现和案例分析。
知识扩展
首先,我们需要理解什么是线程安全。
建议阅读 Brain Goetz 等专家撰写的《Java 并发编程实战》(Java Concurrency in Practice),虽然可能稍显学究,但不可否认这是一本非常系统和全面的 Java 并发编程书籍。按照其中的定义,线程安全是一个多线程环境下正确性的概念,也就是保证多线程环境下共享的、可修改的状态的正确性,这里的状态反映在程序中其实可以看作是数据。
换个角度来看,如果状态不是共享的,或者不是可修改的,也就不存在线程安全问题,进而可以推理出保证线程安全的两个办法:
- 封装:通过封装,我们可以将对象内部状态隐藏、保护起来。
- 不可变:Java 语言目前还没有真正意义上的原生不可变,但是未来也许会引入。
线程安全需要保证几个基本特性:
- 原子性,简单说就是相关操作不会中途被其他线程干扰,一般通过同步机制实现。
- 可见性,是一个线程修改了某个共享变量,其状态能够立即被其他线程知晓,通常被解释为将线程本地状态反映到主内存上,
volatile就是负责保证可见性的。 - 有序性,是保证线程内串行语义,避免指令重排等。
可能有点晦涩,那么我们看看下面的代码段,分析一下原子性需求体现在哪里。这个例子通过取两次数值然后进行对比,来模拟两次对共享状态的操作。
你可以编译并执行,可以看到,仅仅是两个线程的低度并发,就非常容易碰到 former 和 latter 不相等的情况。这是因为,在两次取值的过程中,其他线程可能已经修改了 sharedState。
public class ThreadSafeSample {
public int sharedState;
public void nonSafeAction() {
while (sharedState < 100000) {
int former = sharedState++;
int latter = sharedState;
if (former != latter - 1) {
System.out.printf("Observed data race, former is " +
former + ", " + "latter is " + latter);
}
}
}
public static void main(String[] args) throws InterruptedException {
ThreadSafeSample sample = new ThreadSafeSample();
Thread threadA = new Thread(){
public void run(){
sample.nonSafeAction();
}
};
Thread threadB = new Thread(){
public void run(){
sample.nonSafeAction();
}
};
threadA.start();
threadB.start();
threadA.join();
threadB.join();
}
}
下面是在我的电脑上的运行结果:
C:>c:jdk-9injava ThreadSafeSample
Observed data race, former is 13097, latter is 13099
将两次赋值过程用 synchronized 保护起来,使用 this 作为互斥单元,就可以避免别的线程并发的去修改 sharedState。
synchronized (this) {
int former = sharedState ++;
int latter = sharedState;
// …
}
如果用 javap 反编译,可以看到类似片段,利用 monjavaitorenter/monitorexit 对实现了同步的语义:
11: astore_1
12: monitorenter
13: aload_0
14: dup
15: getfield #2 // Field sharedState:I
18: dup_x1
…
56: monitorexit
代码中使用 synchronized 非常便利,如果用来修饰静态方法,其等同于利用下面代码将方法体囊括进来:
synchronized (ClassName.class) {}
再来看看 ReentrantLock。你可能好奇什么是再入?它是表示当一个线程试图获取一个它已经获取的锁时,这个获取动作就自动成功,这是对锁获取粒度的一个概念,也就是锁的持有是以线程为单位而不是基于调用次数。Java 锁实现强调再入性是为了和 pthread 的行为进行区分。
再入锁可以设置公平性(fairness),我们可在创建再入锁时选择是否是公平的。
ReentrantLock fairLock = new ReentrantLock(true);
这里所谓的公平性是指在竞争场景中,当公平性为真时,会倾向于将锁赋予等待时间最久的线程。公平性是减少线程“饥饿”(个别线程长期等待锁,但始终无法获取)情况发生的一个办法。
如果使用 synchronized,我们根本无法进行公平性的选择,其永远是不公平的,这也是主流操作系统线程调度的选择。通用场景中,公平性未必有想象中的那么重要,Java 默认的调度策略很少会导致 “饥饿”发生。与此同时,若要保证公平性则会引入额外开销,自然会导致一定的吞吐量下降。所以,我建议只有当你的程序确实有公平性需要的时候,才有必要指定它。
我们再从日常编码的角度学习下再入锁。为保证锁释放,每一个 lock() 动作,我建议都立即对应一个 try-catch-finally,典型的代码结构如下,这是个良好的习惯。
ReentrantLock fairLock = new ReentrantLock(true);// 这里是演示创建公平锁,一般情况不需要。
fairLock.lock();
try {
// do something
} finally {
fairLock.unlock();
}
ReentrantLock 相比 synchronized,因为可以像普通对象一样使用,所以可以利用其提供的各种便利方法,进行精细的同步操作,甚至是实现 synchronized 难以表达的用例,如:
- 带超时的获取锁尝试。
- 可以判断是否有线程,或者某个特定线程,在排队等待获取锁。
- 可以响应中断请求。
- …
这里特别想强调条件变量(java.util.concurrent.Condition),如果说 ReentrantLock 是 synchronized 的替代选择,Condition 则是将 wait、notify、notifyAll 等操作转化为相应的对象,将复杂而晦涩的同步操作转变为直观可控的对象行为。
条件变量最为典型的应用场景就是标准类库中的 ArrayBlockingQueue 等。
我们参考下面的源码,首先,通过再入锁获取条件变量:
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
两个条件变量是从同一再入锁创建出来,然后使用在特定操作中,如下面的 take 方法,判断和等待条件满足:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
当队列为空时,试图 take 的线程的正确行为应该是等待入队发生,而不是直接返回,这是 BlockingQueue 的语义,使用条件 notEmpty 就可以优雅地实现这一逻辑。
那么,怎么保证入队触发后续 take 操作呢?请看 enqueue 实现:
private void enqueue(E e) {
// assert lock.isHeldByCurrentThread();
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
items[putIndex] = e;
if (++putIndex == items.length) putIndex = 0;
count++;
notEmpty.signal(); // 通知等待的线程,非空条件已经满足
}
通过 signal/await 的组合,完成了条件判断和通知等待线程,非常顺畅就完成了状态流转。注意,signal 和 await 成对调用非常重要,不然假设只有 await 动作,线程会一直等待直到被打断(interrupt)。
从性能角度,synchronized 早期的实现比较低效,对比 ReentrantLock,大多数场景性能都相差较大。但是在 Java 6 中对其进行了非常多的改进,可以参考性能对比,在高竞争情况下,ReentrantLock 仍然有一定优势。在大多数情况下,无需纠结于性能,还是考虑代码书写结构的便利性、可维护性等。
synchronized底层如何实现?什么是锁的升级、降级?
典型回答
synchronized 代码块是由一对儿 monitorenter/monitorexit 指令实现的,Monitor 对象是同步的基本实现单元。
在 Java 6 之前,Monitor 的实现完全是依靠操作系统内部的互斥锁,因为需要进行用户态到内核态的切换,所以同步操作是一个无差别的重量级操作。
现代的(Oracle)JDK 中,JVM 对此进行了大刀阔斧地改进,提供了三种不同的 Monitor 实现,也就是常说的三种不同的锁:偏斜锁(Biased Locking)、轻量级锁和重量级锁,大大改进了其性能。所谓锁的升级、降级,就是 JVM 优化 synchronized 运行的机制,当 JVM 检测到不同的竞争状况时,会自动切换到适合的锁实现,这种切换就是锁的升级、降级。
当没有竞争出现时,默认会使用偏斜锁。JVM 会利用 CAS 操作(compare and swap),在对象头上的 Mark Word 部分设置线程 ID,以表示这个对象偏向于当前线程,所以并不涉及真正的互斥锁。这样做的假设是基于在很多应用场景中,大部分对象生命周期中最多会被一个线程锁定,使用偏斜锁可以降低无竞争开销。
如果有另外的线程试图锁定某个已经被偏斜过的对象,JVM 就需要撤销(revoke)偏斜锁,并切换到轻量级锁实现。轻量级锁依赖 CAS 操作 Mark Word 来试图获取锁,如果重试成功,就使用普通的轻量级锁;否则,进一步升级为重量级锁。
注意到有的观点认为 Java 不会进行锁降级。实际上,锁降级确实是会发生的,当 JVM 进入安全点(SafePoint)的时候,会检查是否有闲置的 Monitor,然后试图进行降级。
考点分析
今天的问题主要是考察你对 Java 内置锁实现的掌握,也是并发的经典题目。
能够基础性地理解这些概念和机制,其实对于大多数并发编程已经足够了,毕竟大部分工程师未必会进行更底层、更基础的研发,很多时候解决的是知道与否,真正的提高还要靠实践踩坑。
后面会进一步分析:
- 从源码层面,稍微展开一些
synchronized的底层实现。如果你对 Java 底层源码有兴趣,但还没有找到入手点,这里可以成为一个切入点。 - 理解并发包中
java.util.concurrent.lock提供的其他锁实现,毕竟 Java 可不是只有ReentrantLock一种显式的锁类型,会结合代码分析其使用。
知识扩展
synchronized 是 JVM 内部的 Intrinsic Lock,所以偏斜锁、轻量级锁、重量级锁的代码实现,并不在核心类库部分,而是在 JVM 的代码中。
Java 代码运行可能是解释模式也可能是编译模式,所以对应的同步逻辑实现,也会分散在不同模块下,比如,解释器版本就是:src/hotspot/share/interpreter/interpreterRuntime.cpp
为了简化便于理解,我这里会专注于通用的基类实现:src/hotspot/share/runtime/
另外请注意,链接指向的是最新 JDK 代码库,所以可能某些实现与历史版本有所不同。
首先,synchronized 的行为是 JVM runtime 的一部分,所以我们需要先找到 Runtime 相关的功能实现。通过在代码中查询类似“monitor_enter”或“Monitor Enter”,很直观的就可以定位到:
- sharedRuntime.cpp/hpp,它是解释器和编译器运行时的基类。
- synchronizer.cpp/hpp,JVM 同步相关的各种基础逻辑。
在 sharedRuntime.cpp 中,下面代码体现了 synchronized 的主要逻辑。

Handle h_obj(THREAD, obj);
if (UseBiasedLocking) {
// Retry fast entry if bias is revoked to avoid unnecessary inflation
ObjectSynchronizer::fast_enter(h_obj, lock, true, CHECK);
} else {
ObjectSynchronizer::slow_enter(h_obj, lock, CHECK);
}
其实现可以简单进行分解:
UseBiasedLocking是一个检查,因为,在 JVM 启动时,我们可以指定是否开启偏斜锁。
偏斜锁并不适合所有应用场景,撤销操作(revoke)是比较重的行为,只有当存在较多不会真正竞争的 synchronized 块儿时,才能体现出明显改善。实践中对于偏斜锁的一直是有争议的,有人甚至认为,当你需要大量使用并发类库时,往往意味着你不需要偏斜锁。从具体选择来看,还是建议需要在实践中进行测试,根据结果再决定是否使用。
还有一方面是,偏斜锁会延缓 JIT 预热的进程,所以很多性能测试中会显式地关闭偏斜锁,命令如下:
-XX:-UseBiasedLocking
fast_enter是我们熟悉的完整锁获取路径,slow_enter则是绕过偏斜锁,直接进入轻量级锁获取逻辑。
那么 fast_enter 是如何实现的呢?同样是通过在代码库搜索,我们可以定位到 synchronizer.cpp。 类似 fast_enter 这种实现,解释器或者动态编译器,都是拷贝这段基础逻辑,所以如果我们修改这部分逻辑,要保证一致性。这部分代码是非常敏感的,微小的问题都可能导致死锁或者正确性问题。
void ObjectSynchronizer::fast_enter(Handle obj, BasicLock* lock,
bool attempt_rebias, TRAPS) {
if (UseBiasedLocking) {
if (!SafepointSynchronize::is_at_safepoint()) {
BiasedLocking::Condition cond = BiasedLocking::revoke_and_rebias(obj, attempt_rebias, THREAD);
if (cond == BiasedLocking::BIAS_REVOKED_AND_REBIASED) {
return;
}
} else {
assert(!attempt_rebias, "can not rebias toward VM thread");
BiasedLocking::revoke_at_safepoint(obj);
}
assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");
}
slow_enter(obj, lock, THREAD);
}
来分析下这段逻辑实现:
- biasedLocking定义了偏斜锁相关操作,
revoke_and_rebias是获取偏斜锁的入口方法,revoke_at_safepoint则定义了当检测到安全点时的处理逻辑。 - 如果获取偏斜锁失败,则进入
slow_enter。 - 这个方法里面同样检查是否开启了偏斜锁,但是从代码路径来看,其实如果关闭了偏斜锁,是不会进入这个方法的,所以算是个额外的保障性检查吧。
另外,如果你仔细查看synchronizer.cpp里,会发现不仅仅是 synchronized 的逻辑,包括从本地代码,也就是 JNI,触发的 Monitor 动作,全都可以在里面找到(jni_enter/jni_exit)。
关于biasedLocking的更多细节就不展开了,明白它是通过 CAS 设置 Mark Word 就完全够用了,对象头中 Mark Word 的结构,可以参考下图:

顺着锁升降级的过程分析下去,偏斜锁到轻量级锁的过程是如何实现的呢?
我们来看看 slow_enter 到底做了什么。
void ObjectSynchronizer::slow_enter(Handle obj, BasicLock* lock, TRAPS) {
markOop mark = obj->mark();
if (mark->is_neutral()) {
// 将目前的 Mark Word 复制到 Displaced Header 上
lock->set_displaced_header(mark);
// 利用 CAS 设置对象的 Mark Word
if (mark == obj()->cas_set_mark((markOop) lock, mark)) {
TEVENT(slow_enter: release stacklock);
return;
}
// 检查存在竞争
} else if (mark->has_locker() &&
THREAD->is_lock_owned((address)mark->locker())) {
// 清除
lock->set_displaced_header(NULL);
return;
}
// 重置 Displaced Header
lock->set_displaced_header(markOopDesc::unused_mark());
ObjectSynchronizer::inflate(THREAD,
obj(),
inflate_cause_monitor_enter)->enter(THREAD);
}
请结合在代码中添加的注释,来理解如何从试图获取轻量级锁,逐步进入锁膨胀的过程。你可以发现这个处理逻辑,和我在这一讲最初介绍的过程是十分吻合的。
- 设置 Displaced Header,然后利用
cas_set_mark设置对象 Mark Word,如果成功就成功获取轻量级锁。 - 否则 Displaced Header,然后进入锁膨胀阶段,具体实现在 inflate 方法中。
今天就不介绍膨胀的细节了,这里提供了源代码分析的思路和样例,考虑到应用实践,再进一步增加源代码解读意义不大,有兴趣的同学可以参考我提供的synchronizer.cpp链接,例如:
- deflate_idle_monitors是分析锁降级逻辑的入口,这部分行为还在进行持续改进,因为其逻辑是在安全点内运行,处理不当可能拖长 JVM 停顿(STW,stop-the-world)的时间。
- fast_exit 或者 slow_exit 是对应的锁释放逻辑。
前面分析了 synchronized 的底层实现,理解起来有一定难度,下面我们来看一些相对轻松的内容。 Java 核心类库中还有其他一些特别的锁类型,具体请参考下面的图。

你可能注意到了,这些锁竟然不都是实现了 Lock 接口,ReadWriteLock 是一个单独的接口,它通常是代表了一对儿锁,分别对应只读和写操作,标准类库中提供了再入版本的读写锁实现(ReentrantReadWriteLock),对应的语义和 ReentrantLock 比较相似。
StampedLock 竟然也是个单独的类型,从类图结构可以看出它是不支持再入性的语义的,也就是它不是以持有锁的线程为单位。
为什么我们需要读写锁(ReadWriteLock)等其他锁呢?
这是因为,虽然 ReentrantLock 和 synchronized 简单实用,但是行为上有一定局限性,通俗点说就是“太霸道”,要么不占,要么独占。实际应用场景中,有的时候不需要大量竞争的写操作,而是以并发读取为主,如何进一步优化并发操作的粒度呢?
Java 并发包提供的读写锁等扩展了锁的能力,它所基于的原理是多个读操作是不需要互斥的,因为读操作并不会更改数据,所以不存在互相干扰。而写操作则会导致并发一致性的问题,所以写线程之间、读写线程之间,需要精心设计的互斥逻辑。
下面是一个基于读写锁实现的数据结构,当数据量较大,并发读多、并发写少的时候,能够比纯同步版本凸显出优势。
public class RWSample {
private final Map<String, String> m = new TreeMap<>();
private final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
private final Lock r = rwl.readLock();
private final Lock w = rwl.writeLock();
public String get(String key) {
r.lock();
System.out.println(" 读锁锁定!");
try {
return m.get(key);
} finally {
r.unlock();
}
}
public String put(String key, String entry) {
w.lock();
System.out.println(" 写锁锁定!");
try {
return m.put(key, entry);
} finally {
w.unlock();
}
}
// …
}
在运行过程中,如果读锁试图锁定时,写锁是被某个线程持有,读锁将无法获得,而只好等待对方操作结束,这样就可以自动保证不会读取到有争议的数据。
读写锁看起来比 synchronized 的粒度似乎细一些,但在实际应用中,其表现也并不尽如人意,主要还是因为相对比较大的开销。
所以,JDK 在后期引入了 StampedLock,在提供类似读写锁的同时,还支持优化读模式。优化读基于假设,大多数情况下读操作并不会和写操作冲突,其逻辑是先试着读,然后通过 validate 方法确认是否进入了写模式,如果没有进入,就成功避免了开销;如果进入,则尝试获取读锁。请参考下面的样例代码。
public class StampedSample {
private final StampedLock sl = new StampedLock();
void mutate() {
long stamp = sl.writeLock();
try {
write();
} finally {
sl.unlockWrite(stamp);
}
}
Data access() {
long stamp = sl.tryOptimisticRead();
Data data = read();
if (!sl.validate(stamp)) {
stamp = sl.readLock();
try {
data = read();
} finally {
sl.unlockRead(stamp);
}
}
return data;
}
// …
}
注意,这里的 writeLock 和 unLockWrite 一定要保证成对调用。
你可能很好奇这些显式锁的实现机制,Java 并发包内的各种同步工具,不仅仅是各种 Lock,其他的如Semaphore、CountDownLatch,甚至是早期的FutureTask等,都是基于一种AQS框架。
一个线程两次调用start()方法会出现什么情况?
典型回答
Java 的线程是不允许启动两次的,第二次调用必然会抛出 IllegalThreadStateException,这是一种运行时异常,多次调用 start 被认为是编程错误。
关于线程生命周期的不同状态,在 Java 5 以后,线程状态被明确定义在其公共内部枚举类型 java.lang.Thread.State 中,分别是:
- 新建(NEW),表示线程被创建出来还没真正启动的状态,可以认为它是个 Java 内部状态。
- 就绪(RUNNABLE),表示该线程已经在 JVM 中执行,当然由于执行需要计算资源,它可能是正在运行,也可能还在等待系统分配给它 CPU 片段,在就绪队列里面排队。
- 在其他一些分析中,会额外区分一种状态 RUNNING,但是从 Java API 的角度,并不能表示出来。
- 阻塞(BLOCKED),阻塞表示线程在等待 Monitor lock。比如,线程试图通过
synchronized去获取某个锁,但是其他线程已经独占了,那么当前线程就会处于阻塞状态。 - 等待(WAITING),表示正在等待其他线程采取某些操作。一个常见的场景是类似生产者消费者模式,发现任务条件尚未满足,就让当前消费者线程等待(wait),另外的生产者线程去准备任务数据,然后通过类似 notify 等动作,通知消费线程可以继续工作了。
Thread.join()也会令线程进入等待状态。 - 计时等待(TIMED_WAIT),其进入条件和等待状态类似,但是调用的是存在超时条件的方法,比如 wait 或 join 等方法的指定超时版本,如下面示例:
public final native void wait(long timeout) throws InterruptedException;
- 终止(TERMINATED),不管是意外退出还是正常执行结束,线程已经完成使命,终止运行,也有人把这个状态叫作死亡。
在第二次调用 start() 方法的时候,线程可能处于终止或者其他(非 NEW)状态,但是不论如何,都是不可以再次启动的。
考点分析
这个问题可以算是个常见的面试热身题目,前面的给出的典型回答,算是对基本状态和简单流转的一个介绍,如果觉得还不够直观,下面分析会对比一个状态图进行介绍。总的来说,理解线程对于我们日常开发或者诊断分析,都是不可或缺的基础。
面试官可能会以此为契机,从各种不同角度考察你对线程的掌握:
- 相对理论一些的面试官可以会问你线程到底是什么以及 Java 底层实现方式。
- 线程状态的切换,以及和锁等并发工具类的互动。
- 线程编程时容易踩的坑与建议等。
可以看出,仅仅是一个线程,就有非常多的内容需要掌握。我们选择重点内容,开始进入详细分析。
知识扩展
首先,我们来整体看一下线程是什么?
从操作系统的角度,可以简单认为,线程是系统调度的最小单元,一个进程可以包含多个线程,作为任务的真正运作者,有自己的栈(Stack)、寄存器(Register)、本地存储(Thread Local)等,但是会和进程内其他线程共享文件描述符、虚拟地址空间等。
在具体实现中,线程还分为内核线程、用户线程,Java 的线程实现其实是与虚拟机相关的。对于我们最熟悉的 Sun/Oracle JDK,其线程也经历了一个演进过程,基本上在 Java 1.2 之后,JDK 已经抛弃了所谓的Green Thread,也就是用户调度的线程,现在的模型是一对一映射到操作系统内核线程。
如果我们来看 Thread 的源码,你会发现其基本操作逻辑大都是以 JNI 形式调用的本地代码。
private native void start0();
private native void setPriority0(int newPriority);
private native void interrupt0();
这种实现有利有弊,总体上来说,Java 语言得益于精细粒度的线程和相关的并发操作,其构建高扩展性的大型应用的能力已经毋庸置疑。但是,其复杂性也提高了并发编程的门槛,近几年的 Go 语言等提供了协程(coroutine),大大提高了构建并发应用的效率。于此同时,Java 也在Loom项目中,孕育新的类似轻量级用户线程(Fiber)等机制,也许在不久的将来就可以在新版 JDK 中使用到它。
下面,来分析下线程的基本操作。如何创建线程想必你已经非常熟悉了,请看下面的例子:
Runnable task = () -> {System.out.println("Hello World!");};
Thread myThread = new Thread(task);
myThread.start();
myThread.join();
我们可以直接扩展 Thread 类,然后实例化。但在本例中,我选取了另外一种方式,就是实现一个 Runnable,将代码逻放在 Runnable 中,然后构建 Thread 并启动(start),等待结束(join)。
Runnable 的好处是,不会受 Java 不支持类多继承的限制,重用代码实现,当我们需要重复执行相应逻辑时优点明显。而且,也能更好的与现代 Java 并发库中的 Executor 之类框架结合使用,比如将上面 start 和 join 的逻辑完全写成下面的结构:
Future future = Executors.newFixedThreadPool(1)
.submit(task)
.get();
这样我们就不用操心线程的创建和管理,也能利用 Future 等机制更好地处理执行结果。线程生命周期通常和业务之间没有本质联系,混淆实现需求和业务需求,就会降低开发的效率。
从线程生命周期的状态开始展开,那么在 Java 编程中,有哪些因素可能影响线程的状态呢?主要有:
- 线程自身的方法,除了
start,还有多个join方法,等待线程结束;yield是告诉调度器,主动让出 CPU;另外,就是一些已经被标记为过时的resume、stop、suspend之类,据了解,在 JDK 最新版本中,destory/stop方法将被直接移除。 - 基类
Object提供了一些基础的wait/notify/notifyAll方法。如果我们持有某个对象的Monitor锁,调用wait会让当前线程处于等待状态,直到其他线程notify或者notifyAll。所以,本质上是提供了 Monitor 的获取和释放的能力,是基本的线程间通信方式。 - 并发类库中的工具,比如
CountDownLatch.await()会让当前线程进入等待状态,直到latch被基数为 0,这可以看作是线程间通信的Signal。
这里画了一个状态和方法之间的对应图:

Thread 和 Object 的方法,听起来简单,但是实际应用中被证明非常晦涩、易错,这也是为什么 Java 后来又引入了并发包。总的来说,有了并发包,大多数情况下,我们已经不再需要去调用 wait/notify 之类的方法了。
前面谈了不少理论,下面谈谈线程 API 使用,会侧重于平时工作学习中,容易被忽略的一些方面。
先来看看守护线程(Daemon Thread),有的时候应用中需要一个长期驻留的服务程序,但是不希望其影响应用退出,就可以将其设置为守护线程,如果 JVM 发现只有守护线程存在时,将结束进程,具体可以参考下面代码段。注意,必须在线程启动之前设置。
Thread daemonThread = new Thread();
daemonThread.setDaemon(true);
daemonThread.start();
再来看看Spurious wakeup。尤其是在多核 CPU 的系统中,线程等待存在一种可能,就是在没有任何线程广播或者发出信号的情况下,线程就被唤醒,如果处理不当就可能出现诡异的并发问题,所以我们在等待条件过程中,建议采用下面模式来书写。
// 推荐
while ( isCondition()) {
waitForAConfition(...);
}
// 不推荐,可能引入 bug
if ( isCondition()) {
waitForAConfition(...);
}
Thread.onSpinWait(),这是 Java 9 中引入的特性。“自旋锁”(spin-wait, busy-waiting),也可以认为其不算是一种锁,而是一种针对短期等待的性能优化技术。“onSpinWait()”没有任何行为上的保证,而是对 JVM 的一个暗示,JVM 可能会利用 CPU 的 pause 指令进一步提高性能,性能特别敏感的应用可以关注。
再有就是慎用ThreadLocal,这是 Java 提供的一种保存线程私有信息的机制,因为其在整个线程生命周期内有效,所以可以方便地在一个线程关联的不同业务模块之间传递信息,比如事务 ID、Cookie 等上下文相关信息。
它的实现结构,可以参考源码,数据存储于线程相关的 ThreadLocalMap,其内部条目是弱引用,如下面片段。
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
// …
}
当 Key 为 null 时,该条目就变成“废弃条目”,相关“value”的回收,往往依赖于几个关键点,即 set、remove、rehash。
下面是 set 的示例,进行了精简和注释:
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];; …) {
//…
if (k == null) {
// 替换废弃条目
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
// 扫描并清理发现的废弃条目,并检查容量是否超限
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();// 清理废弃条目,如果仍然超限,则扩容(加倍)
}
具体的清理逻辑是实现在 cleanSomeSlots 和 expungeStaleEntry 之中,如果你有兴趣可以自行阅读。
通常弱引用都会和引用队列配合清理机制使用,但是 ThreadLocal 是个例外,它并没有这么做。
这意味着,废弃项目的回收依赖于显式地触发,否则就要等待线程结束,进而回收相应 ThreadLocalMap!这就是很多 OOM 的来源,所以通常都会建议,应用一定要自己负责 remove,并且不要和线程池配合,因为 worker 线程往往是不会退出的。
什么情况下Java程序会产生死锁?如何定位、修复?
典型回答
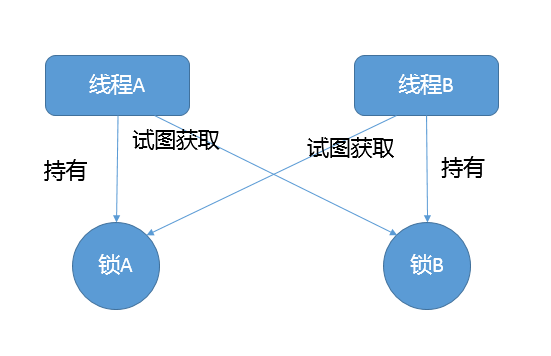
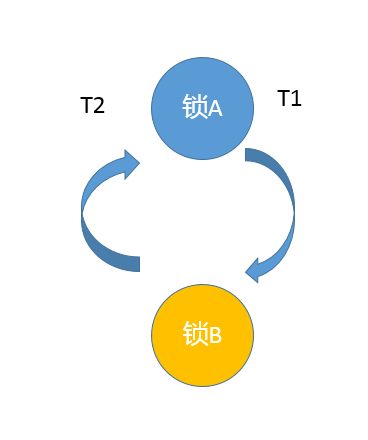
死锁是一种特定的程序状态,在实体之间,由于循环依赖导致彼此一直处于等待之中,没有任何个体可以继续前进。死锁不仅仅是在线程之间会发生,存在资源独占的进程之间同样也可能出现死锁。通常来说,我们大多是聚焦在多线程场景中的死锁,指两个或多个线程之间,由于互相持有对方需要的锁,而永久处于阻塞的状态。
你可以利用下面的示例图理解基本的死锁问题:
定位死锁最常见的方式就是利用 jstack 等工具获取线程栈,然后定位互相之间的依赖关系,进而找到死锁。如果是比较明显的死锁,往往 jstack 等就能直接定位,类似 JConsole 甚至可以在图形界面进行有限的死锁检测。
如果程序运行时发生了死锁,绝大多数情况下都是无法在线解决的,只能重启、修正程序本身问题。所以,代码开发阶段互相审查,或者利用工具进行预防性排查,往往也是很重要的。
考点分析
问题偏向于实用场景,大部分死锁本身并不难定位,掌握基本思路和工具使用,理解线程相关的基本概念,比如各种线程状态和同步、锁、Latch 等并发工具,就已经足够解决大多数问题了。
针对死锁,面试官可以深入考察:
- 抛开字面上的概念,让面试者写一个可能死锁的程序,顺便也考察下基本的线程编程。
- 诊断死锁有哪些工具,如果是分布式环境,可能更关心能否用 API 实现吗?
- 后期诊断死锁还是挺痛苦的,经常加班,如何在编程中尽量避免一些典型场景的死锁,有其他工具辅助吗?
知识扩展
在分析开始之前,先以一个基本的死锁程序为例,在这里只用了两个嵌套的 synchronized 去获取锁,具体如下:
public class DeadLockSample extends Thread {
private String first;
private String second;
public DeadLockSample(String name, String first, String second) {
super(name);
this.first = first;
this.second = second;
}
public void run() {
synchronized (first) {
System.out.println(this.getName() + " obtained: " + first);
try {
Thread.sleep(1000L);
synchronized (second) {
System.out.println(this.getName() + " obtained: " + second);
}
} catch (InterruptedException e) {
// Do nothing
}
}
}
public static void main(String[] args) throws InterruptedException {
String lockA = "lockA";
String lockB = "lockB";
DeadLockSample t1 = new DeadLockSample("Thread1", lockA, lockB);
DeadLockSample t2 = new DeadLockSample("Thread2", lockB, lockA);
t1.start();
t2.start();
t1.join();
t2.join();
}
}
这个程序编译执行后,几乎每次都可以重现死锁,请看下面截取的输出。另外,这里有个比较有意思的地方,为什么我先调用 Thread1 的 start,但是 Thread2 却先打印出来了呢?这就是因为线程调度依赖于(操作系统)调度器,虽然你可以通过优先级之类进行影响,但是具体情况是不确定的。

下面来模拟问题定位,选取最常见的 jstack,其他一些类似 JConsole 等图形化的工具,请自行查找。
首先,可以使用 jps 或者系统的 ps 命令、任务管理器等工具,确定进程 ID。
其次,调用 jstack 获取线程栈:
${JAVA_HOME}injstack your_pid
然后,分析得到的输出,具体片段如下:

最后,结合代码分析线程栈信息。上面这个输出非常明显,找到处于 BLOCKED 状态的线程,按照试图获取(waiting)的锁 ID(请看我标记为相同颜色的数字)查找,很快就定位问题。 jstack 本身也会把类似的简单死锁抽取出来,直接打印出来。
在实际应用中,类死锁情况未必有如此清晰的输出,但是总体上可以理解为:
区分线程状态 -> 查看等待目标 -> 对比 Monitor 等持有状态
所以,理解线程基本状态和并发相关元素是定位问题的关键,然后配合程序调用栈结构,基本就可以定位到具体的问题代码。
如果我们是开发自己的管理工具,需要用更加程序化的方式扫描服务进程、定位死锁,可以考虑使用 Java 提供的标准管理 API,ThreadMXBean,其直接就提供了 findDeadlockedThreads() 方法用于定位。为方便说明,修改了 DeadLockSample,请看下面的代码片段。
public static void main(String[] args) throws InterruptedException {
ThreadMXBean mbean = ManagementFactory.getThreadMXBean();
Runnable dlCheck = new Runnable() {
@Override
public void run() {
long[] threadIds = mbean.findDeadlockedThreads();
if (threadIds != null) {
ThreadInfo[] threadInfos = mbean.getThreadInfo(threadIds);
System.out.println("Detected deadlock threads:");
for (ThreadInfo threadInfo : threadInfos) {
System.out.println(threadInfo.getThreadName());
}
}
}
};
ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);
// 稍等 5 秒,然后每 10 秒进行一次死锁扫描
scheduler.scheduleAtFixedRate(dlCheck, 5L, 10L, TimeUnit.SECONDS);
// 死锁样例代码…
}
重新编译执行,你就能看到死锁被定位到的输出。在实际应用中,就可以据此收集进一步的信息,然后进行预警等后续处理。但是要注意的是,对线程进行快照本身是一个相对重量级的操作,还是要慎重选择频度和时机。
如何在编程中尽量预防死锁呢?
首先,我们来总结一下前面例子中死锁的产生包含哪些基本元素。基本上死锁的发生是因为:
- 互斥条件,类似 Java 中 Monitor 都是独占的,要么是我用,要么是你用。
- 互斥条件是长期持有的,在使用结束之前,自己不会释放,也不能被其他线程抢占。
- 循环依赖关系,两个或者多个个体之间出现了锁的链条环。
所以,我们可以据此分析可能的避免死锁的思路和方法。
第一种方法
如果可能的话,尽量避免使用多个锁,并且只有需要时才持有锁。否则,即使是非常精通并发编程的工程师,也难免会掉进坑里,嵌套的 synchronized 或者 lock 非常容易出问题。
举个例子, Java NIO 的实现代码向来以锁多著称,一个原因是,其本身模型就非常复杂,某种程度上是不得不如此;另外是在设计时,考虑到既要支持阻塞模式,又要支持非阻塞模式。直接结果就是,一些基本操作如 connect,需要操作三个锁以上,在最近的一个 JDK 改进中,就发生了死锁现象。
将其简化为下面的伪代码,问题是暴露在 HTTP/2 客户端中,这是个非常现代的反应式风格的 API,非常推荐学习使用。
/// Thread HttpClient-6-SelectorManager:
readLock.lock();
writeLock.lock();
// 持有 readLock/writeLock,调用 close()需要获得 closeLock
close();
// Thread HttpClient-6-Worker-2 持有 closeLock
implCloseSelectableChannel (); // 想获得 readLock
在 close 发生时, HttpClient-6-SelectorManager 线程持有 readLock/writeLock,试图获得 closeLock;与此同时,另一个 HttpClient-6-Worker-2 线程,持有 closeLock,试图获得 readLock,这就不可避免地进入了死锁。
这里比较难懂的地方在于,closeLock 的持有状态(就是标记为绿色的部分)并没有在线程栈中显示出来,请参考我在下图中标记的部分。
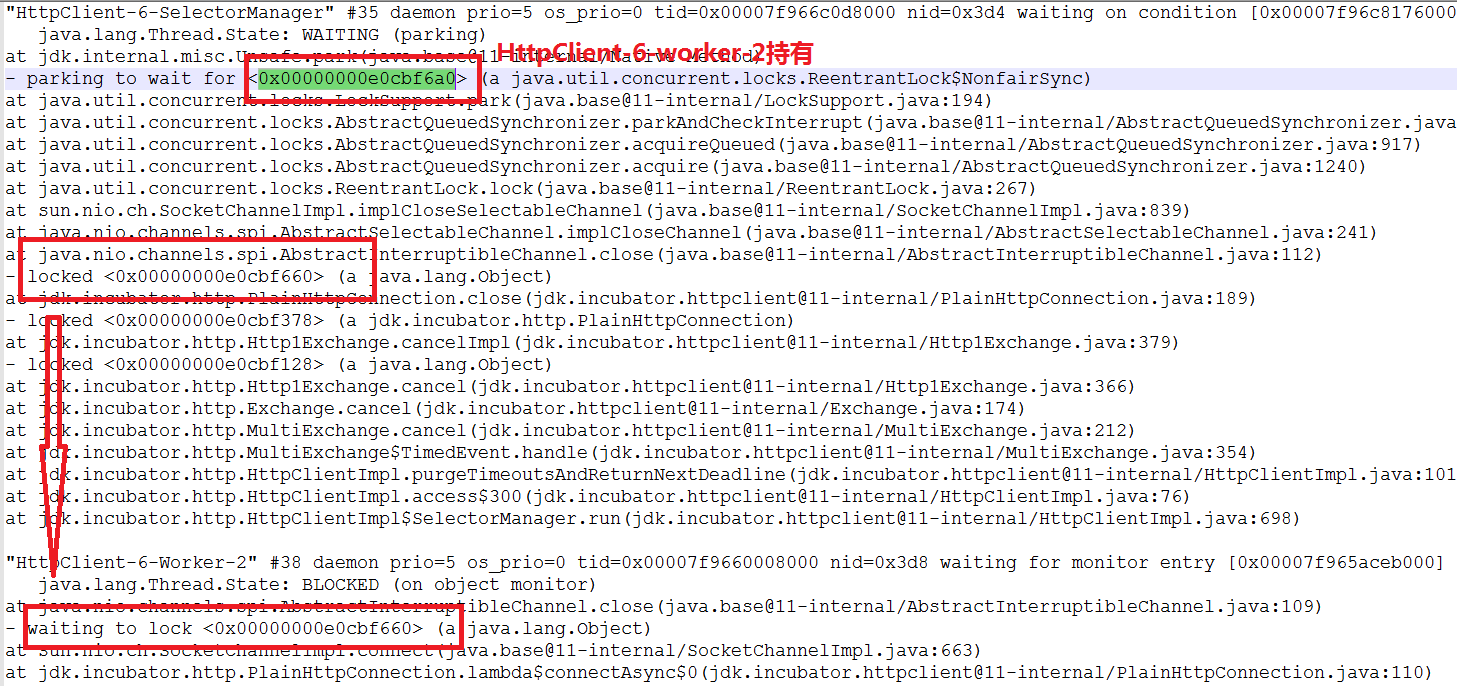
更加具体来说,请查看SocketChannelImpl的 663 行,对比 implCloseSelectableChannel() 方法实现和AbstractInterruptibleChannel.close()在 109 行的代码,这里就不展示代码了。
所以,从程序设计的角度反思,如果我们赋予一段程序太多的职责,出现“既要…又要…”的情况时,可能就需要我们审视下设计思路或目的是否合理了。对于类库,因为其基础、共享的定位,比应用开发往往更加令人苦恼,需要仔细斟酌之间的平衡。
第二种方法
如果必须使用多个锁,尽量设计好锁的获取顺序,这个说起来简单,做起来可不容易,你可以参看著名的银行家算法。
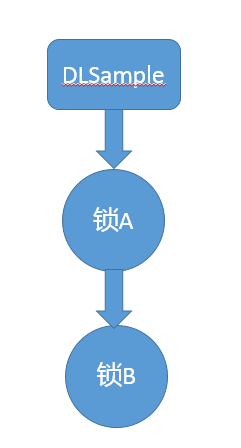
一般的情况,我建议可以采取些简单的辅助手段,比如:
- 将对象(方法)和锁之间的关系,用图形化的方式表示分别抽取出来,以今天最初讲的死锁为例,因为是调用了同一个线程所以更加简单。
- 然后根据对象之间组合、调用的关系对比和组合,考虑可能调用时序。
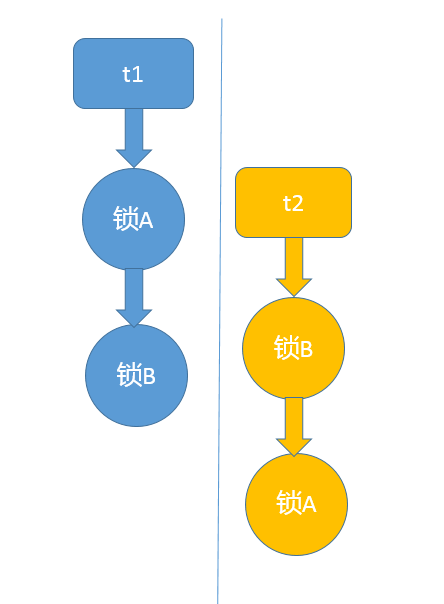
- 按照可能时序合并,发现可能死锁的场景。
第三种方法
使用带超时的方法,为程序带来更多可控性。
类似 Object.wait(…) 或者 CountDownLatch.await(…),都支持所谓的 timed_wait,我们完全可以就不假定该锁一定会获得,指定超时时间,并为无法得到锁时准备退出逻辑。
并发 Lock 实现,如 ReentrantLock 还支持非阻塞式的获取锁操作 tryLock(),这是一个插队行为(barging),并不在乎等待的公平性,如果执行时对象恰好没有被独占,则直接获取锁。有时,我们希望条件允许就尝试插队,不然就按照现有公平性规则等待,一般采用下面的方法:
if (lock.tryLock() || lock.tryLock(timeout, unit)) {
// ...
}
第四种方法
业界也有一些其他方面的尝试,比如通过静态代码分析(如 FindBugs)去查找固定的模式,进而定位可能的死锁或者竞争情况。实践证明这种方法也有一定作用,请参考相关文档。
除了典型应用中的死锁场景,其实还有一些更令人头疼的死锁,比如类加载过程发生的死锁,尤其是在框架大量使用自定义类加载时,因为往往不是在应用本身的代码库中,jstack 等工具也不见得能够显示全部锁信息,所以处理起来比较棘手。对此,Java 有官方文档进行了详细解释,并针对特定情况提供了相应 JVM 参数和基本原则。